bert_language_understanding
1.0.0
Берт в последнее время достигает нового современного результата по более чем 10 задачам NLP.
Это тензорфлоу реализация предварительного обучения глубоких двунаправленных трансформаторов для понимания языка
(Берт) и внимание - все, что вам нужно (трансформатор).
Обновление: большинство повторяющихся основных представлений об этих двух работах было сделано, существует очевидная выгода
Для предварительного обучения модель и точная настройка сравните для обучения модели с нуля.
Мы провели эксперимент, чтобы заменить сеть магистралей BERT от Transformer в TextCnn, и результат в том, что
Предварительное обучение модели с маскарной моделью языка с использованием множества необработанных данных могут повысить производительность в заметной сумме.
В более общем плане мы считаем, что стратегия предварительной поездки и тонкой настройки является независимой для модели и предварительной задачи.
С учетом вышесказанного вы можете заменить сеть магистралей, как вам нравится. и добавить больше задач перед поездкой или определить некоторые новые задачи перед поездками как
Вы можете, предварительный тренировки не ограничивается моделью в масках и или предсказание следующего предложения задачи. Что нас удивляет, что,
С набором данных среднего размера, в котором говорится, что один миллион, даже без использования внешних данных, с помощью задачи перед поездками
Как и модель в масках, производительность может быть повышена на большом крае, и модель может сходиться еще быстро. когда -нибудь
Обучение может быть только в нескольких эпохе на стадии точной настройки.
В то время как есть открытый исходный код (tensor2tensor) и официальный
Внедрение официальной реализации Transformer и BERT появится в ближайшее время, но есть/может прочитать/может прочитать, нелегко понять.
Мы не намерены полностью повторять оригинальные статьи, но применять основные идеи и решить проблему НЛП в лучшем виде.
Большая часть работы здесь была сделана еще одним хранилищем в прошлом году: классификация текста
Набор данных среднего размера (CAIL2018, 450K)
| Модель | TextCnn (без предварительного пути) | TextCnn (предварительный фининг) | Получение от предварительного обучения |
