bert_language_understanding
1.0.0
伯特最近在10个以上的NLP任务上实现了新的最新结果。
这是深层双向变压器的预训练的张量实现,以了解语言
(伯特)和注意力是您所需要的(变压器)。
更新:这两篇论文的重复主要思想的大部分部分已经完成,表现显而易见
对于预训练,模型和微调比较从头开始训练模型。
我们已经完成了实验,以替换从变压器到TextCNN的BERT的骨干网络,结果是
使用大量原始数据使用屏蔽语言模型预先培训模型可以以显着的数量提高性能。
更普遍地,我们认为,预训练和微调策略独立于模型独立和预训练任务。
话虽如此,您可以根据需要替换骨干网络。并添加更多的预训练任务或将一些新的预训练任务定义为
您可以,预训练将不仅限于蒙版语言模型,也不会预测下一个句子任务。我们感到惊讶的是,
有一个中间尺寸数据集,即在预训练任务的帮助下,即使不使用外部数据,也没有使用外部数据
像蒙版语言模型一样,性能可以大大提高,并且该模型甚至可以快速收敛。有时
在微调阶段,训练只需几个时代。
虽然有开源(Tensor2Tensor)和官方
Transformer和BERT官方实施的实施即将到来,但可能会/可能很难阅读,不容易理解。
我们不是要完全复制原始论文,而是要以更好的方式应用主要想法并解决NLP问题。
FO工作的大部分部分是由去年另一个存储库完成的:文本分类
中型数据集(Cail2018,450k)
| 模型 | textcnn(无预告片) | textcnn(预处理) | 从预训练中获得 |
|---|---|---|---|
| 1个时期后的F1得分 | 0.09 | 0.58 | 0.49 |
| 5个时期后的F1得分 | 0.40 | 0.74 | 0.35 |
| 7个时期后的F1分数 | 0.44 | 0.75 | 0.31 |
| 35个时期后的F1得分 | 0.58 | 0.75 | 0.27 |
