bert_language_understanding
1.0.0
Bert logra un nuevo resultado de estado de arte en más de 10 tareas de PNL recientemente.
Esta es una implementación de TensorFlow de la capacitación previa de transformadores bidireccionales profundos para la comprensión del lenguaje
(Bert) y la atención es todo lo que necesitas (transformador).
ACTUALIZACIÓN: Se realizó la parte mayoritaria de las ideas principales replicadas de estos dos documentos, hay una aparente ganancia de rendimiento
Para pre-entrenado, un modelo y ajuste fino compare para entrenar el modelo desde cero.
Hemos realizado un experimento para reemplazar la red troncal de Bert de Transformer a TextCnn, y el resultado es que
Pre-entrenado El modelo con modelo de lenguaje enmascarado que utiliza muchos datos sin procesar puede aumentar el rendimiento en una cantidad notable.
En términos más generales, creemos que la estrategia de pre-entrenado y ajuste fino es independiente de la tarea independiente y pre-entrenamiento independiente.
Dicho esto, puede reemplazar la red troncal como desee. y agregue más tareas previas al tren o defina algunas nuevas tareas de pre-entrenamiento como
Puede que el pre-entrante no se limitará al modelo de lenguaje enmascarado o predecir la tarea de la siguiente oración. Lo que nos sorprende es que,
Con un conjunto de datos de tamaño medio que, por ejemplo, un millón, incluso sin uso de datos externos, con la ayuda de la tarea de pre-entrenamiento
Al igual que el modelo de lenguaje enmascarado, el rendimiento puede ser impulsado en un gran margen, y el modelo puede converger aún rápido. a veces
El entrenamiento puede estar en un solo necesidad de una época en la etapa de ajuste fino.
Mientras que hay un código abierto (tensor2tensor) y oficial
Implementación de la implementación oficial de Transformer y Bert Próximamente, pero es difícil de leer, no es fácil de entender.
No tenemos la intención de replicar los documentos originales por completo, sino aplicar las ideas principales y resolver el problema de PNL de una mejor manera.
La parte mayoritaria para el trabajo aquí fue realizada por otro repositorio el año pasado: Clasificación de texto
Conjunto de datos de tamaño medio (Cail2018, 450k)
| Modelo | Textcnn (sin pretratamiento) | TextCnn (Pretrain-Finetuning) | Ganancia del pre-tren |
|---|---|---|---|
| Puntaje F1 después de 1 época | 0.09 | 0.58 | 0.49 |
| Puntuación F1 después de 5 época | 0.40 | 0.74 | 0.35 |
| Puntuación F1 después de 7 época | 0.44 | 0.75 | 0.31 |
| Puntaje F1 después de 35 época | 0.58 | 0.75 | 0.27 |
| Pérdida de entrenamiento al comienzo | 284.0 | 84.3 | 199.7 |
| Pérdida de validación después de 1 época | 13.3 | 1.9 | 11.4 |
| Pérdida de validación después de 5 época | 6.7 | 1.3 | 5.4 |
| Tiempo de entrenamiento (GPU único) | 8h | 2h | 6h |
Aviso:
A. La etapa de ajuste de fino completó el entrenamiento después de solo correr 7 época cuando Max Epoch llegó a 35.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
El puntaje C.F1 informado aquí está en el conjunto de validación, un promedio de micro y macro de puntaje F1.
La puntuación D.F1 después de 35 época se informa en el conjunto de pruebas.
mi. De 450k documentos sin procesar, recuperó 2 millones de datos de capacitación para el modelo de lenguaje enmascarado,
pre-train stage finished within 5 hours in single GPU.
