bert_language_understanding
1.0.0
เบิร์ตบรรลุผลงานศิลปะใหม่ ๆ ในงาน NLP มากกว่า 10 งานเมื่อเร็ว ๆ นี้
นี่คือการใช้ tensorflow ก่อนการฝึกอบรมหม้อแปลงแบบสองทิศทางลึกสำหรับการทำความเข้าใจภาษา
(เบิร์ต) และความสนใจคือสิ่งที่คุณต้องการ (หม้อแปลง)
UPDATE: ส่วนใหญ่ของการทำซ้ำแนวคิดหลักของเอกสารทั้งสองนี้ได้ทำไปแล้วมีประสิทธิภาพที่ชัดเจน
สำหรับการฝึกอบรมล่วงหน้ารุ่นและการปรับแต่งเปรียบเทียบเพื่อฝึกอบรมรุ่นตั้งแต่เริ่มต้น
เราได้ทำการทดลองเพื่อแทนที่เครือข่าย Backbone ของ Bert จาก Transformer เป็น textCNN และผลลัพธ์คือ
ฝึกอบรมรุ่นก่อนด้วยโมเดลภาษาที่สวมหน้ากากโดยใช้ข้อมูลดิบจำนวนมากสามารถเพิ่มประสิทธิภาพในจำนวนที่น่าสังเกต
โดยทั่วไปเราเชื่อว่ากลยุทธ์ก่อนการฝึกอบรมและการปรับแต่งเป็นแบบจำลองที่เป็นอิสระและเป็นอิสระจากงานก่อนการฝึกอบรม
เมื่อถูกกล่าวว่าคุณสามารถแทนที่เครือข่าย Backbone ตามที่คุณต้องการ และเพิ่มงานก่อนรถไฟมากขึ้นหรือกำหนดงานก่อนรถไฟใหม่เป็น
คุณสามารถฝึกอบรมล่วงหน้าจะไม่ จำกัด เฉพาะรูปแบบภาษาที่สวมหน้ากากและหรือทำนายงานประโยคถัดไป สิ่งที่ทำให้เราประหลาดใจคือ
ด้วยชุดข้อมูลขนาดกลางที่บอกว่าหนึ่งล้านแม้จะไม่ใช้ข้อมูลภายนอกด้วยความช่วยเหลือของงานก่อนรถไฟ
เช่นเดียวกับรูปแบบภาษาที่สวมหน้ากากประสิทธิภาพสามารถเพิ่มขึ้นได้ในระยะขอบที่ยิ่งใหญ่และโมเดลสามารถมาบรรจบกันได้อย่างรวดเร็ว บางครั้ง
การฝึกอบรมสามารถอยู่ในช่วงเวลาเพียงไม่กี่ช่วงในช่วงการปรับจูน
ในขณะที่มีโอเพ่นซอร์ส (Tensor2tensor) และเป็นทางการ
การใช้งานของ Transformer และ Bert อย่างเป็นทางการในเร็ว ๆ นี้ แต่มี/อาจอ่านยากไม่ใช่เรื่องง่ายที่จะเข้าใจ
เราไม่ได้ตั้งใจที่จะทำซ้ำเอกสารต้นฉบับทั้งหมด แต่เพื่อใช้แนวคิดหลักและแก้ปัญหา NLP ในวิธีที่ดีกว่า
ส่วนใหญ่สำหรับการทำงานที่นี่ทำโดยที่เก็บอื่นเมื่อปีที่แล้ว: การจำแนกประเภทข้อความ
ชุดข้อมูลขนาดกลาง (Cail2018, 450K)
| แบบอย่าง | textcnn (ไม่มีการพรีทราน) | textcnn (pretrain-finetuning) | ได้รับจาก Pre-Train |
|---|---|---|---|
| คะแนน F1 หลังจาก 1 ยุค | 0.09 | 0.58 | 0.49 |
| คะแนน F1 หลังจาก 5 ยุค | 0.40 | 0.74 | 0.35 |
| คะแนน F1 หลังจาก 7 ยุค | 0.44 | 0.75 | 0.31 |
| คะแนน F1 หลังจาก 35 ยุค | 0.58 | 0.75 | 0.27 |
| การสูญเสียการฝึกอบรมตั้งแต่ต้น | 284.0 | 84.3 | 199.7 |
| การสูญเสียการตรวจสอบหลังจาก 1 ยุค | 13.3 | 1.9 | 11.4 |
| การสูญเสียการตรวจสอบหลังจาก 5 ยุค | 6.7 | 1.3 | 5.4 |
| เวลาฝึกอบรม (GPU เดี่ยว) | 8h | 2H | 6h |
สังเกต:
A. ขั้นตอนการปรับแต่งเสร็จสิ้นการฝึกอบรมเสร็จสิ้นหลังจากผ่าน 7 Epoch เมื่อ Epoch สูงสุดถึง 35
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
คะแนน C.F1 รายงานที่นี่อยู่ในชุดการตรวจสอบความถูกต้องโดยเฉลี่ยของคะแนนไมโครและแมโครของคะแนน F1
คะแนน D.F1 หลังจากรายงาน 35 EPOCH ในชุดทดสอบ
ก. จากเอกสารดิบ 450K ดึงข้อมูลการฝึกอบรม 2 ล้านรายการสำหรับรูปแบบภาษาที่สวมหน้ากาก
pre-train stage finished within 5 hours in single GPU.