| 一开始训练损失 | 284.0 | 84.3 | 199.7 |
| 1个时期后的验证损失 | 13.3 | 1.9 | 11.4 |
| 5个时期后的验证损失 | 6.7 | 1.3 | 5.4 |
| 培训时间(单GPU) | 8H | 2H | 6H |
注意:
A.Fine-Tuning阶段在刚刚进行7个时期后完成了训练,因为Max Epoch达到35。
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
此处报告的C.F1分数是在验证集上,平均是F1得分的微观和宏。
在测试集上报告了35个时期后的d.f1分数。
e。从450k RAW文档中,检索了200万次培训数据的蒙版语言模型,
pre-train stage finished within 5 hours in single GPU.
预先训练后进行微调:
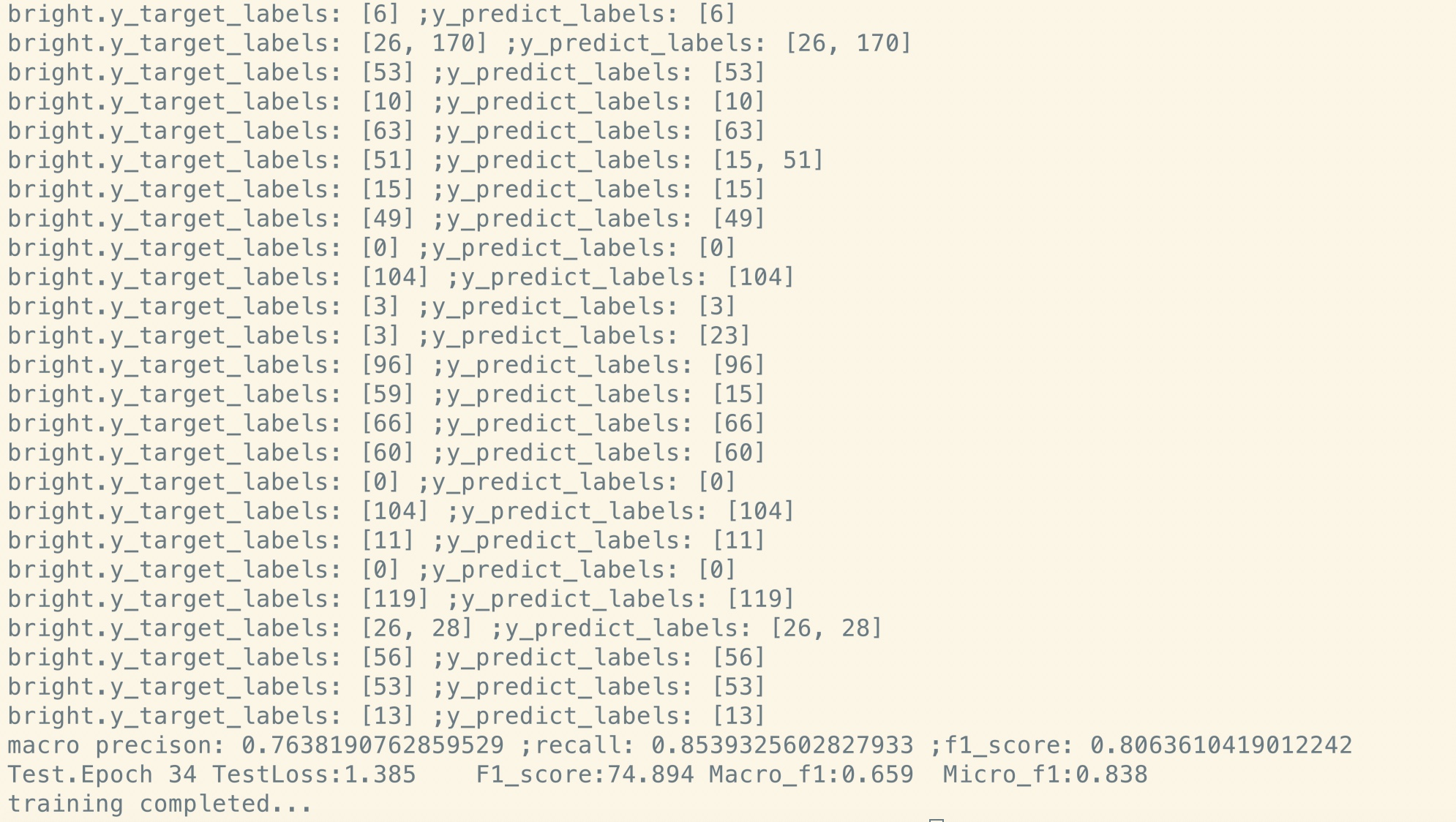
没有预训练:
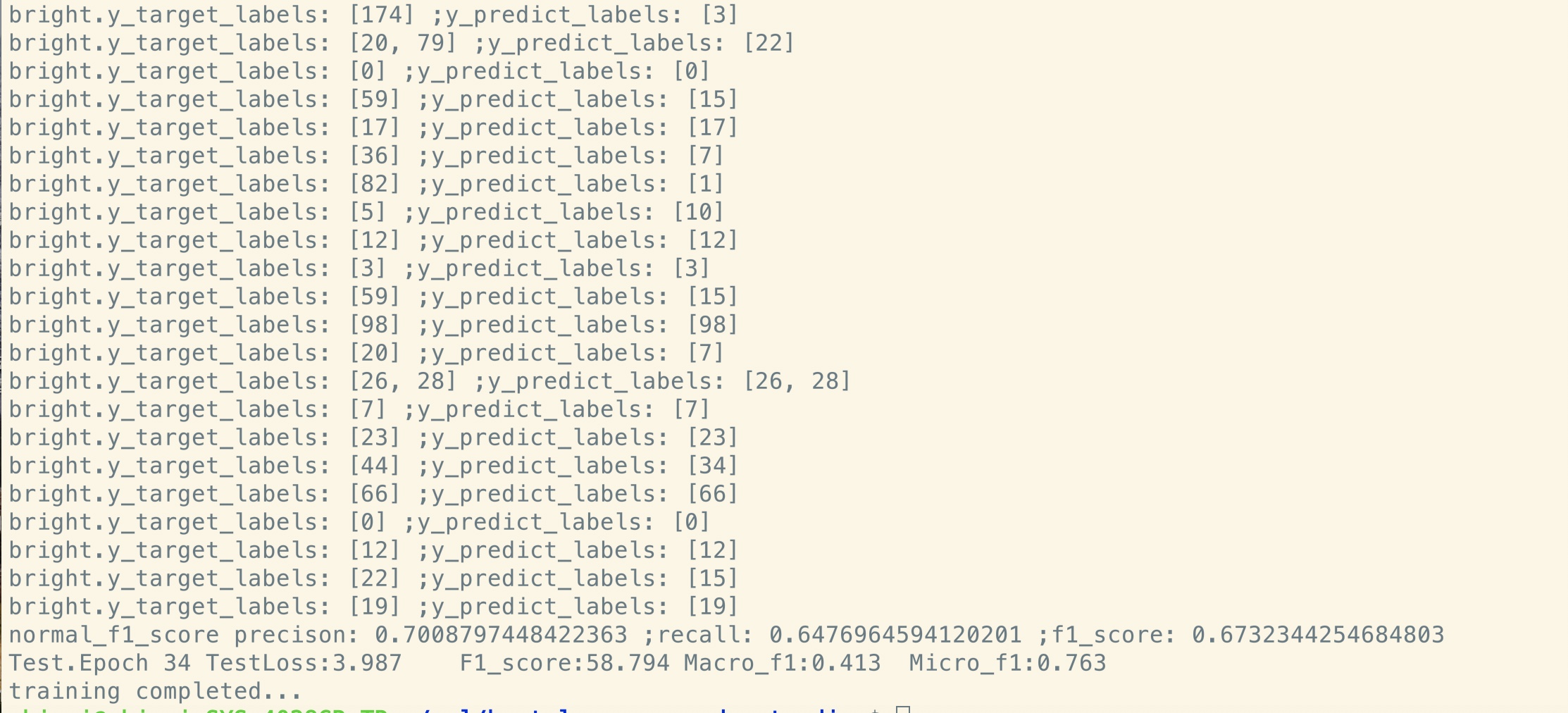
小型数据集(私人,100k)
| 模型 | textcnn(无预告片) | textcnn(预处理) | 从预训练中获得 |
|---|---|---|---|
| 1个时期后的F1得分 | 0.44 | 0.57 | 10%+ |
| 1个时期后的验证损失 | 55.1 | 1.0 | 54.1 |
| 一开始训练损失 | 68.5 | 8.2 | 60.3 |
如果您想尝试使用蒙版语言模型和微调的预培训的BERT。采取两个步骤:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
如您所见,即使在微调的起点,在预训练模型的还原参数之后,模型的丢失也较小
比全新的训练和F1分数也更高,而新型号可能从0开始。