|---|---|---|---|
| Оценка F1 после 1 эпохи | 0,09 | 0,58 | 0,49 |
| Оценка F1 после 5 эпохи | 0,40 | 0,74 | 0,35 |
| Оценка F1 после 7 эпохи | 0,44 | 0,75 | 0,31 |
| Оценка F1 после 35 эпохи | 0,58 | 0,75 | 0,27 |
| Потеря обучения в начале | 284.0 | 84.3 | 199,7 |
| Потеря проверки после 1 эпохи | 13.3 | 1.9 | 11.4 |
| Потеря проверки после 5 эпохи | 6.7 | 1.3 | 5.4 |
| Время обучения (одиночный графический процессор) | 8 часов | 2H | 6H |
Уведомление:
А. Настройка настройки завершила обучение после того, как только пропустила 7 эпох, когда максимальная эпоха достигла 35.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
Оценка C.F1, о которой здесь сообщается, находится на наборе валидации, в среднем микро и макросмерка оценки F1.
Оценка D.F1 после 35 EPOCH сообщается в тестовом наборе.
эн. Из 450K RAW Documents, извлеченные 2 миллиона данных обучения для модели в масках,
pre-train stage finished within 5 hours in single GPU.
Прекрасная настройка после предварительного обучения:
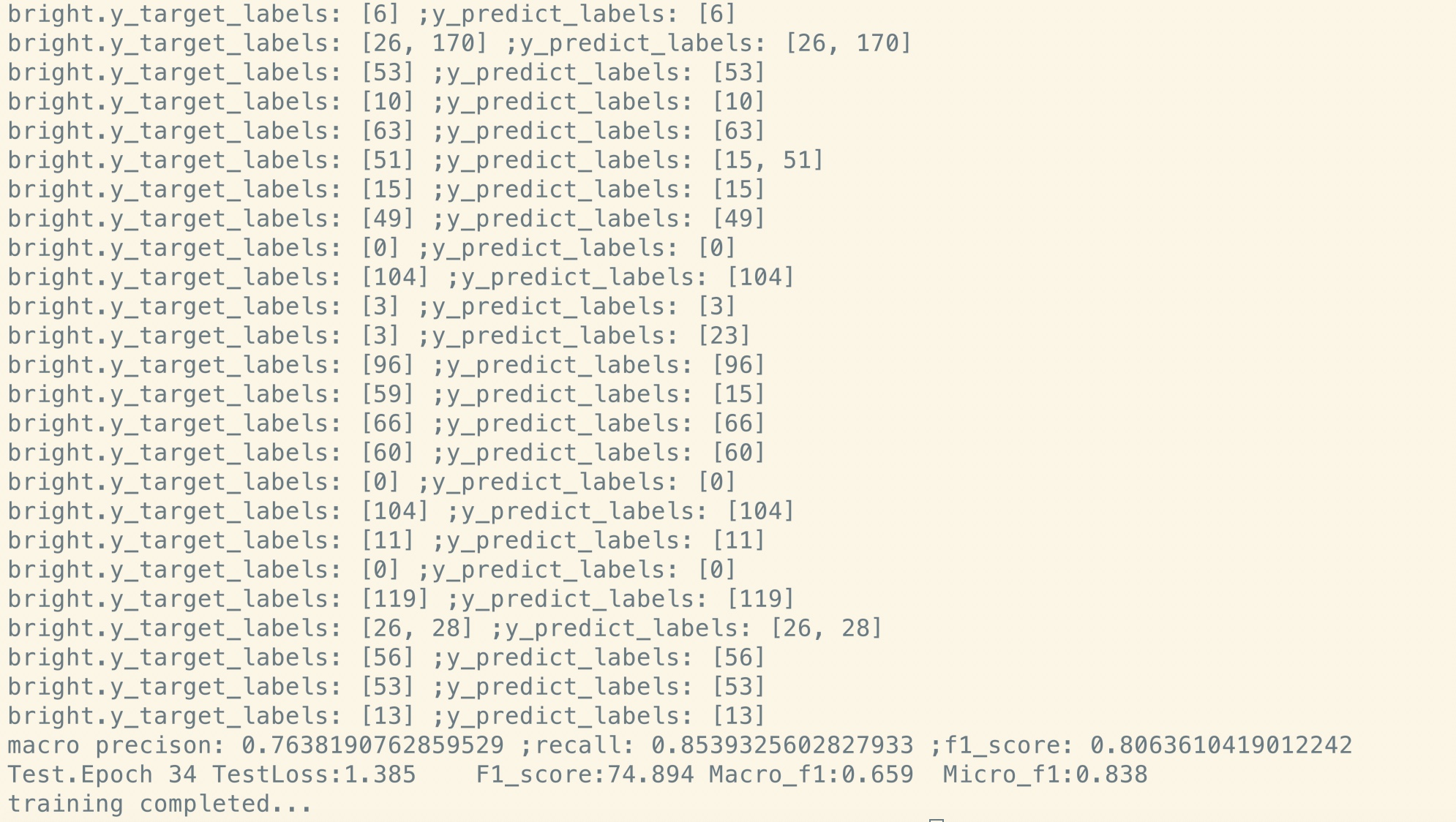
Нет перед-тренировок:
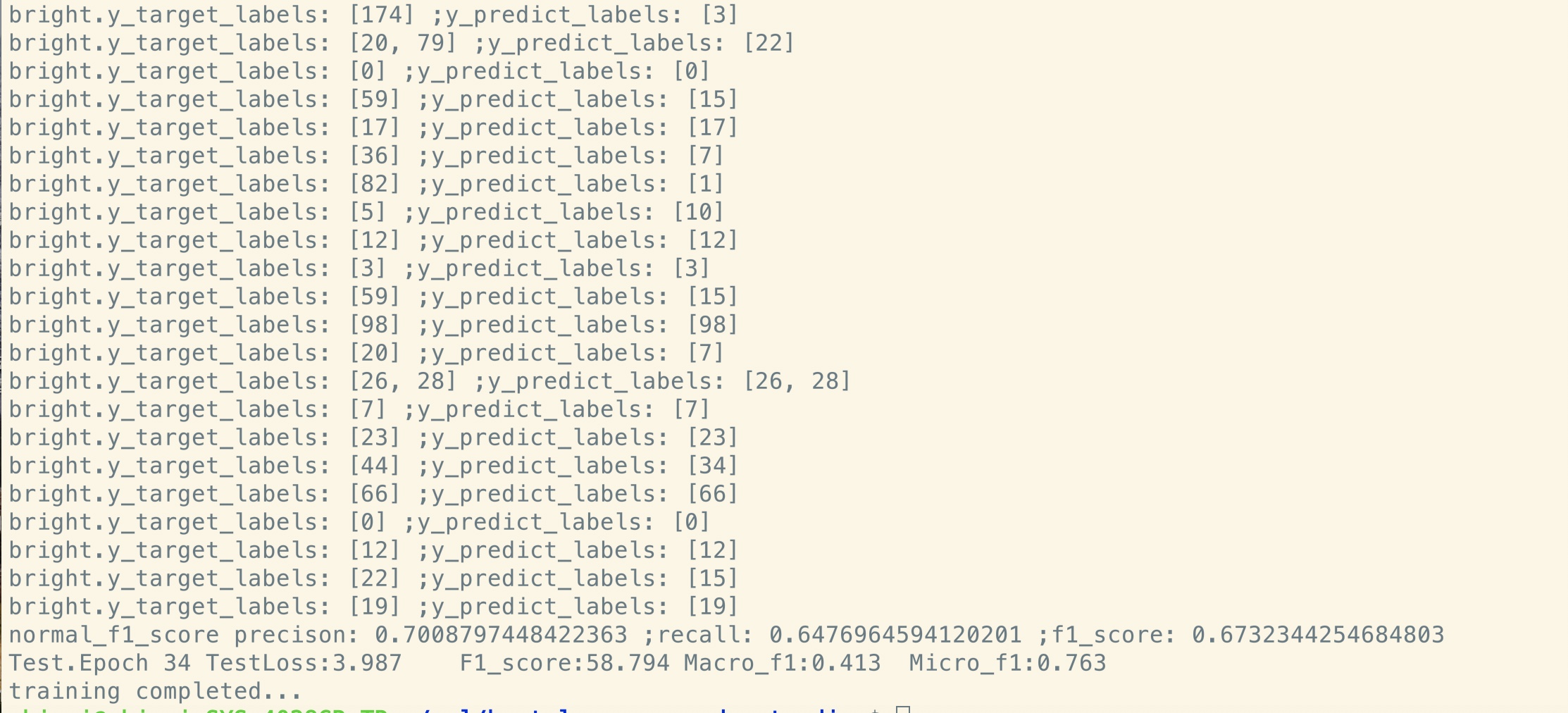
Набор данных небольшого размера (частная, 100 тыс.)
| Модель | TextCnn (без предварительного пути) | TextCnn (предварительный фининг) | Получение от предварительного обучения |
|---|---|---|---|
| Оценка F1 после 1 эпохи | 0,44 | 0,57 | 10%+ |
| Потеря проверки после 1 эпохи | 55,1 | 1.0 | 54.1 |
| Потеря обучения в начале | 68.5 | 8.2 | 60.3 |
Если вы хотите попробовать Bert с предварительным обучением модели маскированного языка и тонкой настройкой. Сделайте два шага:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Как видите, даже в начальной точке точной настройки, сразу после параметров восстановления из предварительно обученной модели, потеря модели меньше
чем обучение от совершенно нового, а оценка F1 также выше, в то время как новая модель может начинаться с 0.
Примечание: Чтобы помочь вам попробовать новую идею, вы можете установить Hyper-Paramater test_mode на true. Он будет загружать только несколько данных и начнет быстро тренироваться.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_Model: измерение модели. [512]
num_layer: количество слоев. [6]
