bert_language_understanding
1.0.0
Bert a réalisé de nouveaux résultats de pointe sur plus de 10 tâches NLP récemment.
Il s'agit d'une implémentation TensorFlow de la pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
(Bert) et l'attention est tout ce dont vous avez besoin (transformateur).
MISE À JOUR: La partie majoritaire des idées principales répliquées de ces deux articles a été réalisée, il y a un gain de performance apparent
Pour le pré-trajet, un modèle et un réglage fin comparent pour entraîner le modèle à partir de zéro.
Nous avons fait une expérience pour remplacer le réseau de squelette de Bert de Transformer à TextCNN, et le résultat est que
Pré-entraînant le modèle avec un modèle de langage masqué en utilisant de nombreuses données brutes peut augmenter les performances en un montant notable.
Plus généralement, nous pensons que la stratégie pré-trains et affinés est indépendante des modèles et pré-traditionnels indépendants.
Cela étant dit, vous pouvez remplacer le réseau de squelette comme vous le souhaitez. et ajouter plus de tâches prétraitées ou définir de nouvelles tâches pré-trains comme
Vous pouvez, pré-train ne se limitera pas au modèle de langue masquée et ou prédire la tâche de phrase suivante. Ce qui nous surprend, c'est que,
avec un ensemble de données de taille moyenne qui disent, un million, même sans utiliser de données externes, à l'aide d'une tâche pré-train
Comme le modèle de langage masqué, les performances peuvent être stimulées en grande marge et le modèle peut converger encore rapidement. un jour
La formation peut être dans un besoin seulement de quelques époques au stade de réglage fin.
Bien qu'il y ait une open source (tensor2tenseur) et officiel
Mise en œuvre de la mise en œuvre officielle de Transformer et de Bert à venir bientôt, mais il y a / peut être difficile à lire, pas facile à comprendre.
Nous n'avons pas l'intention de reproduire entièrement les articles originaux, mais d'appliquer les principales idées et de résoudre un problème de PNL d'une meilleure manière.
La partie majoritaire de travailler ici a été réalisée par un autre référentiel l'année dernière: Classification du texte
Ensemble de données de taille moyenne (CAIL2018, 450K)
| Modèle | Textcnn (sans prétraitement) | Textcnn (Pretrain-Finetuning) | Gain du pré-train |
|---|---|---|---|
| Score F1 après 1 époque | 0,09 | 0,58 | 0,49 |
