bert_language_understanding
1.0.0
Bert alcance o novo resultado da arte em mais de 10 tarefas de PNL recentemente.
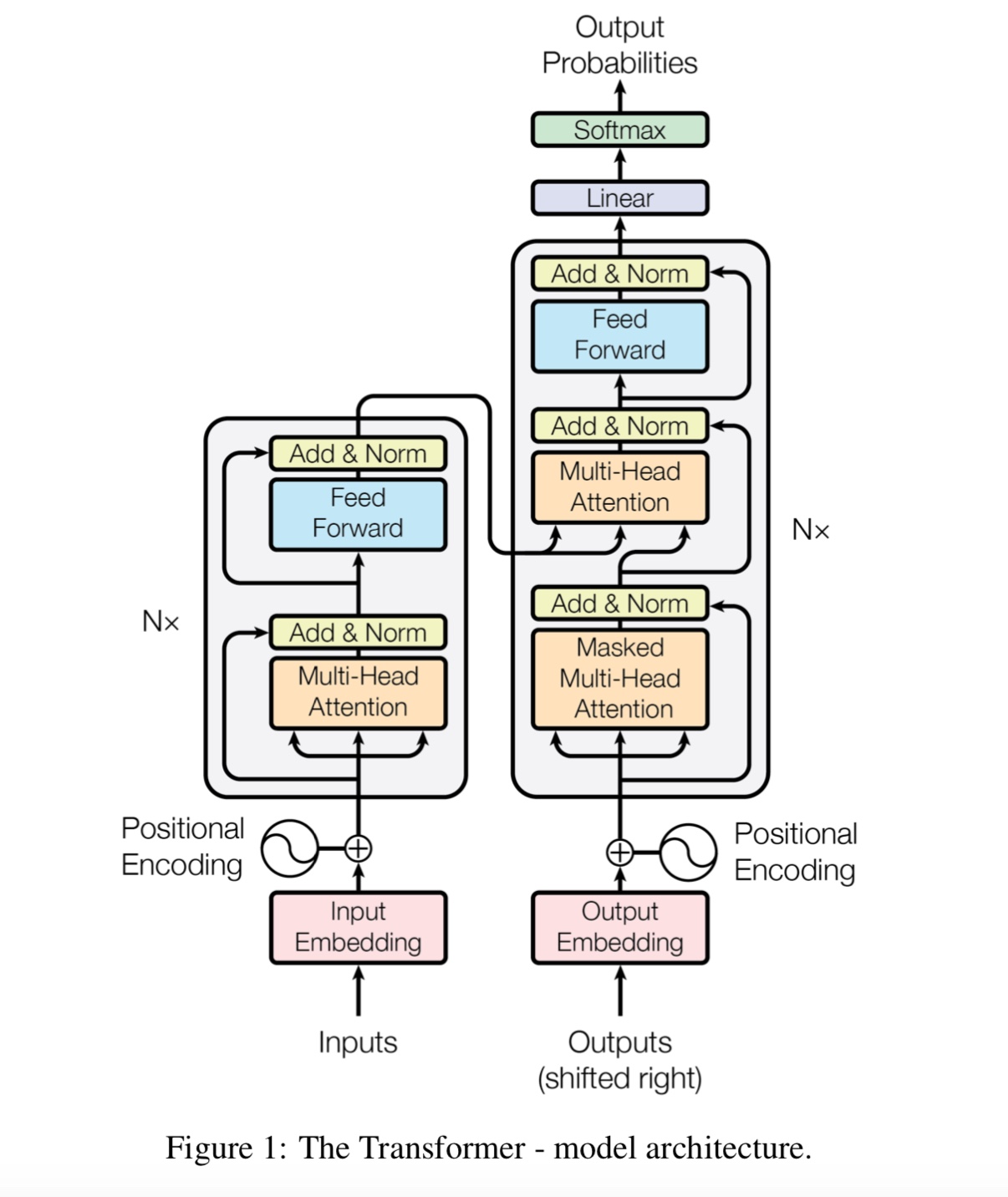
Esta é uma implementação do tensorflow do pré-treinamento de transformadores bidirecionais profundos para o entendimento da linguagem
(Bert) e atenção é tudo o que você precisa (transformador).
ATUALIZAÇÃO: A maioria das idéias principais replicadas desses dois artigos foi feita, há um aparente ganho de desempenho
Para pré-treinar, um modelo e o ajuste fino compare para treinar o modelo do zero.
Fizemos um experimento para substituir a rede de backbone de Bert de transformador para textcnn, e o resultado é que
Pré-trep o modelo com modelo de linguagem mascarada usando muitos dados brutos pode aumentar o desempenho em uma quantidade notável.
De maneira mais geral, acreditamos que a estratégia de pré-treinio e ajuste é independente de modelos e pré-treino, independente de tarefas.
