bert_language_understanding
1.0.0
Bert는 최근 10 개 이상의 NLP 작업에서 새로운 최첨단 결과를 달성합니다.
이것은 언어 이해를위한 심층 양방향 변압기의 사전 훈련의 텐서 플로 구현입니다.
(Bert) 및주의 만 있으면됩니다 (변압기).
업데이트 :이 두 논문의 복제 주요 아이디어의 대다수 부분이 완료되었으며, 명백한 성능 이득이 있습니다.
사전 훈련의 경우 모델 및 미세 조정을 비교하여 모델을 처음부터 훈련시킵니다.
우리는 변압기에서 TextCNN으로 BERT의 백본 네트워크를 대체하기위한 실험을 수행했으며 결과적으로
많은 원시 데이터를 사용하여 마스크 언어 모델로 모델을 사전 트레인하면 성능이 눈에 띄게 향상 될 수 있습니다.
보다 일반적으로, 우리는 사전 훈련 및 미세 조정 전략이 모델 독립적이고 사전 훈련 작업 독립이라고 생각합니다.
그렇게 말하면, 당신은 원하는대로 백본 네트워크를 교체 할 수 있습니다. 더 많은 사전 훈련 작업을 추가하거나 새로운 사전 훈련 작업을 다음과 같이 정의하십시오.
사전 훈련은 가면 언어 모델로 제한되지 않거나 다음 문장 작업을 예측할 수 있습니다. 우리가 놀랍게도
외부 데이터를 사용하지 않아도 백만 명이 말하는 중간 크기의 데이터 세트를 사용하여 사전 훈련 작업을 수행합니다.
마스크 된 언어 모델과 마찬가지로 성능은 큰 마진으로 향상 될 수 있으며 모델은 빠르게 수렴 할 수 있습니다. 언젠가
훈련은 미세 조정 단계에서 몇 가지 시대가 필요할 수 있습니다.
오픈 소스 (Tensor2tensor)와 공식이 있습니다
Transformer 및 Bert 공식 구현이 곧 출시 될 수 있지만 읽기가 어려울 수 있습니다. 이해하기 쉽습니다.
우리는 원본 논문을 완전히 복제하려는 의도가 아니라 주요 아이디어를 적용하고 NLP 문제를 더 나은 방법으로 해결해야합니다.
여기에서 작업하는 대다수의 부분은 작년에 또 다른 저장소에 의해 수행되었습니다 : 텍스트 분류
중간 크기 데이터 세트 (CAIL2018, 450K)
| 모델 | TextCnn (프레세 인) | TextCnn (프리 트레인-피니 튜닝) | 사전 훈련으로부터 이득 |
|---|---|---|---|
| 1 epoch 후 F1 점수 | 0.09 | 0.58 | 0.49 |
| 5 에포크 후 F1 점수 | 0.40 | 0.74 | 0.35 |
| 7 시점 후 F1 점수 | 0.44 | 0.75 | 0.31 |
| 35 에포크 후 F1 점수 | 0.58 | 0.75 | 0.27 |
| 처음에 훈련 손실 | 284.0 | 84.3 | 199.7 |
| 1 epoch 후 유효성 검사 손실 | 13.3 | 1.9 | 11.4 |
| 5 Epoch 이후의 검증 손실 | 6.7 | 1.3 | 5.4 |
| 훈련 시간 (단일 GPU) | 8h | 2h | 6H |
알아채다:
A. Fine-Tuning Stage는 Max Epoch가 35에 도달함에 따라 7 Epoch를 실행 한 후 훈련을 완료했습니다.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
C.F1 점수는 여기에보고 된 점수는 F1 점수의 평균 및 매크로의 평균 인 검증 세트에 있습니다.
35 에포크 후 D.F1 점수는 테스트 세트에보고됩니다.
이자형. 450K RAW 문서에서 가면 언어 모델에 대해 2 백만 개의 교육 데이터를 검색했습니다.
pre-train stage finished within 5 hours in single GPU.
