bert_language_understanding
1.0.0
بيرت يحقق نتيجة جديدة على أحدث طراز على أكثر من 10 مهام NLP مؤخرًا.
هذا هو تنفيذ التوتر من التدريب المسبق لمحولات ثنائية الاتجاه العميقة لفهم اللغة
(بيرت) والانتباه هو كل ما تحتاجه (محول).
تحديث: تم تنفيذ الجزء العظمى من الأفكار الرئيسية المتكررة لهاتين الورقة ، وهناك مكسب أداء واضح
بالنسبة لتدريب ما قبل النموذج والضوء الدقيق مقارنة لتدريب النموذج من الصفر.
لقد أجرينا تجربة لاستبدال شبكة العمود الفقري من Bert من Transformer إلى TextCnn ، والنتيجة هي ذلك
قبل تدريب النموذج مع نموذج اللغة المقنعة باستخدام الكثير من البيانات الخام يمكن أن يعزز الأداء بكمية ملحوظة.
بشكل أعم ، نعتقد أن استراتيجية ما قبل التدريب والضوء هي نموذج مستقل ومستقل ما قبل التدريب.
مع ما يقال ، يمكنك استبدال شبكة العمود الفقري كما تريد. وأضف المزيد من مهام ما قبل التدريب أو تحديد بعض مهام ما قبل التدريب الجديدة
يمكنك ، لن يقتصر ما قبل التدريب على نموذج اللغة المقنعة أو التنبؤ بمهمة الجملة التالية. ما يفاجئنا هو ذلك ،
مع مجموعة بيانات ذات حجم متوسط تقول ، مليون ، حتى بدون استخدام البيانات الخارجية ، بمساعدة مهمة ما قبل التدريب
مثل نموذج اللغة المقنعة ، يمكن أن يعزز الأداء بهامش كبير ، ويمكن أن يتقارب النموذج بسرعة. في وقت ما
يمكن أن يكون التدريب في حاجة فقط إلى عدد قليل من الحقبة في مرحلة الضبط.
في حين أن هناك مصدرًا مفتوحًا (Tensor2Tensor) والمسؤول
تنفيذ تطبيق Transformer و BERT الرسمي قريبًا ، ولكن من الصعب قراءته/قد يكون من السهل فهمه.
نحن لسنا نية لتكرار الأوراق الأصلية تمامًا ، ولكن لتطبيق الأفكار الرئيسية وحل مشكلة NLP بطريقة أفضل.
تم تنفيذ جزء الأغلبية من العمل هنا بواسطة مستودع آخر العام الماضي: تصنيف النص
مجموعة بيانات الحجم المتوسط (CAIL2018 ، 450K)
| نموذج | TextCnn (لا توجد محفوظات) | textcnn (pretrain-finetuning) | ربح من ما قبل التدريب |
|---|---|---|---|
| درجة F1 بعد 1 عصر | 0.09 | 0.58 | 0.49 |
| درجة F1 بعد 5 عصر | 0.40 | 0.74 | 0.35 |
| درجة F1 بعد 7 عصر | 0.44 | 0.75 | 0.31 |
| درجة F1 بعد 35 عصر | 0.58 | 0.75 | 0.27 |
| خسارة التدريب في البداية | 284.0 | 84.3 | 199.7 |
| خسارة التحقق من الصحة بعد 1 عصر | 13.3 | 1.9 | 11.4 |
| خسارة التحقق من الصحة بعد 5 عصر | 6.7 | 1.3 | 5.4 |
| وقت التدريب (GPU واحد) | 8H | 2H | 6H |
يلاحظ:
أكملت مرحلة التثبيت A.Fine التدريب بعد تشغيل 7 حقبة حيث وصل Max Epoch إلى 35.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
درجة C.F1 المذكورة هنا هي على مجموعة التحقق من الصحة ، في المتوسط Micro و Macro من درجة F1.
تم الإبلاغ عن درجة D.F1 بعد 35 عصرًا في مجموعة الاختبار.
ه. من 450 ألف مستندات أولية ، تم استرداد 2 مليون بيانات تدريب لنموذج اللغة المقنعة ،
pre-train stage finished within 5 hours in single GPU.
