ESIM
1.0.0
Внедрение модели ESIM для вывода естественного языка с помощью pytorch
Этот репозиторий содержит реализацию с Pytorch последовательной модели, представленной в статье «Улучшенный LSTM для вывода естественного языка» Chen et al. в 2016 году.
Рисунок ниже иллюстрирует высокий уровень архитектуры модели.
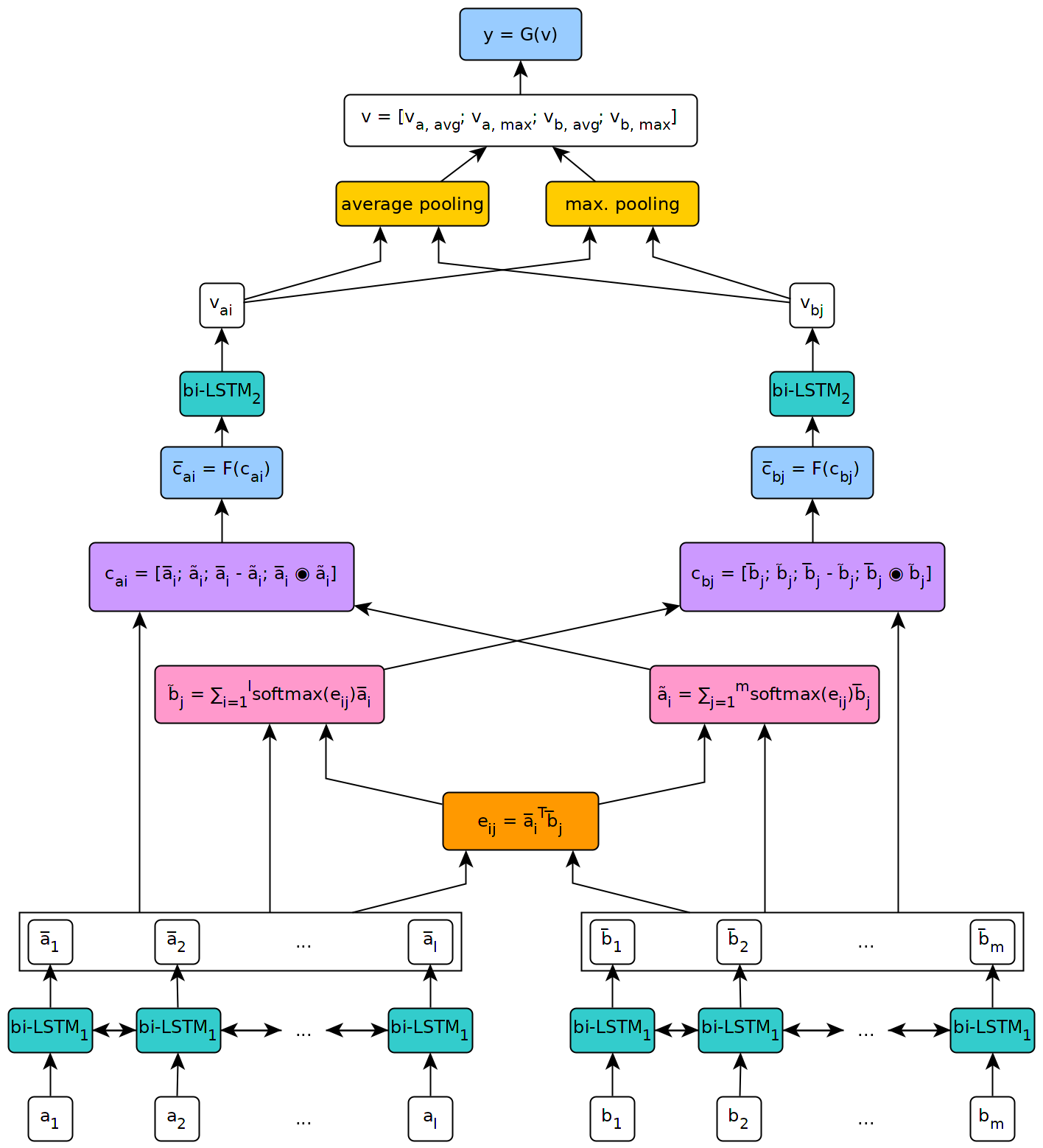
Эта модель была реализована в контексте моей магистерской диссертации в Женевском университете.
Чтобы использовать модель, определенную в этом репозитории, вам сначала необходимо установить Pytorch на вашем компьютере, выполнив шаги, описанные на официальной странице пакета (этот шаг необходим только в том случае, если вы используете Windows). Затем, чтобы установить зависимости, необходимые для запуска модели, просто выполните команду pip install --upgrade . из клонированного репозитория (в корне и предпочтительно внутри виртуальной среды).