| Score F1 après 5 époques | 0,40 | 0,74 | 0,35 |
| Score F1 après 7 époques | 0,44 | 0,75 | 0,31 |
| Score F1 après 35 époques | 0,58 | 0,75 | 0,27 |
| Perte de formation au début | 284.0 | 84.3 | 199.7 |
| Perte de validation après 1 époque | 13.3 | 1.9 | 11.4 |
| Perte de validation après 5 époques | 6.7 | 1.3 | 5.4 |
| Temps de formation (GPU unique) | 8h | 2h | 6h |
Avis:
A. étape de réglage de la finition a terminé la formation après avoir simplement exécuté 7 Epoch alors que Max Epoch a atteint 35 ans.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
Le score C.F1 rapporté ici est sur un ensemble de validation, une moyenne de micro et de macro de score F1.
Le score D.F1 après 35 Epoch est signalé sur le test de test.
e. À partir des documents bruts de 450k, récupéré 2 millions de données de formation pour le modèle de langue masquée,
pre-train stage finished within 5 hours in single GPU.
réglage fin après pré-transfert:
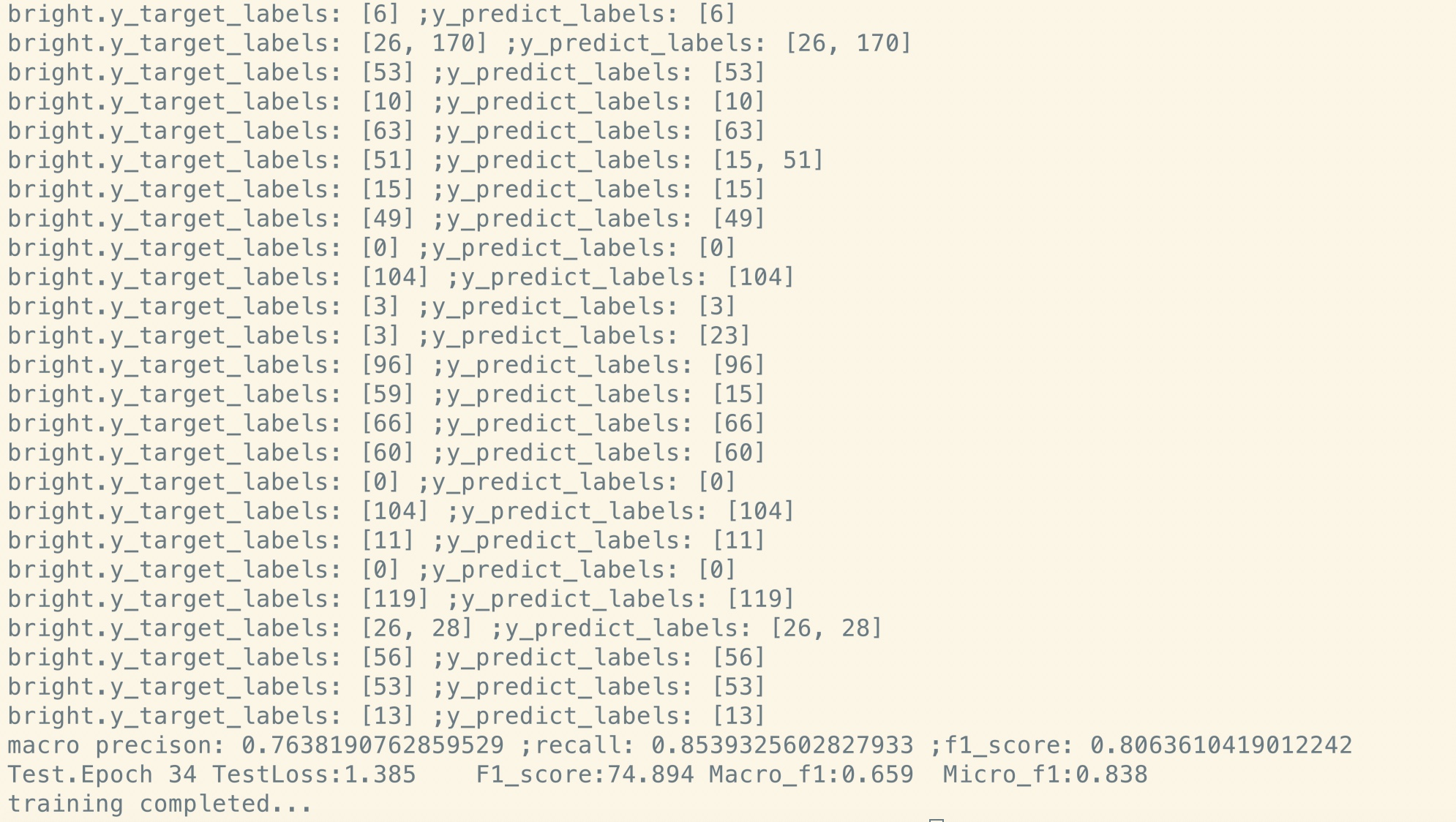
Pas de pré-train:
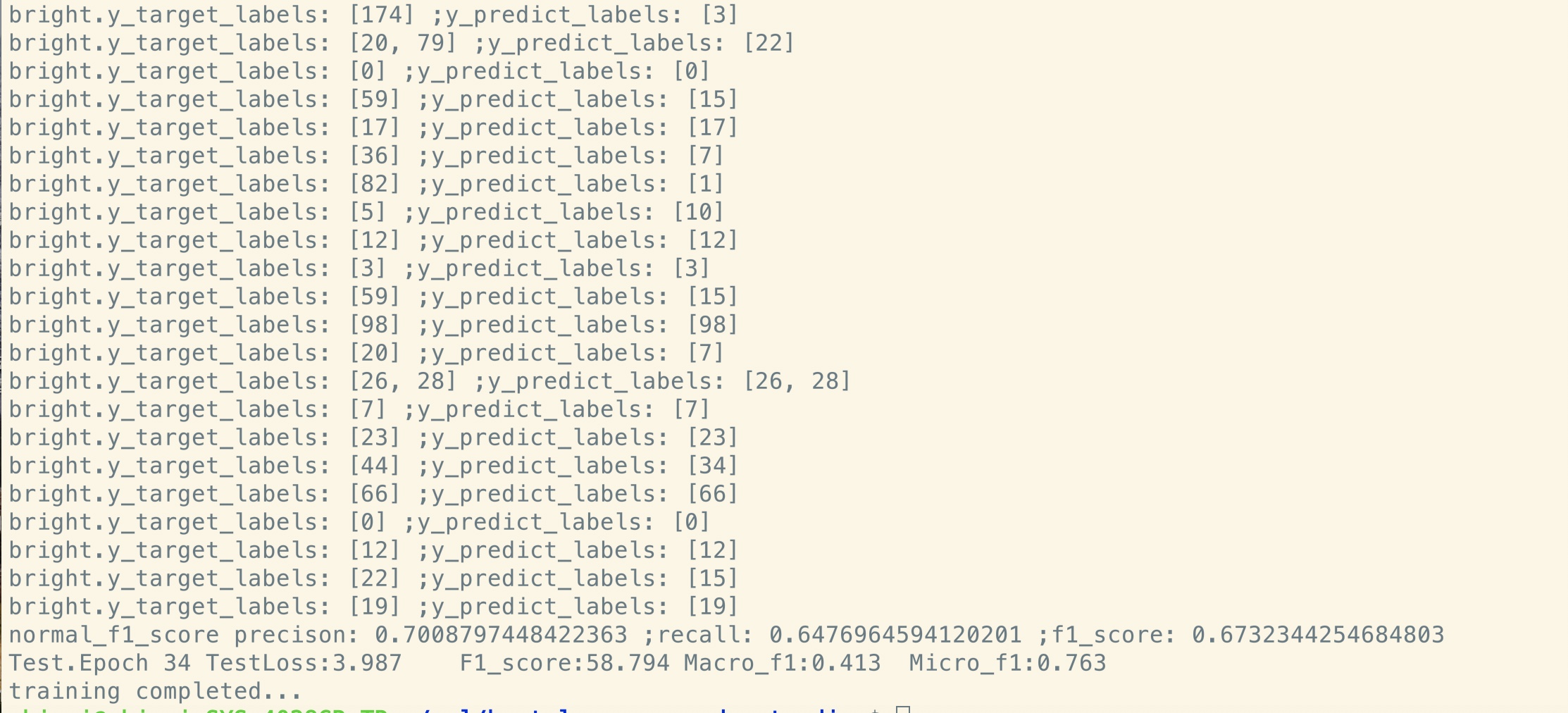
Ensemble de données de petite taille (privé, 100k)
| Modèle | Textcnn (sans prétraitement) | Textcnn (Pretrain-Finetuning) | Gain du pré-train |
|---|---|---|---|
| Score F1 après 1 époque | 0,44 | 0,57 | 10% + |
| Perte de validation après 1 époque | 55.1 | 1.0 | 54.1 |
| Perte de formation au début | 68.5 | 8.2 | 60.3 |
Si vous voulez essayer Bert avec un modèle de langage masqué et un réglage fin. Faites deux étapes:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Comme vous pouvez le voir, même au point de départ du réglage fin, juste après la restauration des paramètres du modèle pré-formé, la perte de modèle est plus petite
que la formation de complètement nouvelle, et le score F1 est également plus élevé tandis que le nouveau modèle peut commencer à partir de 0.
Remarque: Pour vous aider à essayer une nouvelle idée en premier, vous pouvez définir Hyper-Parmater Test_Mode sur true. Il ne chargera que peu de données et commencera à s'entraîner rapidement.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_Model: Dimension du modèle. [512]
num_layer: nombre de couches. [6]
NUM_HEADER: Nombre d'en-têtes d'auto-assertion [8]
D_K: dimension de la clé (k). La dimension de la requête (Q) est la même. [64]