ضبط دقيق بعد ما قبل التدريب:
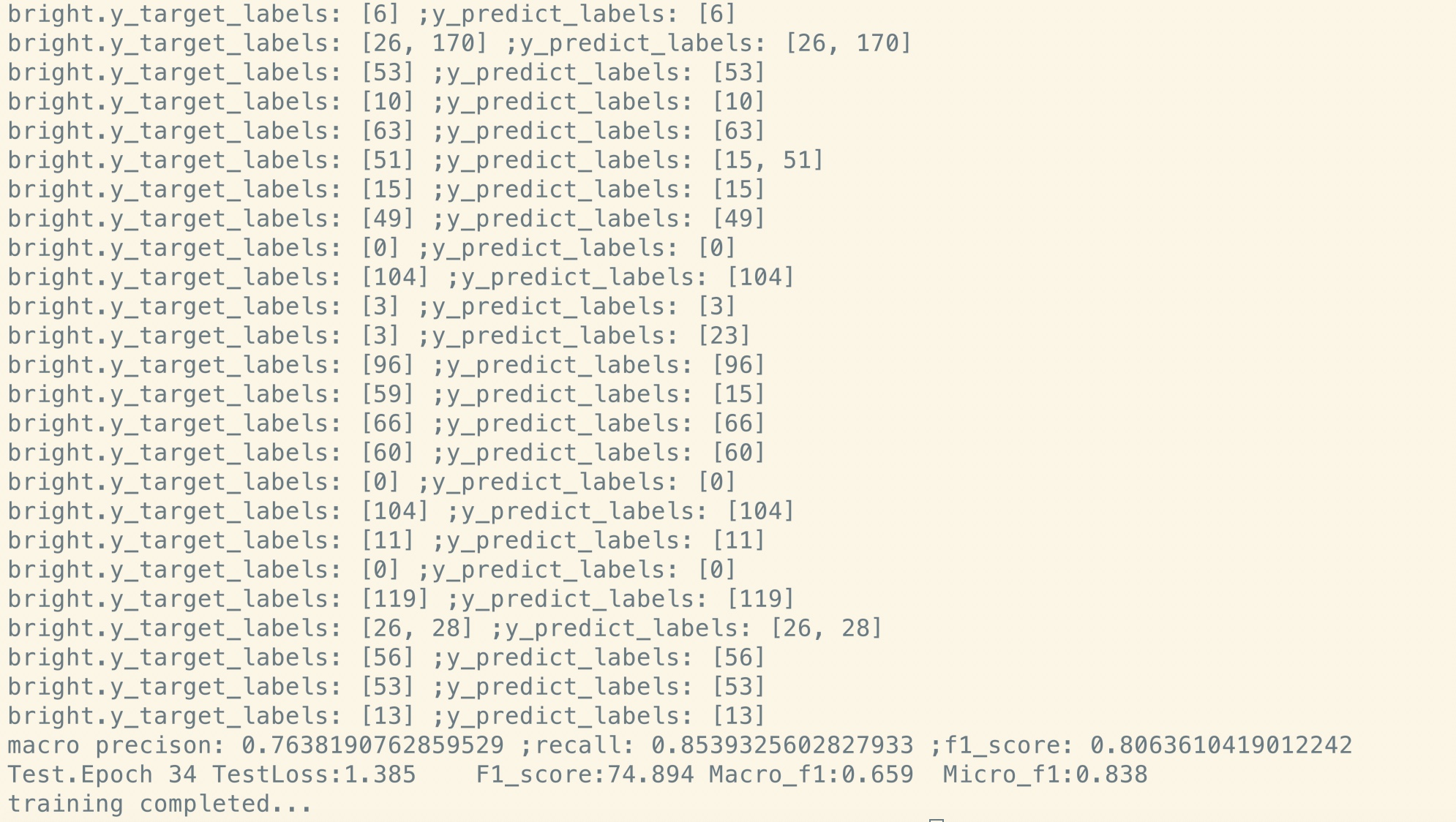
لا مسبق:
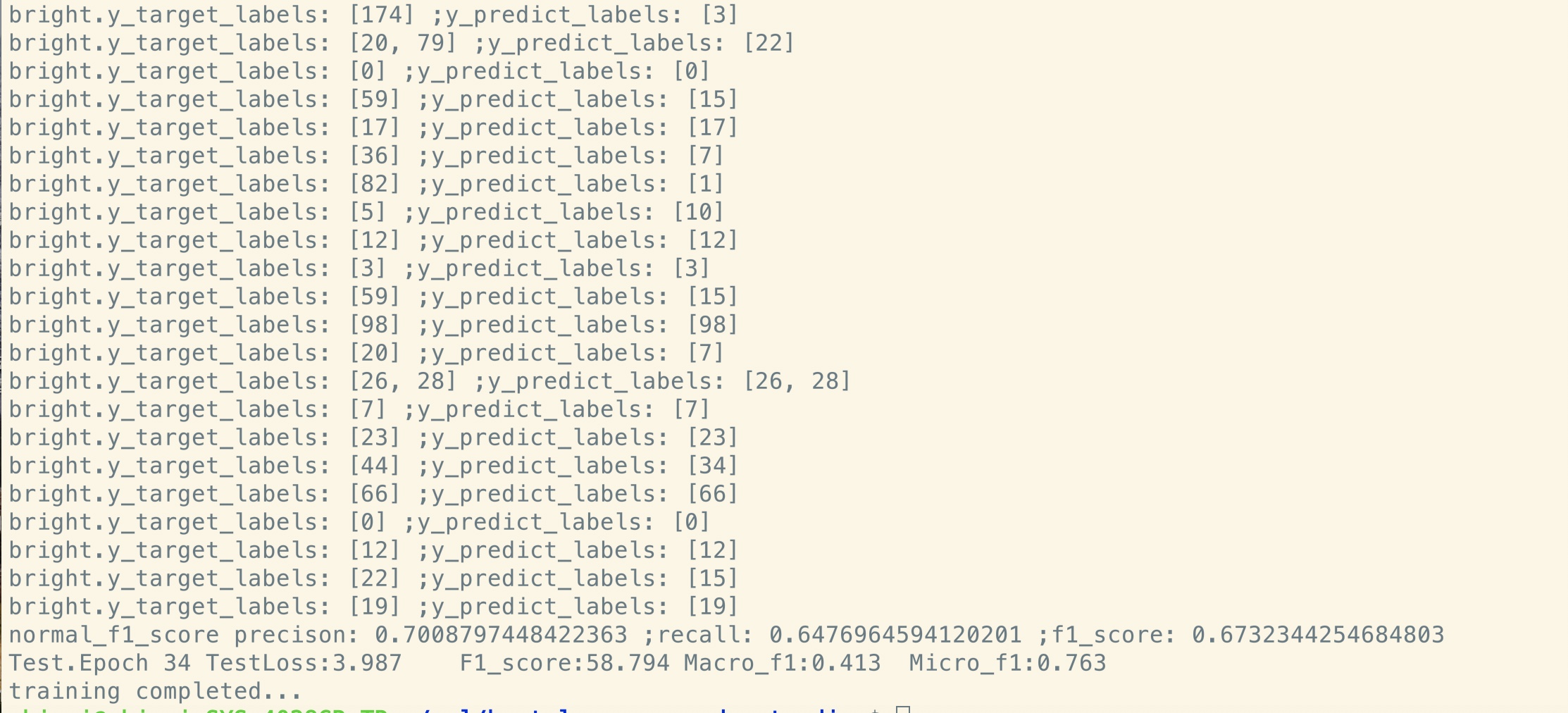
مجموعة بيانات صغيرة الحجم (خاصة ، 100 ألف)
| نموذج | TextCnn (لا توجد محفوظات) | textcnn (pretrain-finetuning) | ربح من ما قبل التدريب |
|---|---|---|---|
| درجة F1 بعد 1 عصر | 0.44 | 0.57 | 10 ٪+ |
| خسارة التحقق من الصحة بعد 1 عصر | 55.1 | 1.0 | 54.1 |
| خسارة التدريب في البداية | 68.5 | 8.2 | 60.3 |
إذا كنت ترغب في تجربة Bert مع تدريب ما قبل التدريب من نموذج اللغة المقنعة والضبط. اتخذ خطوتين:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
كما ترون ، حتى في نقطة بداية الضبط الدقيقة ، مباشرة بعد استعادة المعلمات من النموذج الذي تم تدريبه مسبقًا ، يكون فقدان النموذج أصغر
من التدريب من جديد تمامًا ، ودرجة F1 أعلى أيضًا بينما قد يبدأ طراز جديد من 0.
إشعار: لمساعدتك في تجربة فكرة جديدة أولاً ، يمكنك تعيين Hyper-Paramater Test_Mode على True. سوف يقوم فقط بتحميل القليل من البيانات ، والبدء في التدريب بسرعة.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_MODEL: بُعد النموذج. [512]
num_layer: عدد الطبقات. [6]
num_header: عدد رؤوس الاهتمام الذاتي [8]
D_K: بُعد المفتاح (K). أبعاد الاستعلام (ف) هو نفسه. [64]
D_V: بُعد V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
كل سطر مستند (عدة جمل) أو جملة. هذا النص الحر يمكنك الحصول عليه بسهولة.
تحقق من البيانات/bert_train.txt أو bert_train2.txt في ملف zip.
