ESIM
1.0.0
Mise en œuvre du modèle ESIM pour l'inférence du langage naturel avec Pytorch
Ce référentiel contient une implémentation avec Pytorch du modèle séquentiel présenté dans l'article "LSTM amélioré pour l'inférence du langage naturel" par Chen et al. en 2016.
La figure ci-dessous illustre une vue de haut niveau de l'architecture du modèle.
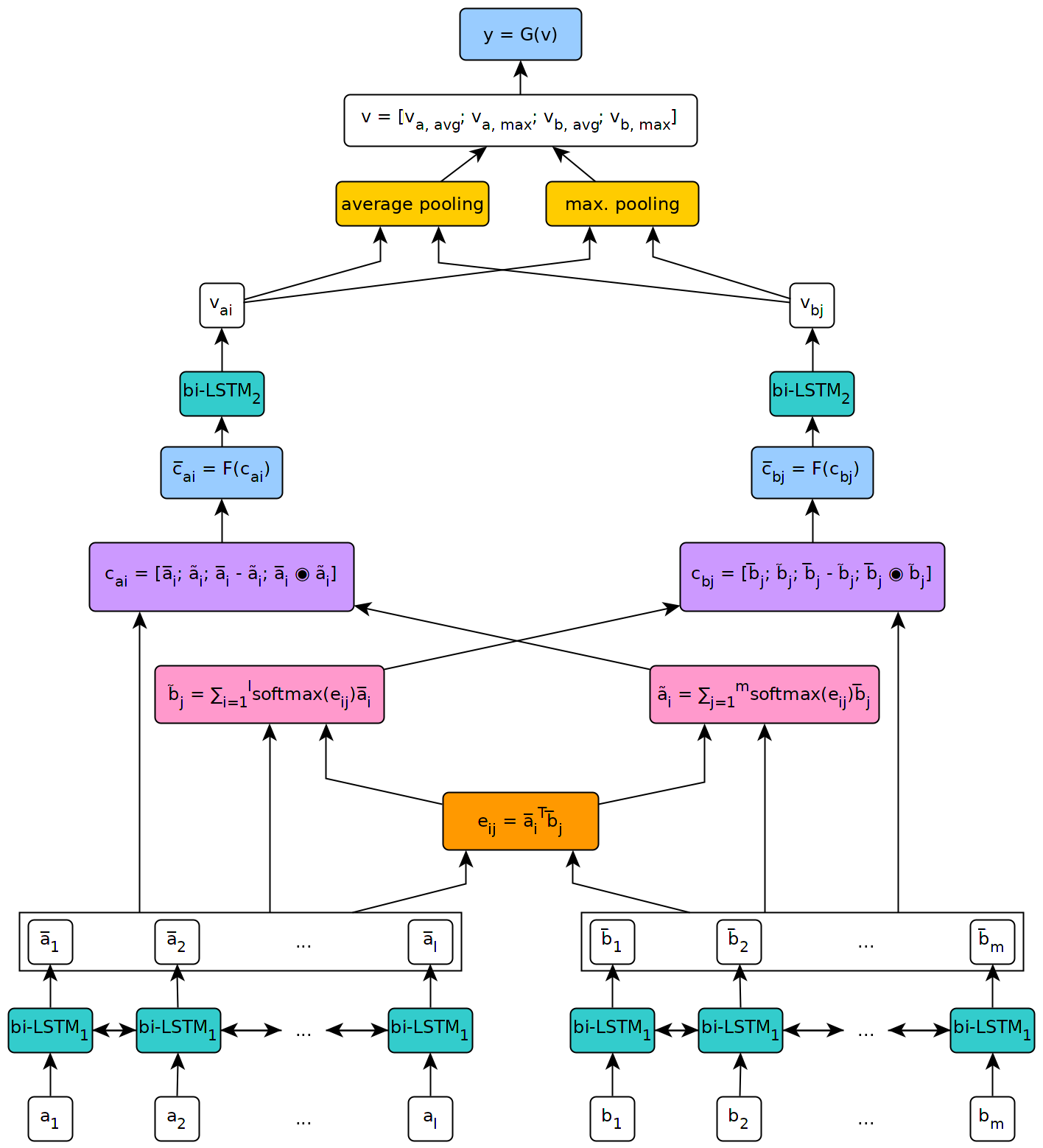
Ce modèle a été mis en œuvre dans le contexte de ma thèse de maîtrise à l'Université de Genève.
Pour utiliser le modèle défini dans ce référentiel, vous devrez d'abord installer Pytorch sur votre machine en suivant les étapes décrites sur la page officielle du package (cette étape n'est nécessaire que si vous utilisez Windows). Ensuite, pour installer les dépendances nécessaires pour exécuter le modèle, exécutez simplement la commande pip install --upgrade . De l'intérieur du référentiel cloné (à la racine, et de préférence à l'intérieur d'un environnement virtuel).
Le script fetch_data.py situé dans les scripts / dossier de ce référentiel peut être utilisé pour télécharger un ensemble de données NLI et des incorporations de mots pré-entraînés. Par défaut, le script récupère le corpus SNLI et les incorporations Glove 840B 300D. D'autres ensembles de données peuvent être téléchargés en faisant simplement passer leur URL comme argument au script (par exemple, l'ensemble de données MultnLI).