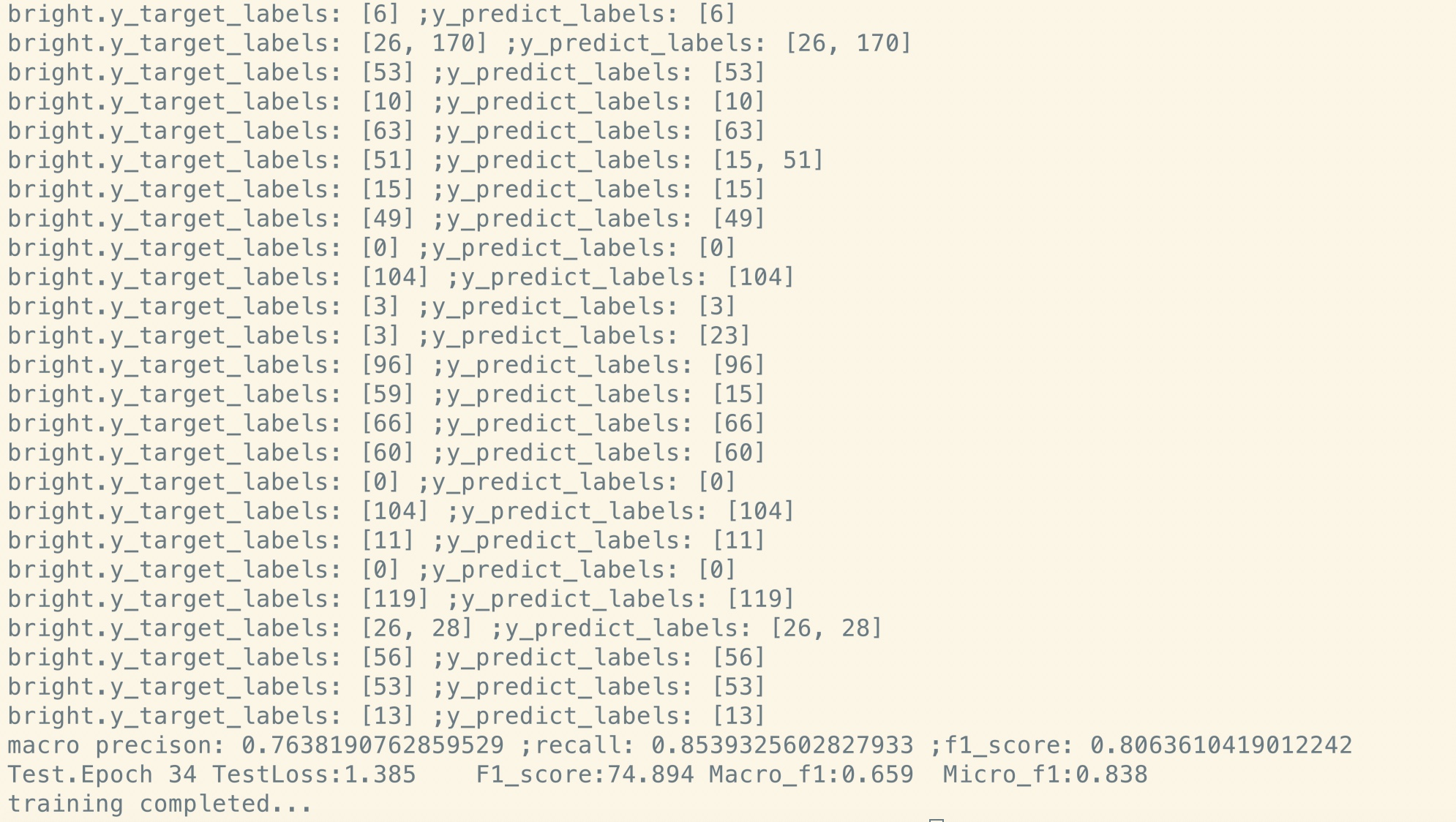
사전 훈련 후 미세 조정 :
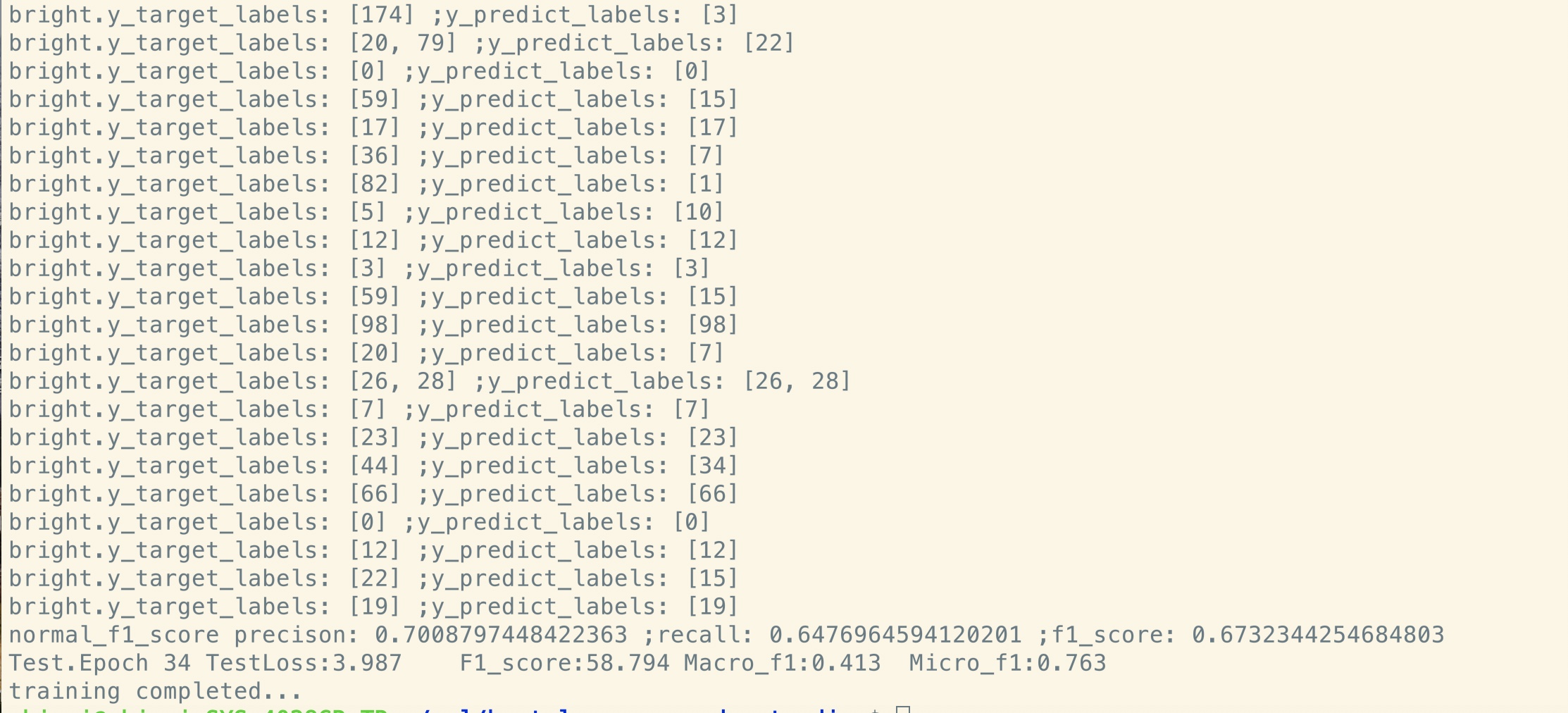
사전 훈련 없음 :
작은 크기 데이터 세트 (개인, 100k)
| 모델 | TextCnn (프레세 인) | TextCnn (프리 트레인-피니 튜닝) | 사전 훈련으로부터 이득 |
|---|---|---|---|
| 1 epoch 후 F1 점수 | 0.44 | 0.57 | 10%+ |
| 1 epoch 후 유효성 검사 손실 | 55.1 | 1.0 | 54.1 |
| 처음에 훈련 손실 | 68.5 | 8.2 | 60.3 |
마스크 언어 모델과 미세 조정의 사전 훈련으로 Bert를 시도하고 싶다면. 두 단계를 수행하십시오.
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
보시다시피, 미세 조정의 시작점에서도 미리 훈련 된 모델에서 매개 변수를 복원 한 직후 모델 손실은 더 작습니다.
완전히 새로운 교육보다 F1 점수도 높아지고 새로운 모델은 0에서 시작될 수 있습니다.
주목 : 새로운 아이디어를 먼저 시도하는 데 도움이 되려면 하이퍼 패러 메이터 test_mode를 true로 설정할 수 있습니다. 데이터가 거의없고 빨리 훈련을 시작합니다.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
d_model : 모델의 차원. [512]
Num_Layer : 레이어 수. [6]
NUM_HEADER : 자기 변환 헤더 수 [8]
D_K : 키 차원 (k). 쿼리의 치수 (Q)는 동일합니다. [64]
D_V : V의 차원 [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
각 줄은 문서 (여러 문장) 또는 문장입니다. 그것은 당신이 쉽게 얻을 수있는 자유 텍스트입니다.
zip 파일에서 data/bert_train.txt 또는 bert_train2.txt를 확인하십시오.
입력 및 출력은 같은 줄에 있으며 각 레이블은 ' 레이블 '으로 시작됩니다.