Ajuste fino después del pre-tren:
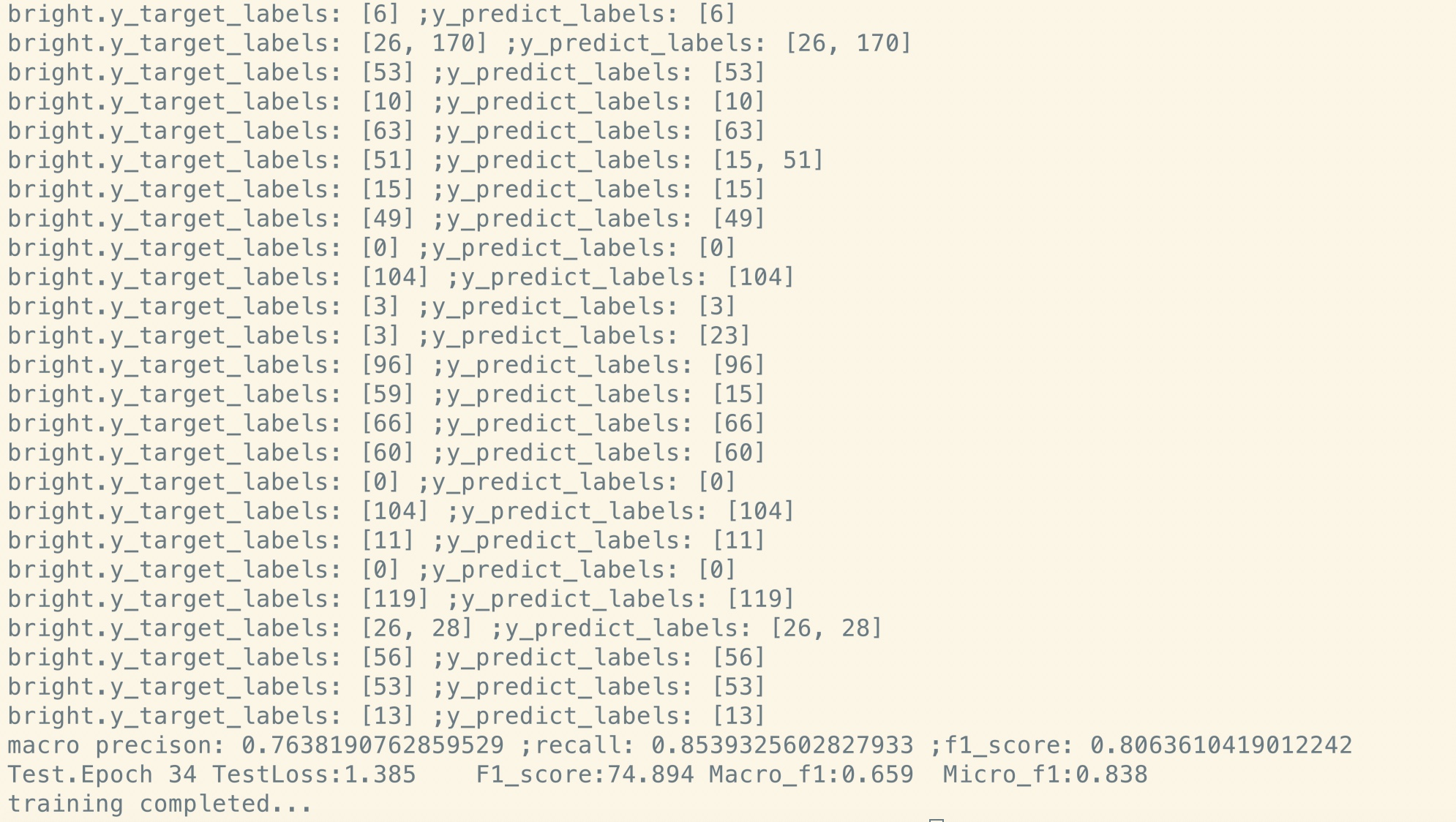
Sin pre-entrenado:
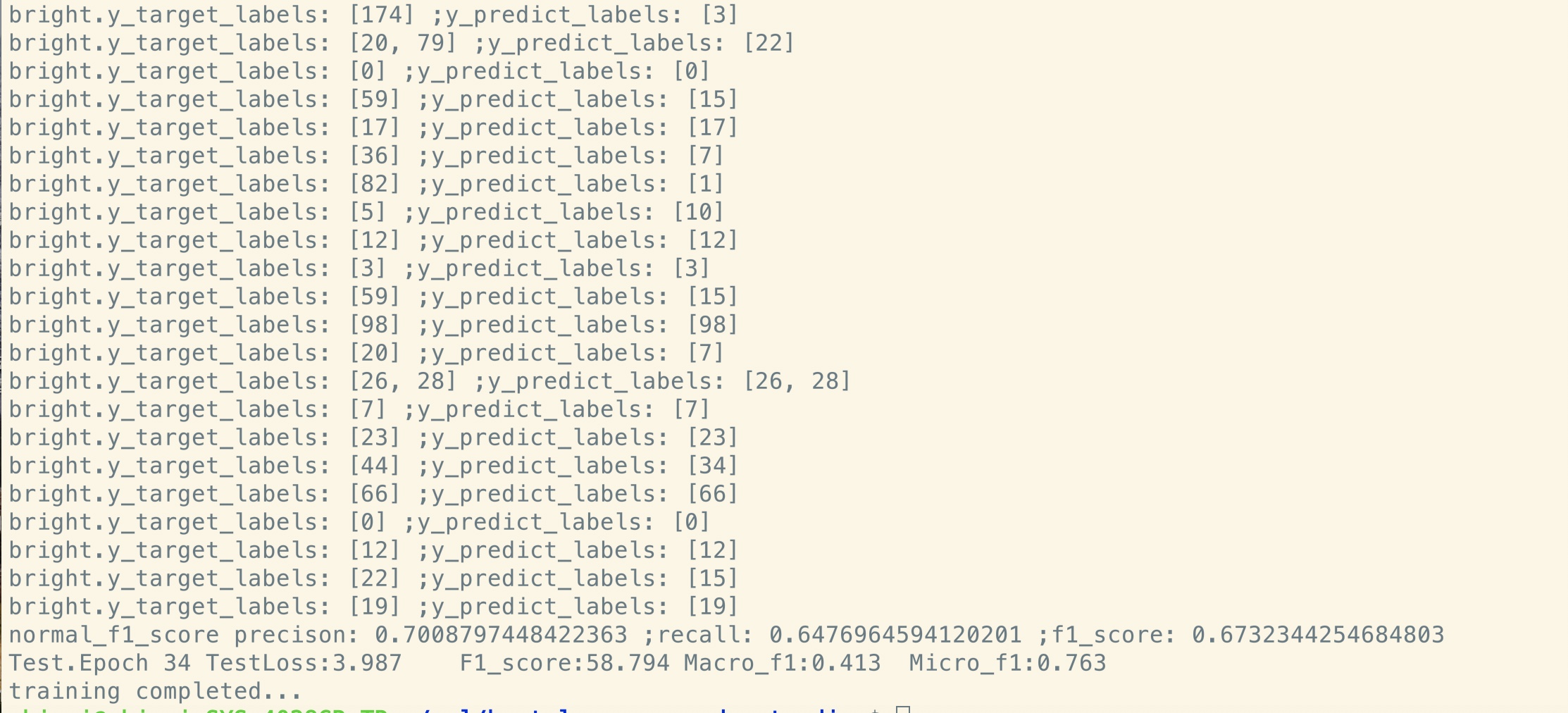
Conjunto de datos de tamaño pequeño (privado, 100k)
| Modelo | Textcnn (sin pretratamiento) | TextCnn (Pretrain-Finetuning) | Ganancia del pre-tren |
|---|---|---|---|
| Puntaje F1 después de 1 época | 0.44 | 0.57 | 10%+ |
| Pérdida de validación después de 1 época | 55.1 | 1.0 | 54.1 |
| Pérdida de entrenamiento al comienzo | 68.5 | 8.2 | 60.3 |
Si desea probar Bert con el modelo de lenguaje enmascarado y el ajuste fino. Da dos pasos:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Como puede ver, incluso en el punto de inicio del ajuste fino, justo después de la restauración de los parámetros del modelo previamente capacitado, la pérdida del modelo es más pequeña
que el entrenamiento desde completamente nuevo, y la puntuación F1 también es más alta, mientras que el nuevo modelo puede comenzar a partir de 0.
Aviso: para ayudarlo a probar una nueva idea primero, puede establecer Hyper-Paramater test_mode en verdadero. Solo cargará pocos datos y comenzará a entrenar rápidamente.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
d_model: dimensión del modelo. [512]
num_layer: número de capas. [6]
num_header: número de encabezados de autoatención [8]
D_K: Dimensión de la clave (k). La dimensión de la consulta (Q) es la misma. [64]
D_V: Dimensión de V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Cada línea es documento (varias oraciones) o una oración. Ese es un texto libre que puede obtener fácilmente.
Verifique datos/bert_train.txt o bert_train2.txt en el archivo zip.
La entrada y la salida están en la misma línea, cada etiqueta comienza con ' etiqueta '.
Hay un espacio entre la cadena de entrada y la primera etiqueta, cada etiqueta también es dividida por un espacio.