Com isso dito, você pode substituir a rede de backbone como desejar. e adicione mais tarefas pré-trep ou definir algumas novas tarefas pré-trep
Você pode, o pré-trep não se limitará ao modelo de idioma mascarado e / ou prever a próxima tarefa de frase. O que nos surpreende é que,
Com um conjunto de dados de tamanho médio que dizem, um milhão, mesmo sem uso de dados externos, com a ajuda da tarefa pré-trep
Como o modelo de linguagem mascarada, o desempenho pode aumentar em uma grande margem, e o modelo pode convergir ainda rápido. algum dia
O treinamento pode estar em uma apenas algumas épocas em estágio de ajuste fino.
Embora exista um código aberto (tensor2tensor) e oficial
A implementação da implementação oficial do Transformer e da BERT em breve, mas é/pode ser difícil de ler, não é fácil de entender.
Não temos a intenção de replicar completamente os papéis originais, mas de aplicar as principais idéias e resolver o problema da PNL de uma maneira melhor.
A parte da maioria do trabalho aqui foi realizada por outro repositório no ano passado: classificação de texto
DataSet de tamanho médio (CAIL2018, 450K)
| Modelo | TextCnn (sem-pré-fixação) | Textcnn (pré-train-finetuning) | Ganho do pré-treino |
|---|---|---|---|
| Pontuação F1 após 1 época | 0,09 | 0,58 | 0,49 |
| Pontuação F1 após 5 épocas | 0,40 | 0,74 | 0,35 |
| Pontuação F1 após 7 época | 0,44 | 0,75 | 0,31 |
| Pontuação F1 após 35 época | 0,58 | 0,75 | 0,27 |
| Perda de treinamento no começo | 284.0 | 84.3 | 199.7 |
| Perda de validação após 1 época | 13.3 | 1.9 | 11.4 |