입력 문자열과 첫 번째 레이블 사이에는 공간이 있으며 각 레이블은 공간으로 분할됩니다.
예를 들어, Token1 Token2 Token3 __label__l1 __label__l5 __label__l3
Token1 Token2 Token3 __Label__L2 __Label__L4
zip 파일에서 data/bert_train.txt 또는 bert_train2.txt를 확인하십시오.
샘플 데이터에 대한 '데이터'폴더를 확인하십시오. 다운로드 중간 크기 데이터 세트를 여기에로드하십시오
450k 206 클래스의 경우 각 입력은 문서이며 평균 길이는 약 300, 하나 또는 다중 라벨은 입력과 관련이 있습니다.
Tencent Ailab에서 사전 트레인 단어 임베딩을 다운로드하십시오
쉬운 일이 될 수 있습니다.
데이터 세트 (약 200m, 450k 데이터, 일부 캐시 파일 포함)를 다운로드하고 압축을 풀고 데이터/ 폴더에 넣으십시오.
사전 훈련에 대한 1 단계 실행
미세 조정을 위해 2 단계를 실행하십시오.
나는 세 단계 이상을 마치고 더 나은 성능을 갖기를 원합니다. 어떻게 더 할 수 있습니까? 큰 데이터 세트를 찾아야합니까?