por ejemplo, token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
Verifique datos/bert_train.txt o bert_train2.txt en el archivo zip.
Verifique la carpeta 'Datos' para obtener datos de muestra. Cargue abajo un conjunto de datos de tamaño medio aquí
Con 450k 206 clases, cada entrada es un documento, la longitud promedio es de alrededor de 300, uno o una etiqueta múltiple asociada con la entrada.
Descargar la incrustación de palabras previas al tren de Tencent Ailab
Las cosas pueden ser fáciles:
Descargue el conjunto de datos (alrededor de 200 m, 450k datos, con algunos archivos de caché), descúplalo y colóquelo en datos/ carpeta,
Ejecutar el paso 1 para el pre-tren,
y ejecute el paso 2 para ajustar.
Termino por encima de tres pasos y quiero tener un mejor rendimiento, ¿cómo puedo hacer más? ¿Necesito encontrar un gran conjunto de datos?
No. Puede generar un conjunto de big data usted mismo para la etapa previa al entrenamiento descargando un texto gratuito, asegúrese de que cada línea
es un documento o oración, reemplace los datos/bert_train2.txt con su nuevo archivo de datos.
¿Qué es más?
Pruebe un gran hiper-parámetro o modelo grande (reemplazando la red de la red troncal) Utiliza que puede observar todos sus datos de pre-entrenamiento.
Juega con el modelo: modelo/bert_cnn_model.py, o verifique el preprocesamiento con data_util_hdf5.py.
Modelo de lenguaje de pretrano y tarea de predicción de la siguiente oración a gran escala de corpus,
Basado en el modelo de auto attación múltiple de capa, luego ajuste fino mediante agregar una capa de clasificación.
Como el modelo BERT se basa en Transformer, actualmente estamos trabajando en la tarea Agregar Pretrain al modelo.
Aviso: Cail2018 es de alrededor de 450k como enlace anterior.