Сценарий fetch_data.py , расположенный в сценариях/ папке этого репозитория, может использоваться для загрузки некоторого набора данных NLI и предварительных встроенных слов. По умолчанию скрипт получает корпус SNLI и Glove 840B 300D Entgeddings. Другие наборы данных можно загрузить, просто передавая их URL в качестве аргумента в сценарий (например, набор данных Multnli).
Использование сценария следующее:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
где target_dir - это путь к каталогу, в котором должны быть сохранены загруженные данные (по умолчанию .../data /).
Для Multinli соответствующие и несоответствующие тестовые наборы должны быть загружены вручную из Kaggle и соответствующих файлов .txt, копируемых в папке набора данных Multinli_1.0 .
Перед тем, как загруженный корпус и встраивание могут быть использованы в модели ESIM, их необходимо предварительно обработать. Это может быть сделано с помощью сценариев PRY в сценариях PY в папке сценариев/предварительной обработки этого репозитория. Скрипт preprocess_snli.py может использоваться для предварительной обработки snli, preprocess_mnli.py для предварительного обработки Multinli и Preprocess_bnli.py , чтобы предварительно обрабатывать набор данных NLI (BNLI). Обратите внимание, что при вызове сценария Bnli данные SNLI должны были быть предварительно обработаны, чтобы на BNLI можно было использовать WordDict, созданный для него.
Использование сценариев является следующим (замените * на SNLI , MNLI или BNLI ):
preprocess_*.py [-h] [--config CONFIG]
где config - это путь к файлу конфигурации, определяющим параметры, которые будут использоваться для предварительной обработки. Файлы конфигурации по умолчанию можно найти в папке Config/Preprocessing этого репозитория.
Поезд _*. Сценарии PY в папке сценариев/обучения могут использоваться для обучения модели ESIM на некоторых учебных данных и проверки ее на некоторых данных проверки.
Использование сценария является следующим (замените * на snli или mnli ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
где config - это файл конфигурации (по умолчанию находятся в папке конфигурации/обучения ), а checkpoint - дополнительная контрольная точка, из которой можно возобновить обучение. Контрольные точки создаются сценарием после каждой эпохи обучения с именем Esim _*. Pth.TAR , где '*' указывает номер эпохи.
Тест _*. Сценарии PY в папке сценариев/тестирования могут использоваться для тестирования модели ESIM, предварительно проведенной на некоторых тестовых данных.
Чтобы проверить на SNLI, используйте скрипт test_snli.py следующим образом:
test_snli.py [-h] test_data checkpoint
где test_data - это путь к некоторому предварительному набору тестов, а checkpoint - это путь к контрольной точке, созданному сценарием Train_snli.py (либо один из контрольных точек, созданных после тренировочных эпох, или лучшую модель, которую можно увидеть во время обучения, которая сохраняется в данных/контрольно -пропускных пунктах/snli/best.pth.tar - разница между eSim _*. что последнее не может быть использовано для возобновления обучения, поскольку он не содержит состояния оптимизатора).
Сценарий test_snli.py также может использоваться в наборе данных о разрыве NLI с моделью, предварительно проведенным на SNLI.
Чтобы проверить на Multinli, используйте скрипт test_mnli.py следующим образом:
test_mnli.py [-h] [--config CONFIG] checkpoint
где config - это файл конфигурации (один доступен по умолчанию в конфигурации/тестировании ), а checkpoint - контрольная точка, созданная сценарием Train_mnli.py .
Сценарий test_mnli.py делает прогнозы на соответствующих и несоответствующих тестовых наборах Multinli и сохраняет их в файлах .csv. Чтобы получить точность классификации, связанную с прогнозами модели, файлы .csv, которые он создает, необходимо представить на соревнования Kaggle для Multinli.
Модель, предварительно обученная SNLI, доступна в папке данных/контрольных точек/SNLI этого репозитория. Модель была обучена параметрам, определенным в файлах конфигурации по умолчанию, представленным в config/ . Чтобы проверить это, просто выполните python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar из папки сценариев/тестирования .
Предварительная модель достигает следующей производительности в наборе данных SNLI:
| Расколоть | Точность (%) |
|---|---|
| Тренироваться | 93.2 |
| Девчонка | 88.4 |
| Тест | 88.0 |
Результаты соответствуют результатам, представленным в статье Chen et al.
В рамках набора данных NLI, опубликованном Glockner et al. В 2018 году модель достигает 65,5% точности, как сообщается в статье.
На Multinli модель достигает следующей точности:
| Расколоть | Соответствует | Несоответствующий |
|---|---|---|
| Девчонка | 77,0 % | 76,8 % |
| Тест | 76,6 % | 75,8 % |
Эти результаты немного выше того, что сообщили Williams et al. в их многофункциональной бумаге.