d_v: dimension de V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Chaque ligne est un document (plusieurs phrases) ou une phrase. C'est du texte libre que vous pouvez obtenir facilement.
Vérifiez les données / bert_train.txt ou bert_train2.txt dans le fichier zip.
L'entrée et la sortie sont dans la même ligne, chaque étiquette commence par « étiquette ».
Il existe un espace entre la chaîne d'entrée et la première étiquette, chaque étiquette est également divisée par un espace.
par exemple token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
Vérifiez les données / bert_train.txt ou bert_train2.txt dans le fichier zip.
Vérifiez le dossier «données» pour les exemples de données. Chargez en bas un ensemble de données de taille moyenne ici
Avec 450k 206 classes, chaque entrée est un document, la longueur moyenne est d'environ 300, un ou un associé multi-étiquettes à l'entrée.
Téléchargez l'intégration de Word pré-Train à partir de Tencent Ailab
Les choses peuvent être faciles:
Téléchargez l'ensemble de données (environ 200m, 450k de données, avec un fichier de cache), dézippez-les et mettez-les dans des données / dossier,
Exécutez l'étape 1 pour le pré-transfert,
et exécutez l'étape 2 pour le réglage fin.
Je termine au-dessus de trois étapes et je veux avoir une meilleure performance, comment puis-je faire plus loin. Dois-je trouver un grand ensemble de données?
Non
est un document ou une phrase, puis remplacez les données / bert_train2.txt par votre nouveau fichier de données.
Quoi de plus?
Essayez un grand hyper-paramètre ou un grand modèle (en remplaçant le réseau de squelette), vous pouvez observer toutes vos données de pré-train.
Jouez avec le modèle: modèle / bert_cnn_model.py, ou vérifiez le pré-processus avec data_util_hdf5.py.
Modèle de langage en purée prétraitée et tâche de prédiction de phrase suivante à grande échelle de corpus,
Basé sur un modèle d'auto-agence de couche multiple, puis régler un réglage fin en ajoutant une couche de classification.
Comme le modèle Bert est basé sur le transformateur, nous travaillons actuellement sur Ajouter une tâche de prétraitement au modèle.
AVIS: CAIL2018 est d'environ 450k comme lien ci-dessus.
La taille de la formation de l'ensemble de données privées est d'environ 100 000 km, le nombre de classes est de 9, pour chaque entrée, il existe une ou plusieurs étiquettes.
Le score F1 pour CAIL2018 est signalé sous forme de score Micro F1.