注意:要帮助您首先尝试新想法,您可以将Hyper-Paramater Test_mode设置为true。它只会加载少量数据,并开始快速培训。
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_Model:模型的维度。 [512]
num_layer:图层数。 [6]
num_header:自我注意力的标题数[8]
D_K:键(K)的尺寸。查询(Q)的维度相同。 [64]
D_V:V的维度。[64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
每行都是文档(几个句子)或句子。那是自由文本,您可以轻松获得。
在zip文件中检查数据/bert_train.txt或bert_train2.txt。
输入和输出在同一条线上,每个标签以“标签”开头。
在输入字符串和第一个标签之间有一个空间,每个标签也被一个空间拆开。
例如token1 token2 token3 __label__l1 __label __l5 __label __l3
token1 token2 token3 __label__l2 __label__l4
在zip文件中检查数据/bert_train.txt或bert_train2.txt。
检查“数据”文件夹中的示例数据。在此处加载中间尺寸数据集
每个输入是450k 206类,平均长度约为300,一个或多标签与输入相关。
从Tencent AILAB下载嵌入式训练单词
事情很容易:
下载数据集(大约200m,450k数据,带有一些缓存文件),将其解压缩并将其放入数据/文件夹中,
运行步骤1进行预训练,
并运行第2步以进行微调。
我完成了三个步骤以上,并希望有更好的性能,我该怎么做。我需要找到一个大数据集吗?
否。您可以通过下载一些自由文本来生成一个大数据集,以便在预训练阶段
是文档或句子,然后用新数据文件替换数据/bert_train2.txt。
还有什么?