| Perda de validação após 5 épocas | 6.7 | 1.3 | 5.4 |
| Tempo de treinamento (GPU único) | 8h | 2h | 6h |
Perceber:
A. A etapa de ajuste concluiu o treinamento depois de executar apenas 7 épocas quando Max Epoch chegou a 35.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
A pontuação de C.F1 relatada aqui está no conjunto de validação, uma média de micro e macro da pontuação F1.
A pontuação de D.F1 após 35 época é relatada no conjunto de testes.
e. De 450k documentos brutos, recuperados 2 milhões de dados de treinamento para modelo de linguagem mascarada,
pre-train stage finished within 5 hours in single GPU.
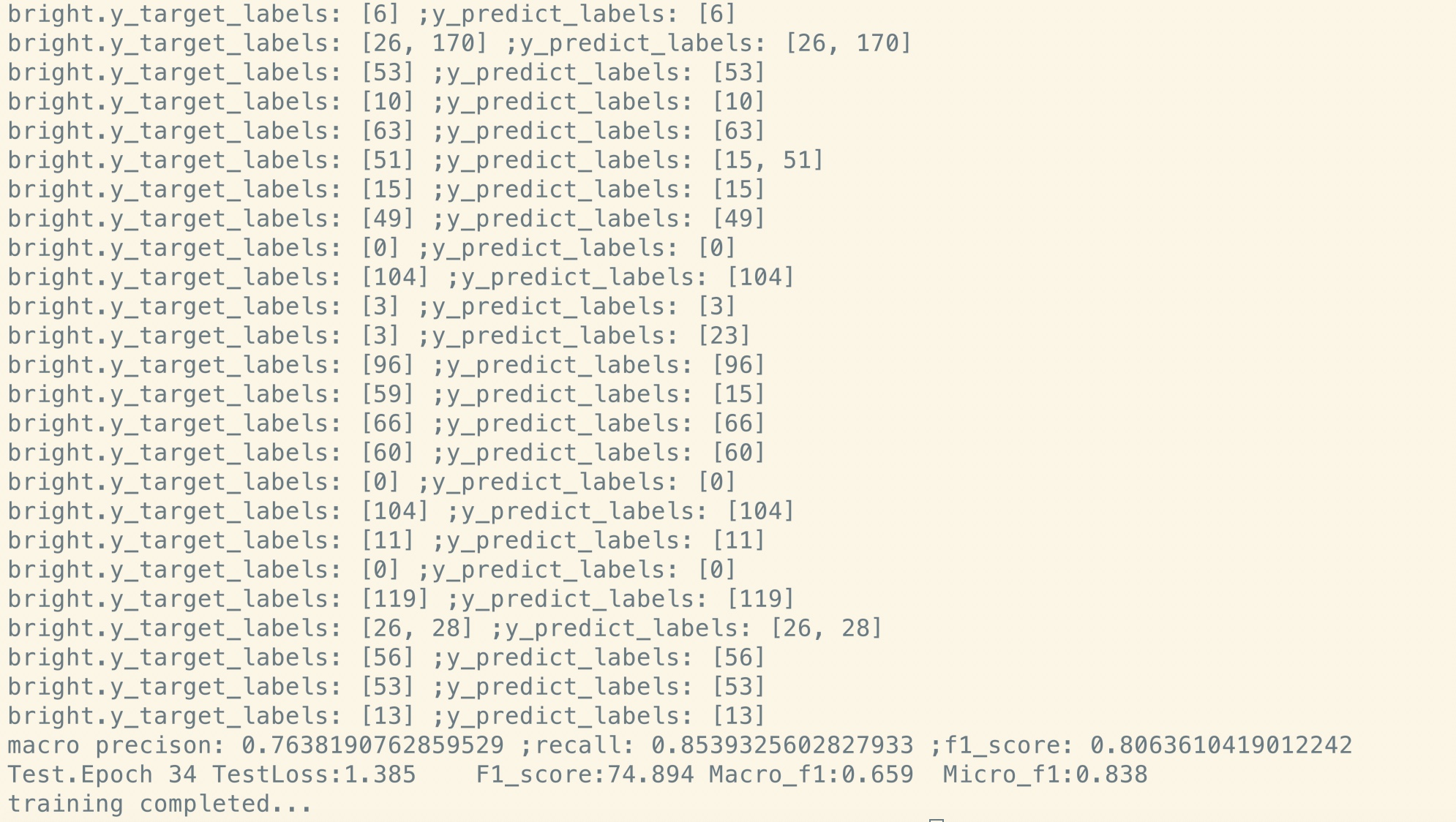
Tuning fino após o pré-treino:
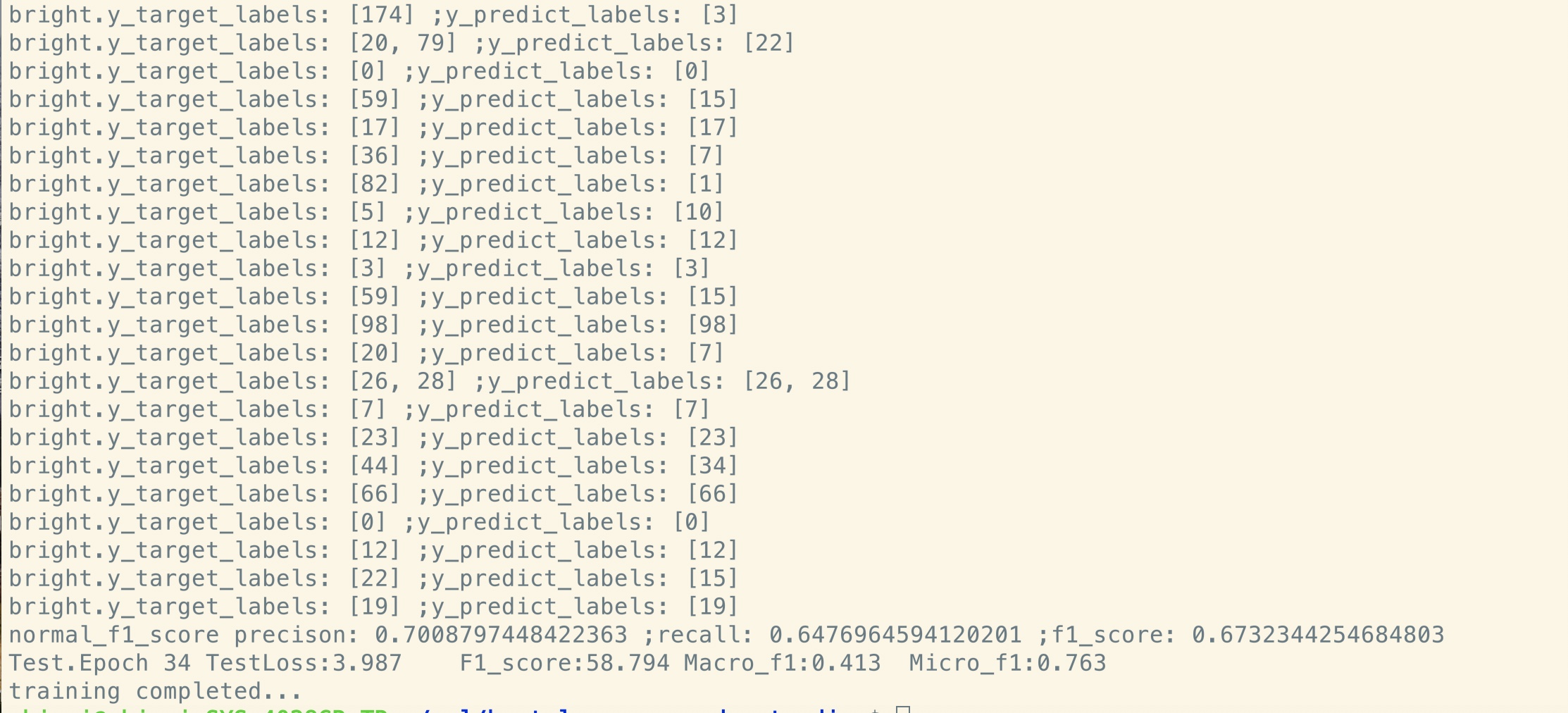
Sem pré-treino:
Conjunto de dados de tamanho pequeno (privado, 100k)
| Modelo | TextCnn (sem-pré-fixação) | Textcnn (pré-train-finetuning) | Ganho do pré-treino |
|---|---|---|---|
| Pontuação F1 após 1 época | 0,44 | 0,57 | 10%+ |
| Perda de validação após 1 época | 55.1 | 1.0 | 54.1 |
| Perda de treinamento no começo | 68.5 | 8.2 | 60.3 |
Se você quiser experimentar Bert com pré-treino de modelo de idioma mascarado e ajuste fino. Dê dois passos:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Como você pode ver, mesmo no ponto de início do ajuste fino, logo após os parâmetros de restauração do modelo pré-treinado, a perda de modelo é menor
do que o treinamento da pontuação completamente nova e a pontuação de F1 também é maior, enquanto o novo modelo pode começar de 0.