아니요. 프리 텍스트를 다운로드하여 사전 트레인 단계를 위해 빅 데이터 세트를 생성 할 수 있습니다. 각 라인을 확인하십시오.
문서 또는 문장 인 다음 데이터/bert_train2.txt를 새 데이터 파일로 바꾸십시오.
무엇이 더 있습니까?
큰 하이퍼 패러라미터 또는 큰 모델 (백본 네트워크를 교체하여)을 사용해보십시오.
Model : Model/Bert_cnn_Model.py를 사용하거나 Data_util_hdf5.py로 사전 프로세스를 확인하십시오.
대규모 코퍼스의 프리 트레인 으깬 언어 모델 및 다음 문장 예측 작업,
다중 계층 자체 복원 모델을 기반으로 분류 계층을 추가하여 미세 조정을합니다.
Bert Model은 변압기를 기반으로하므로 현재 우리는 모델에 프리 트레인 작업을 추가하기 위해 노력하고 있습니다.
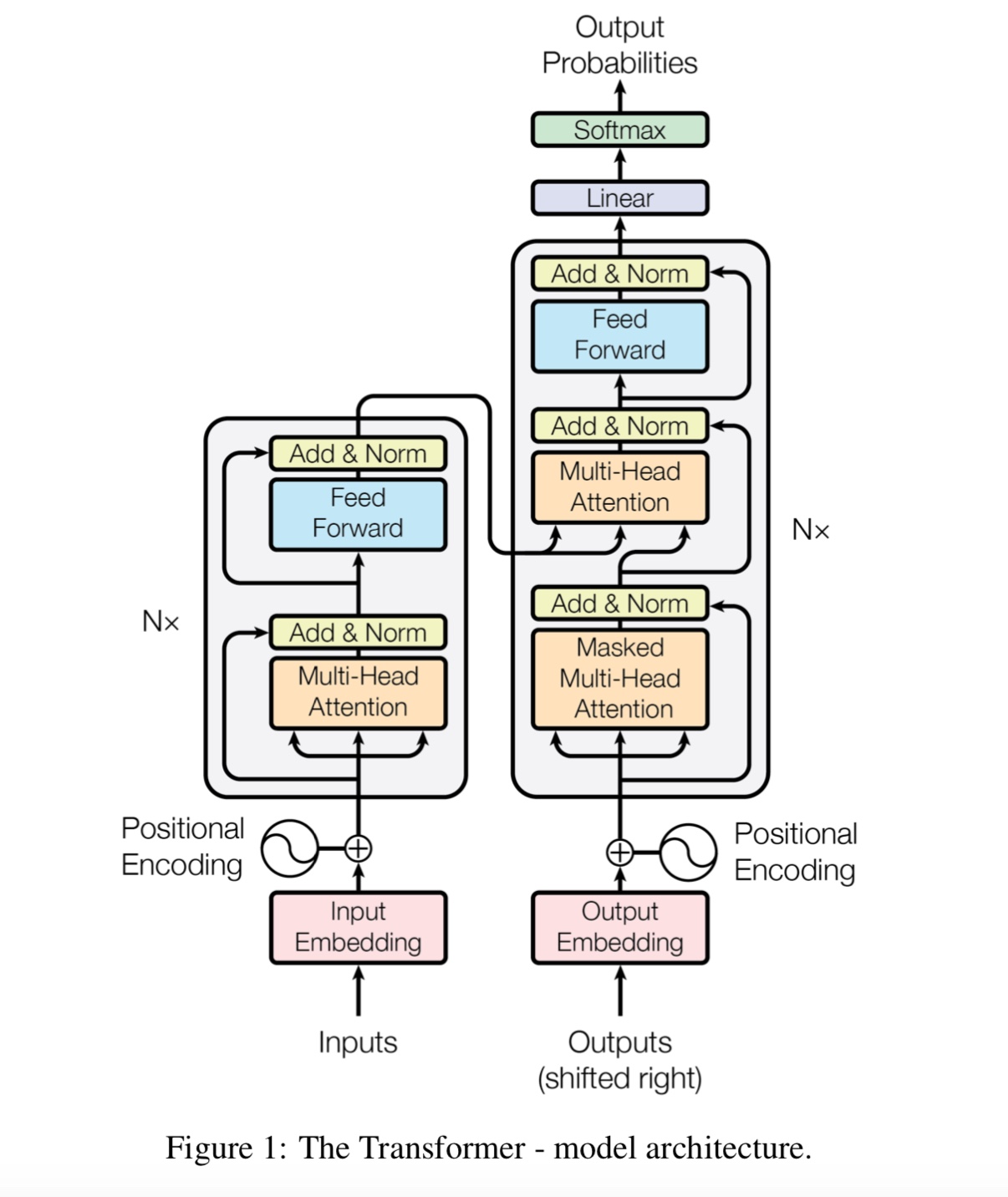
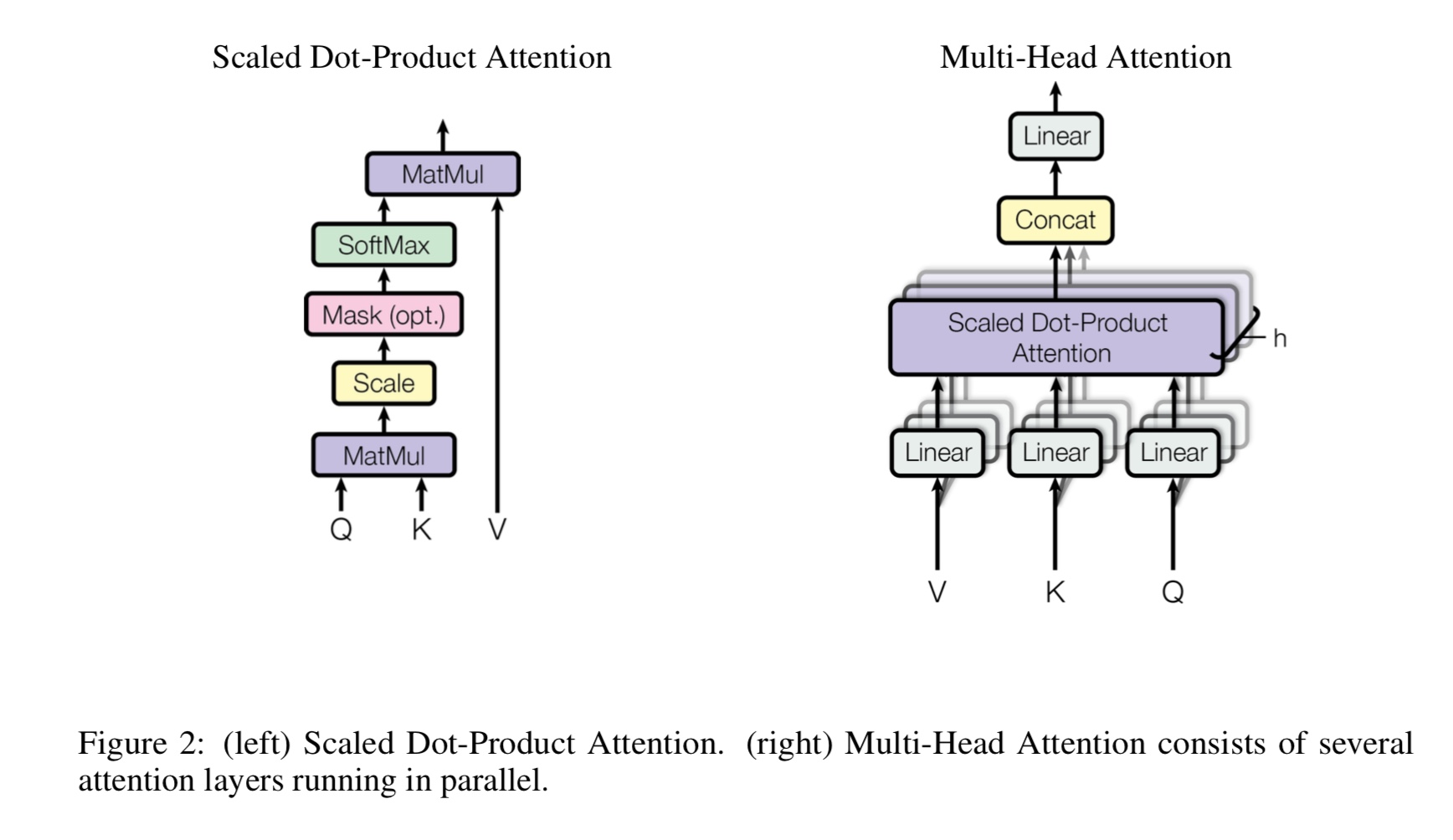
통지 : CAIL2018은 위의 링크와 같이 약 450K입니다.