ปรับจูนหลังรถไฟก่อน:
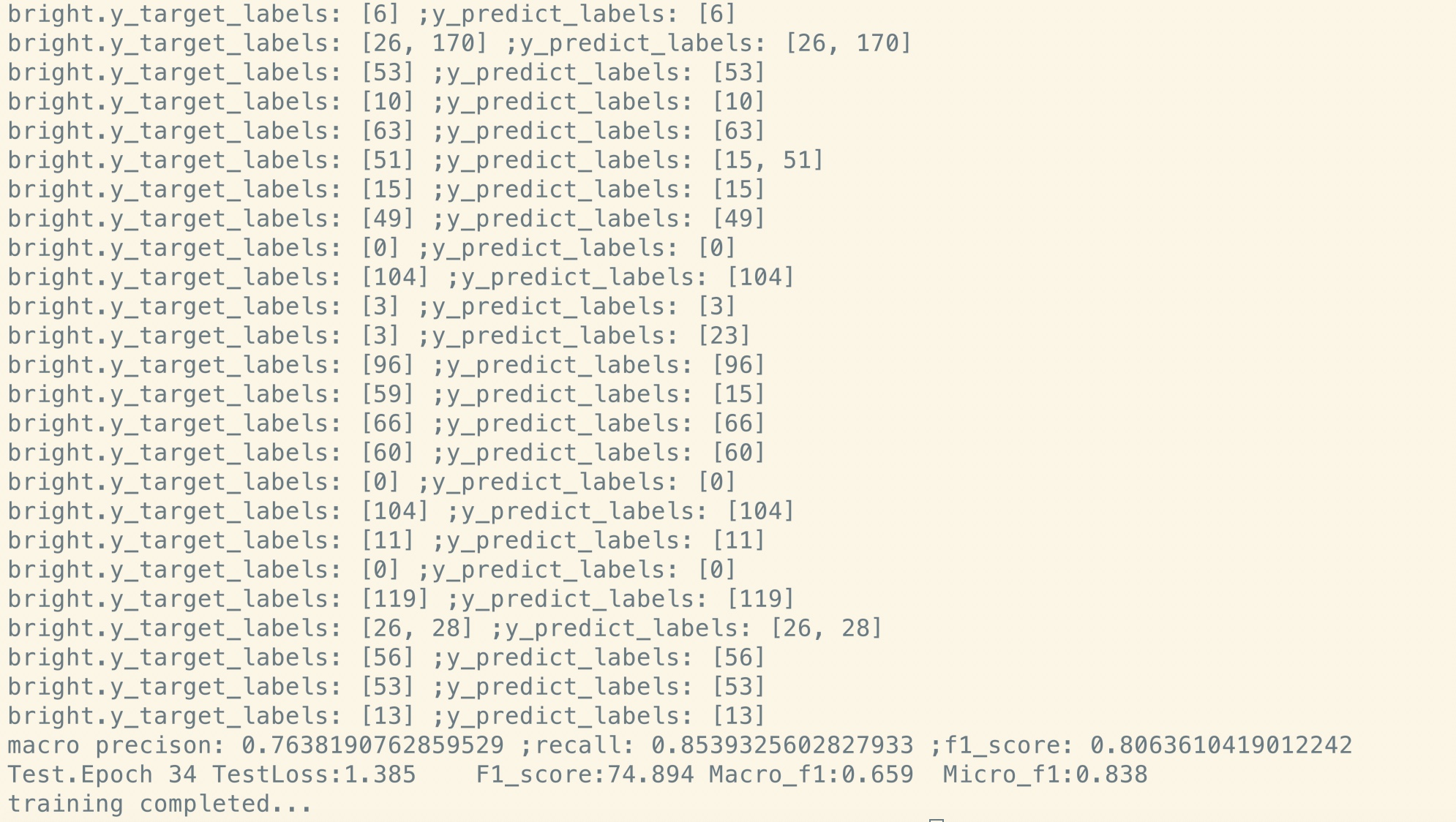
ไม่มีการฝึกอบรมก่อน:
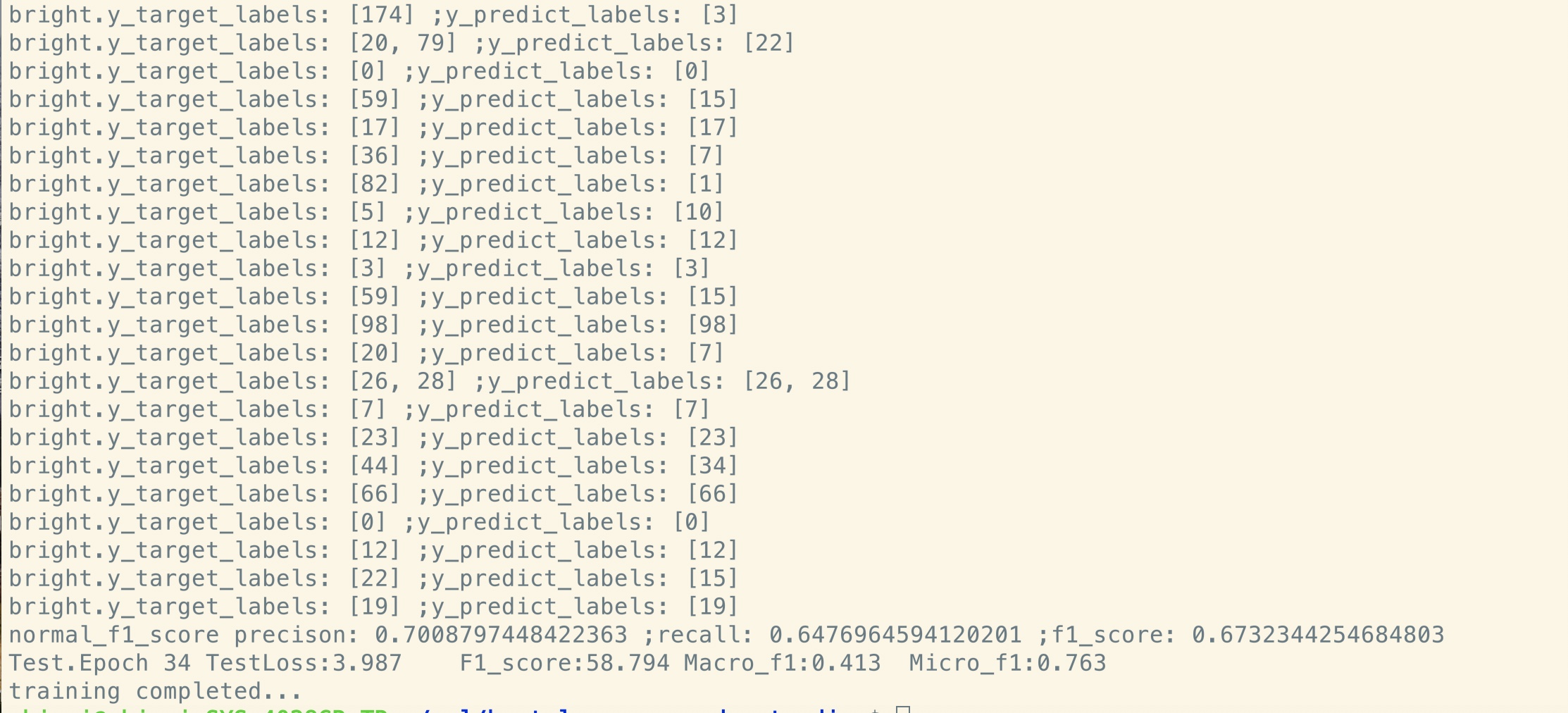
ชุดข้อมูลขนาดเล็ก (ส่วนตัว, 100k)
| แบบอย่าง | textcnn (ไม่มีการพรีทราน) | textcnn (pretrain-finetuning) | ได้รับจาก Pre-Train |
|---|---|---|---|
| คะแนน F1 หลังจาก 1 ยุค | 0.44 | 0.57 | 10%+ |
| การสูญเสียการตรวจสอบหลังจาก 1 ยุค | 55.1 | 1.0 | 54.1 |
| การสูญเสียการฝึกอบรมตั้งแต่ต้น | 68.5 | 8.2 | 60.3 |
หากคุณต้องการลองใช้เบิร์ตด้วยการฝึกฝนภาษาที่สวมหน้ากากและการปรับแต่ง ทำสองขั้นตอน:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
อย่างที่คุณเห็นแม้ในจุดเริ่มต้นของการปรับแต่งเพียงหลังจากพารามิเตอร์คืนค่าจากแบบจำลองที่ผ่านการฝึกอบรมมาก่อนการสูญเสียของแบบจำลองก็เล็กลง
กว่าการฝึกอบรมจากใหม่อย่างสมบูรณ์และคะแนน F1 ก็สูงกว่าในขณะที่รุ่นใหม่อาจเริ่มต้นจาก 0
ข้อสังเกต: เพื่อช่วยให้คุณลองใช้แนวคิดใหม่ก่อนคุณสามารถตั้งค่าการทดสอบ hyper-paramater test_mode เป็น TRUE มันจะโหลดข้อมูลเพียงไม่กี่ข้อมูลและเริ่มฝึกอบรมอย่างรวดเร็ว
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_MODEL: มิติของแบบจำลอง [512]
num_layer: จำนวนเลเยอร์ [6]
num_header: จำนวนส่วนหัวของความสนใจตนเอง [8]
D_K: มิติของคีย์ (k) มิติของการสืบค้น (q) เหมือนกัน [64]
D_V: มิติของ V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