num_header: количество заголовков самоуправления [8]
D_K: измерение ключа (k). Размер запроса (Q) одинаково. [64]
D_V: измерение V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Каждая строка - это документ (несколько предложений) или предложение. Это свободный текст, который вы можете легко получить.
Проверьте данные/bert_train.txt или bert_train2.txt в zip -файле.
Ввод и вывод находится в одной линии, каждая метка начинается с « метки ».
Существует пространство между входной строкой и первой меткой, каждая метка также разделена пространством.
например, token1 token2
token1 token2 token3 __label__l2 __label__l4
Проверьте данные/bert_train.txt или bert_train2.txt в zip -файле.
Проверьте папку «Данные» для образца данных. Загрузите набор данных среднего размера здесь
С классами 450K 206 каждый вход представляет собой документ, средняя длина составляет около 300, один или мульти-маршрутный ассортимент с вводом.
Загрузите предварительное встроение слов с Tencent ailab
Вещи могут быть легко:
Набор данных загрузки (около 200 м, 450K, с некоторым файлом кэша), разкачивайте его и поместите в данные/ папку,
Запустите шаг 1 для предварительного обучения,
и запустите шаг 2 для точной настройки.
Я заканчиваю выше трех шагов и хочу получить лучшую производительность, как я могу сделать дальше. Мне нужно найти большой набор данных?
Нет. Вы можете создать большой набор данных для предварительного обучения, загрузив немного бесплатного текста, убедитесь, что каждая строка
это документ или предложение, затем замените Data/Bert_train2.txt вашим новым файлом данных.
Что еще?
Попробуйте большую гиперпараметрическую или большую модель (заменив сеть магистралей). Вы можете наблюдать все данные перед поездками.
Играйте с моделью: модель/bert_cnn_model.py или проверьте предварительный процесс с помощью data_util_hdf5.py.
Модель пюре с предварительным пюре и задача прогнозирования предложений в больших масштабах корпуса,
На основании нескольких слоев модели самодовольства, затем тонкая настройка путем добавления классификационного слоя.
Поскольку модель BERT основана на трансформаторе, в настоящее время мы работаем над добавлением задачи предварительной обработки в модель.
