bert_language_understanding
1.0.0
Bert erzielen in letzter Zeit neue hochmoderne Ergebnisse bei mehr als 10 NLP -Aufgaben.
Dies handelt
(Bert) und Aufmerksamkeit ist alles, was Sie brauchen (Transformator).
UPDATE: Der Mehrheitsteil der Replikat -Hauptideen dieser beiden Papiere wurde durchgeführt, es gibt einen offensichtlichen Leistungsgewinn
Für das Vor-Training ist ein Modell und ein Feinabstimmungsvergleich, um das Modell von Grund auf neu zu trainieren.
Wir haben experimentiert, um das Backbone -Netzwerk von Bert vom Transformator zu TextCNN zu ersetzen, und das Ergebnis ist, dass
Das Modell mit maskiertem Sprachmodell unter Verwendung vieler Rohdaten vorhanden kann die Leistung in einer bemerkenswerten Menge steigern.
Im Allgemeinen glauben wir, dass die Strategie vor dem Training und der Feinabstimmung modellunabhängig und vor dem Training unabhängig ist.
Nachdem dies gesagt wird, können Sie das Backbone -Netzwerk nach Belieben ersetzen. und fügen Sie weitere Aufgaben vor dem Training hinzu oder definieren Sie einige neue Vor-Training-Aufgaben als
Sie können, Pre-Train ist nicht auf maskiertes Sprachmodell beschränkt und / / oder die nächste Satzaufgabe vorhersagen. Was uns überrascht, ist das,
Mit einem Datensatz mit mittlerer Größe, der eine Million auch ohne Verwendung externer Daten mithilfe der Vor-Training-Aufgabe
Wie das maskierte Sprachmodell kann die Leistung in einem großen Rand erhöht werden und das Modell kann sogar schnell konvergieren. irgendwann
Das Training kann in der Feinabstimmung nur ein paar Epoche benötigen.
Während es eine Open Source (Tensor2tensor) und offiziell gibt
Implementierung der offiziellen Umsetzung von Transformer und Bert erfolgt bald, aber es gibt/Mai schwer zu lesen, nicht leicht zu verstehen.
Wir sind nicht beabsichtigt, Originalarbeiten vollständig zu replizieren, sondern die Hauptideen anzuwenden und das NLP -Problem besser zu lösen.
Der Mehrheitsteil für die Arbeit hier wurde im letzten Jahr von einem anderen Repository durchgeführt: Textklassifizierung
Datensatz mittlerer Größe (Cail2018, 450k)
| Modell | Textcnn (No-Presen) | Textcnn (vorab-finetuning) | Gewinn aus vor dem Training |
|---|---|---|---|
| F1 -Score nach 1 Epoche | 0,09 | 0,58 | 0,49 |
| F1 -Score nach 5 Epoche | 0,40 | 0,74 | 0,35 |
| F1 -Score nach 7 Epoche | 0,44 | 0,75 | 0,31 |
| F1 -Score nach 35 Epoche | 0,58 | 0,75 | 0,27 |
| Trainingsverlust am Anfang | 284.0 | 84.3 | 199.7 |
| Validierungsverlust nach 1 Epoche | 13.3 | 1.9 | 11.4 |
| Validierungsverlust nach 5 Epoche | 6.7 | 1.3 | 5.4 |
| Trainingszeit (Single GPU) | 8h | 2H | 6h |
Beachten:
Die A.-Fine-Tuning-Bühne absolvierte das Training, nachdem er gerade 7 Epoche als Max-Epoche auf 35 erreichte.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
Der hier gemeldete C.F1 -Score befindet sich im Validierungssatz, ein Durchschnitt des Micro- und Makros der F1 -Score.
D.F1 -Score nach 35 Epoche wird am Testsatz gemeldet.
e. Ab 450.000 Rohdokumenten wurden 2 Millionen Trainingsdaten für maskiertes Sprachmodell abgerufen,
pre-train stage finished within 5 hours in single GPU.