AVISO: Para ajudá-lo a experimentar a nova ideia primeiro, você pode definir test-paramater test_mode como true. Ele apenas carregará poucos dados e começará a treinar rapidamente.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
d_model: dimensão do modelo. [512]
NUM_LAYER: Número de camadas. [6]
NUM_HEADER: Número de cabeçalhos de auto-atenção [8]
d_k: dimensão da chave (k). A dimensão da consulta (Q) é a mesma. [64]
D_V: dimensão de V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Cada linha é documento (várias frases) ou uma frase. Esse é o texto livre, você pode obter facilmente.
Verifique os dados/bert_train.txt ou bert_train2.txt no arquivo zip.
A entrada e saída estão na mesma linha, cada rótulo é iniciado com ' etiqueta '.
Há um espaço entre a sequência de entrada e a primeira etiqueta, cada rótulo também é dividido por um espaço.
por exemplo, token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
Verifique os dados/bert_train.txt ou bert_train2.txt no arquivo zip.
Verifique a pasta 'dados' para obter dados de amostra. Carregar para baixo um conjunto de dados de tamanho médio aqui
Com 450k 206 classes, cada entrada é um documento, o comprimento médio é de cerca de 300, um ou multi-rótulo associado à entrada.
Baixe a incorporação de palavras antes do treino do tencent Ailab
As coisas podem ser fáceis:
Baixe o conjunto de dados (cerca de 200m, dados 450k, com algum arquivo de cache), descompacte -os e coloque -os em dados/ pasta,
execute a etapa 1 para pré-treino,
e execute a etapa 2 para ajuste fino.
Termino acima de três etapas e quero ter um desempenho melhor, como posso fazer mais. Preciso encontrar um grande conjunto de dados?
Não. Você pode gerar um Big Data definido para o estágio pré-trep, baixando um texto livre, verifique se cada linha
é um documento ou frase, substitua os dados/bert_train2.txt pelo seu novo arquivo de dados.
O que há mais?
Experimente um grande hiper-parâmetro ou modelo grande (substituindo a rede de backbone) Util, você pode observar todos os dados pré-trep.
Jogue com o modelo: Model/bert_cnn_model.py ou verifique o pré-processo com data_util_hdf5.py.
Modelo de idioma de purê de pré -atrain e a próxima tarefa de previsão de frases em larga escala de corpus,
Com base no modelo de auto-atendimento de múltiplas camadas, depois adicione uma camada de classificação.
Como o modelo BERT é baseado no transformador, atualmente estamos trabalhando na tarefa Adicionar Pré -TRARAN ao modelo.
Aviso: o CAIL2018 está em torno de 450k como link acima.
O tamanho do treinamento do conjunto de dados privado é de cerca de 100k, o número de classes é 9, pois cada entrada existe um ou mais rótulos.
A pontuação F1 para CAIL2018 é relatada como pontuação micro F1.
A ideia básica é muito simples. Por vários anos, as pessoas estão obtendo resultados muito bons "pré-treinamento" DNNs como modelo de idioma
e depois o ajuste fino em alguma tarefa a jusante de PNL (resposta a perguntas, inferência de linguagem natural, análise de sentimentos etc.).
Os modelos de idiomas geralmente são da esquerda para a direita, por exemplo:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
O problema é que, para a tarefa a jusante que você geralmente não deseja um modelo de idioma, você deseja uma melhor representação contextual possível de
cada palavra. Se cada palavra só puder ver o contexto à sua esquerda, claramente está faltando muito. Então, um truque que as pessoas fizeram é também treinar um
Modelo da direita para a esquerda, por exemplo:
P(store|</s>)*P(a|store </s>)*…
Agora você tem duas representações de cada palavra, uma da esquerda para a direita e uma da direita para a esquerda, e pode concatená-las juntas para sua tarefa a jusante.