L'utilisation du script est la suivante:
fetch_data.py [-h] [--dataset_url DATASET_URL]
[--embeddings_url EMBEDDINGS_URL]
[--target_dir TARGET_DIR]
où target_dir est le chemin d'accès à un répertoire où les données téléchargées doivent être enregistrées (par défaut à ../data/ ).
Pour Multinli, les ensembles de tests correspondants et dépareillés doivent être téléchargés manuellement à partir de Kaggle et les fichiers .txt correspondants copiés dans le dossier de jeu de données multinli_1.0 .
Avant que le corpus et les intégres téléchargés puissent être utilisés dans le modèle ESIM, ils doivent être prétraités. Cela peut être fait avec le prétraitement _ *. Py Scripts dans le dossier scripts / prétraitement de ce référentiel. Le script Preprocess_Snli.py peut être utilisé pour prétraiter SNLI, Preprocess_mnli.py pour prétraiter Multinli et Preprocess_Bnli.py pour prétraiter l'ensemble de données NLI (BNLI). Notez que lors de l'appel du script fot bnli, les données SNLI auraient dû être prétraitées en premier, de sorte que le mot produit pour lui puisse être utilisé sur BNLI.
L'utilisation des scripts est la suivante (remplacez le * par SNLI , MNLI ou BNLI ):
preprocess_*.py [-h] [--config CONFIG]
où config est le chemin d'accès à un fichier de configuration définissant les paramètres à utiliser pour le prétraitement. Les fichiers de configuration par défaut peuvent être trouvés dans le dossier Config / Prétraitement de ce référentiel.
Le train _ *. Les scripts PY dans le dossier Scripts / formation peuvent être utilisés pour former le modèle ESIM sur certaines données de formation et les valider sur certaines données de validation.
L'utilisation du script est la suivante (remplacer le * par SNLI ou MNLI ):
train_*.py [-h] [--config CONFIG] [--checkpoint CHECKPOINT]
où config est un fichier de configuration (les par défaut sont situés dans le dossier Config / formation ) et checkpoint est un point de contrôle facultatif à partir duquel la formation peut être reproduite. Les points de contrôle sont créés par le script après chaque époque d'entraînement, avec le nom esim _ *. Pth.tar , où '*' indique le numéro de l'époque.
Le test _ *. Les scripts PY dans le dossier scripts / test peuvent être utilisés pour tester un modèle ESIM pré-entraîné sur certaines données de test.
Pour tester sur SNLI, utilisez le script test_snli.py comme suit:
test_snli.py [-h] test_data checkpoint
Lorsque test_data est le chemin d'accès à un ensemble de tests prétraité, et checkpoint est le chemin vers un point de contrôle produit par le script Train_snli.py (l'un des points de contrôle créés après les époques de formation, ou le meilleur modèle vu pendant la formation, qui est enregistré dans les données / points de contrôle / snli / best.pth.tar - la différence entre le latte . ne peut pas être utilisé pour reprendre la formation, car il ne contient pas l'état de l'optimiseur).
Le script test_snli.py peut également être utilisé sur l'ensemble de données NLI brisé avec un modèle pré-entraîné sur SNLI.
Pour tester sur Multinli, utilisez le script test_mnli.py comme suit:
test_mnli.py [-h] [--config CONFIG] checkpoint
où config est un fichier de configuration (un par défaut est disponible en config / test ) et checkpoint est un point de contrôle produit par le script Train_mnli.py .
Le script test_mnli.py fait des prédictions sur les ensembles de tests correspondants et dépareillés de Multinli et les enregistre dans des fichiers .csv. Pour obtenir la précision de classification associée aux prédictions du modèle, les fichiers .csv qu'il produit doivent être soumis aux compétitions de Kaggle pour Multinli.
Un modèle pré-formé sur SNLI est mis à disposition dans le dossier Data / Checkpoints / SNLI de ce référentiel. Le modèle a été formé avec les paramètres définis dans les fichiers de configuration par défaut fournis dans config / . Pour le tester, exécutez simplement python test_snli.py ../../preprocessed/SNLI/test_data.pkl ../../data/checkpoints/best.pth.tar à partir du dossier scripts / test .
Le modèle pré-entraîné réalise les performances suivantes sur l'ensemble de données SNLI:
| Diviser | Précision (%) |
|---|---|
| Former | 93.2 |
| Dev | 88.4 |
| Test | 88.0 |
Les résultats sont conformes à ceux présentés dans l'article par Chen et al.
Sur l'ensemble de données NLI Breaking, publié par Glockner et al. En 2018, le modèle atteint une précision de 65,5% , comme indiqué dans le document.
Sur Multinli, le modèle atteint la précision suivante:
| Diviser | Assorti | Incomparable |
|---|---|---|
| Dev | 77,0% | 76,8% |
| Test | 76,6% | 75,8% |
Ces résultats sont légèrement supérieurs à ce qui a été rapporté par Williams et al. Dans leur papier multinli.