L'idée de base est très simple. Depuis plusieurs années, les gens obtiennent de très bons résultats "pré-formation" DNNS en tant que modèle de langue
puis affiner la tâche de PNL en aval (réponse aux questions, inférence du langage naturel, analyse des sentiments, etc.).
Les modèles de langue sont généralement de gauche à droite, par exemple:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
Le problème est que pour la tâche en aval, vous ne voulez généralement pas de modèle de langue, vous voulez une meilleure représentation contextuelle possible de
chaque mot. Si chaque mot ne peut voir que le contexte à sa gauche, il manque clairement beaucoup. Donc, une astuce que les gens ont faite est également de former un
Modèle de droite à gauche, par exemple:
P(store|</s>)*P(a|store </s>)*…
Maintenant, vous avez deux représentations de chaque mot, une gauche à droite et une droite à gauche, et vous pouvez les concaténer ensemble pour votre tâche en aval.
Mais intuitivement, ce serait beaucoup mieux si nous pouvions entraîner un seul modèle profondément bidirectionnel.
Il est malheureusement impossible de former un modèle bidirectionnel profond comme un LM normal, car cela créerait des cycles où les mots peuvent indirectement
"Se voir", et les prédictions deviennent triviales.
Ce que nous pouvons faire à la place, c'est l'astuce très simple qui est utilisée dans le décalage des autocodeurs, où nous masquons un pourcentage de mots de l'entrée et