الإدخال والإخراج في نفس السطر ، كل تسمية تبدأ بـ " Label ".
هناك مساحة بين سلسلة الإدخال والتسمية الأولى ، يتم تقسيم كل تسمية أيضًا بواسطة مساحة.
مثل Token1 Token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
تحقق من البيانات/bert_train.txt أو bert_train2.txt في ملف zip.
تحقق من مجلد "البيانات" لعينة البيانات. أسفل تحميل مجموعة بيانات الحجم المتوسط هنا
مع فئة 450K 206 ، يكون كل إدخال مستندًا ، ويبلغ متوسط الطول حوالي 300 أو واحد أو مشارك متعدد العلامات في المدخلات.
قم بتنزيل تضمين كلمة ما قبل التدريب من Tencent Ailab
يمكن أن تكون الأمور سهلة:
قم بتنزيل مجموعة البيانات (حوالي 200 متر ، 450 ألف بيانات ، مع بعض ملفات ذاكرة التخزين المؤقت) ، قم بفك ضغطها ووضعها في البيانات/ المجلد ،
قم بتشغيل الخطوة 1 للتدريب ،
وتشغيل الخطوة 2 للضوء.
انتهيت من ثلاث خطوات ، وأريد الحصول على أداء أفضل ، كيف يمكنني القيام بمزيد من العمل. هل أحتاج إلى العثور على مجموعة بيانات كبيرة؟
لا ، يمكنك إنشاء مجموعة بيانات كبيرة بنفسك لمرحلة ما قبل التدريب عن طريق تنزيل بعض النص المجاني ، تأكد من كل سطر
هو مستند أو جملة ثم استبدل البيانات/Bert_Train2.txt بملف البيانات الجديد.
ما هو أكثر؟
جرب بعض المعلمات الكبيرة أو النموذج الكبير (عن طريق استبدال شبكة العمود الفقري) باستخدام جميع بيانات ما قبل التدريب.
العب مع النموذج: Model/Bert_Cnn_Model.py ، أو تحقق من العملية المسبقة باستخدام Data_util_hdf5.py.
نموذج اللغة المهروسة المهروسة ومهمة التنبؤ بالجملة التالية على نطاق واسع من الجسم ،
استنادًا إلى نموذج التحويل الذاتي للطبقة المتعددة ، ثم ضبط دقيق عن طريق إضافة طبقة تصنيف.
نظرًا لأن نموذج BERT يعتمد على المحول ، فإننا نعمل حاليًا على إضافة مهمة PREDRAIN إلى النموذج.