El tamaño de la capacitación del conjunto de datos privados es de alrededor de 100k, el número de clases es 9, para cada entrada existen una o más etiquetas.
El puntaje F1 para Cail2018 se informa como puntaje Micro F1.
La idea básica es muy simple. Durante varios años, las personas han estado obteniendo muy buenos resultados de "pretración" como modelo de idioma
y luego ajustar una tarea de PNL aguas abajo (respuesta a las preguntas, inferencia del lenguaje natural, análisis de sentimientos, etc.).
Los modelos de lenguaje son típicamente de izquierda a derecha, por ejemplo:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
El problema es que para la tarea aguas abajo que generalmente no desea un modelo de idioma, desea la mejor representación contextual posible de
cada palabra. Si cada palabra solo puede ver el contexto a su izquierda, claramente falta mucho. Entonces, un truco que la gente ha hecho es entrenar también
modelo de derecha a izquierda, por ejemplo:
P(store|</s>)*P(a|store </s>)*…
Ahora tiene dos representaciones de cada palabra, una de izquierda a derecha y otra derecha a izquierda, y puede concatenarlas para su tarea aguas abajo.
Pero intuitivamente, sería mucho mejor si pudiéramos entrenar a un solo modelo que fuera profundamente bidireccional.
Desafortunadamente, es imposible entrenar un modelo bidireccional profundo como un LM normal, porque eso crearía ciclos donde las palabras pueden indirectamente
"Mira a sí mismos", y las predicciones se vuelven triviales.