尝试一些大型参数或大型型号(通过替换骨干网络),您可以观察所有预训练数据。
播放模型:model/bert_cnn_model.py,或使用data_util_hdf5.py检查预处理。
预处理语言模型和大规模语料库的下一个句子预测任务,
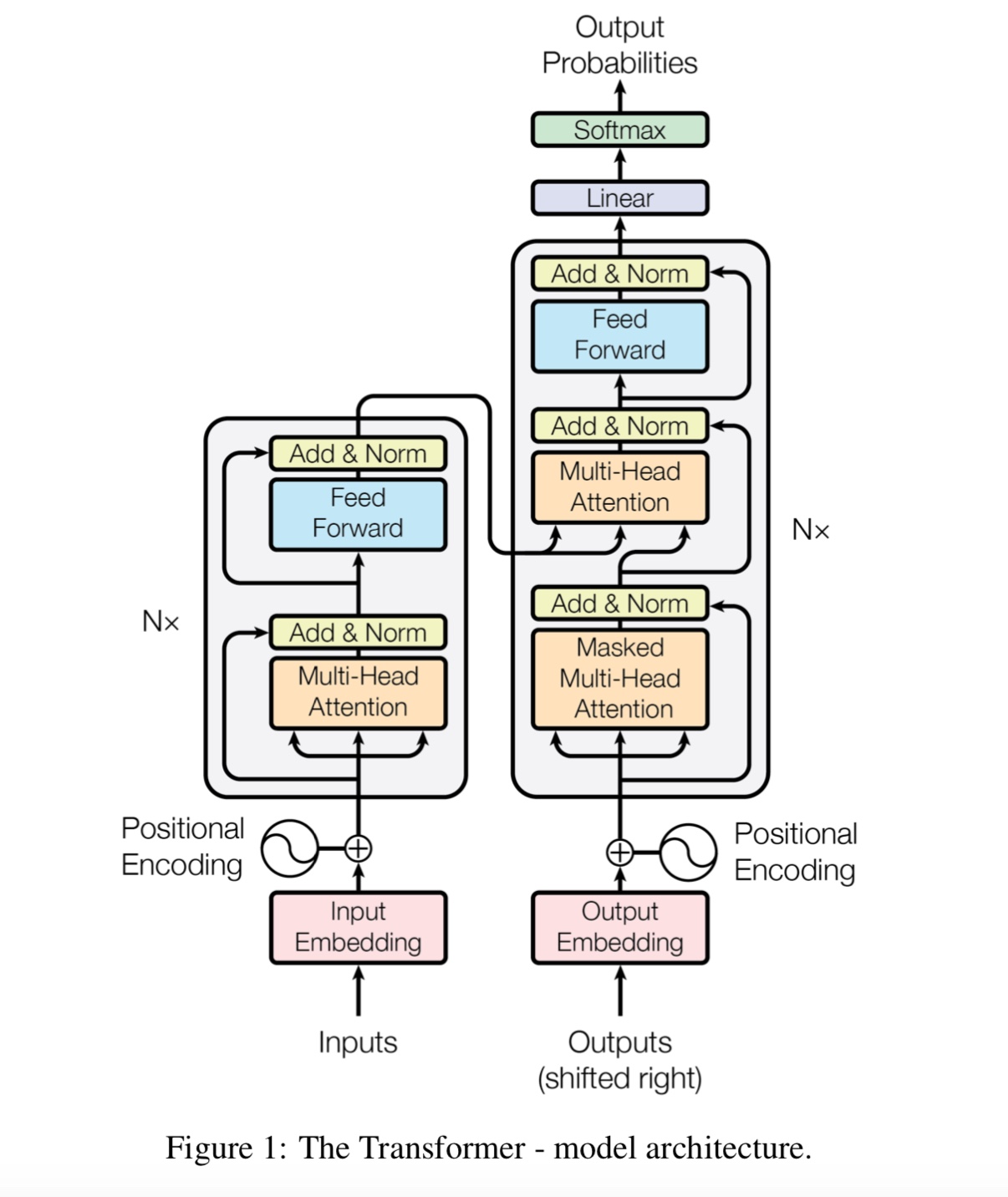
基于多层自我输入模型,然后通过添加分类层进行微调。
由于BERT模型是基于变压器的,因此目前,我们正在为模型添加预处理任务。
注意:CAIL2018约为450K,如上所述。
私人数据集的训练大小约为100K,类数为9,对于每个输入都有一个或多个标签。
CAIL2018的F1得分据报道为Micro F1分数。
基本想法非常简单。几年来,人们一直在作为语言模型获得很好的结果“预训练” DNN
然后对一些下游NLP任务进行微调(问题回答,自然语言推断,情感分析等)。
语言模型通常是从左到右的,例如:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