แต่ละบรรทัดคือเอกสาร (หลายประโยค) หรือประโยค นั่นคือข้อความฟรีที่คุณสามารถทำได้อย่างง่ายดาย
ตรวจสอบข้อมูล/bert_train.txt หรือ bert_train2.txt ในไฟล์ zip
อินพุตและเอาต์พุตอยู่ในบรรทัดเดียวกันแต่ละป้ายจะเริ่มต้นด้วย ' ฉลาก '
มีช่องว่างระหว่างสตริงอินพุตและฉลากแรกแต่ละฉลากจะถูกแยกออกจากพื้นที่
เช่น token1 token2 token3 __label__l1 __label__l5 __label__l3
TOKEN1 TOKEN2 TOKEN3 __label__l2 __label__l4
ตรวจสอบข้อมูล/bert_train.txt หรือ bert_train2.txt ในไฟล์ zip
ตรวจสอบโฟลเดอร์ 'ข้อมูล' สำหรับข้อมูลตัวอย่าง โหลดข้อมูลขนาดกลางที่ตั้งไว้ที่นี่
ด้วยคลาส 450K 206 แต่ละอินพุตเป็นเอกสารความยาวเฉลี่ยอยู่ที่ประมาณ 300, หนึ่งหรือหลาย label ที่เกี่ยวข้องกับอินพุต
ดาวน์โหลดคำศัพท์ก่อนรถไฟจาก Tencent Ailab
สิ่งต่างๆสามารถง่าย:
ดาวน์โหลดชุดข้อมูล (ประมาณ 200m, 450k Data พร้อมไฟล์แคชบางส่วน) เปิดซิปและใส่ลงใน Data/ Folder
เรียกใช้ขั้นตอนที่ 1 สำหรับ Pre-Train
และเรียกใช้ขั้นตอนที่ 2 เพื่อปรับแต่ง
ฉันจบเหนือสามขั้นตอนและต้องการมีประสิทธิภาพที่ดีขึ้นฉันจะทำอย่างไรต่อไป ฉันต้องหาชุดข้อมูลขนาดใหญ่หรือไม่?
ไม่คุณสามารถสร้างชุดข้อมูลขนาดใหญ่ที่ตั้งไว้สำหรับขั้นตอนก่อนรถไฟได้โดยการดาวน์โหลดข้อความฟรีบางอย่างตรวจสอบให้แน่ใจว่าแต่ละบรรทัด
เป็นเอกสารหรือประโยคจากนั้นแทนที่ข้อมูล/bert_train2.txt ด้วยไฟล์ข้อมูลใหม่ของคุณ
มีอะไรอีกบ้าง?