Mas, intuitivamente, seria muito melhor se pudéssemos treinar um único modelo profundamente bidirecional.
Infelizmente, é impossível treinar um modelo bidirecional profundo como um LM normal, porque isso criaria ciclos onde as palavras podem indiretamente
"Veja a si mesmos", e as previsões se tornam triviais.
O que podemos fazer é o truque muito simples que é usado em incodes de auto-nois, onde mascaramos algum porcentagem de palavras da entrada e
tem que reconstruir essas palavras do contexto. Chamamos isso de "LM mascarado", mas é frequentemente chamado de tarefa de cloze.
Alimentamos a entrada através de um codificador de transformador profundo e depois usamos os estados ocultos finais correspondentes às posições mascaradas para
Preveja qual palavra foi mascarada, exatamente como se fôssemos um modelo de idioma.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Como obter o último estado oculto de posição (s) mascarada (s)?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Para mais detalhes, verifique o método de Mask_Language_model de pretain_task.py e trens_vert_lm.py
Muitas tarefas de entendimento de idiomas, como resposta a perguntas, inferência, precisam entender o relacionamento
entre a frase. No entanto, o modelo de idioma só é capaz de entender sem uma frase. Próxima frase
A previsão é uma tarefa de amostra para ajudar o modelo a entender melhor nesses tipos de tarefas.
50% da chance A segunda frase é a próxima frase do primeiro, 50% do próximo.
Dada duas frases, o modelo é solicitado a prever se a segunda frase é a próxima frase real de
o primeiro.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
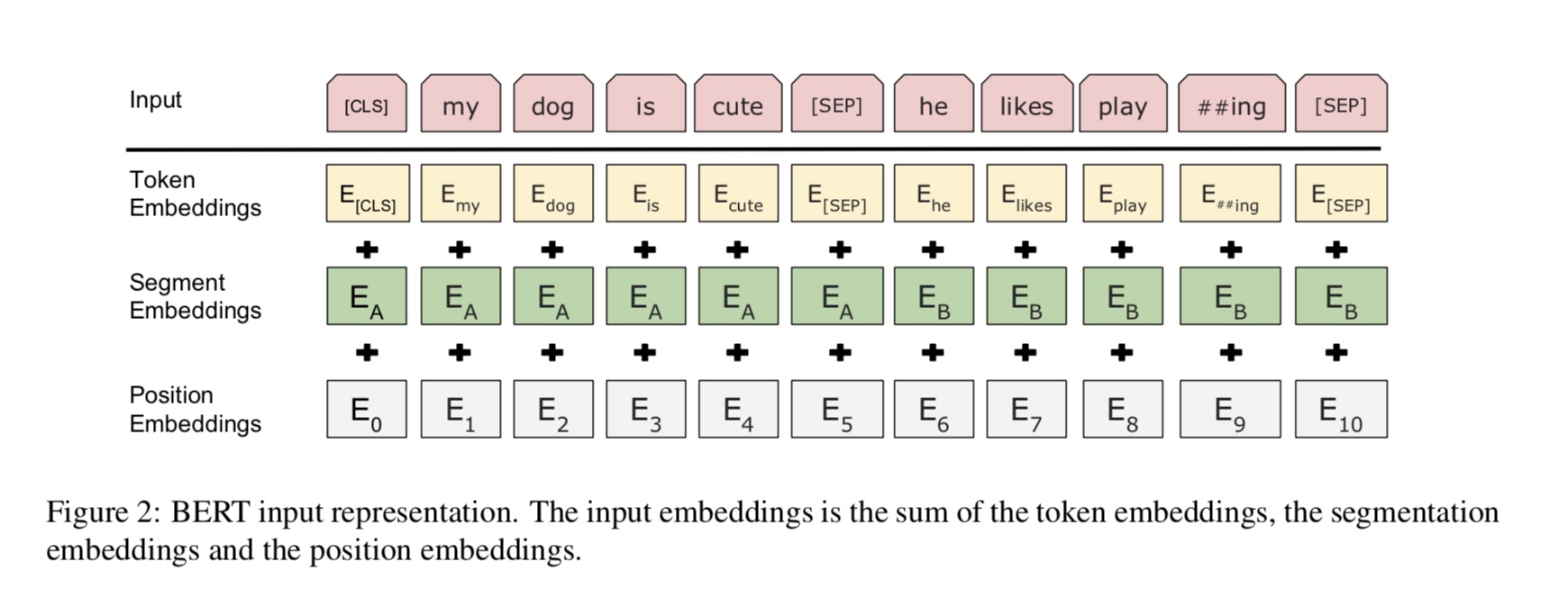
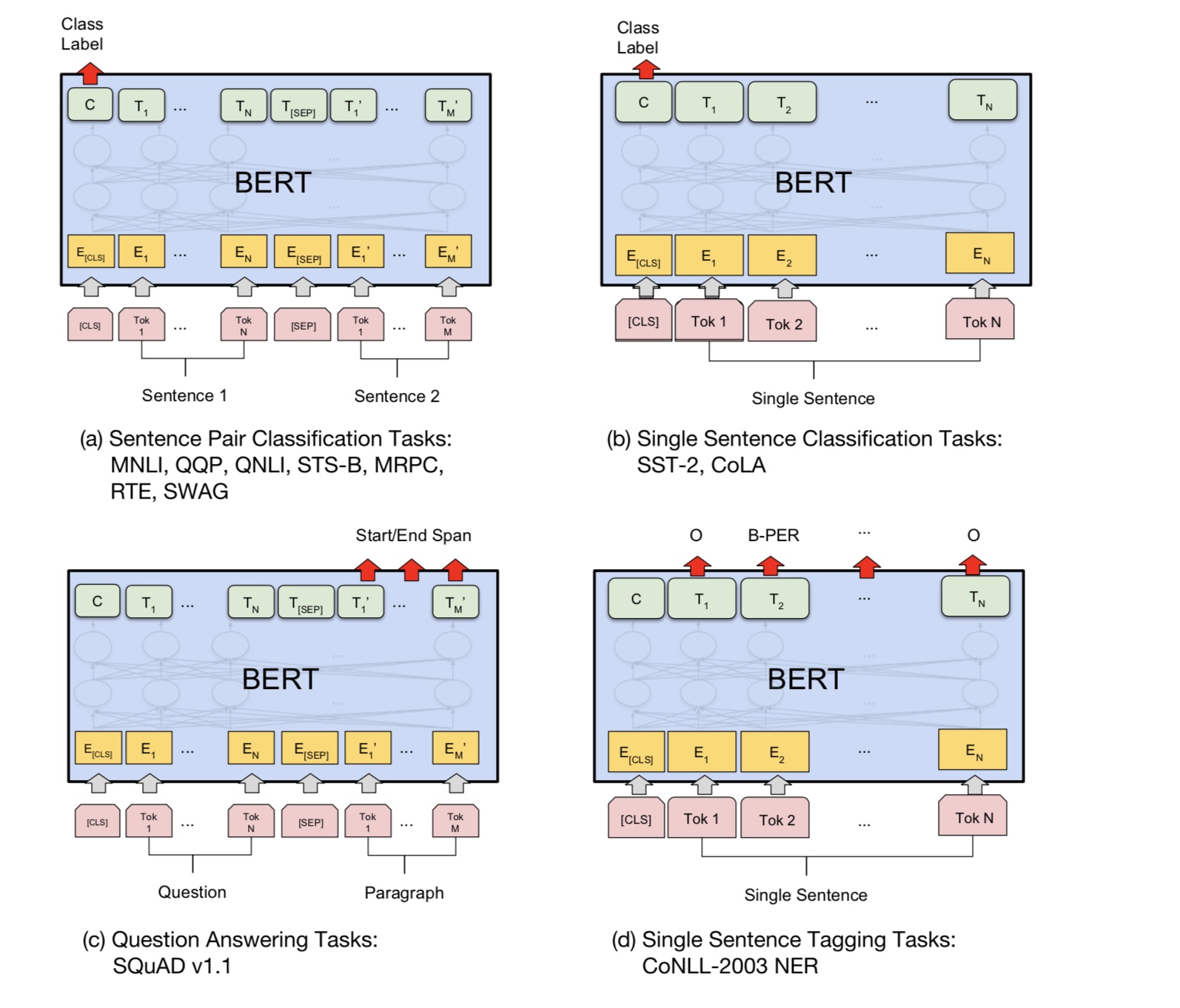
Python 3+ Tensorflow 1.10
Que compartilhamento e não compartilham entre os estágios pré-treinos e de ajuste fino?
1). Basicamente, todos os parâmetros da rede de backbone usados por estágios de pré-treinio e ajuste fino são compartilhados.
2). Como podemos compartilhar parâmetros o máximo possível, para que durante o estágio de ajuste fino precisamos aprender como poucos
O parâmetro é o possível, também compartilhamos a incorporação de palavras para esses dois estágios.
3). Portanto, a maioria dos parâmetros já foi aprendida no início do estágio de ajuste fino.
Como implementamos o modelo de linguagem mascarado?
Para fazer as coisas facilmente, geramos frases a partir de documentos, dividimos -os em frases. para cada frase
Truncamos e preenchemos o mesmo comprimento e selecionamos aleatoriamente uma palavra e depois substituímos por [máscara], seu eu e um aleatório
palavra.