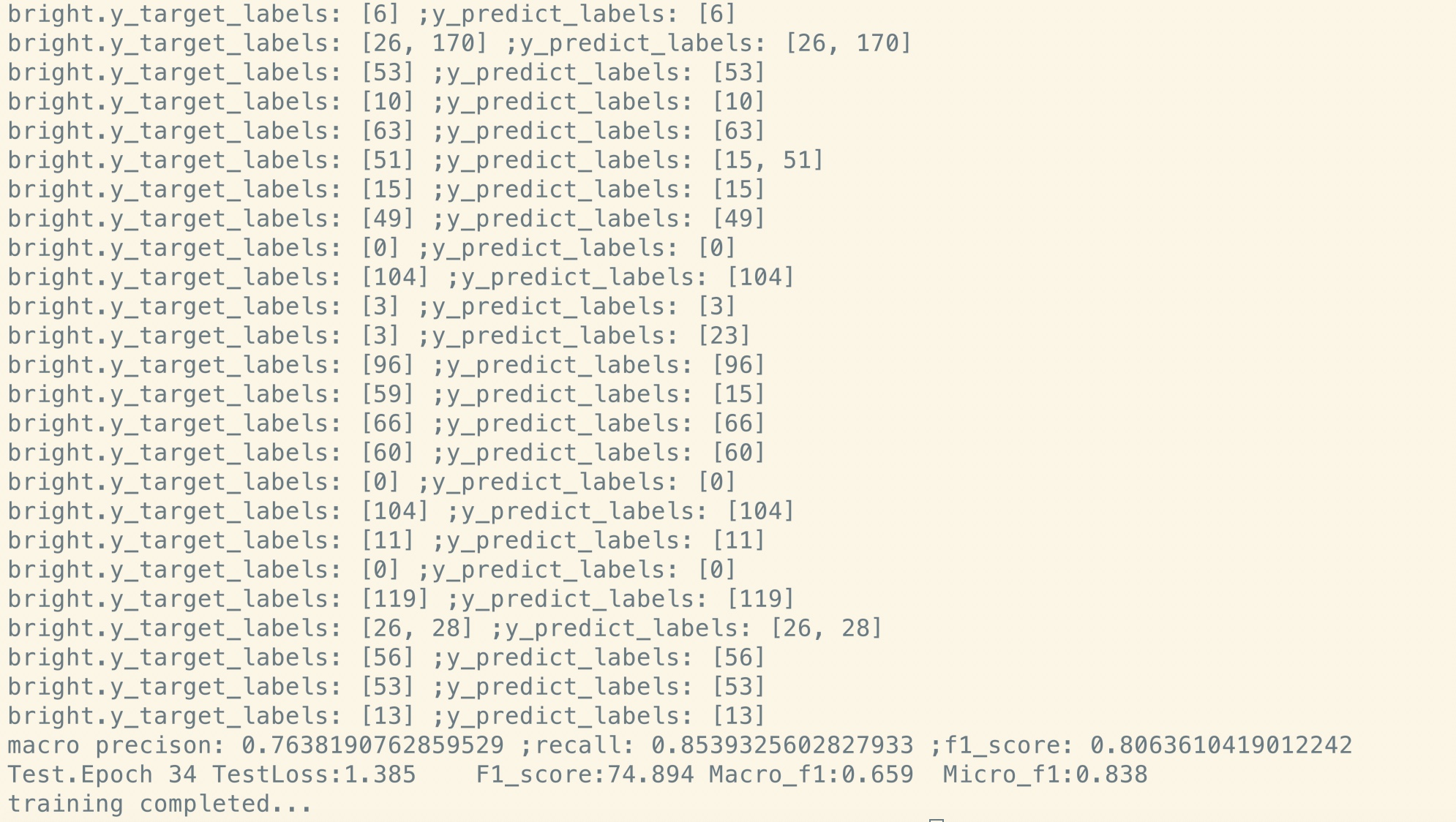
Feinabstimmung nach dem Vor-Training:
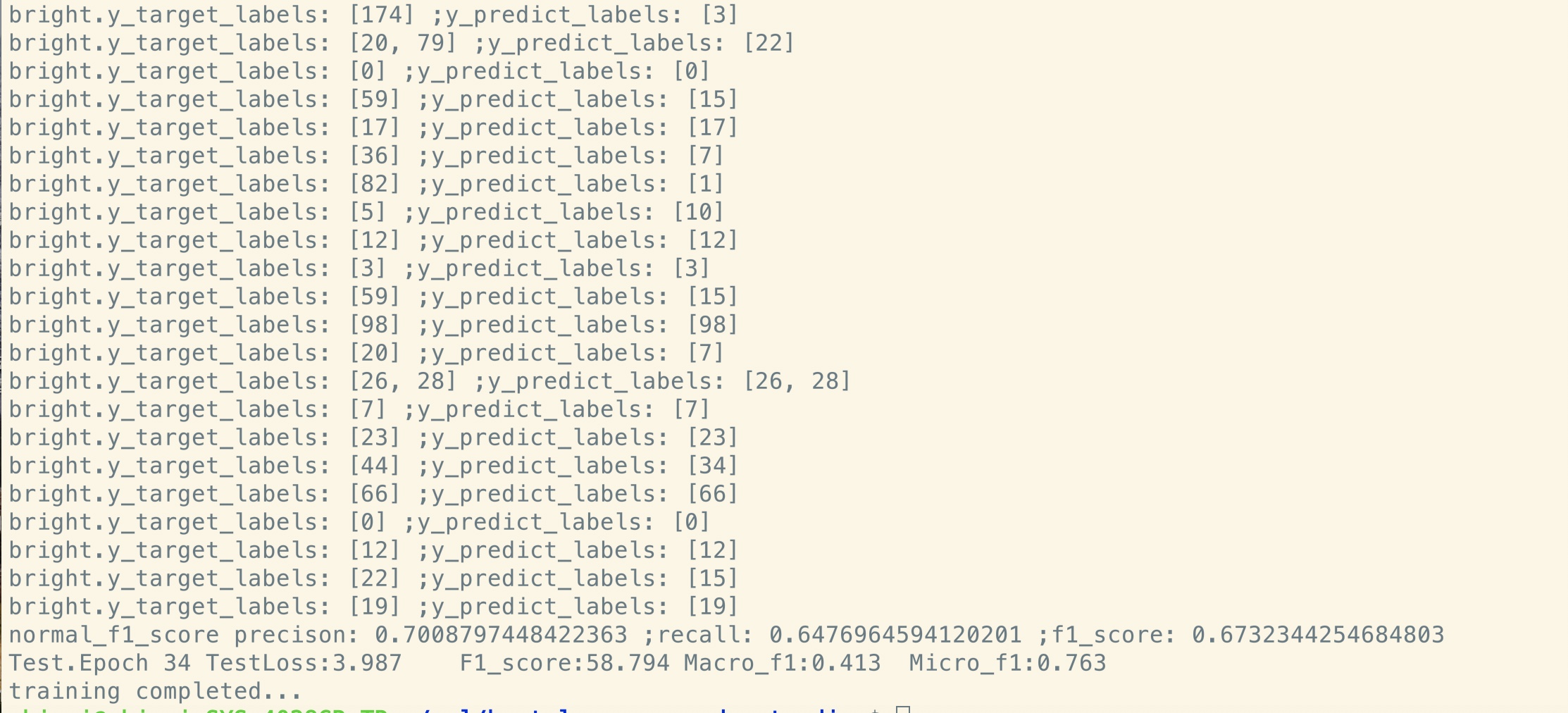
Kein Vor-Training:
Kleiner Datensatz (privat, 100k)
| Modell | Textcnn (No-Presen) | Textcnn (vorab-finetuning) | Gewinn aus vor dem Training |
|---|---|---|---|
| F1 -Score nach 1 Epoche | 0,44 | 0,57 | 10%+ |
| Validierungsverlust nach 1 Epoche | 55.1 | 1.0 | 54.1 |
| Trainingsverlust am Anfang | 68,5 | 8.2 | 60.3 |
Wenn Sie Bert mit dem Vorverfahren aus maskiertem Sprachmodell und Feinabstimmung ausprobieren möchten. zwei Schritte machen:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Wie Sie sehen können, ist der Verlust des Modells selbst am Startpunkt der Feinabstimmung kurz nach der Wiederherstellungsparametern aus dem vorgeborenen Modell kleiner
als das Training aus völlig neu und der F1 -Score ist ebenfalls höher, während ein neues Modell von 0 beginnen kann.
Hinweis: Um Ihnen zuerst eine neue Idee auszuprobieren, können Sie Hyper-Paramater test_mode auf true einstellen. Es wird nur wenige Daten geladen und beginnt schnell mit dem Training zu trainieren.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_Model: Dimension des Modells. [512]
num_layer: Anzahl der Schichten. [6]
Num_header: Anzahl der Header der Selbstbekämpfung [8]
D_K: Dimension von Key (k). Die Dimension der Abfrage (q) ist gleich. [64]
D_V: Dimension von V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Jede Zeile ist Dokument (mehrere Sätze) oder ein Satz. Das ist freien Text, den Sie leicht bekommen können.
Überprüfen Sie in der ZIP -Datei data/bert_train.txt oder bert_train2.txt.
Eingang und Ausgabe befinden sich in derselben Zeile, jede Etikett wird mit ' Etikett ' begonnen.
Es gibt einen Speicherplatz zwischen der Eingangszeichenfolge und der ersten Etikett. Jede Etikett wird auch durch einen Speicherplatz aufgeteilt.