ลองใช้พารามิเตอร์ขนาดใหญ่หรือโมเดลขนาดใหญ่ (โดยการแทนที่เครือข่ายแบ็คโบน) UTIL คุณสามารถสังเกตข้อมูลล่วงหน้าทั้งหมดของคุณ
เล่นกับรุ่น: รุ่น/bert_cnn_model.py หรือตรวจสอบกระบวนการล่วงหน้าด้วย data_util_hdf5.py
รูปแบบภาษาที่บดกับ Pretrain และงานทำนายประโยคถัดไปในคลังข้อมูลขนาดใหญ่
ขึ้นอยู่กับแบบจำลองการทัศนวิสัยด้วยตนเองหลายชั้นจากนั้นปรับจูนโดยเพิ่มเลเยอร์การจำแนกประเภท
เนื่องจากโมเดลเบิร์ตขึ้นอยู่กับหม้อแปลงปัจจุบันเรากำลังทำงานเพื่อเพิ่มงาน pretrain ให้กับโมเดล
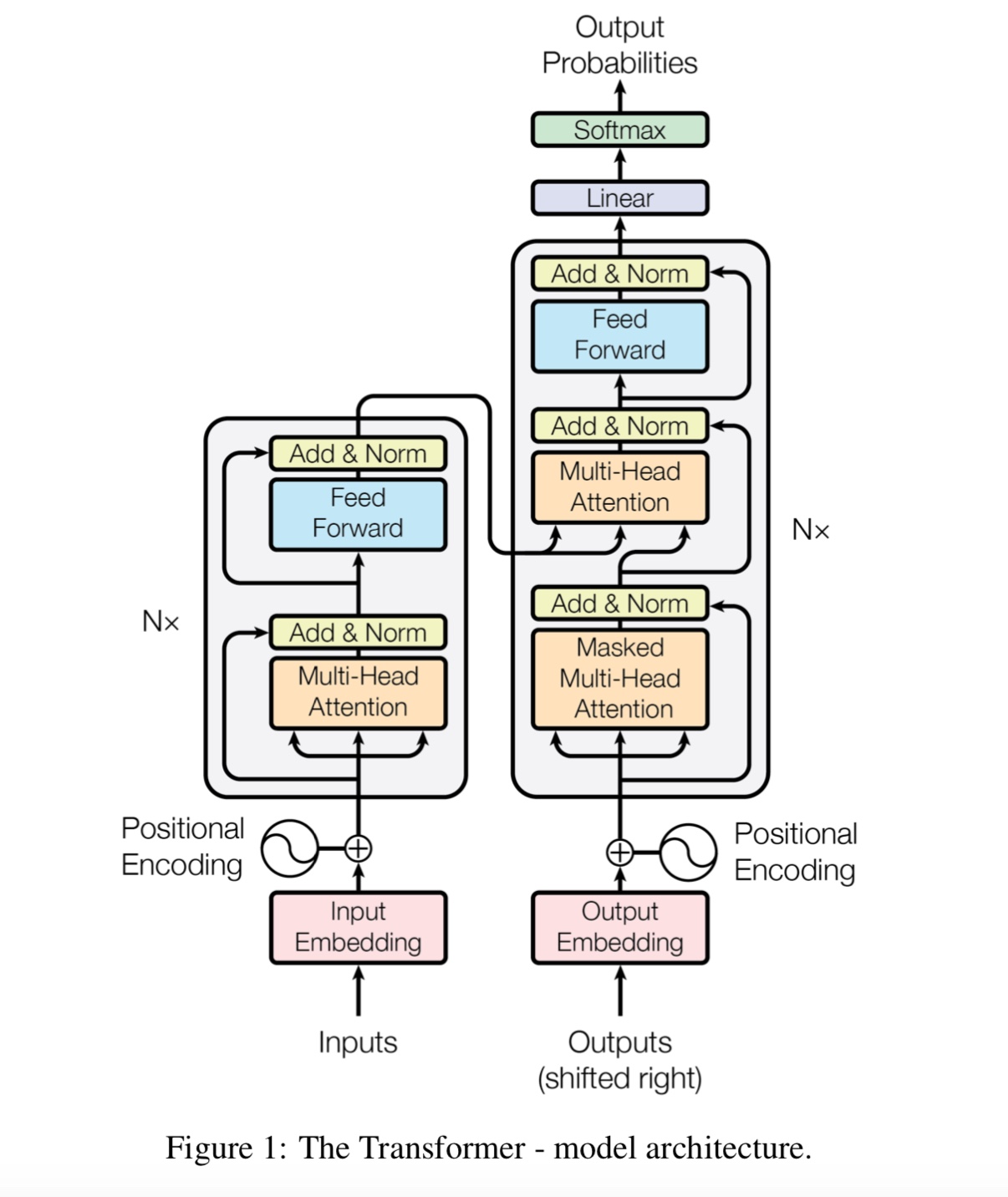
ข้อสังเกต: Cail2018 อยู่ที่ประมาณ 450K เป็นลิงค์ด้านบน
ขนาดการฝึกอบรมของชุดข้อมูลส่วนตัวอยู่ที่ประมาณ 100k จำนวนคลาสคือ 9 สำหรับแต่ละอินพุตมีหนึ่งหรือมากกว่าหนึ่งฉลาก
คะแนน F1 สำหรับ Cail2018 ถูกรายงานว่าเป็นคะแนน Micro F1
แนวคิดพื้นฐานนั้นง่ายมาก เป็นเวลาหลายปีที่ผู้คนได้รับผลลัพธ์ที่ดีมาก "ฝึกอบรมก่อน" DNNS เป็นรูปแบบภาษา
จากนั้นการปรับแต่งอย่างละเอียดเกี่ยวกับงาน NLP ปลายน้ำ (การตอบคำถามการอนุมานภาษาธรรมชาติการวิเคราะห์ความเชื่อมั่น ฯลฯ )
โดยทั่วไปแล้วแบบจำลองภาษาจะเป็นไปขวา-ขวาเช่น:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
ปัญหาคือสำหรับงานดาวน์สตรีมที่คุณมักไม่ต้องการรูปแบบภาษาคุณต้องการการแสดงบริบทที่ดีที่สุดเท่าที่จะเป็นไปได้
แต่ละคำ หากแต่ละคำสามารถมองเห็นบริบททางด้านซ้ายได้ชัดเจนว่ามีจำนวนมากหายไป ดังนั้นเคล็ดลับอย่างหนึ่งที่ผู้คนทำก็คือการฝึกอบรมก