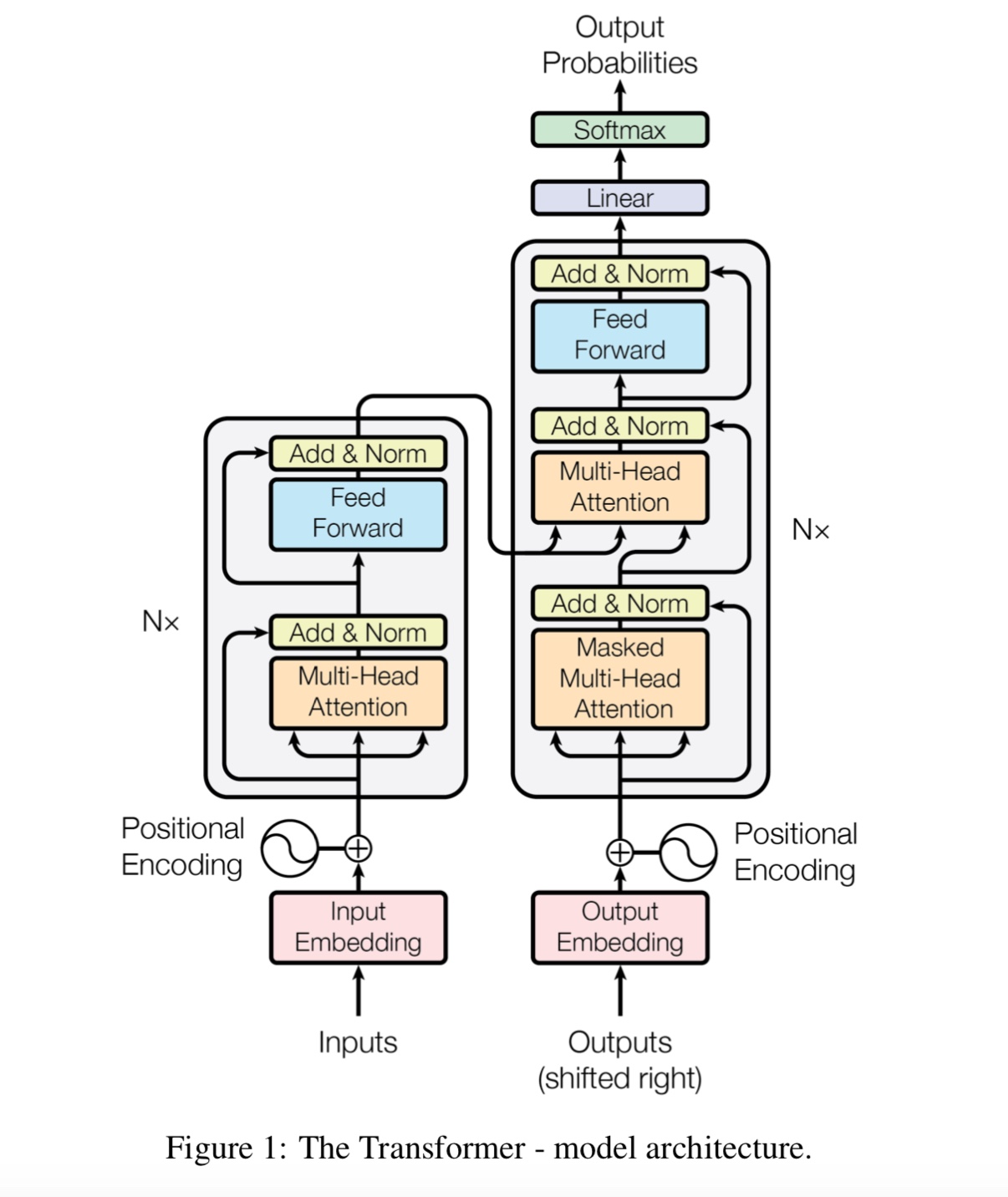
Примечание: Cail2018 составляет около 450 тысяч, как ссылка выше.
Размер обучения частного набора данных составляет около 100 тыс., Количество классов составляет 9, для каждого ввода существует одна или несколько метков.
Оценка F1 для CAIL2018 сообщается как показатель Micro F1.
Основная идея очень проста. В течение нескольких лет люди получали очень хорошие результаты, «предварительные тренировки» DNN в качестве языковой модели
а затем тонкая настройка на какую-то нижестоящая задача NLP (ответный вопрос, вывод естественного языка, анализ настроений и т. Д.).