zB token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
Überprüfen Sie in der ZIP -Datei data/bert_train.txt oder bert_train2.txt.
Überprüfen Sie den Ordner "Daten" auf Beispieldaten. Laden Sie hier einen Datensatz mit mittlerer Größe herunter
Bei 450K 206-Klassen ist jeder Eingang ein Dokument, die durchschnittliche Länge beträgt etwa 300, eine oder Multi-Label, die mit Eingaben assoziiert sind.
Laden Sie das Einbetten vor dem Training vor Tencent Ailab herunter
Dinge können einfach sein:
Laden Sie den Datensatz (ca. 200 m, 450.000 Daten, mit einer Cache -Datei) herunter, entpacken Sie sie und legen Sie sie in Daten/ Ordner ein.
Schritt 1 für vor dem Training ausführen,
und Schritt 2 für die Feinabstimmung ausführen.
Ich beende über drei Schritte und möchte eine bessere Leistung haben, wie kann ich weiter machen? Muss ich einen großen Datensatz finden?
Nein. Sie können selbst einen Big-Data-Set für die Bühne vor dem Trainer generieren, indem Sie einen Freistaat herunterladen. Stellen Sie sicher, dass jede Zeile sicherstellen
ist ein Dokument oder Satz, dann ersetzen Sie dann Daten/Bert_Train2.txt durch Ihre neue Datendatei.
Was ist mehr?
Probieren Sie ein großes Hyper-Parameter oder ein großes Modell (indem Sie das Backbone-Netzwerk ersetzen).
Spielen Sie mit Modell: modell/bert_cnn_model.py oder prüfen Sie die Vorverarbeitung mit data_util_hdf5.py.
Vorbereitungsmodell und Nächste Satzvorhersageaufgabe auf großer Skala von Korpus,
Basierend auf dem Selbstanpassungsmodell mehrerer Ebenen fein abzusetzen, indem Sie eine Klassifizierungsschicht hinzufügen.
Da das Bert -Modell auf Transformator basiert, arbeiten wir derzeit daran, dem Modell die Aufgabe von Vorab -Vorlagen hinzuzufügen.
Hinweis: CAIL2018 ist etwa 450 km wie die obige Verbindung.