Como tornar o estágio de ajuste fino mais eficiente, embora não quebre o resultado e o conhecimento que aprendemos com o estágio de pré-trens?
Usamos uma pequena taxa de aprendizado durante o ajuste fino, para que o ajuste foi feito em pequena parte.
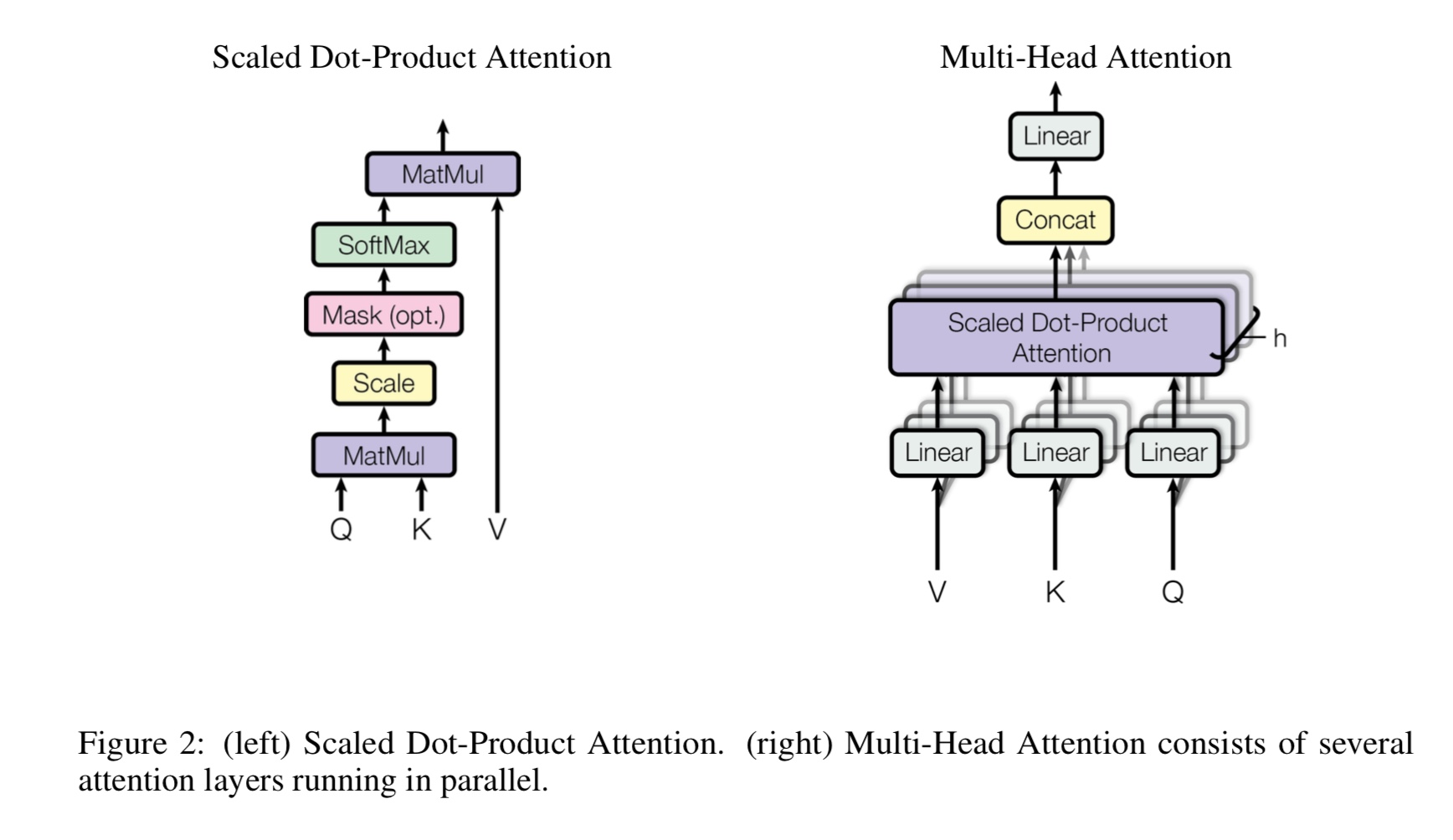
Por que precisamos de auto-parceria?
ATAÇÃO DE AUTO AUTO Um novo tipo de rede recentemente ganha cada vez mais atenção. Tradicionalmente, usamos
RNN ou CNN para resolver o problema. No entanto, o RNN tem um problema em paralelo e a CNN não é boa em tarefas sensíveis à posição do modelo.
A auto-atimento pode ser executada em paralelo, embora capaz de modelar a dependência de longa distância.
O que é a auto-distribuição de várias cabeças, o que significa Q, K, V? Adicione algo aqui.