Lo que podemos hacer en su lugar es el truco muy simple que se usa para desactivar los codificadores automáticos, donde enmascaramos algún porcentaje de palabras de la entrada y
tener que reconstruir esas palabras del contexto. Llamamos a esto un "LM enmascarado", pero a menudo se llama una tarea de cloze.
Alimentamos la entrada a través de un codificador de transformador profundo y luego usamos los estados ocultos finales correspondientes a las posiciones enmascaradas para
Predecir qué palabra estaba enmascarada, exactamente como entrenaríamos un modelo de idioma.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
¿Cómo obtener el último estado oculto de posiciones enmascaradas?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Para obtener más detalles, verifique el método de Mask_Language_Model desde Pretrain_Task.py y Train_vert_lm.py
Muchas tareas de comprensión del lenguaje, como la respuesta de las preguntas, la inferencia, necesitan entender la relación
entre oración. Sin embargo, el modelo de idioma solo puede entender sin una oración. Siguiente oración
La predicción es una tarea de muestra para ayudar a modelar a comprender mejor en este tipo de tareas.
50% de la posibilidad La segunda oración es la próxima oración de la primera, el 50% de no la siguiente.
Dada dos oraciones, se le pide al modelo que predice si la segunda oración es real la próxima oración de
el primero.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
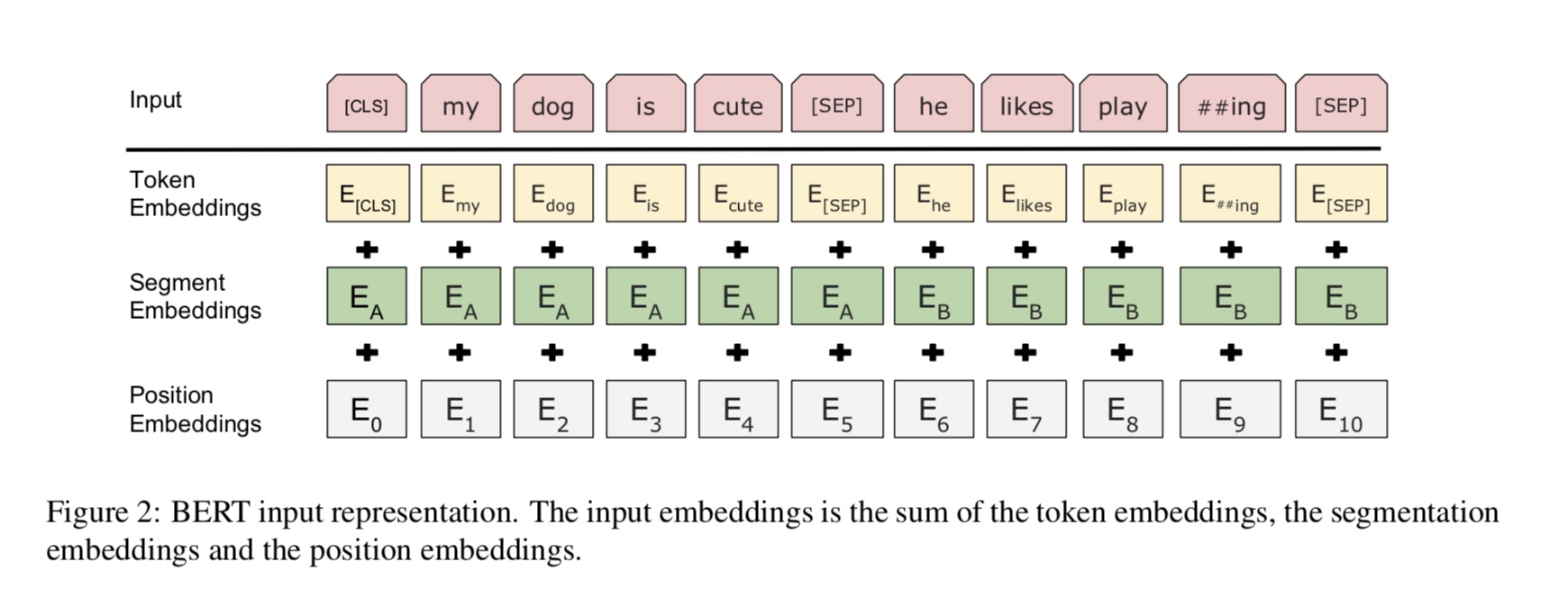
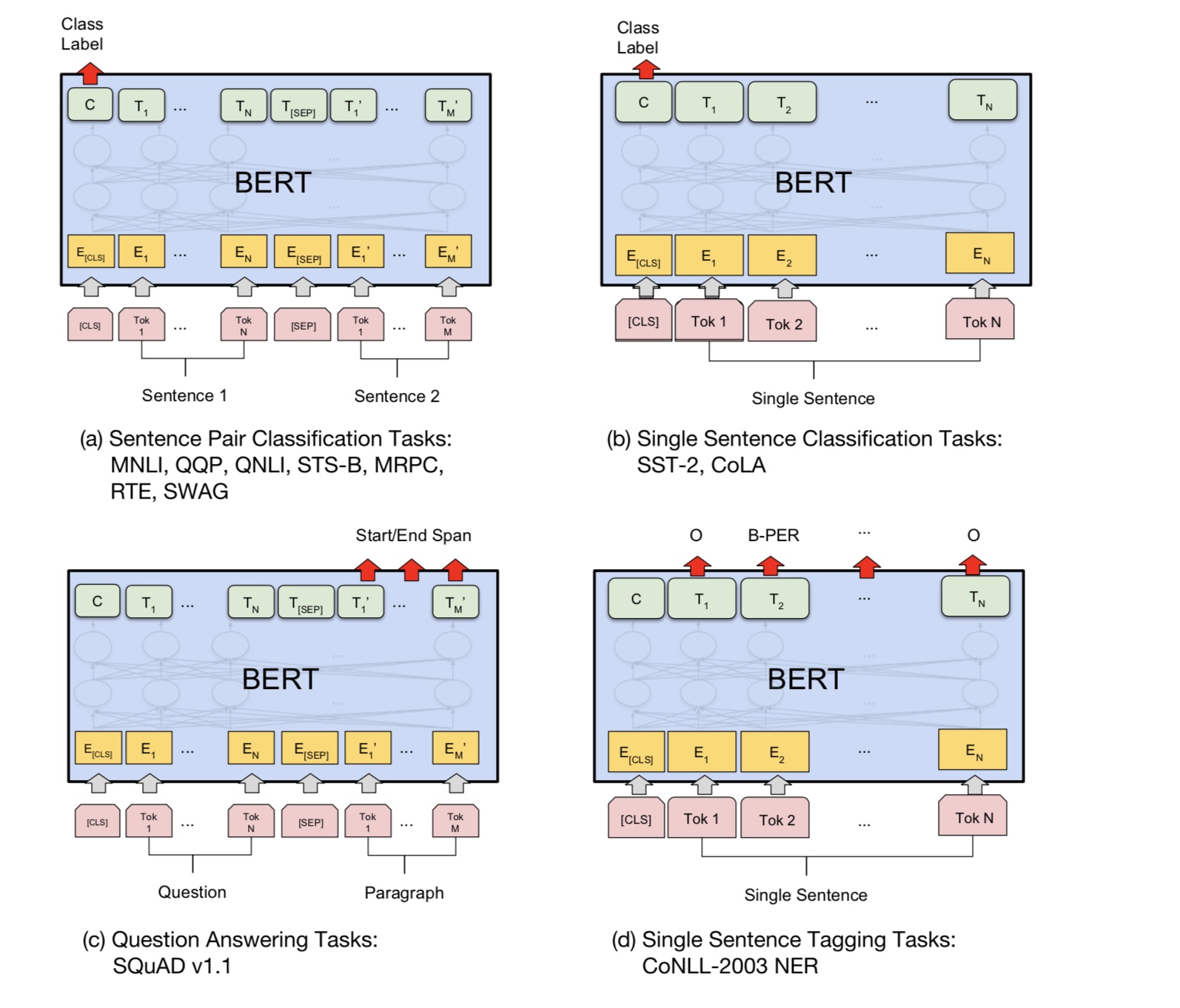
Python 3+ TensorFlow 1.10
¿Qué compartir y no compartir entre las etapas previas y ajustadas?