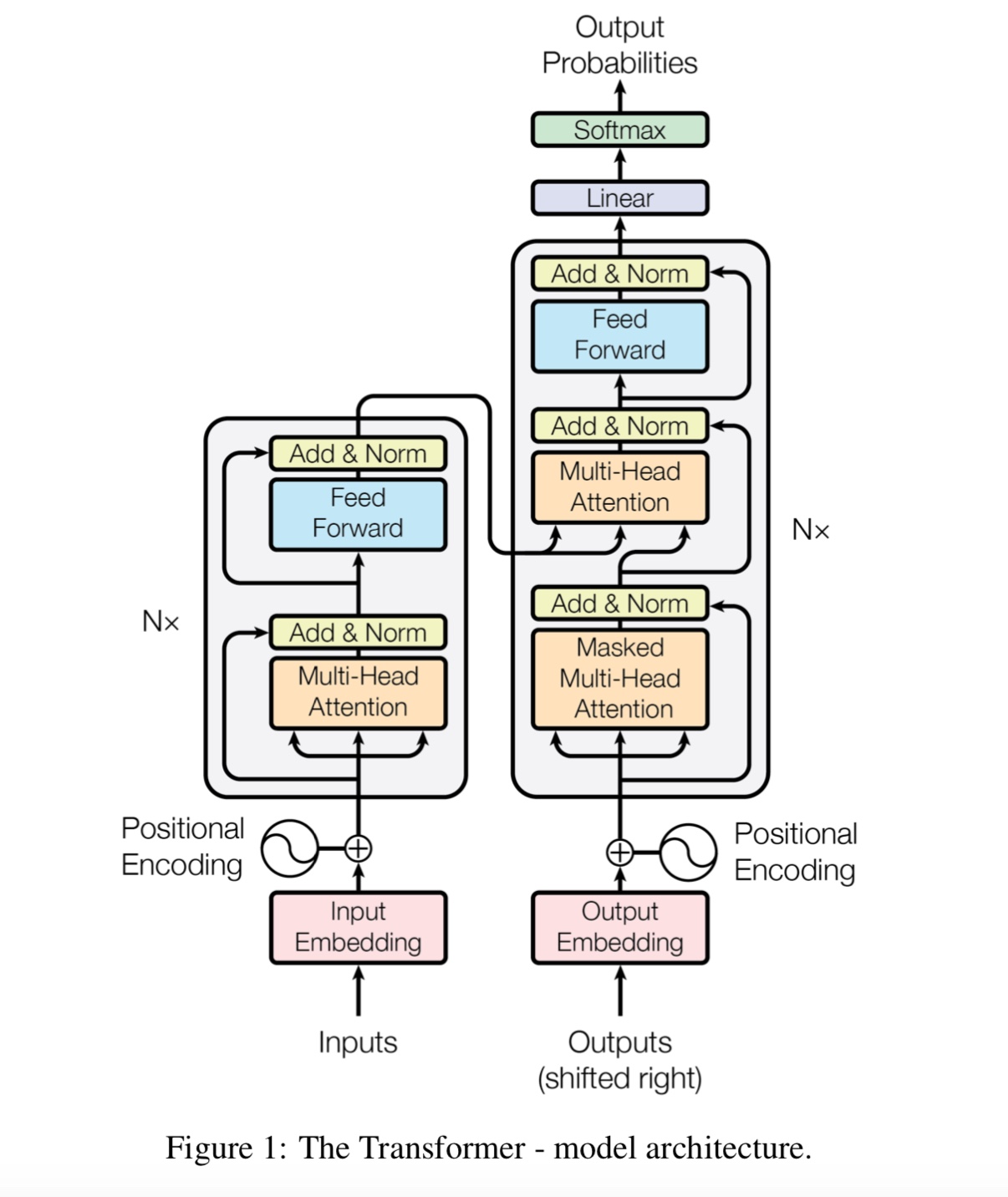
إشعار: CAIL2018 حوالي 450 ألف كرابط أعلاه.
يبلغ حجم تدريب مجموعة البيانات الخاصة حوالي 100 ألف ، وعدد الفصول هو 9 ، لكل إدخال يوجد واحد أو أكثر من الملصقات.
تم الإبلاغ عن درجة F1 لـ CAIL2018 كنتيجة Micro F1.
الفكرة الأساسية بسيطة للغاية. لعدة سنوات ، حصل الناس على نتائج جيدة للغاية "قبل التدريب" DNNS كنموذج لغة
ثم صقله على بعض مهمة NLP المصب (الإجابة على الأسئلة ، استنتاج اللغة الطبيعية ، تحليل المشاعر ، إلخ).
عادة ما تكون نماذج اللغة من اليسار إلى اليمين ، على سبيل المثال:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
المشكلة هي أنه بالنسبة للمهمة المصب التي لا تريدها عادةً نموذج لغة ، فأنت تريد أفضل تمثيل سياق ممكن لـ
كل كلمة. إذا كانت كل كلمة يمكن أن ترى سياقًا على يساره فقط ، فمن الواضح أن الكثير مفقود. لذا فإن إحدى الحيلة التي قام بها الناس هي تدريب أ أيضًا
النموذج من اليمين إلى اليسار ، على سبيل المثال:
P(store|</s>)*P(a|store </s>)*…
الآن لديك "تمثيلان لكل كلمة ، واحدة من اليسار إلى اليمين وواحد من اليمين إلى اليسار ، ويمكنك تسلسلهما معًا لمهمة المصب.
ولكن بشكل حدسي ، سيكون من الأفضل أن نتمكن من تدريب نموذج واحد كان ثنائي الاتجاه بعمق.
من المستحيل للأسف تدريب نموذج ثنائي الاتجاه عميق مثل LM العادي ، لأن ذلك من شأنه أن يخلق دورات حيث يمكن للكلمات بشكل غير مباشر
"انظر أنفسهم" ، وتصبح التنبؤات تافهة.
ما يمكننا القيام به بدلاً من ذلك هو الخدعة البسيطة التي يتم استخدامها في إلغاء الضوضاء التلقائية ، حيث نقوم بإخفاء بعض الكلمات من المدخلات و
يجب إعادة بناء هذه الكلمات من السياق. نحن نسمي هذا "LM مقنعة" ولكن غالبًا ما يطلق عليه مهمة cloze.