问题在于,对于通常不想要语言模型的下游任务,您需要最好的上下文表示
每个单词。如果每个单词只能看到左边的上下文,那么显然缺少很多。因此,人们所做的一个技巧也是训练
左右模型,例如:
P(store|</s>)*P(a|store </s>)*…
现在,您有两个单词的两种表示形式,一个从左到右和一个右至左的表示,您可以将它们串联在一起以完成下游任务。
但是从直觉上讲,如果我们可以训练一个深层双向的单个模型,那就更好了。
不幸的是,不可能训练像普通LM这样的深层双向模型,因为这会产生单词可以间接的周期
“看自己”,预测变得琐碎。
相反,我们可以做的是用于脱落自动编码器中的非常简单的技巧,我们从输入和
必须从上下文重建这些词。我们将其称为“蒙版LM”,但通常被称为披肩任务。
我们通过深层变压器编码器馈入输入,然后使用对应于蒙版位置对应的最终隐藏状态
预测什么词被掩盖,就像我们将训练语言模型一样。
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
如何获得最后一个隐藏的蒙版位置状态?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
有关更多详细信息,请检查Mask_language_model的方法
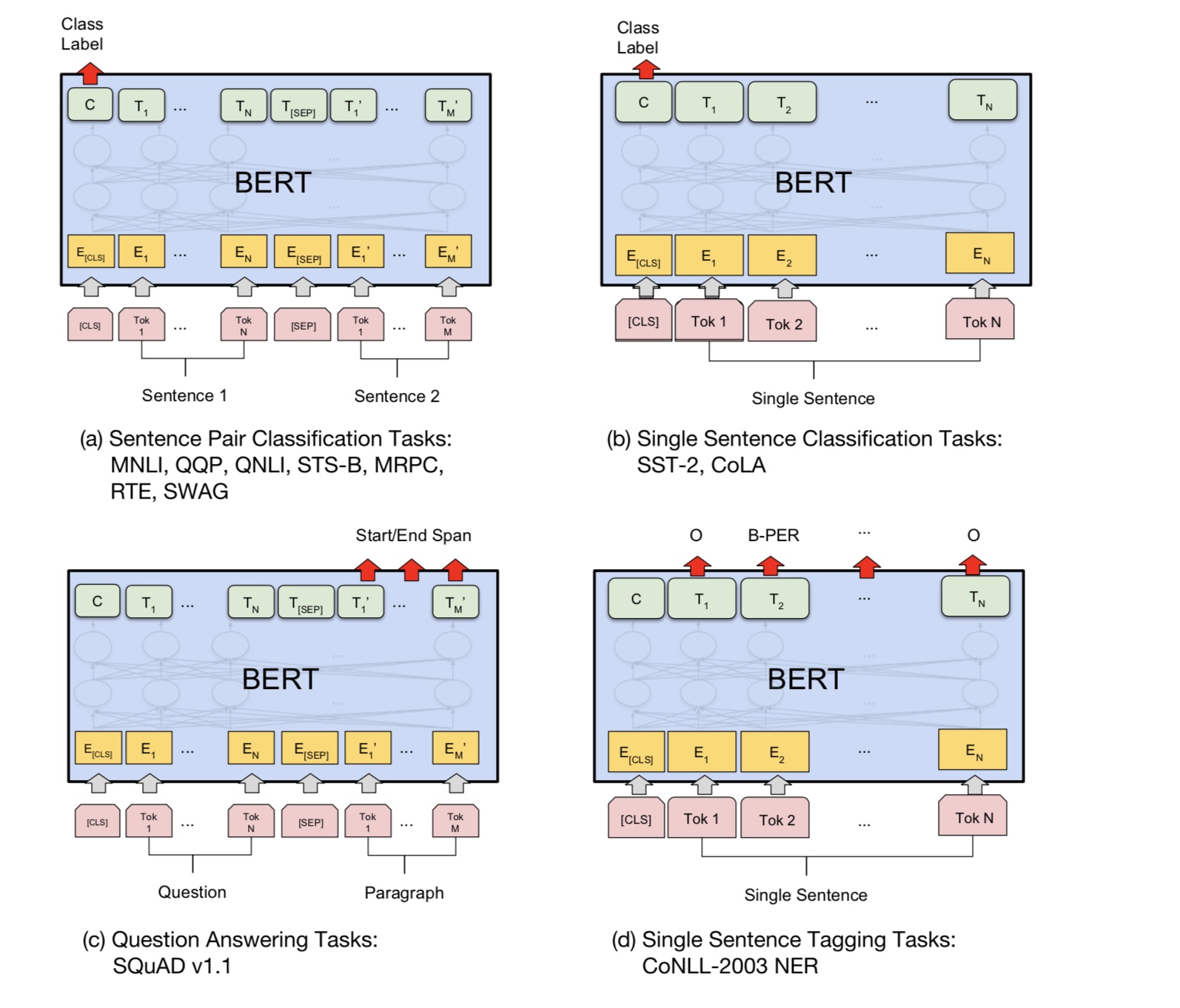
许多语言理解任务,例如问答,推论,需要理解关系
在句子之间。但是,语言模型只能在没有句子的情况下理解。下一个句子
预测是一项示例任务,可以帮助模型在这类任务中更好地理解。
机会的50%是第二句话的下一个句子,而不是下一个句子的50%。
给定两个句子,要求该模型预测第二句是否是真实的下一个句子
第一个。
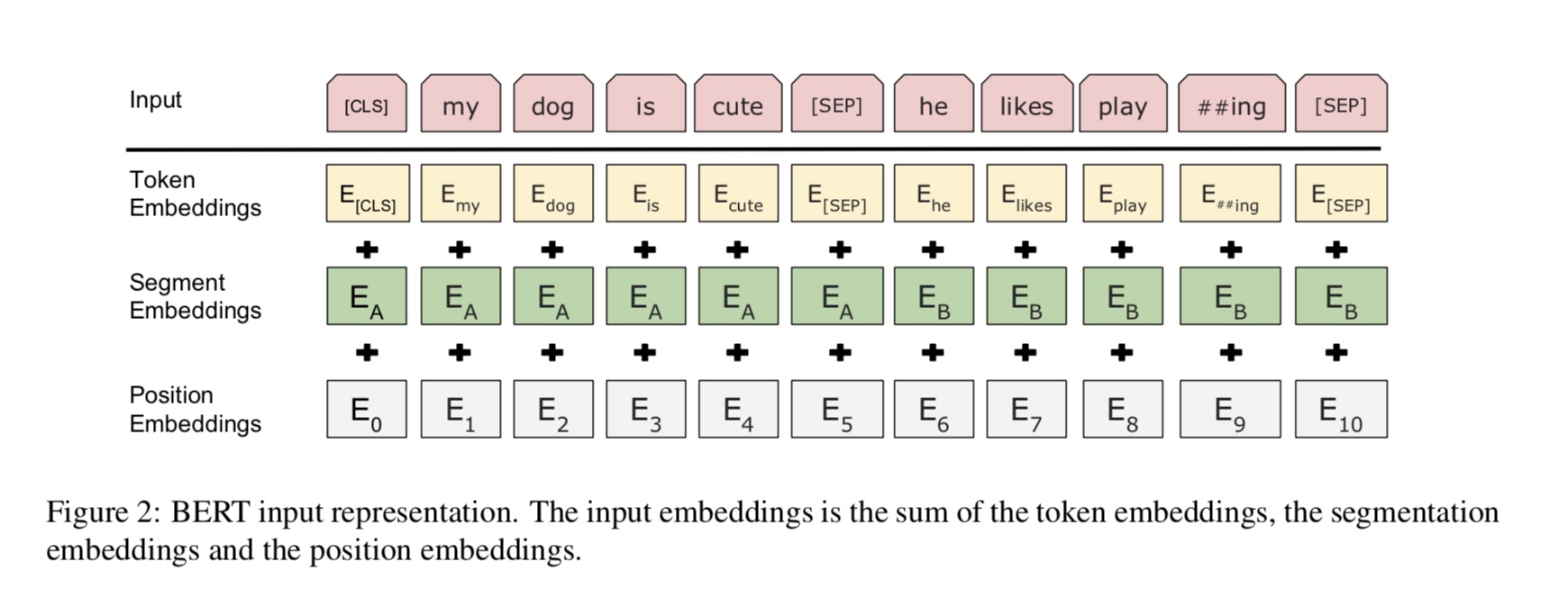
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
Python 3+张量1.10
在培训和微调阶段之间有什么共享和不共享?