1). Básicamente, todos los parámetros de la red troncal utilizada por las etapas de pre-entrenamiento y ajuste fino se comparten entre sí.
2). Como podemos compartir parámetros tanto como sea posible, de modo que durante la etapa de ajuste fino necesitemos aprender tan pocos
Parámetro como sea posible, también compartimos la incrustación de palabras para estas dos etapas.
3). Por lo tanto, la mayoría de los parámetros ya se aprendieron al comienzo de la etapa de ajuste.
¿Cómo implementamos el modelo de lenguaje enmascarado?
Para hacer las cosas fácilmente, generamos oraciones de documentos, las dividimos en oraciones. por cada oración
Lo truncamos y la acolchamos a la misma longitud, y seleccionamos al azar una palabra, luego la reemplazamos con [máscara], su yo y un azar
palabra.
¿Cómo hacer que la etapa de ajuste fino sea más eficiente, mientras que no rompa el resultado y el conocimiento que aprendimos de la etapa previa al entrenamiento?
Utilizamos una pequeña tasa de aprendizaje durante el ajuste fino, de modo que el ajuste se realizó en una medida.
¿Por qué necesitamos autoatención?
Autoatención Un nuevo tipo de red recientemente obtiene más y más atención. Tradicionalmente usamos
RNN o CNN para resolver el problema. Sin embargo, RNN tiene un problema en paralelo, y CNN no es bueno en las tareas sensibles a la posición del modelo.
La autoatición puede funcionar en paralelo, mientras que puede modelar la dependencia de larga distancia.
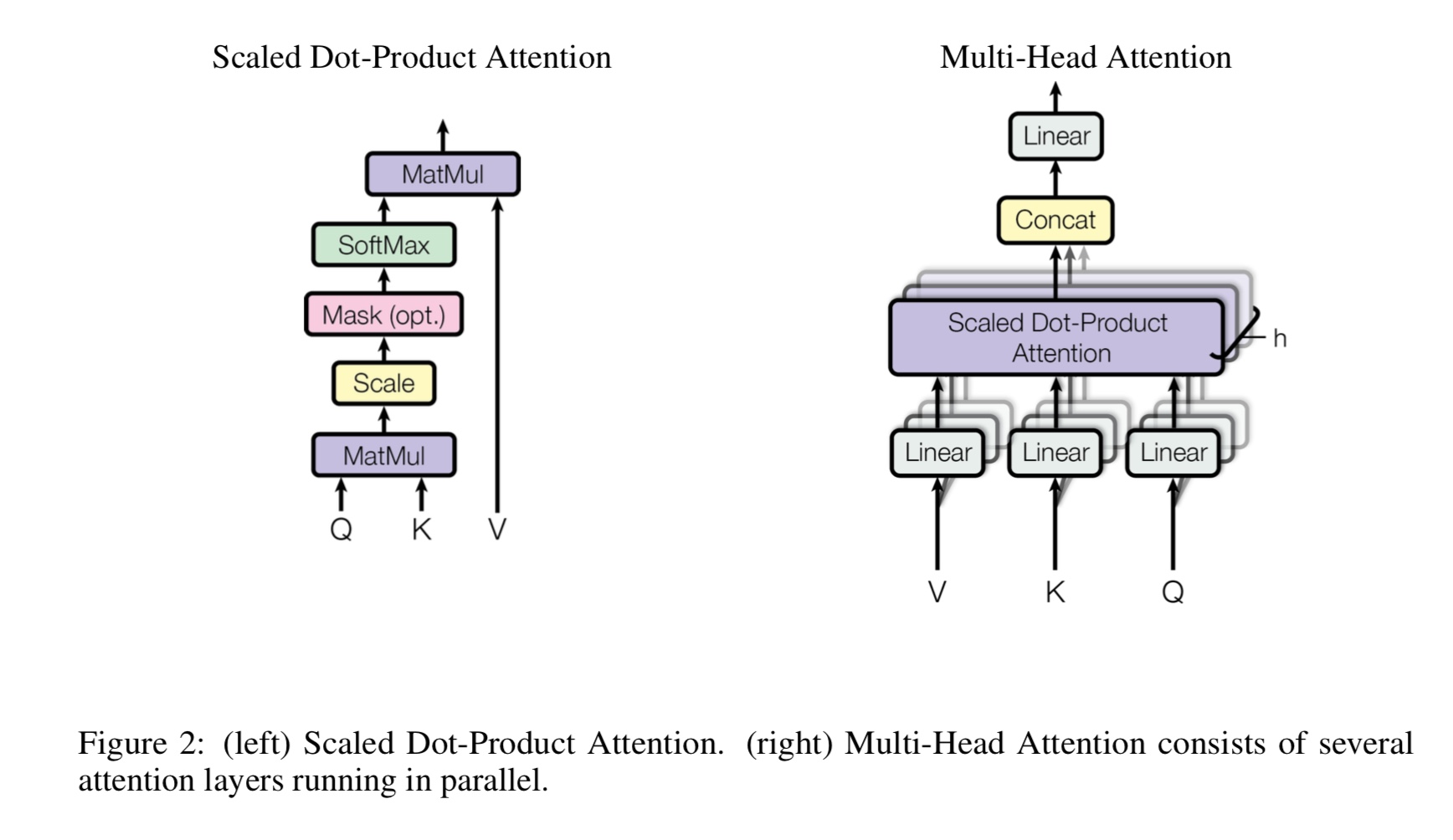
¿Qué es la autoatención de múltiples cabezas, qué representa Q, K, V? Agregue algo aquí.