نقوم بتغذية المدخلات من خلال تشفير محول عميق ثم نستخدم الحالات المخفية النهائية المقابلة للمواقف المقنعة
التنبؤ بالكلمة التي تم إخفاءها ، تمامًا كما كنا سنقوم بتدريب نموذج اللغة.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
كيف تحصل على آخر حالة مخفية من المواقف المقنعة؟
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
لمزيد من التفاصيل ، تحقق من طريقة Mask_language_model من pretrain_task.py و train_vert_lm.py
العديد من مهمة فهم اللغة ، مثل الإجابة على الأسئلة ، والاستدلال ، تحتاج إلى فهم العلاقة
بين الجملة. ومع ذلك ، فإن نموذج اللغة قادر فقط على الفهم بدون جملة. الجملة القادمة
التنبؤ بمهمة عينة للمساعدة في فهم النموذج بشكل أفضل في هذه الأنواع من المهام.
50 ٪ من الصدفة على الجملة الثانية هي الجملة التالية من أول واحد ، 50 ٪ من ليست الجمل التالية.
بالنظر إلى جملة ، يُطلب من النموذج التنبؤ بما إذا كانت الجملة الثانية هي الجملة القادمة الحقيقية
الأول.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
Python 3+ Tensorflow 1.10
ما هي المشاركة وعدم المشاركة بين مراحل ما قبل التدريب وصقلها؟
1).
2). كما يمكننا مشاركة المعلمات قدر الإمكان ، بحيث نحتاج خلال مرحلة الضبط
المعلمة قدر الإمكان ، شاركنا أيضًا تضمين الكلمات لهاتين المرحلتين.
3). لذلك تم تعلم معظم المعلمات بالفعل في بداية مرحلة الضبط.
كيف ننفذ نموذج اللغة المقنعة؟
لجعل الأمور بسهولة ، ننشئ جملًا من المستندات ، ونقسمها إلى جمل. لكل جملة
نحن نقبل ونحطوها بنفس الطول ، ونحدد بشكل عشوائي كلمة ، ثم استبدلها بـ [قناع] ، وذاتها وعشوائية
كلمة.
كيف تجعل مرحلة الضبط أكثر كفاءة ، في حين أن النتيجة والمعرفة التي تعلمناها من مرحلة ما قبل التدريب؟
نستخدم معدل تعليمي صغير أثناء الضبط الدقيق ، بحيث تم ضبط ذلك إلى حد كبير.
لماذا نحتاج إلى الاهتمام الذاتي؟
الاهتمام الذاتي ، يحظى نوع جديد من الشبكات مؤخرًا بمزيد من الاهتمام. تقليديا نستخدم