doivent reconstruire ces mots du contexte. Nous appelons cela un "LM masqué" mais il est souvent appelé tâche de serrage.
Nous nourrissons l'entrée par un encodeur de transformateur profond, puis utilisons les états cachés finaux correspondant aux positions masquées pour
Prédisez quel mot était masqué, exactement comme nous pourrions former un modèle de langue.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Comment obtenir le dernier état caché de la (s) position (s) masquée (s)?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Pour plus de détails, vérifiez la méthode de mask_language_model à partir de pretrain_task.py et train_vert_lm.py
De nombreuses tâches de compréhension des langues, comme la réponse aux questions, l'inférence, doivent comprendre la relation
entre la phrase. Cependant, le modèle de langue ne peut comprendre que sans phrase. phrase suivante
La prédiction est un échantillon de tâche pour aider à mieux comprendre ce type de tâche.
50% du hasard, la deuxième phrase est la phrase suivante du premier, 50% de la suivante.
Compte tenu de deux phrases, le modèle est invité à prédire si la deuxième phrase est réelle de la prochaine phrase de
le premier.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
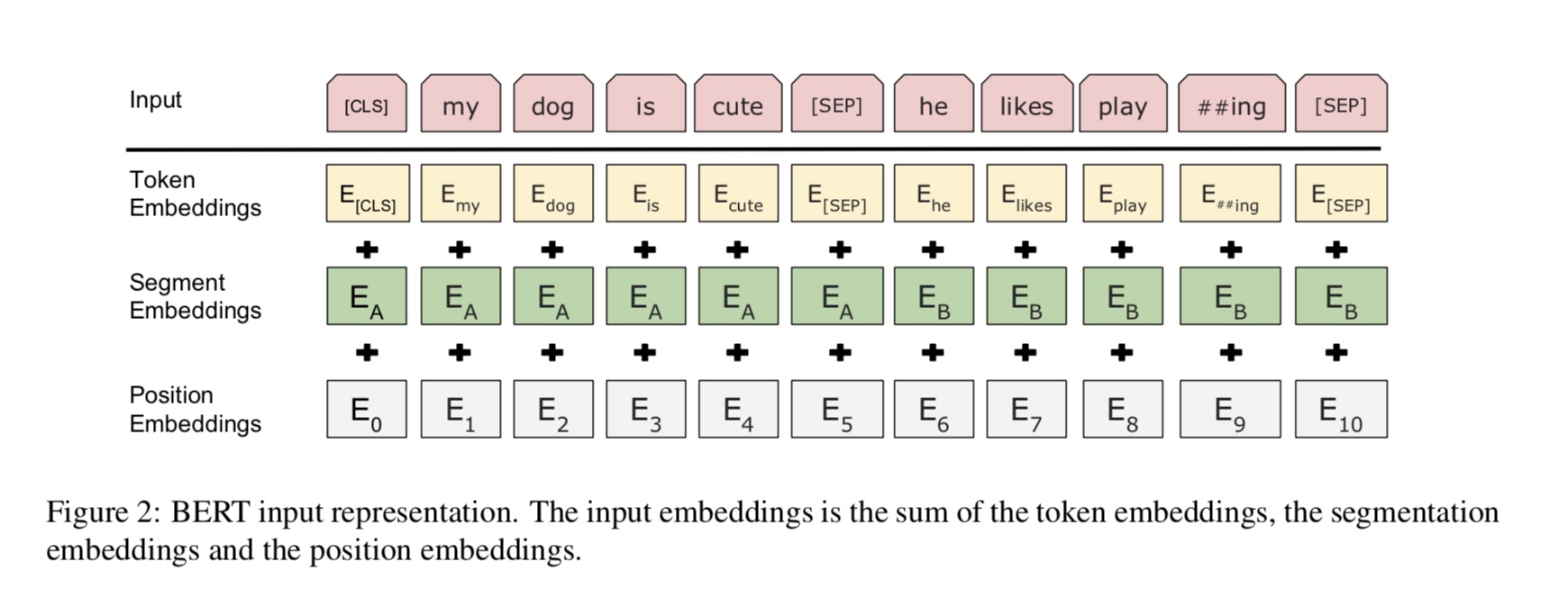
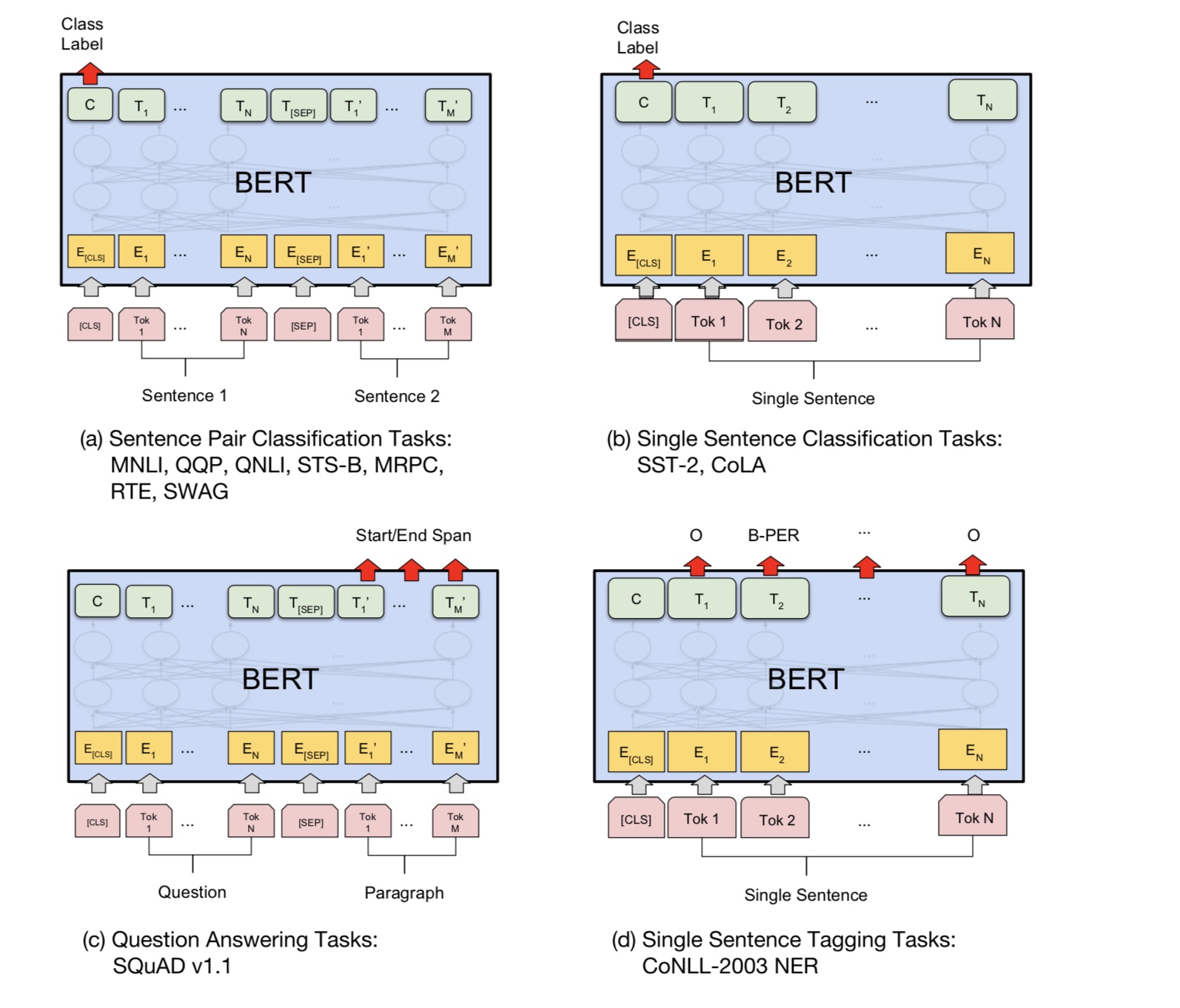
Python 3+ TensorFlow 1.10
Quel partage et ne partage pas entre les étapes pré-trains et les étapes de réglage fin?
1) .Bastiquement, tous les paramètres du réseau de squelette utilisés par les étapes pré-trains et à réglage fin sont partagés mutuellement.