La autoatención de Mulit-Heads es una autoatención, mientras se divide y el proyecto Q y K en varios subespacios diferentes,
Entonces haz atención.
P Pasar una pregunta, K defiende las teclas. Para la tarea de traducción automática, Q es un estado oculto previo de decodes, K representa
estados ocultos del codificador. Cada uno de los elementos de K calculará una puntuación de similitud con q. Y luego se utilizará Softmax
Para normalizar el puntaje, obtendremos pesos. Finalmente, se calcula una suma ponderada utilizando pesos aplicados a V.
Pero en el escenario de autoatención, Q, K, V son todos los mismos, que la representación de secuencias de entrada de una tarea.
¿Qué es FeedFoward de Position-Wise?
Es una capa de avance de alimentación, también llamada capa totalmente conectada (FC). Pero dado que en Transformer, toda la entrada y salida de
Las capas son secuencia de vectores: [secuence_length, d_model]. Usualmente hacemos FC a un vector de entrada. Entonces lo hacemos de nuevo
Pero el paso de tiempo diferente tiene su propio FC.
¿Cuál es la principal contribución de Bert?
Si bien la tarea previa al entrenamiento ya existe durante muchos años, introduce una nueva forma (llamada bidireccional) para hacer un modelo de idioma
y úsalo para la tarea de transmisión hacia abajo. como datos para el modelo de idioma están en todas partes. resultó ser poderoso y, por lo tanto, se remodera
Mundo PNL.
¿Por qué el autor usa tres tipos diferentes de tokens al generar datos de capacitación del modelo de lenguaje enmascarado?
Los autores creen que en la etapa de ajuste fino no hay token [máscara]. Por lo tanto, no coincide entre pre-entrenado y ajuste fino.
También obliga al modelo a atención a toda la información de contexto en una oración.
¿Qué hizo que Bert Model para lograr un nuevo estado de arte resulte en tareas de comprensión del lenguaje?
Modelo grande, gran cálculo y, lo más importante, el nuevo algoritmo pre-entrenado, el modelo que usa datos de texto libre.
La tarea de juguete se usa para verificar si el modelo puede funcionar correctamente sin depender de datos reales.
Le pide al modelo que cuente los números y resume todas las entradas. y se usa un umbral,
Si la suma es mayor (o menos) que un umbral, entonces el modelo necesita predecirlo como 1 (o 0).
Inside Model/Transform_model.py, hay un método de tren y predicción.
Primero puede ejecutar Train () para comenzar a entrenar, luego ejecutar Predicte () para comenzar a predicción utilizando el modelo entrenado.
Como el modelo es bastante grande, con HyperParamter predeterminado (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6), requiere muchos datos antes de que pueda converger.
Se necesitan al menos 10k pasos, antes de que la pérdida sea inferior a 0.1. Si quieres entrenarlo rápido con pequeños
Datos, puede usar un pequeño conjunto de hiperparmeter (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Puede usarlo dos resolver clasificación binaria, clasificación de múltiples clases o problema de clasificación de múltiples etiquetas.
Imprimirá la pérdida durante el entrenamiento e imprimirá el puntaje F1 para cada época durante la validación.
corrige un error en Transformer [importante, recluta a un miembro del equipo y necesite una solicitud de fusión]
(Transformador: ¿Por qué la pérdida de la etapa previa al entrenamiento es una disminución para la etapa temprana, pero la pérdida aún no es tan pequeña (por ejemplo, pérdida = 8.0)? Incluso con
Más datos de pre-entrenamiento, la pérdida aún no es pequeña)
Tarea del par de oraciones de apoyo [importante, reclute a un miembro del equipo y necesita una solicitud de fusión]
Agregue la tarea previa al entrenamiento de la siguiente predicción de oraciones [importante, recluta a un miembro del equipo y necesite una solicitud de fusión]
Necesita un conjunto de datos para el análisis de sentimientos o la clasificación de texto en inglés [importante, reclutar a un miembro del equipo y necesita una solicitud de fusión]
La incrustación de posición aún no se comparte entre el entrenamiento previo y el ajuste fino. ya que aquí en la longitud de la etapa previa al tren puede
más corto que el escenario de ajuste fino.