โมเดลจากขวาไปซ้ายเช่น:
P(store|</s>)*P(a|store </s>)*…
ตอนนี้คุณมีตัวแทนสองคำของแต่ละคำหนึ่งจากซ้ายไปขวาและหนึ่งจากขวาไปซ้ายและคุณสามารถเชื่อมต่อพวกเขาเข้าด้วยกันสำหรับงานดาวน์สตรีมของคุณ
แต่โดยสังหรณ์ใจมันจะดีกว่ามากถ้าเราสามารถฝึกอบรมรุ่นเดียวที่เป็นแบบสองทิศทางอย่างลึกซึ้ง
น่าเสียดายที่เป็นไปไม่ได้ที่จะฝึกอบรมแบบสองทิศทางแบบลึกเช่น LM ปกติเพราะนั่นจะสร้างวัฏจักรที่คำสามารถทางอ้อม
"เห็นตัวเอง" และการคาดการณ์กลายเป็นเรื่องเล็กน้อย
สิ่งที่เราสามารถทำได้แทนที่จะเป็นเคล็ดลับง่าย ๆ ที่ใช้ในการเข้ารหัสอัตโนมัติที่ไม่น่าสนใจ
ต้องสร้างคำเหล่านั้นขึ้นใหม่จากบริบท เราเรียกสิ่งนี้ว่า "Masked LM" แต่มักจะเรียกว่างาน Cloze
เราป้อนอินพุตผ่านตัวเข้ารหัสหม้อแปลงลึกจากนั้นใช้สถานะที่ซ่อนอยู่สุดท้ายที่สอดคล้องกับตำแหน่งที่สวมหน้ากาก
ทำนายว่าคำใดถูกสวมหน้ากากเหมือนที่เราจะฝึกแบบจำลองภาษา
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
จะได้รับสถานะที่ซ่อนอยู่สุดท้ายของตำแหน่งหน้ากากได้อย่างไร?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
สำหรับรายละเอียดเพิ่มเติมให้ตรวจสอบวิธีการของ MASK_LANGUAGE_MODE
งานทำความเข้าใจภาษามากมายเช่นการตอบคำถามการอนุมานต้องการความสัมพันธ์ที่เข้าใจ
ระหว่างประโยค อย่างไรก็ตามรูปแบบภาษาสามารถเข้าใจได้โดยไม่ต้องมีประโยคเท่านั้น ประโยคถัดไป