1)基本上,预训练和微调阶段使用的骨干网络的所有参数彼此共享。
2)。我们可以尽可能地共享参数,以便在微调阶段我们需要学习很少
参数尽可能地共享了这两个阶段的单词嵌入。
3)。因此,大多数参数已经在微调阶段开始时被学到了。
我们如何实施蒙版语言模型?
为了使事情变得容易,我们从文档中生成句子,将其分成句子。对于每个句子
我们将其截断并填充到相同的长度,然后随机选择一个单词,然后用[mask],其自我和随机替换
单词。
如何使微调阶段提高效率,而不是打破结果和我们从培训阶段学到的知识?
我们在微调过程中使用较小的学习率,因此调整的程度很小。
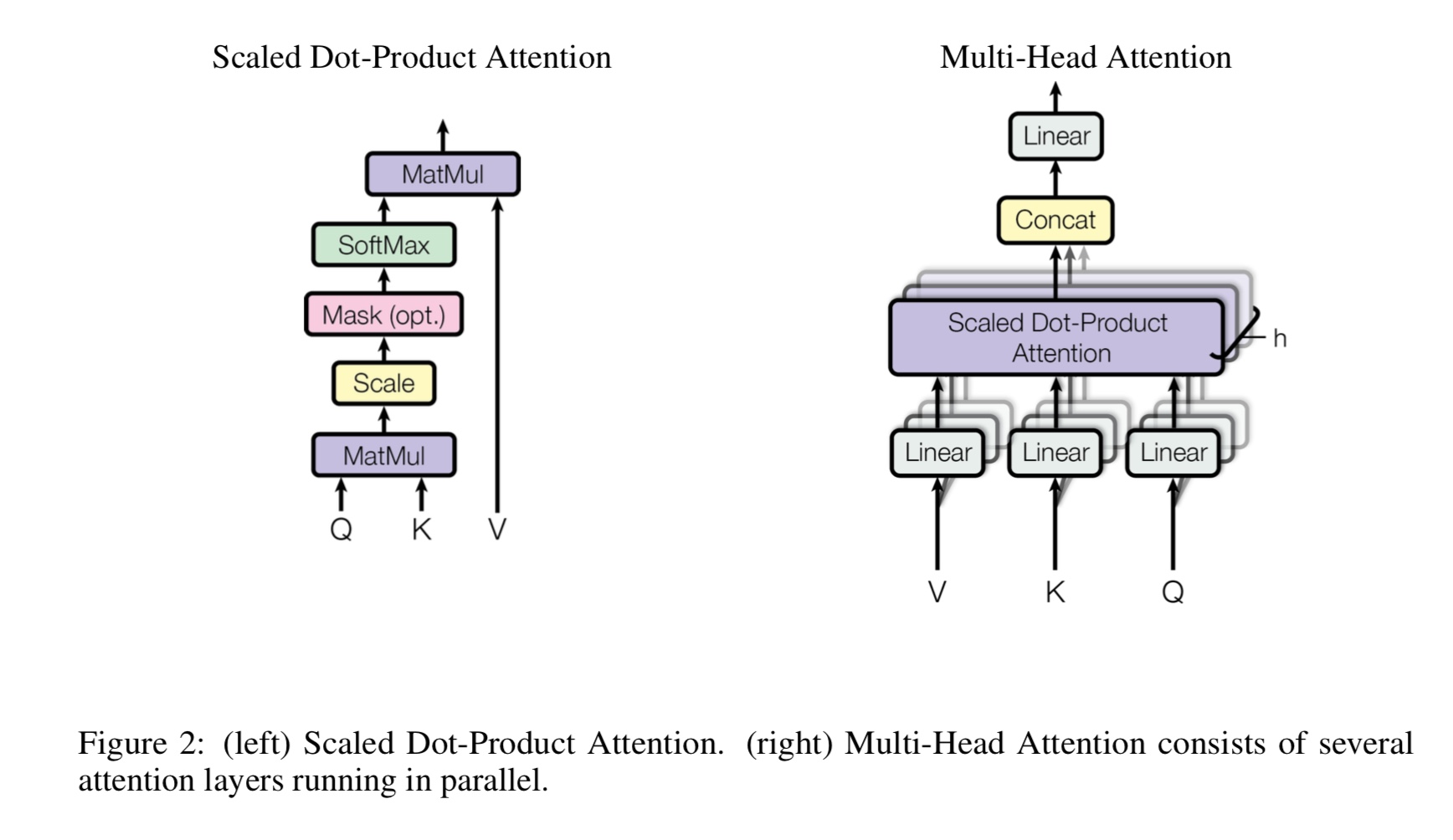
为什么我们需要自我注意?