Языковые модели, как правило, направляются, например:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
Проблема в том, что для нижней задачи вам обычно не нужна языковая модель, вам нужно наилучшее контекстное представление
каждое слово. Если каждое слово может увидеть только контекст слева, явно много отсутствует. Итак, один трюк, который люди сделали, - это также тренировать
Модель справа налево, например:
P(store|</s>)*P(a|store </s>)*…
Теперь у вас есть два представления каждого слова, одно слева направо и одно право на пол, и вы можете объединить их вместе для выполнения задачи.
Но интуитивно было бы намного лучше, если бы мы могли тренировать одну модель, которая была глубоко двунаправленной.
К сожалению, невозможно обучить глубокую двунаправленную модель, как обычную LM, потому что это создаст циклы, где слова могут косвенно
«Видите себя», и прогнозы становятся тривиальными.
Вместо этого мы можем сделать очень простой улов
нужно реконструировать эти слова из контекста. Мы называем это «маскированным LM», но его часто называют задачей.
Мы кормим вход через глубокий трансформированный кодер, а затем используем конечные скрытые состояния, соответствующие маскированным положениям
Предсказайте, что было замаскировано, точно так же, как мы будем обучать языковую модель.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Как получить последнее скрытое состояние маскированного позиции (ы)?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Для получения более подробной информации, проверьте метод mask_language_model от pretrain_task.py и train_vert_lm.py