การทำนายเป็นงานตัวอย่างที่จะช่วยให้แบบจำลองเข้าใจได้ดีขึ้นในงานประเภทนี้
50% ของโอกาสประโยคที่สองคือประโยคถัดไปของประโยคแรก 50% ของไม่ใช่ประโยคถัดไป
ให้สองประโยคแบบจำลองนี้ถูกขอให้ทำนายว่าประโยคที่สองเป็นประโยคต่อไปของจริง
คนแรก
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
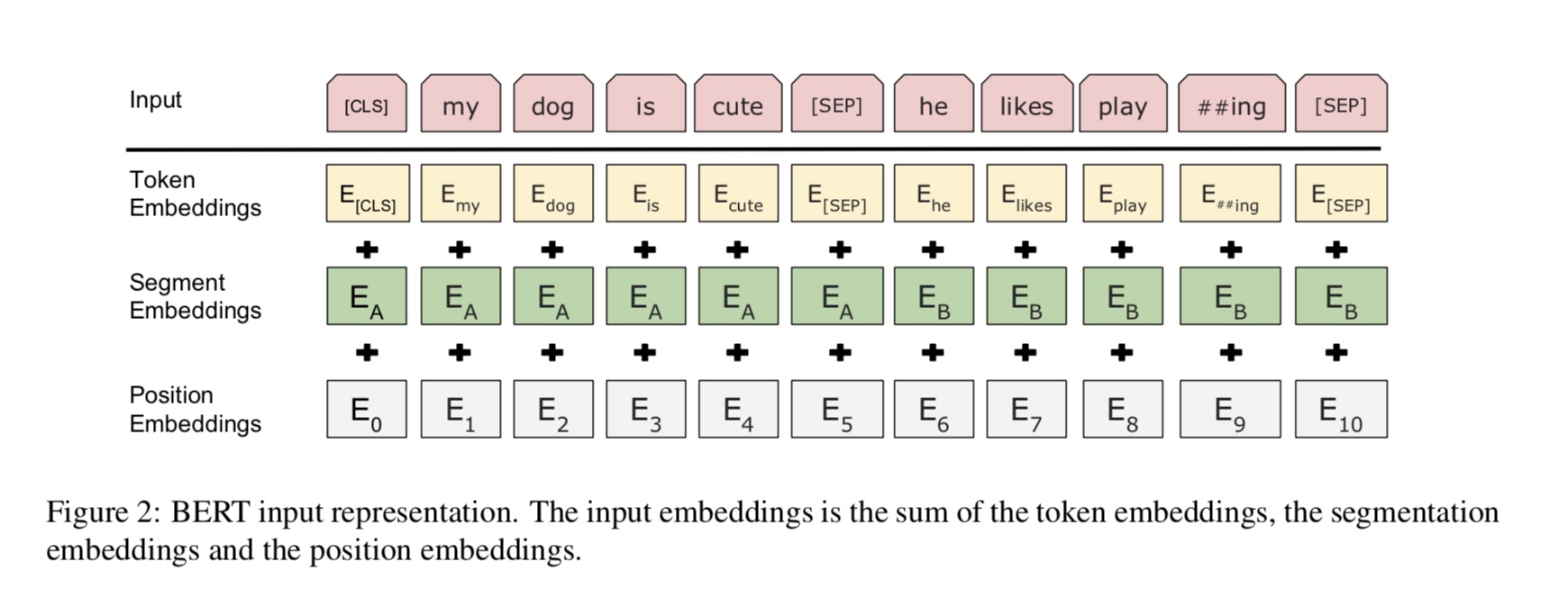
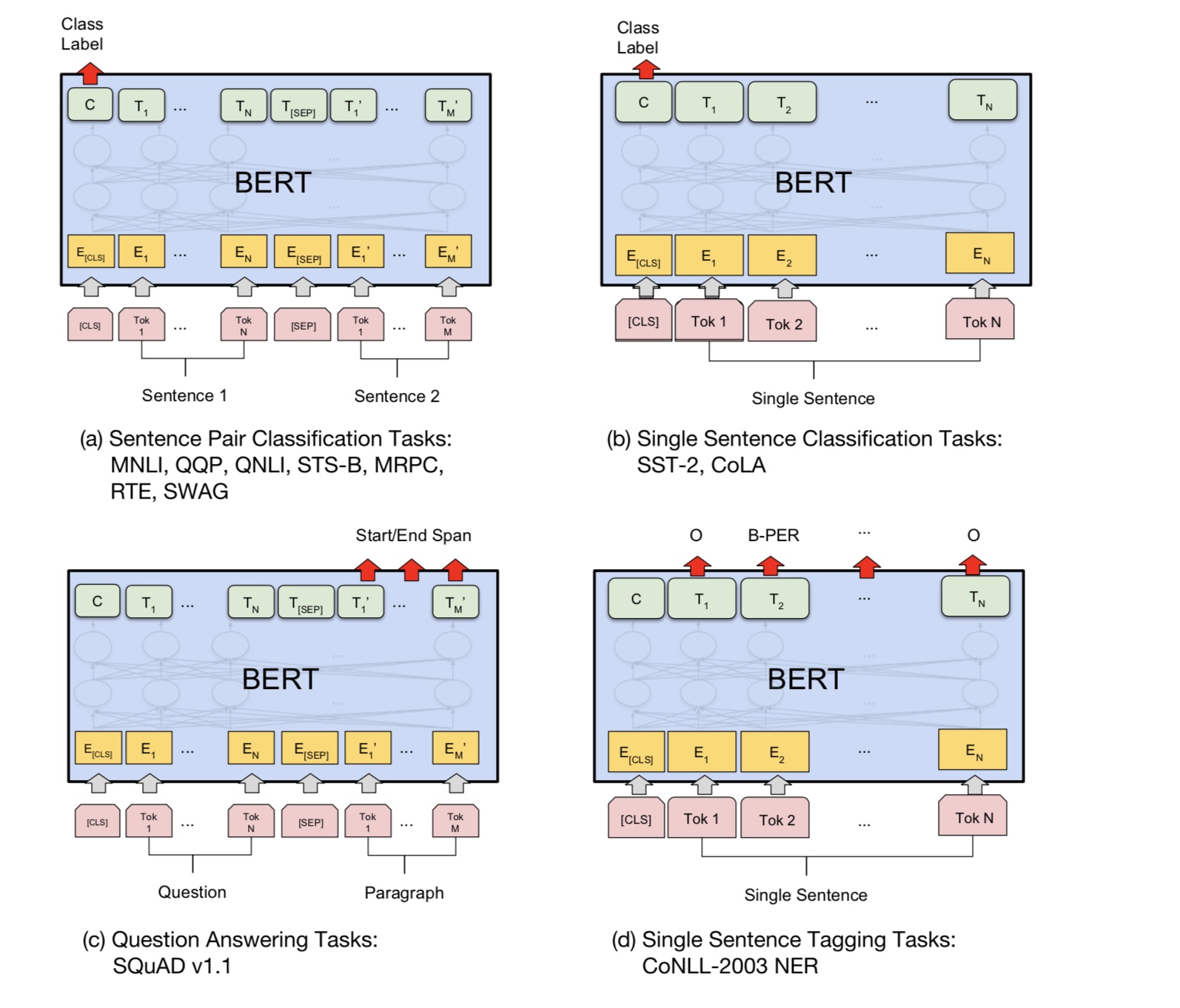
Python 3+ Tensorflow 1.10
ส่วนแบ่งและไม่แบ่งปันระหว่างขั้นตอนก่อนรถไฟและการปรับจูน?
1) โดยทั่วไปพารามิเตอร์ทั้งหมดของเครือข่ายกระดูกสันหลังที่ใช้โดยขั้นตอนก่อนรถไฟและการปรับแต่งจะถูกแชร์กัน
2). ในขณะที่เราสามารถแบ่งปันพารามิเตอร์ให้มากที่สุดเท่าที่จะเป็นไปได้ดังนั้นในช่วงการปรับแต่งเราจำเป็นต้องเรียนรู้น้อย
พารามิเตอร์ที่สุดเท่าที่จะเป็นไปได้เรายังแบ่งปันคำที่ฝังคำสำหรับสองขั้นตอนนี้
3) ดังนั้นพารามิเตอร์ส่วนใหญ่ได้เรียนรู้แล้วในช่วงเริ่มต้นของขั้นตอนการปรับแต่ง
เราใช้โมเดลภาษาที่สวมหน้ากากอย่างไร
เพื่อทำสิ่งต่าง ๆ ได้อย่างง่ายดายเราสร้างประโยคจากเอกสารแบ่งออกเป็นประโยค สำหรับแต่ละประโยค
เราตัดทอนและขยายให้มีความยาวเท่ากันและสุ่มเลือกคำจากนั้นแทนที่ด้วย [หน้ากาก] ตัวเองและแบบสุ่ม
คำ.
จะทำให้ขั้นตอนการปรับแต่งได้ดีขึ้นในขณะที่ไม่ทำลายผลลัพธ์และความรู้ที่เราเรียนรู้จากขั้นตอนก่อนรถไฟ?
เราใช้อัตราการเรียนรู้เล็ก ๆ ในระหว่างการปรับแต่งดังนั้นการปรับจึงทำในระดับเล็กน้อย
ทำไมเราต้องใส่ใจในตนเอง?