RNN أو CNN لحل المشكلة. ومع ذلك ، فإن RNN لديه مشكلة بالتوازي ، وشبكة CNN ليست جيدة في مهام حساسية موضع النموذج.
يمكن أن يعمل الاهتمام الذاتي بالتوازي ، بينما قادر على تصميم تبعية المسافات الطويلة.
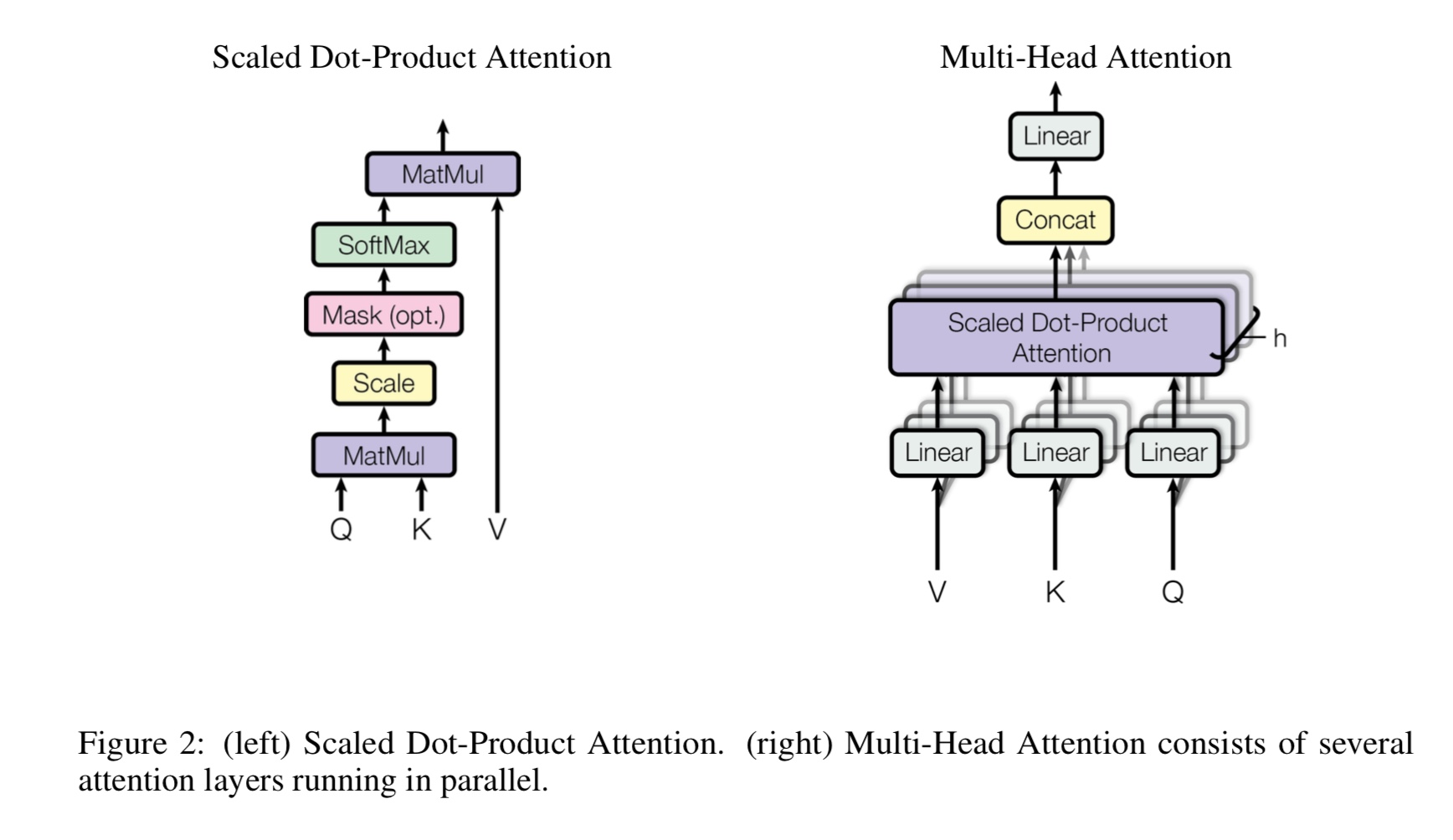
ما هي الرؤوس المتعددة الذاتية ، ما الذي تمثله Q ، K ، V؟ أضف شيئًا هنا.
يعد Mulit-Heads Technote Attrantion بمثابة اعتناق ذاتي ، بينما يتقسم ويسدد Q و K إلى عدة فضاء فرعي مختلف ،
ثم لا الانتباه.
Q Staking for Question ، K Stand for Keys. بالنسبة لمهمة الترجمة الآلية ، Q هي حالة فك تشفير مخفية سابقة ، K تمثل
حالات مخفية للتشفير. كل عنصر من عناصر K سيحسب درجة التشابه مع Q. ثم سيتم استخدام softmax
للقيام بتطبيع الدرجات ، سوف نحصل على الأوزان. أخيرًا ، يتم حساب مجموع مرجح باستخدام الأوزان ينطبق على V.
ولكن في سيناريو الاهتمام الذاتي ، Q ، K ، V كلها متماثلة ، مثل تمثيل تسلسل الإدخال للمهمة.
ما هو الموقف الحكيمة؟
إنها طبقة للأمام تغذية ، تسمى أيضًا طبقة متصلة بالكامل (FC). ولكن منذ أن في المحول ، كل مدخلات ومخرجات
الطبقات هي تسلسل المتجهات: [sequence_length ، d_model]. عادة ما نفعل FC إلى متجه المدخلات. لذلك نحن نفعل ذلك مرة أخرى ،
لكن خطوة زمنية مختلفة لها FC الخاصة بها.
ما هي المساهمة الرئيسية لبيرت؟
على الرغم من وجود مهمة ما قبل التدريب بالفعل لسنوات عديدة ، فإنها تقدم طريقة جديدة (تسمى ثنائية الاتجاه) للقيام بنموذج اللغة
واستخدامه لمهمة دفق أسفل. كبيانات لنموذج اللغة في كل مكان. ثبت أنه قوي ، وبالتالي يعيد تشكيله
عالم NLP.
لماذا يستخدم المؤلف ثلاثة أنواع مختلفة من الرموز عند إنشاء بيانات تدريب من نموذج اللغة المقنعة؟
يعتقد المؤلفون أنه في مرحلة الضبط ، لا يوجد رمز [قناع]. لذلك لا يتطابق بين ما قبل التدريب والضوء.
كما أنه يجبر النموذج على الانتباه جميع معلومات السياق في الجملة.