A auto-atimento das cabeças de Mulit é uma auto-atenção, enquanto divide e projeta Q e K em vários subespaços diferentes,
Então faça a atenção.
q Faça uma pergunta, k representa chaves. Para a tarefa de tradução da máquina, q é um estado de decodificação anterior anterior, k representa
Estados ocultos do codificador. Cada um dos elementos de K calculará uma pontuação de similaridade com Q. e então softmax será usado
Para fazer a pontuação normalizada, teremos pesos. Finalmente, uma soma ponderada é calculada usando pesos aplicados a v.
Mas, no cenário de auto-ataque, Q, K, V são iguais, como a representação das seqüências de entrada de uma tarefa.
O que é o feedFoward em posição?
É uma camada de alimentação para a frente, também chamada de camada totalmente conectada (FC). mas desde o transformador, toda a entrada e saída de
As camadas são sequência de vetores: [sequence_length, d_model]. Geralmente fazemos FC a um vetor de entrada. Então fazemos de novo,
Mas a etapa de tempo diferente tem seu próprio FC.
Qual é a principal contribuição de Bert?
Embora a tarefa pré-trein
e use -o para tarefa de fluxo. como dados para o modelo de idioma está em toda parte. provou ser poderoso e, portanto, remodelar
NLP World.
Por que o autor usa três tipos diferentes de tokens ao gerar dados de treinamento do modelo de linguagem mascarada?
Os autores acreditam que, no estágio de ajuste fino, não há token [máscara]. Portanto, ele incompatibilidade entre pré-treino e ajuste fino.
Também force o modelo a atenção todas as informações de contexto em uma frase.
O que fez o modelo Bert para alcançar um novo estado da arte resultar em tarefas de compreensão de idiomas?
Grande modelo, grande computação e, o mais importante,-o algoritmo de nova pré-trep the Model usando dados de texto livre.
A tarefa de brinquedo é usada para verificar se o modelo pode funcionar corretamente sem depender de dados reais.
Ele pede ao modelo para contar números e resumir de todas as entradas. e um limiar é usado,
Se a soma for maior (ou menos) que um limite, o modelo precisará prever como 1 (ou 0).
Modelo interno/transform_model.py, existe um método de trem e previsão.
Primeiro, você pode executar o trem () para começar o treinamento e depois executar previsto () para iniciar a previsão usando o modelo treinado.
Como o modelo é muito grande, com o HyperParparamter padrão (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6), requer muitos dados antes que possam convergir.
Pelo menos 10k etapas são necessárias, antes que a perda se torne menor que 0,1. Se você quiser treiná -lo rápido com pequeno
Dados, você pode usar um pequeno conjunto de hiperparmeter (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Você pode usá-lo dois problemas de classificação binária, classificação de várias classes ou classificação de vários rótulos.
Imprimirá a perda durante o treinamento e imprimirá a pontuação de F1 para cada época durante a validação.
Corrija um bug no transformador [importante, recrute um membro da equipe e precisa de uma solicitação de mesclagem]
(Transformador: Por que a perda de estágio pré-treino é diminuição para o estágio inicial, mas a perda ainda não é tão pequena (por exemplo, perda = 8,0)? Mesmo com
Mais dados pré-trep, a perda ainda não é pequena)
Tarefa de pares de frases de suporte [importante, recrute um membro da equipe e precisa de uma solicitação de mesclagem]
Adicione a tarefa pré-treining da próxima previsão de frases [importante, recrute um membro da equipe e precisa de uma solicitação de mesclagem]
Precisa de um conjunto de dados para análise de sentimentos ou classificação de texto em inglês [importante, recrute um membro da equipe e precisa de uma solicitação de mesclagem]
A incorporação de posição ainda não é compartilhada entre o pré-treino e o ajuste fino. já que aqui na duração do estágio pré-trepador pode
estágio mais curto que o ajuste fino.
Handle Special Primeiro Token [CLS] como entrada e classificação [feito]
Pré-trep com fine_tuning: Precisa de um vocabulário de carga de tokens do estágio pré-trep, mas rótulos da tarefa real. [FEITO]
A taxa de aprendizado deve ser menor quando o ajuste fino. [Feito]
Pré-trep é tudo o que você precisa. Ao usar o Transformer ou algum outro modelo profundo complexo, pode ajudá -lo a alcançar o desempenho superior
Em algumas tarefas, o pré-extrair com outro modelo, como o TextCNN, usando uma enorme quantidade de dados brutos e depois ajustando seu modelo no conjunto de dados específico da tarefa,
sempre ajudará você a obter desempenho adicional.
Adicione mais aqui.
Adicione sugestão, problema ou deseja fazer uma contribuição, bem -vindo ao contato comigo: [email protected]
Atenção é tudo que você precisa
Bert: pré-treinamento de transformadores bidirecionais profundos para compreensão de idiomas
Tensor2tensor para tradução para máquinas neurais
Redes neurais convolucionais para classificação de frases
CAIL2018: Um conjunto de dados legal em larga escala para previsão de julgamento