ความสนใจด้วยตนเองเครือข่ายรูปแบบใหม่เมื่อเร็ว ๆ นี้ได้รับความสนใจมากขึ้นเรื่อย ๆ ตามเนื้อผ้าเราใช้
RNN หรือ CNN เพื่อแก้ปัญหา อย่างไรก็ตาม RNN มีปัญหาในคู่ขนานและ CNN ไม่ดีในงานที่มีความละเอียดอ่อนตำแหน่ง
ความตั้งใจด้วยตนเองสามารถทำงานได้แบบขนานในขณะที่สามารถจำลองการพึ่งพาทางไกลได้
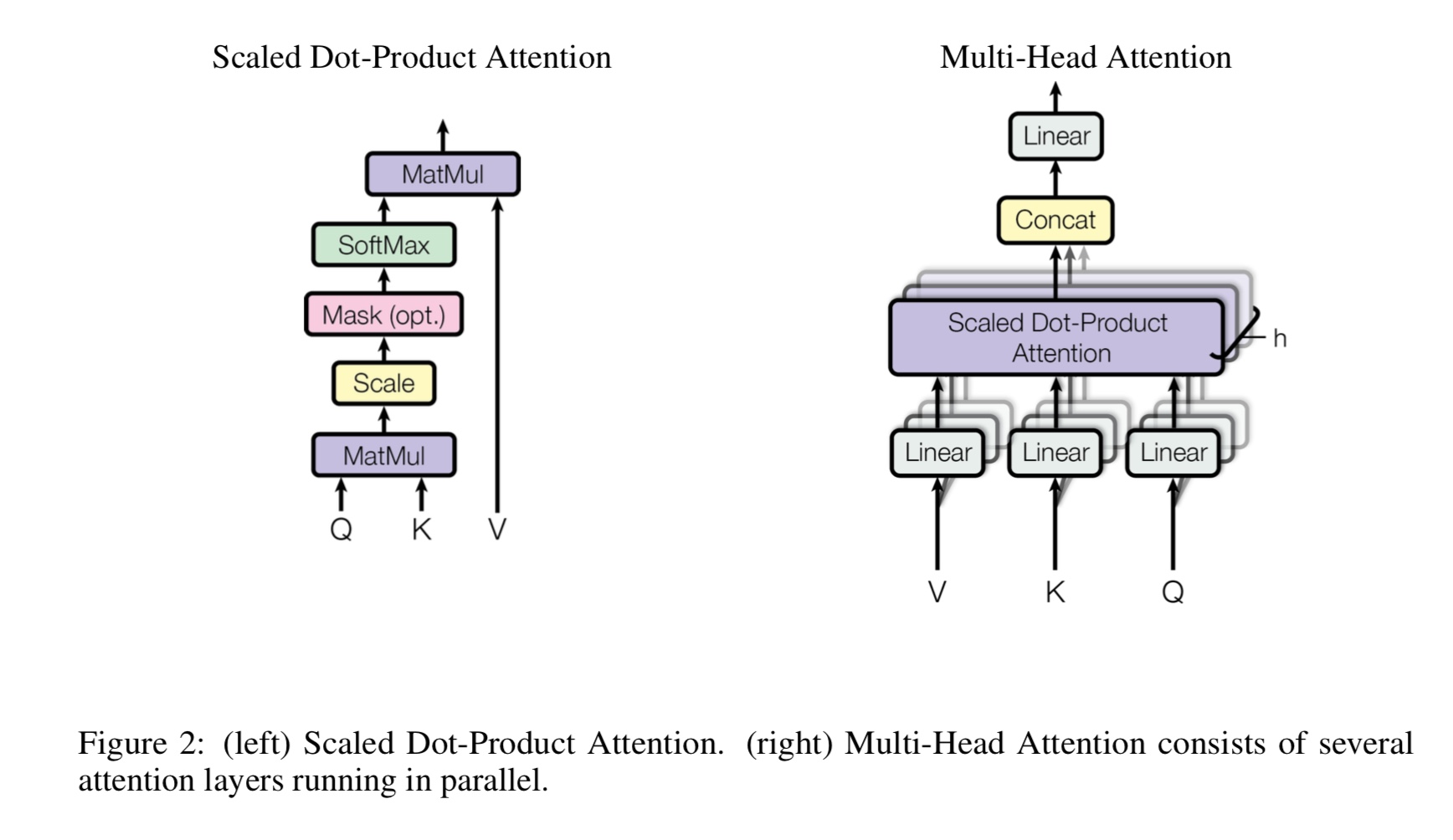
การตั้งใจด้วยตนเองหลายหัวคืออะไร Q, K, V หมายถึงอะไร? เพิ่มบางอย่างที่นี่
Mulit-Heads การตั้งใจด้วยตนเองคือความตั้งใจของตนเองในขณะที่มันแบ่งและโครงการ Q และ K เป็นพื้นที่ย่อยที่แตกต่างกันหลายแห่ง
จากนั้นให้ความสนใจ
q ยืนสำหรับคำถาม k ยืนสำหรับกุญแจ สำหรับงานการแปลของเครื่อง Q คือสถานะที่ซ่อนอยู่ก่อนหน้านี้
สถานะที่ซ่อนอยู่ของ encoder แต่ละองค์ประกอบของ K จะคำนวณคะแนนความคล้ายคลึงกันกับ q จากนั้นจะใช้ softmax
ในการทำคะแนนปกติเราจะได้รับน้ำหนัก ในที่สุดก็มีการคำนวณผลรวมถ่วงน้ำหนักโดยใช้น้ำหนักใช้กับ v
แต่ในสถานการณ์การดูแลตนเอง, Q, K, V นั้นเหมือนกันทั้งหมดเช่นเดียวกับการแสดงลำดับอินพุตของงาน
Feedfoward ตำแหน่งที่ชาญฉลาดคืออะไร?
มันเป็นเลเยอร์ไปข้างหน้าฟีดหรือที่เรียกว่าเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ (FC) แต่เนื่องจากในหม้อแปลงอินพุตและเอาต์พุตทั้งหมดของ
เลเยอร์เป็นลำดับของเวกเตอร์: [sequence_length, d_model] เรามักจะทำ FC กับเวกเตอร์ของอินพุต ดังนั้นเราจึงทำอีกครั้ง
แต่ขั้นตอนเวลาที่แตกต่างกันมี FC ของตัวเอง
ผลงานหลักของเบิร์ตคืออะไร?