Много языкового понимания задачи, например, ответ на вопрос, вывод, нужно понимать отношения
между предложением. Тем не менее, языковая модель может понимать только без предложения. Следующее предложение
Прогнозирование - это пример задачи, чтобы помочь модели лучше понять в этих видах задачи.
50% случайности второе предложение - следующее предложение первого, 50% от не следующего.
Учитывая два предложения, модель просят предсказать, является ли второе предложение реальным следующим предложением
первый.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
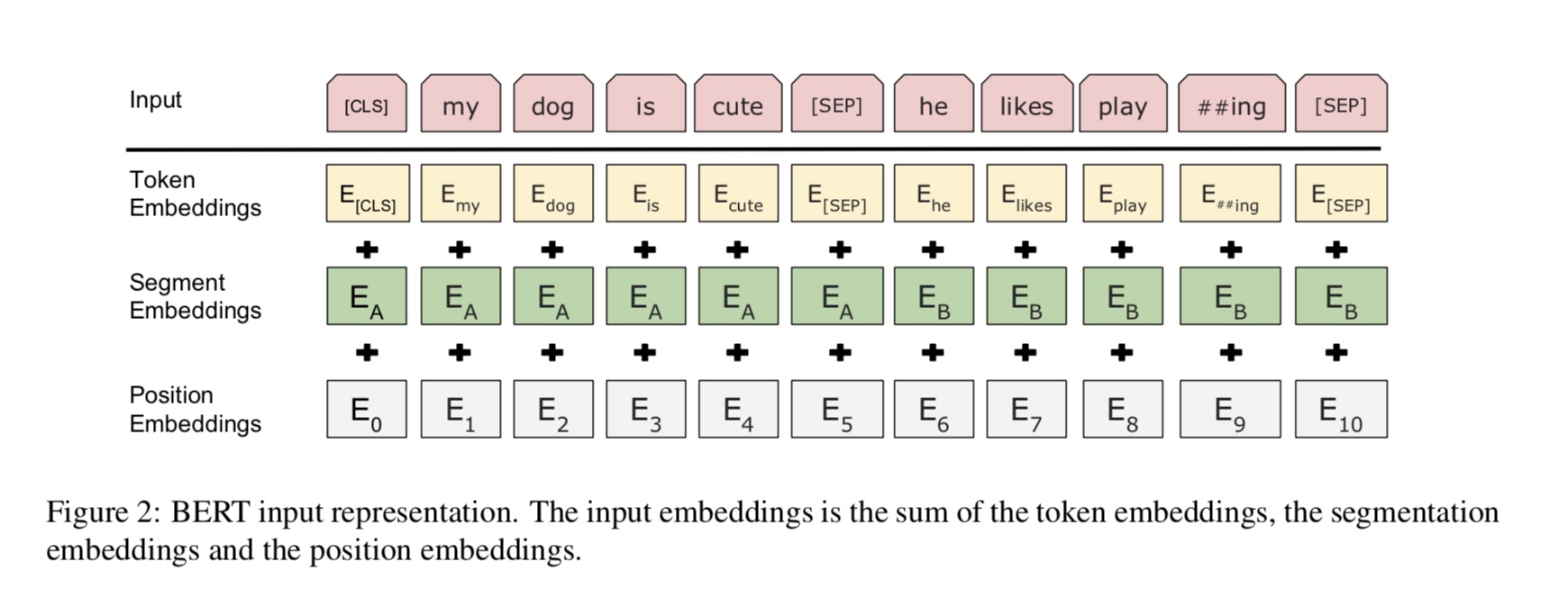
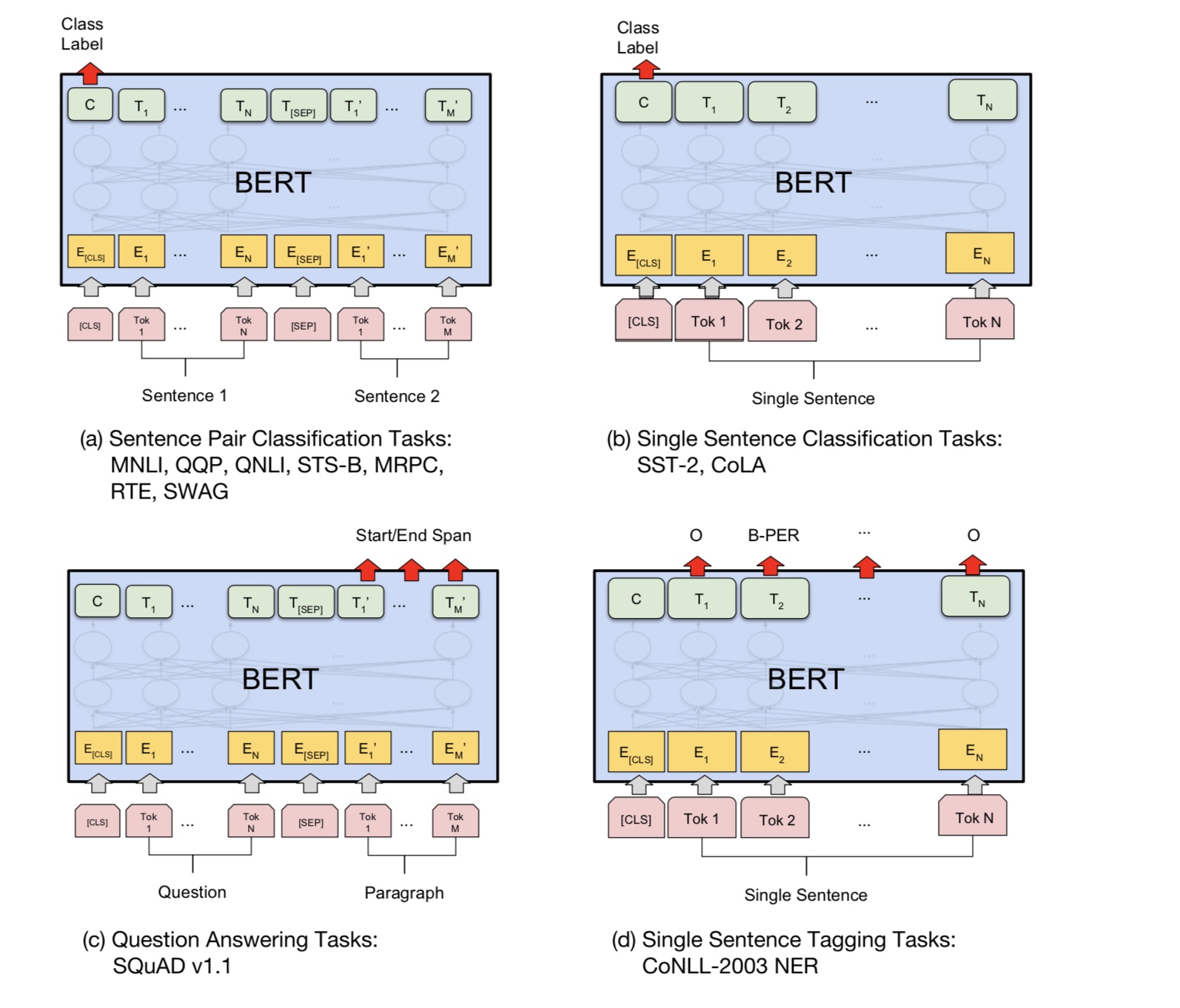
Python 3+ Tensorflow 1.10
Какая доля, а не доля между этапами до тренировки и тонкой настройки?
1).
2). Как мы можем поделиться параметрами как можно больше, так что на стадии точной настройки нам нужно учиться, как мало
Параметр, как можно более, мы также поделились встроением слов для этих двух этапов.
3) Таким образом, большинство параметров уже были изучены в начале стадии точной настройки.
Как мы реализуем модель маскированного языка?
Чтобы сделать вещи легко, мы генерируем предложения из документов, разделили их на предложения. за каждое предложение
Мы усекаем и заполняем его до той же длины и случайным образом выбираем слово, затем заменяем его [маской], его самостоятельно и случайным образом
слово.
Как сделать стадию тонкой настройки более эффективной, в то время как не нарушает результаты и знания, которые мы узнали на стадии перед поездкой?