2). Comme nous pouvons partager autant que possible les paramètres, de sorte que pendant la phase de réglage fin, nous devons apprendre en aussi peu
Paramètre possible, nous avons également partagé l'incorporation de mots pour ces deux étapes.
3). Par conséquent, la plupart des paramètres ont déjà été appris au début du stade de réglage fin.
Comment implémentons-nous le modèle de langue masquée?
Pour faire les choses facilement, nous générons des phrases à partir de documents, les divisions en phrases. pour chaque phrase
Nous tronçons et le remplissons sur la même longueur, et sélectionnons au hasard un mot, puis le remplaçons par [masque], son auto et un aléatoire
mot.
Comment rendre le stade de réglage fin plus efficace, tout en ne cassant pas le résultat et les connaissances que nous avons apprises de la scène pré-trains?
Nous utilisons un petit taux d'apprentissage pendant le réglage fin, de sorte que l'ajustement a été effectué dans une petite mesure.
Pourquoi avons-nous besoin d'auto-assistation?
auto-agencement Un nouveau type de réseau attire récemment de plus en plus d'attention. Traditionnellement, nous utilisons
RNN ou CNN pour résoudre le problème. Cependant, RNN a un problème en parallèle, et CNN n'est pas bon dans les tâches sensibles à la position du modèle.
L'auto-attention peut fonctionner en parallèle, tout en étant capable de modéliser la dépendance à longue distance.
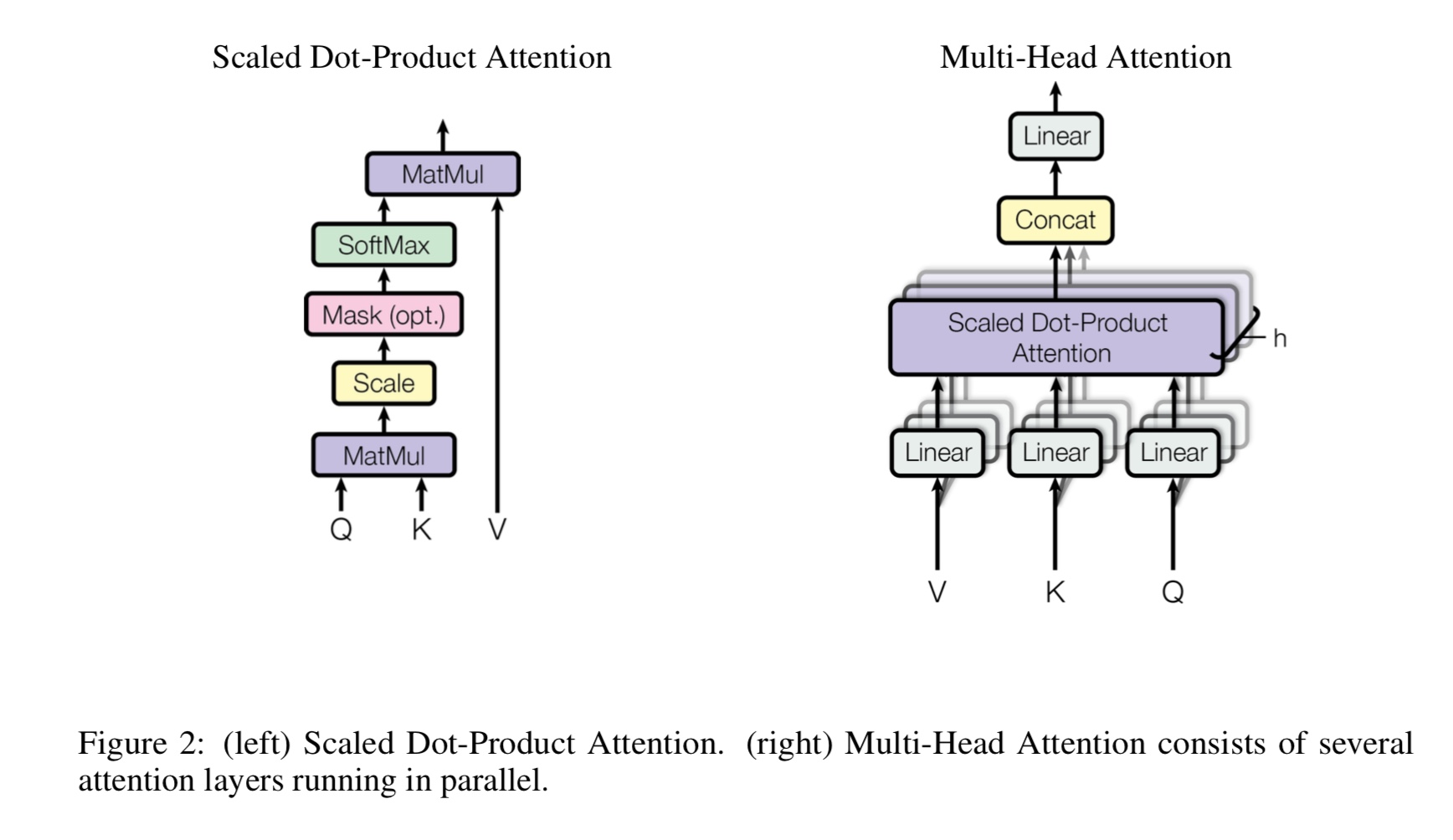
Qu'est-ce que l'auto-attention multi-têtes, que représente Q, K, V? Ajoutez quelque chose ici.