Mango especial First Token [CLS] como entrada y clasificación [HECHO]
Precinete con Fine_Tuning: NECESITA VOCABULARIO DE CARGA DE TOKENS DESDE EL ETAPA DE PRINTO, PERO ESTÁS DE LA TAREA REAL. [HECHO]
La tasa de aprendizaje debe ser más pequeña al ajustar. [Hecho]
El entrenamiento previo es todo lo que necesitas. mientras que el uso de Transformer o algún otro modelo profundo complejo puede ayudarlo a lograr el rendimiento superior
En algunas tareas, prevén que otro modelo como TextCnn use una gran cantidad de datos sin procesar y luego ajuste su modelo en el conjunto de datos específicos de la tarea,
siempre te ayudará a obtener un rendimiento adicional.
Agregue más aquí.
Agregue sugerencia, problema o desee hacer una contribución, bienvenido a contactar conmigo: [email protected]
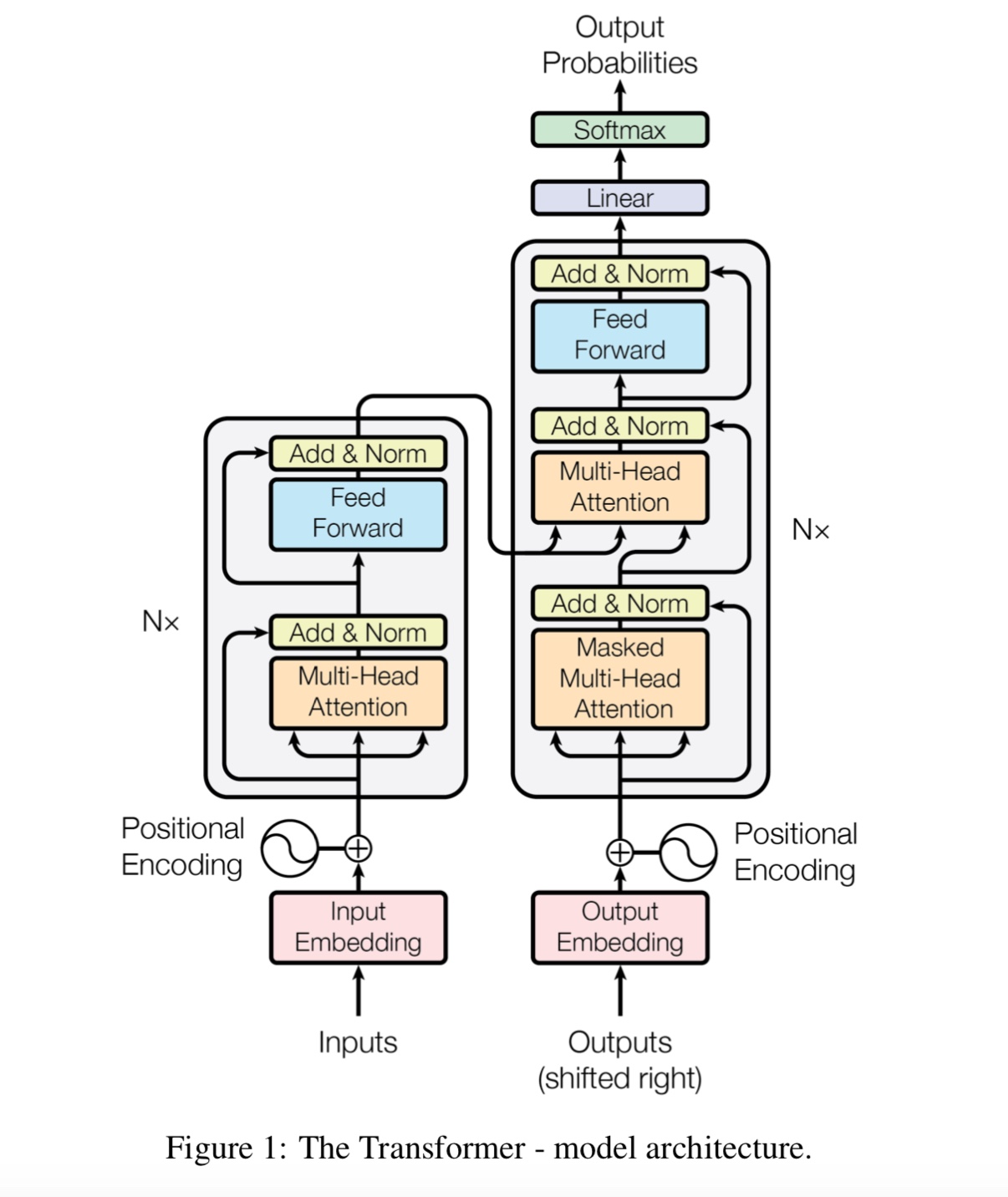
La atención es todo lo que necesitas
BERT: pretruamiento de transformadores bidireccionales profundos para la comprensión del lenguaje
Tensor2Tensor para traducción al automóvil neuronal
Redes neuronales convolucionales para la clasificación de oraciones
Cail2018: un conjunto de datos legal a gran escala para la predicción de juicio