自我发挥的新型网络最近引起了越来越多的关注。传统上,我们使用
RNN或CNN解决问题。但是,RNN并行存在问题,而CNN不擅长模型位置敏感任务。
自我注意力可以并行运行,同时能够建模长距离依赖性。
多头自我注意事项是什么,Q,K,V代表什么?在这里添加一些东西。
Mulit-Heads自我注意是一个自我注意力,而它将Q和K项目分为几个不同的子空间,
然后注意。
Q代表问题,K代表钥匙。对于机器翻译任务,Q是以前隐藏的解码状态,k表示
编码器的隐藏状态。 k的每个元素都将计算q的相似性得分。然后将使用SoftMax
要进行归一化分数,我们将获得权重。最后,通过使用权重计算加权总和适用于V。
但是,在自我注意的情况下,Q,K,V与任务输入序列的表示。
什么是位置的饲料?
它是一个进料前层,也称为完全连接(FC)层。但是由于在变压器中,所有的输入和输出
层是向量的序列:[sequence_length,d_model]。我们通常将FC进行输入矢量。所以我们再做一次,
但是不同的时间步骤有自己的FC。
伯特的主要贡献是什么?
虽然预训练任务已经存在了很多年,但它引入了一种新的方式(所谓的双向)来进行语言模型
并将其用于下流任务。由于语言模型的数据无处不在。事实证明它是强大的,因此重塑
NLP世界。
为什么作者在生成蒙版语言模型的培训数据时使用三种不同类型的令牌?
作者认为,在微调阶段没有[面具]令牌。因此,预训练和微调之间的不匹配。
它还迫使模型注意句子中的所有上下文信息。
是什么使BERT模型实现了新的技术导致语言理解任务?
大型模型,大型计算,最重要的是 - 新算法使用自由文本数据预处理模型。
玩具任务用于检查模型是否可以正常工作而不取决于实际数据。
它要求模型计数数字,并总结所有输入。并使用阈值
如果求和大于阈值(或少于阈值),则该模型需要将其预测为1(或0)。
内部模型/transform_model.py,有火车和预测方法。
首先,您可以运行Train()开始训练,然后运行Predive()以使用训练有素的模型开始预测。
由于模型非常大,因此具有默认的超参票(d_model = 512,h = 8,d_v = d_k = 64,num_layer = 6),因此需要大量数据才能收敛。
至少需要10k步骤,在损失小于0.1之前。如果您想用小训练
数据,您可以使用一组小型Parmeter(d_model = 128,h = 8,d_v = d_k = 16,num_layer = 6)
您可以使用两个求解二进制分类,多类分类或多标签分类问题。
它将在训练期间打印损失,并在验证期间为每个时期打印F1分数。
修复变压器中的错误[重要的是,招募团队成员并需要合并请求]
(变压器:为什么早期训练阶段的损失减少,但损失仍然不太小(例如损失= 8.0)?
更多的预训练数据,损失仍然不小)
支持句子对任务[重要,招募团队成员并需要合并请求]
添加下一个句子预测的预训练任务[重要,招募团队成员并需要合并请求]
需要一个数据集来进行情感分析或英语文本分类[重要的是,招募团队成员并需要合并请求]
位置嵌入尚未与预训练和微调之间共享。由于在训练前的阶段长度可能
比微调阶段短。
特殊处理第一个令牌[CLS]作为输入和分类[完成]
预先训练fine_tuning:需要从预训练阶段的代币的负载词汇量,但可以从实际任务上标记。 [完毕]
进行微调时的学习率应该较小。 [完毕]
预训练就是您所需要的。使用变压器或其他一些复杂的深层模型可以帮助您实现最佳性能
在某些任务中,使用大量的原始数据(然后在特定于任务数据集上微调模型,
将始终帮助您获得额外的表现。
在这里添加更多。
添加建议,问题或想做出贡献,欢迎与我联系:[email protected]
注意就是您所需要的
BERT:深层双向变压器的预训练以了解语言理解
Tensor2Tensor用于神经机器翻译
句子分类的卷积神经网络
CAIL2018:一个大规模的法律数据集用于判断预测