Die Schulungsgröße des privaten Datensatzes beträgt rund 100.000, die Anzahl der Klassen ist 9, für jede Eingabe gibt es eine oder mehrere Etiketten.
Der F1 -Score für CAIL2018 wird als Micro F1 -Score angegeben.
Die Grundidee ist sehr einfach. Seit mehreren Jahren erhalten die Menschen sehr gute Ergebnisse als Sprachmodell "Vorausbildung" als Sprachmodell
und dann eine Feinabstimmung einer nachgelagerten NLP-Aufgabe (Fragenbeantwortung, Inferenz für natürliche Sprache, Stimmungsanalyse usw.).
Sprachmodelle sind in der Regel von links nach rechts, z. B.: zB:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
Das Problem ist, dass Sie für die nachgeschaltete Aufgabe normalerweise kein Sprachmodell möchten, die bestmögliche Kontextdarstellung von
Jedes Wort. Wenn jedes Wort nur einen Kontext links sehen kann, fehlt eindeutig viel. Ein Trick, den die Leute getan haben, ist auch, a zu trainieren
Recht nach links, z. B.:
P(store|</s>)*P(a|store </s>)*…
Jetzt haben Sie zwei Darstellungen jedes Wortes, einen von links nach rechts und einen rechts nach links, und Sie können sie für Ihre nachgeschaltete Aufgabe zusammenschließen.
Aber intuitiv wäre es viel besser, wenn wir ein einzelnes Modell trainieren könnten, das zutiefst bidirektional war.
Es ist leider unmöglich, ein tiefes bidirektionales Modell wie ein normales LM zu trainieren, da dies Zyklen erzeugen würde, in denen Wörter indirekt
"Sehen Sie sich selbst" und die Vorhersagen werden trivial.
Was wir stattdessen tun können, ist der sehr einfache Trick, der bei De-Noising-Auto-Codern verwendet wird, wo wir einige Prozent der Wörter aus der Eingabe maskieren und