Mulit-Heads Auto-Assentiment est une auto-agence d'auto-atténuation, alors qu'elle divise et projette les Q et K en plusieurs sous-espaces différents,
Alors faites l'attention.
Q représentent la question, k représente les clés. Pour la tâche de traduction automatique, Q est un état caché précédent des décodes, k représente
états cachés de l'encodeur. Chacun des éléments de K calculera un score de similitude avec q. Et puis Softmax sera utilisé
Pour faire un score de normalisation, nous aurons des poids. Enfin, une somme pondérée est calculée en utilisant des poids s'appliquent à v.
Mais dans le scénario d'auto-agencement, Q, K, V sont tous les mêmes, que la représentation des séquences d'entrée d'une tâche.
Qu'est-ce que le rasage de position de position?
Il s'agit d'une couche en avant, également appelée couche entièrement connectée (FC). mais depuis dans le transformateur, toute l'entrée et la sortie de
Les couches sont une séquence de vecteurs: [Sequence_length, d_model]. Nous faisons généralement du FC à un vecteur d'entrée. Alors nous recommençons,
Mais un pas de temps différent a son propre FC.
Quelle est la principale contribution de Bert?
Alors que la tâche pré-tradition existe déjà pendant de nombreuses années, elle introduit une nouvelle façon (ce que l'on appelle le bidirection) pour faire un modèle de langue
et utilisez-le pour la tâche en baisse. Comme les données pour le modèle de langue sont partout. il s'est avéré puissant, et donc il remodeler
monde NLP.
Pourquoi l'auteur utilise trois types de jetons différents lors de la génération de données de formation du modèle de langue masquée?
Les auteurs croient qu'au stade de réglage fin, il n'y a pas de jeton [masque]. Il est donc décalé entre le prétraitement et le réglage fin.
Il oblige également le modèle à attirer toutes les informations de contexte d'une phrase.
Qu'est-ce qui a fait que le modèle Bert pour réaliser un nouveau statut d'art entraîne des tâches de compréhension du langage?
Big Model, Big Computation, et surtout - un nouveau algorithme pré-entraîne le modèle à l'aide de données en texte libre.
La tâche du jouet est utilisée pour vérifier si le modèle peut fonctionner correctement sans dépendre de données réelles.
Il demande au modèle de compter les nombres et de résumer toutes les entrées. et un seuil est utilisé,
Si la somme est supérieure (ou moins) à un seuil, le modèle doit le prédire comme 1 (ou 0).
À l'intérieur du modèle / transform_model.py, il existe une méthode de train et de prédire.
Vous pouvez d'abord exécuter Train () pour commencer la formation, puis exécuter Predict () pour démarrer la prédiction à l'aide du modèle formé.
Comme le modèle est assez grand, avec Hyperparamter par défaut (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6), il nécessite beaucoup de données avant de pouvoir converger.
Au moins 10 000 étapes sont nécessaires, avant que la perte ne devienne inférieure à 0,1. Si vous voulez l'entraîner rapidement avec petit
Données, vous pouvez utiliser un petit ensemble d'hyperparmeter (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Vous pouvez l'utiliser deux résolution de classification binaire, de classification multi-classes ou de problème de classification multi-étiquettes.
Il imprimera la perte pendant l'entraînement et imprimera le score F1 pour chaque époque pendant la validation.
Correction d'un bogue dans le transformateur [important, recrutez un membre de l'équipe et avez besoin d'une demande de fusion]
(Transformateur: Pourquoi la perte du stade pré-trains est la diminution du stade précoce, mais la perte n'est toujours pas si petite (par exemple, la perte = 8,0)?
Plus de données pré-trains, la perte n'est toujours pas petite)
Soutenir la tâche de la paire de phrases [important, recruter un membre de l'équipe et avoir besoin d'une demande de fusion]
Ajouter la tâche avant la transformation de la prédiction de phrase suivante [important, recruter un membre de l'équipe et avoir besoin d'une demande de fusion]
Besoin d'un ensemble de données pour l'analyse des sentiments ou la classification du texte en anglais [important, recrutez un membre de l'équipe et besoin d'une demande de fusion]
L'intégration de la position n'est pas encore partagée entre le prétraitement et le réglage fin. Puisque ici sur la longueur du stade pré-trains peut
Étape plus courte que dimensionnée.