Мы используем небольшую скорость обучения во время точной настройки, так что корректировка была сделана в крошечной степени.
Зачем нам нужно самоубиться?
Самоавторан, новый тип сети в последнее время привлекает все больше и больше внимания. Традиционно мы используем
RNN или CNN для решения проблемы. Однако у RNN есть проблема параллельно, и CNN не очень хорош в задачах чувствительных к положению модели.
Самоализация может работать параллельно, в то же время способная моделировать зависимость на длинных расстояниях.
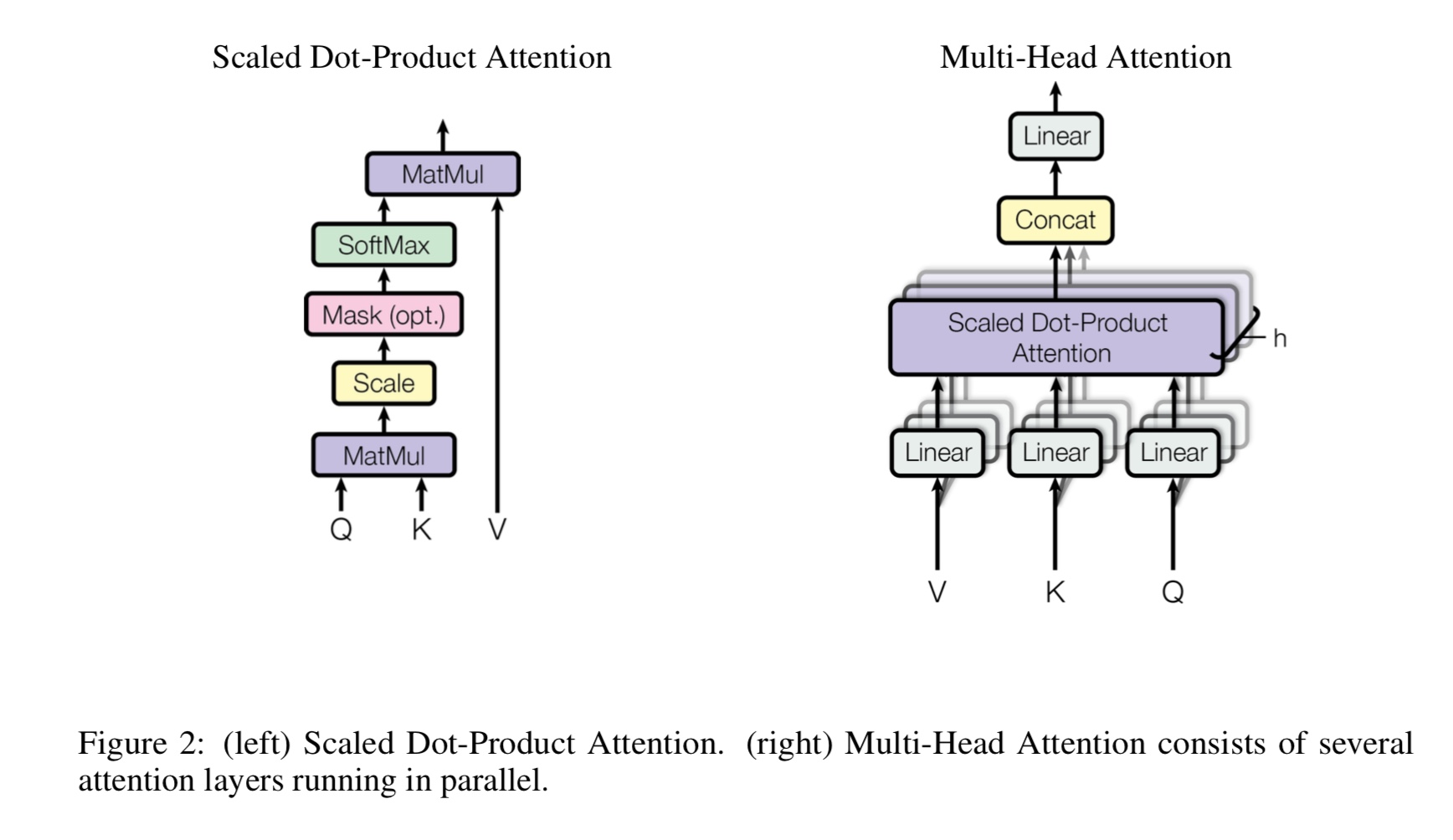
Что такое мульти-головы самостоятельно, что означает Q, K, V? Добавьте что -нибудь здесь.
Mulit-головы самостоятельно приспосабливаются к самостоятельному примеру, в то время как он разделяет и проект Q и K на несколько различных подпространств,
Тогда сделайте внимание.