müssen diese Wörter aus dem Kontext rekonstruieren. Wir nennen dies eine "maskierte LM", aber es wird oft als Lückleaufgabe bezeichnet.
Wir füttern die Eingabe durch einen tiefen Transformator -Encoder und verwenden dann die endgültigen versteckten Zustände, die den maskierten Positionen entsprechen
Vorhersage, welches Wort maskiert wurde, genau wie wir ein Sprachmodell trainieren würden.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Wie bekomme ich den letzten versteckten Zustand maskierter Position (en)?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Weitere Details finden Sie unter mask_language_model von pretrain_task.py und train_vert_lm.py
Viele Sprachverständnisaufgaben, wie Fragen, die Beantwortung, Inferenz, müssen die Beziehung verstehen müssen
zwischen Satz. Das Sprachmodell kann jedoch nur ohne Satz verstehen. Nächster Satz
Vorhersage ist eine Beispielaufgabe, um das Modell zu helfen, in solchen Aufgaben besser zu verstehen.
50% des Zufalls Der zweite Satz ist der nächste Satz des ersten, 50% der nächsten.
Bei zwei Satz wird das Modell gebeten, vorherzusagen, ob der zweite Satz real ist, der nächste Satz von ist
der erste.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
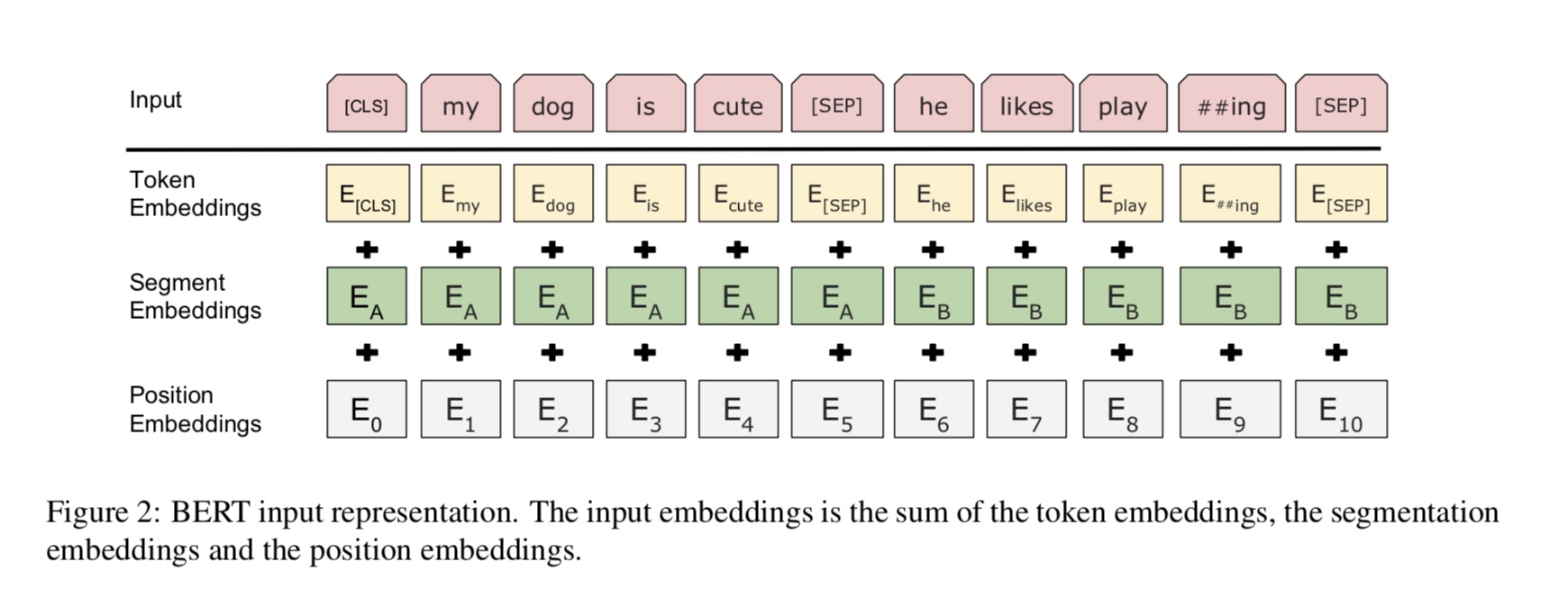
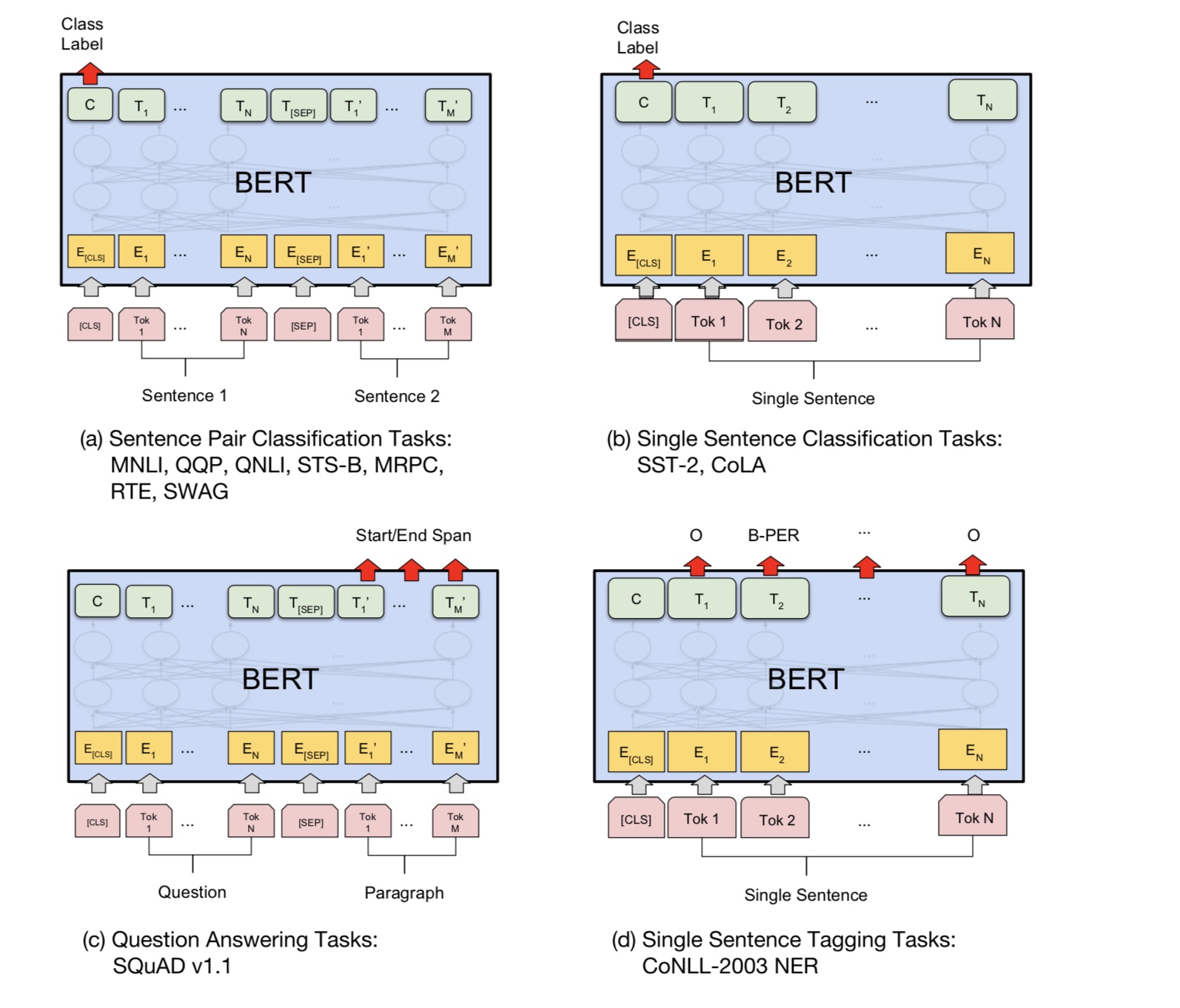
Python 3+ Tensorflow 1.10
Welchen Anteil und nicht zwischen den Phasen vor dem Training und der Feinabstimmung?
1). Grundsätzlich werden alle Parameter des Backbone-Netzwerks, die von Vor-Train- und Feinabstimmungsstufen verwendet werden, gegenseitig geteilt.