Poigure spéciale First Token [CLS] comme entrée et classification [Terminé]
PRE-TRAIN AVEC FINE_TUNING: BESOIN DE VOCABULAIRE DE CHARGEMENT DE TOKENS DE L'ÉTATE DE LA PRE-TRAIN, mais étiquette de la tâche réelle. [FAIT]
Le taux d'apprentissage doit être plus petit lors du réglage fin. [Fait]
Le pré-train est tout ce dont vous avez besoin. Alors que l'utilisation du transformateur ou d'un autre modèle profond complexe peut vous aider à atteindre les performances supérieures
Dans certaines tâches, pré-entraînez-vous avec d'autres modèles comme TextCNN en utilisant une énorme quantité de données brutes puis affinez votre modèle sur l'ensemble de données spécifique à la tâche,
vous aidera toujours à obtenir des performances supplémentaires.
Ajoutez plus ici.
Ajoutez une suggestion, un problème ou vouloir apporter une contribution, bienvenue à contacter avec moi: [email protected]
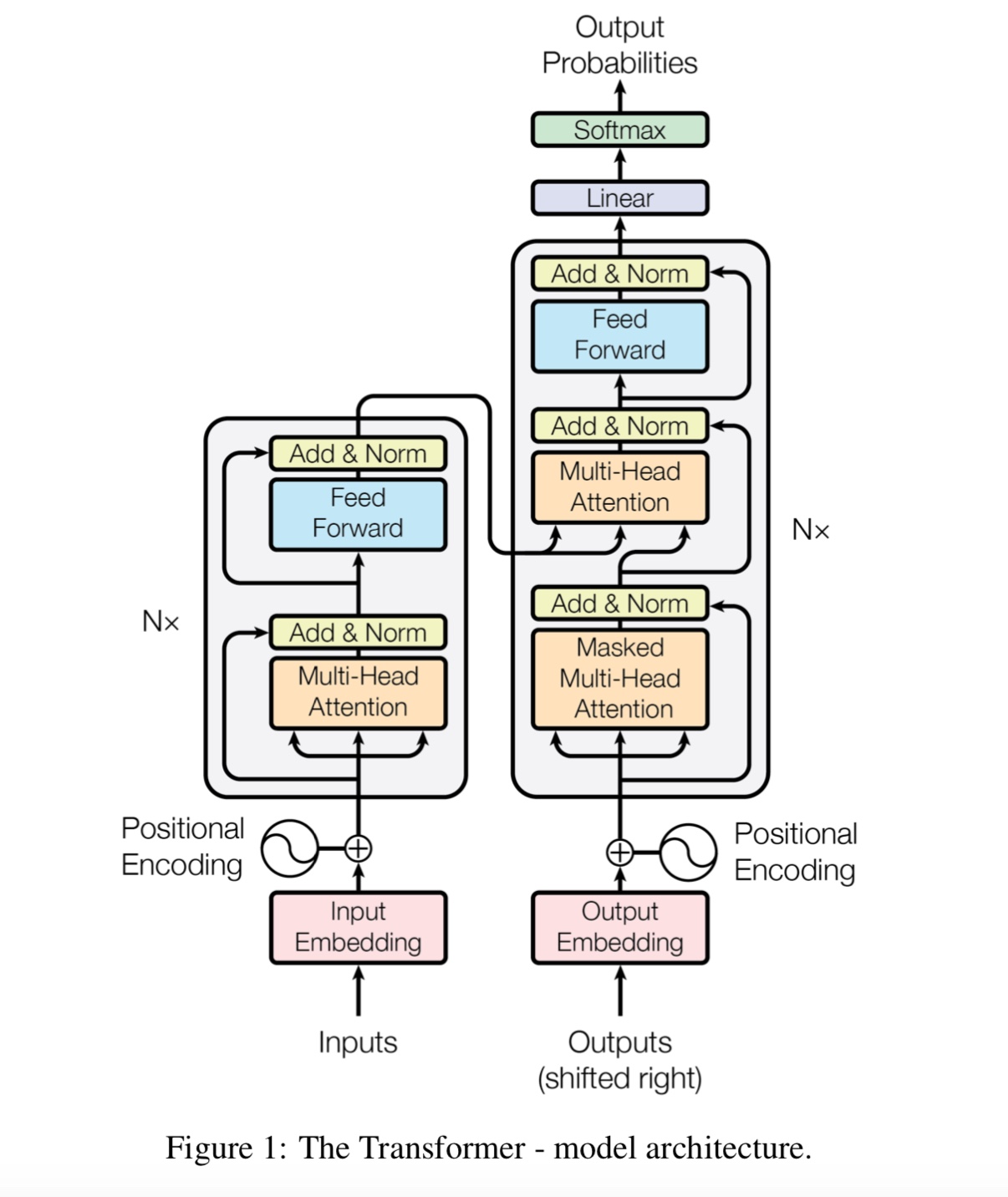
L'attention est tout ce dont vous avez besoin
Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage
Tensor2tenseur pour la traduction de la machine neuronale
Réseaux de neurones convolutionnels pour la classification des phrases
CAIL2018: un ensemble de données juridiques à grande échelle pour la prédiction du jugement