Q Стенда для вопроса, k стоять для ключей. Для задачи по переводу машин Q предыдущее скрытое состояние декодов, k представляет собой
скрытые состояния энкодера. Каждый элемент K будет вычислять оценку сходства с Q. и тогда будет использоваться Softmax
Чтобы нормализовать счет, мы получим вес. Наконец, взвешенная сумма вычисляется с использованием веса, применяемых к V.
Но в сценарии самопристывания Q, K, V все такие же, как представление входных последовательностей задачи.
Что такое положения Fearfoward?
Это слой подачи вперед, также называемый полностью подключенным (FC) слоем. Но с тех пор, как в трансформаторе все входные и выходные данные
Слои представляют собой последовательность векторов: [sequence_length, d_model]. Обычно мы делаем FC на вектор ввода. Итак, мы делаем это снова,
Но у разных временных шагов есть собственный FC.
Какой основной вклад Берта?
В то время как задача перед поездками существует уже много лет, она вводит новый способ (так называемый двунаправленным) для выполнения языковой модели
и используйте его для задачи Down Stream. в качестве данных для языковой модели везде. это оказалось мощным, и, следовательно, он изменил
Мир НЛП.
Почему автор использует три различных типа токенов при создании учебных данных модели маскированного языка?
Авторы считают, что на стадии точной настройки нет токена [маски]. Таким образом, это несоответствие между до тренировки и тонкой настройки.
Это также заставляет модель привлечь внимание всей контекстной информации в предложении.
Что заставило Bert Model для достижения нового состояния искусства к задачам понимания языка?
Большая модель, большие вычисления и, самое главное,-новый алгоритм предварительно обучать модель с использованием данных свободного текста.
Игрушечная задача используется, чтобы проверить, может ли модель работать должным образом без зависимости от реальных данных.
Он просит модель подсчитать числа и суммировать все входные данные. и используется порог,
Если суммирование больше (или меньше), чем порог, то модель должна предсказать его как 1 (или 0).
Внутренняя модель/Transform_model.py есть поезд и метод прогнозирования.
Сначала вы можете запустить Train (), чтобы начать обучение, а затем запустить Predict (), чтобы начать прогноз с использованием обученной модели.
Поскольку модель довольно большая, с гиперпарамтером по умолчанию (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6), она требует большого количества данных, прежде чем он сможет сходиться.
По крайней мере, 10 тысяч шагов - до того, как потеря станет менее 0,1. Если вы хотите тренировать его быстро с небольшим
Данные, вы можете использовать небольшой набор гиперграметра (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Вы можете использовать его два решения бинарной классификации, многоклассовой классификации или задачи классификации с несколькими маркировкой.
Он печатает потерю во время обучения и печатает оценку F1 для каждой эпохи во время проверки.
Исправьте ошибку в Transformer [Важно, наберите члена команды и нуждайтесь в запросе слияния]
(Трансформатор: Почему потеря стадии предварительного обучения снижается на ранней стадии, но потеря все еще не такая мала (например, потеря = 8,0)? Даже с
Больше данных перед поездками, потеря все еще не мала)
Задача поддержки пары предложений [Важно, наберите члена команды и нуждается в запросе слияния]
Добавьте предварительную задачу прогнозирования следующего предложения [Важно, найдите члена команды и нуждаетесь в запросе слияния]
Нужна набор данных для анализа настроений или классификации текста на английском языке [Важно, наберите члена команды и нуждаетесь в запросе слияния]
Позиция внедрения еще не разделяется между предварительным турином и точной настройкой. Поскольку здесь на длина стадии предварительного обучения может
короче, чем сцена с тонкой настройкой.
Специальная ручка первого токена [CLS] в качестве ввода и классификации [выполнено]
Предварительный поезд с Fine_tuning: нужен словарный запас токенов с стадии перед поездками, но этикетки из реальной задачи. [СДЕЛАННЫЙ]
Скорость обучения должно быть меньше при тонкой настройке. [Сделанный]
Предварительный поезд-это все, что вам нужно. При использовании трансформатора или какой -либо другой сложной глубокой модели может помочь вам достичь высшей производительности
В некоторых задачах предварительна с другой моделью, такой как TextCnn, используя огромное количество необработанных данных, а затем настраивать вашу модель по набору данных конкретного задачи,
всегда поможет вам получить дополнительную производительность.
Добавьте больше здесь.
Добавьте предложение, проблему или хотите внести вклад, добро пожаловать, чтобы связаться со мной: [email protected]
Внимание - это все, что вам нужно
Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка
Tensor2tensor для перевода нейронной машины
Сверточные нейронные сети для классификации приговора
CAIL2018: крупномасштабный юридический набор данных для прогнозирования суждений