2). Wie wir die Parameter so weit wie möglich teilen können, so dass wir während der Feinabstimmung so wenige lernen müssen
Der Parameter wie möglich haben wir auch Worteinbettung für diese beiden Stufen geteilt.
3). Daher wurden die meisten Parameter bereits zu Beginn der Feinabstimmung gelernt.
Wie implementieren wir maskiertes Sprachmodell?
Um die Dinge leicht zu machen, generieren wir Sätze aus Dokumenten und teilen sie in Sätze auf. Für jeden Satz
Wir verkürzen und übertreffen es auf die gleiche Länge und wählen zufällig ein Wort aus, ersetzen es dann durch [Maske], ihr Selbst und ein zufälliges
Wort.
Wie kann man die Feinabstimmung effizienter gestalten und nicht das Ergebnis und das Wissen, das wir aus der Bühne vor dem Training gelernt haben?
Wir verwenden eine kleine Lernrate während der Feinabstimmung, so dass die Anpassung in geringem Maße durchgeführt wurde.
Warum brauchen wir Selbstbeziehung?
Selbstbekämpfung Eine neue Art von Netzwerk erlangt in letzter Zeit immer mehr Aufmerksamkeit. Traditionell verwenden wir
RNN oder CNN, um das Problem zu lösen. RNN hat jedoch parallel ein Problem, und CNN ist bei modellpositionsempfindlichen Aufgaben nicht gut.
Selbstbekämpfung kann parallel laufen und in der Lage sein, eine Fernabhängigkeit zu modellieren.
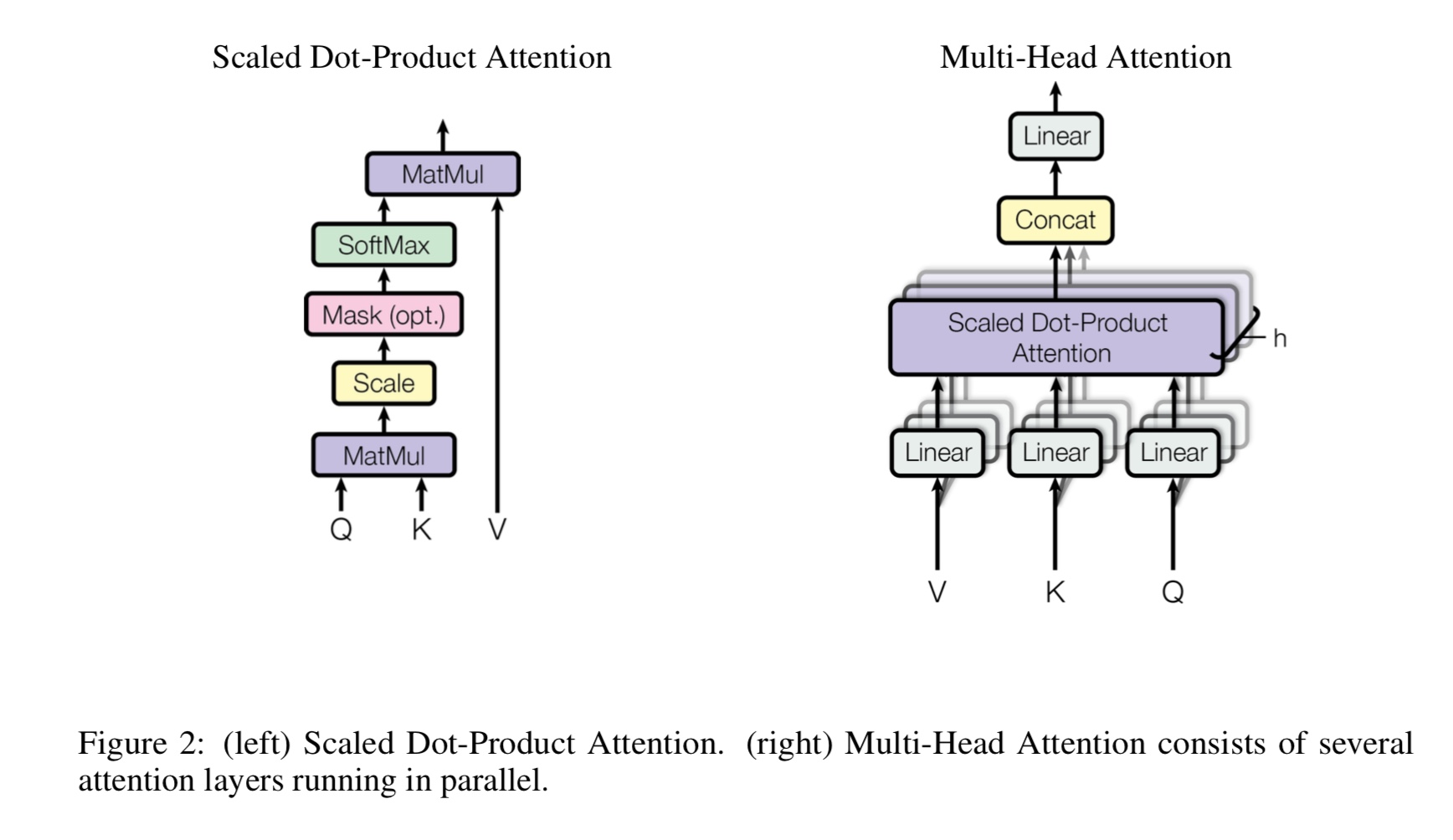
Wofür ist Multi-Heads Selbstbeziehung, wofür steht Q, K, V? Fügen Sie hier etwas hinzu.