ما الذي جعل نموذج BERT لتحقيق حالة فنية جديدة يؤدي إلى مهام فهم اللغة؟
النموذج الكبير ، والحساب الكبير ، والأهم من ذلك-الخوارزمية الجديدة قبل تدريب النموذج باستخدام بيانات النص الحر.
يتم استخدام مهمة لعبة للتحقق مما إذا كان النموذج يمكن أن يعمل بشكل صحيح دون الاعتماد على البيانات الحقيقية.
يطلب من النموذج حساب الأرقام ، وتلخيص جميع المدخلات. ويستخدم عتبة ،
إذا كان الجمع أكبر (أو أقل) من العتبة ، فيجب أن يتنبأ النموذج بأنه 1 (أو 0).
داخل النموذج/transform_model.py ، هناك طريقة للقطار والتنبؤ.
أولاً ، يمكنك تشغيل Train () لبدء التدريب ، ثم تشغيل التنبؤ () لبدء التنبؤ باستخدام نموذج مدرب.
نظرًا لأن النموذج كبير جدًا ، مع وجود فرط الكلام الافتراضي (D_Model = 512 ، H = 8 ، D_V = D_K = 64 ، num_layer = 6) ، فإنه يتطلب الكثير من البيانات قبل أن تتقارب.
ما لا يقل عن 10 آلاف خطوات الحاجة ، قبل أن تصبح الخسارة أقل من 0.1. إذا كنت تريد تدريبه بسرعة مع الصغيرة
البيانات ، يمكنك استخدام مجموعة صغيرة من hyperparmeter (d_model = 128 ، H = 8 ، d_v = d_k = 16 ، num_layer = 6)
يمكنك استخدامه اثنين من التصنيف الثنائي ، تصنيف متعدد الطبقات أو مشكلة تصنيف متعددة العلامات.
سوف يطبع الخسارة أثناء التدريب ، وطباعة درجة F1 لكل فترة أثناء التحقق من الصحة.
إصلاح الخلل في Transformer [مهم ، وقم بتوظيف عضو في الفريق ويحتاج إلى طلب دمج]
(المحول: لماذا ينخفض فقدان مرحلة ما قبل التدريب للمرحلة المبكرة ، لكن الخسارة لا تزال صغيرة جدًا (مثل الخسارة = 8.0)؟ حتى مع
المزيد من بيانات ما قبل التدريب ، لا تزال الخسارة ليست صغيرة)
مهمة زوج الدعم زوج [مهمة ، تجنيد عضو في الفريق ويحتاج إلى طلب دمج]
أضف مهمة ما قبل التدريب للتنبؤ بالجملة القادمة [المهم ، وقم بتوظيف عضو في الفريق ويحتاج إلى طلب دمج]
تحتاج إلى مجموعة بيانات لتحليل المشاعر أو تصنيف النص باللغة الإنجليزية [مهم ، وقم بتوظيف عضو في الفريق ويحتاج إلى طلب دمج]
لا يتم مشاركة التضمين في الموقف مع ما قبل التدريب والضبط حتى الآن. منذ هنا على طول مرحلة ما قبل التدريب قد
أقصر من مرحلة الضبط.
مقبض خاص الرمز المميز [CLS] كمدخلات وتصنيف [تم]
قبل التدريب مع fine_tuning: بحاجة إلى تحميل مفردات من الرموز من مرحلة ما قبل التدريب ، ولكن تسميات من مهمة حقيقية. [منتهي]
يجب أن يكون معدل التعلم أصغر عند ضبطه. [منتهي]
ما قبل التدريب هو كل ما تحتاجه. أثناء استخدام المحول أو بعض النموذج العميق المعقد الآخر يمكن أن يساعدك على تحقيق أفضل الأداء
في بعض المهام ، ما قبل النماذج مع نموذج آخر مثل TextCnn باستخدام كمية هائلة من البيانات الأولية ثم صقل النموذج الخاص بك على مجموعة بيانات محددة للمهمة ،
سوف تساعدك دائمًا على الحصول على أداء إضافي.
أضف المزيد هنا.
أضف اقتراحًا أو مشكلة أو يريد تقديم مساهمة ، مرحبًا بك في الاتصال معي: [email protected]
الانتباه هو كل ما تحتاجه
بيرت: ما قبل التدريب من محولات ثنائية الاتجاه العميقة لفهم اللغة
Tensor2Tensor للترجمة الآلية العصبية
الشبكات العصبية التلافيفية لتصنيف الجملة
CAIL2018: مجموعة بيانات قانونية واسعة النطاق للتنبؤ بالحكم