ในขณะที่งานก่อนการฝึกอบรมมีอยู่แล้วมาหลายปีแล้วมันก็แนะนำวิธีใหม่ (เรียกว่าสองทิศทาง) เพื่อทำแบบจำลองภาษา
และใช้สำหรับงานสตรีมดาวน์ เนื่องจากข้อมูลสำหรับรูปแบบภาษามีอยู่ทั่วไป มันพิสูจน์แล้วว่ามีพลังและด้วยเหตุนี้มันจึงเปลี่ยนรูปร่าง
NLP World
เหตุใดผู้เขียนจึงใช้โทเค็นสามประเภทที่แตกต่างกันเมื่อสร้างข้อมูลการฝึกอบรมของรูปแบบภาษาที่สวมหน้ากาก
ผู้เขียนเชื่อว่าในขั้นตอนการปรับแต่งไม่มีโทเค็น [หน้ากาก] ดังนั้นมันจึงไม่ตรงกันระหว่างการรถไฟก่อนและปรับแต่ง
นอกจากนี้ยังบังคับให้โมเดลให้ความสนใจข้อมูลบริบททั้งหมดในประโยค
อะไรที่ทำให้แบบจำลอง Bert เพื่อให้ได้งานศิลปะใหม่ส่งผลให้งานทำความเข้าใจภาษา?
โมเดลขนาดใหญ่การคำนวณขนาดใหญ่และที่สำคัญที่สุด-อัลกอริทึมใหม่ก่อนการฝึกอบรมแบบจำลองโดยใช้ข้อมูลข้อความฟรี
งานของเล่นใช้เพื่อตรวจสอบว่าโมเดลสามารถทำงานได้อย่างถูกต้องโดยไม่ต้องพึ่งพาข้อมูลจริงหรือไม่
มันขอให้โมเดลนับจำนวนและรวมของอินพุตทั้งหมด และมีการใช้เกณฑ์
หากการรวมดีกว่า (หรือน้อยกว่า) กว่าเกณฑ์แล้วแบบจำลองจะต้องทำนายเป็น 1 (หรือ 0)
ภายในโมเดล/transform_model.py มีรถไฟและทำนายวิธีการ
ก่อนอื่นคุณสามารถเรียกใช้รถไฟ () เพื่อเริ่มการฝึกอบรมจากนั้นเรียกใช้ทำนาย () เพื่อเริ่มทำนายโดยใช้แบบจำลองที่ผ่านการฝึกอบรม
เนื่องจากโมเดลค่อนข้างใหญ่ด้วย HyperParamter เริ่มต้น (D_Model = 512, H = 8, D_V = D_K = 64, NUM_LAYER = 6) ต้องใช้ข้อมูลจำนวนมากก่อนที่จะสามารถมาบรรจบกัน
จำเป็นต้องมีขั้นตอนอย่างน้อย 10k ก่อนที่การสูญเสียจะน้อยกว่า 0.1 หากคุณต้องการฝึกมันอย่างรวดเร็วด้วยขนาดเล็ก
ข้อมูลคุณสามารถใช้ชุด HyperParmeter ขนาดเล็ก (d_model = 128, H = 8, d_v = d_k = 16, num_layer = 6)
คุณสามารถใช้การจำแนกประเภทไบนารีสองประเภทการจำแนกประเภทหลายชั้นหรือปัญหาการจำแนกประเภทหลายฉลาก
มันจะพิมพ์การสูญเสียระหว่างการฝึกอบรมและพิมพ์คะแนน F1 สำหรับแต่ละยุคระหว่างการตรวจสอบ
แก้ไขข้อผิดพลาดในหม้อแปลง [สำคัญรับสมัครสมาชิกในทีมและต้องการคำขอผสาน]
(หม้อแปลง: ทำไมการสูญเสียระยะก่อนรถไฟลดลงสำหรับระยะแรก แต่การสูญเสียยังไม่เล็กมาก (เช่นการสูญเสีย = 8.0) แม้กับ
ข้อมูลก่อนการฝึกอบรมมากขึ้นการสูญเสียยังไม่เล็ก)
สนับสนุนงานประโยคคู่ [สำคัญรับสมัครสมาชิกในทีมและต้องการคำขอผสาน]
เพิ่มงานก่อนการฝึกอบรมการทำนายประโยคถัดไป [สำคัญ, รับสมัครสมาชิกในทีมและต้องการคำขอรวม]
ต้องการชุดข้อมูลสำหรับการวิเคราะห์ความเชื่อมั่นหรือการจำแนกข้อความเป็นภาษาอังกฤษ [สำคัญ, รับสมัครสมาชิกในทีมและต้องการคำขอผสาน]
การฝังตำแหน่งยังไม่ได้ใช้ร่วมกันระหว่างการฝึกก่อนและการปรับแต่ง ตั้งแต่ที่นี่เกี่ยวกับความยาวเวทีก่อนรถไฟพฤษภาคม
สั้นกว่าขั้นตอนการปรับแต่ง
ด้ามจับพิเศษโทเค็นแรก [CLS] เป็นอินพุตและการจำแนกประเภท [เสร็จสิ้น]
ฝึกอบรมล่วงหน้าด้วย Fine_tuning: ต้องการคำศัพท์โหลดของโทเค็นจากขั้นตอนก่อนรถไฟ แต่ฉลากจากงานจริง [เสร็จแล้ว]
อัตราการเรียนรู้ควรจะเล็กลงเมื่อปรับแต่ง [เสร็จแล้ว]
Pre-Train คือทั้งหมดที่คุณต้องการ ในขณะที่ใช้หม้อแปลงหรือโมเดลลึกที่ซับซ้อนอื่น ๆ สามารถช่วยให้คุณบรรลุประสิทธิภาพสูงสุด
ในงานบางอย่างให้ pretrain กับรุ่นอื่น ๆ เช่น textcnn โดยใช้ข้อมูลดิบจำนวนมากจากนั้นปรับแต่งโมเดลของคุณในชุดข้อมูลเฉพาะงาน
จะช่วยให้คุณได้รับประสิทธิภาพเพิ่มเติมเสมอ
เพิ่มเพิ่มเติมที่นี่
เพิ่มข้อเสนอแนะปัญหาปัญหาหรือต้องการบริจาคยินดีต้อนรับสู่การติดต่อกับฉัน: [email protected]
ความสนใจคือสิ่งที่คุณต้องการ
เบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อความเข้าใจภาษา
Tensor2tensor สำหรับการแปลเครื่องประสาท
เครือข่ายประสาท Convolutional สำหรับการจำแนกประโยค
Cail2018: ชุดข้อมูลทางกฎหมายขนาดใหญ่สำหรับการทำนายการตัดสิน