Mulit-Heads Selbstbeziehung ist eine Selbstbekämpfung, während sie Q und K in mehrere verschiedene Subspace unterteilt und projiziert.
Dann machen Sie Aufmerksamkeit.
Q Stehen Sie für Frage, k stehen für Keys. Für die maschinelle Übersetzungsaufgabe ist Q früher versteckter Decodes, k repräsentiert
Versteckte Zustände des Encoders. Jedes Element von K berechnet eine Ähnlichkeitsbewertung mit q. Und dann wird Softmax verwendet
Um die Punktzahl zu normalisieren, werden wir Gewichte bekommen. Schließlich wird eine gewichtete Summe unter Verwendung von Gewichten berechnet, die für v gelten.
Im Selbstbekämpfungsszenario sind Q, K, V jedoch alle gleich wie die Darstellung von Eingabesequenzen einer Aufgabe.
Was ist positionelle Feedfoward?
Es handelt sich um eine Vorwärtsschicht, die auch als vollständig verbundene (FC) -Schicht bezeichnet wird. aber seit im Transformator alle Eingaben und Ausgabe von
Ebenen sind die Abfolge von Vektoren: [Sequence_length, D_Model]. Normalerweise führen wir FC zu einem Eingangsvektor durch. Also machen wir es wieder,
Aber ein anderer Zeitschritt hat einen eigenen FC.
Was ist der Hauptbeitrag von Bert?
Während es bereits seit vielen Jahren vorhanden ist, führt sie einen neuen Weg (so genannte bidirektional), um Sprachmodell zu machen
und verwenden Sie es für Down -Stream -Aufgaben. als Daten für das Sprachmodell sind überall. Es erwies sich als mächtig und umgestaltet es um
NLP -Welt.
Warum verwenden die Autorin drei verschiedene Arten von Token, wenn sie Trainingsdaten mit maskiertem Sprachmodell generieren?
Die Autoren glauben, dass es in der Feinabstimmung kein [Masken-] Token gibt. Es ist also nicht übereinstimmend zwischen Vorverbrauch und Feinabstimmung.
Es zwingt das Modell auch, alle Kontextinformationen in einem Satz zu beachten.
Was hat Bert -Modell dazu gebracht, neue Stand der Kunst zu erreichen, die zu Aufgaben des Sprachverständnisses führen?
Großes Modell, große Berechnung und vor allem-neuer Algorithmus, das Modell mithilfe von Freistufedaten vorhanden.
Die Spielzeugaufgabe wird verwendet, um zu überprüfen, ob das Modell ordnungsgemäß funktionieren kann, ohne von realen Daten abhängig zu sein.
Es fordert das Modell auf, Zahlen zu zählen und alle Eingänge zu summieren. und eine Schwelle wird verwendet,
Wenn die Summierung größer (oder weniger) ist als ein Schwellenwert, muss das Modell es als 1 (oder 0) vorhersagen.
In Inside Model/Transform_Model.py gibt es eine Zug- und Vorhersagemethode.
Zuerst können Sie Train () mit dem Training beginnen und dann Predict () mithilfe des geschulten Modells mit dem Vorhersage beginnen.
Da das Modell ziemlich groß ist, ist mit Standard -Hyperparamter (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6) viele Daten erforderlich, bevor es konvergieren kann.
Mindestens 10 km Schritte sind erforderlich, bevor der Verlust weniger als 0,1 wird. Wenn Sie es schnell mit klein trainieren möchten
Daten, Sie können einen kleinen Satz von Hyperparmeter verwenden (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Sie können es verwenden, um zwei Lösungsklassifizierung, Klassifizierung mit mehreren Klassen oder ein Multi-Label-Klassifizierungsproblem zu lösen.
Es wird Verlust während des Trainings drucken und die F1 -Punktzahl für jede Epoche während der Validierung gedruckt.
Beheben Sie einen Fehler im Transformator [wichtig, rekrutieren Sie ein Teammitglied und benötigen eine Merge -Anfrage]
(Transformator: Warum ist der Verlust des Stadiums vor dem Training im frühen Stadium abgenommen, aber der Verlust ist immer noch nicht so klein (z. B. Verlust = 8,0)? Trotzdem
Weitere Daten vor dem Training, der Verlust ist immer noch nicht klein)
Support Sure Pair Task [Wichtig, ein Teammitglied rekrutieren und eine Merge -Anfrage benötigen]
Fügen Sie die Aufgabe der nächsten Satzvorhersage vor dem Training hinzu [wichtig, rekrutieren Sie ein Teammitglied und benötigen eine Merge-Anfrage]
Benötigen Sie einen Datensatz für die Stimmungsanalyse oder eine Textklassifizierung in Englisch [Wichtig, einkaufen Sie ein Teammitglied und benötigen eine Zusammenführungsanforderung]
Die Positionseinbettung wird noch nicht mit Voraussetzung und Feinabstimmung geteilt. da hier auf der Bühnenlänge vor dem Training kann
kürzer als Feinabstimmung.
Spezielles Griff First Token [CLS] als Eingabe und Klassifizierung [fertig]
Pre-Training mit fine_tuning: Benötigen Sie Lastvokabular von Token aus der Stufe vor dem Training, aber beschriftet von der echten Aufgabe. [ERLEDIGT]
Die Lernrate sollte bei der Feinabstimmung kleiner sein. [Erledigt]
Pre-Train ist alles, was Sie brauchen. Wenn Sie Transformator oder ein anderes komplexes tiefes Modell verwenden, können Sie Top -Leistung erzielen
In einigen Aufgaben, die mit einem anderen Modell wie textCnn mit einer riesigen Menge an Rohdaten vorliegt und Ihr Modell auf den aufgabenspezifischen Datensatz abtun, umstimmt sie zu.
Wird Ihnen immer helfen, zusätzliche Leistung zu erzielen.
Fügen Sie hier mehr hinzu.
Fügen Sie Vorschläge, Problem hinzu oder möchten Sie einen Beitrag leisten. Begrüßen Sie es zu mir, mit mir zu kontaktieren: [email protected]
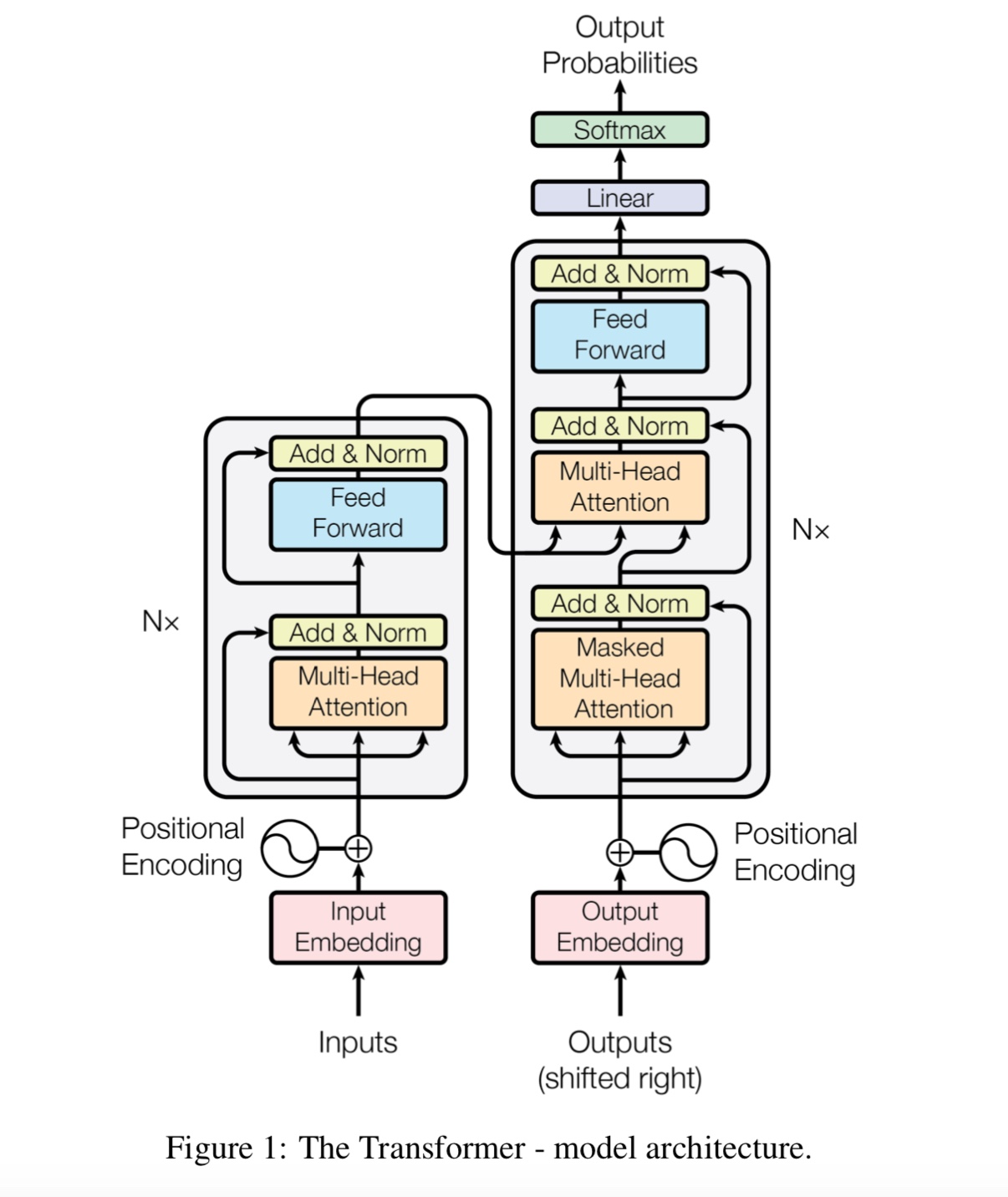
Aufmerksamkeit ist alles was Sie brauchen
Bert: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis
Tensor2tensor für neuronale maschinelle Übersetzung
Faltungsnetzwerke für die Satzklassifizierung
CAIL2018: Ein groß an