개인 데이터 세트의 교육 크기는 약 100k이고 클래스 수는 9이며 각 입력에 대해 하나 이상의 레이블이 있습니다.
CAIL2018의 F1 점수는 마이크로 F1 점수로보고됩니다.
기본 아이디어는 매우 간단합니다. 몇 년 동안 사람들은 언어 모델로서 "사전 훈련"DNN을 매우 좋은 결과를 얻었습니다.
그런 다음 일부 다운 스트림 NLP 작업 (질문 응답, 자연어 추론, 감정 분석 등)을 미세 조정합니다.
언어 모델은 일반적으로 왼쪽에서 오른쪽으로입니다.
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
문제는 다운 스트림 작업의 경우 일반적으로 언어 모델을 원하지 않는다는 것입니다.
각 단어. 각 단어가 왼쪽에 대한 컨텍스트 만 볼 수 있다면 분명히 많이 누락됩니다. 그래서 사람들이 한 한 가지 트릭은 또한 훈련하는 것입니다.
오른쪽에서 왼쪽 모델, 예를 들어 :
P(store|</s>)*P(a|store </s>)*…
이제 각 단어의 두 가지 표현, 즉 왼쪽에서 오른쪽으로 하나와 오른쪽에서 왼쪽으로 두 가지 표현이 있으며 다운 스트림 작업을 위해 함께 연결할 수 있습니다.
그러나 직관적으로, 우리가 깊은 양방향 인 단일 모델을 훈련시킬 수 있다면 훨씬 나을 것입니다.
불행히도 일반 LM과 같은 깊은 양방향 모델을 훈련시키는 것은 불가능합니다. 단어는 단어가 간접적으로 될 수있는주기를 생성하기 때문입니다.
"스스로를 보라"고 예측은 사소해진다.
대신 우리가 할 수있는 것은 자동 인코더에서 데 노이징 자동 인코더에 사용되는 매우 간단한 트릭입니다.
문맥에서 그 단어를 재구성해야합니다. 우리는 이것을 "마스킹 LM"이라고 부르지 만 종종 클로즈 작업이라고합니다.
우리는 깊은 변압기 인코더를 통해 입력을 공급 한 다음 마스킹 된 위치에 해당하는 최종 숨겨진 상태를 사용합니다.
언어 모델을 훈련시키는 것처럼 어떤 단어가 가려 졌는지 예측하십시오.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
마스크 된 위치의 마지막 숨겨진 상태를 얻는 방법은 무엇입니까?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
자세한 내용은 pretrain_task.py 및 train_vert_lm.py의 mask_language_model의 메소드를 확인하십시오.
질문 응답, 추론과 같은 많은 언어 이해 작업, 관계를 이해해야합니다.
문장 사이. 그러나 언어 모델은 문장 없이만 이해할 수 있습니다. 다음 문장
예측은 이러한 종류의 작업에서 모델이 더 잘 이해하는 데 도움이되는 샘플 작업입니다.
우연의 50%는 두 번째 문장이 다음 문장의 다음 문장, 다음 문장의 다음 문장입니다.
두 문장이 주어지면 모델은 두 번째 문장이 다음의 다음 문장인지 예측하도록 요청받습니다.
첫 번째.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
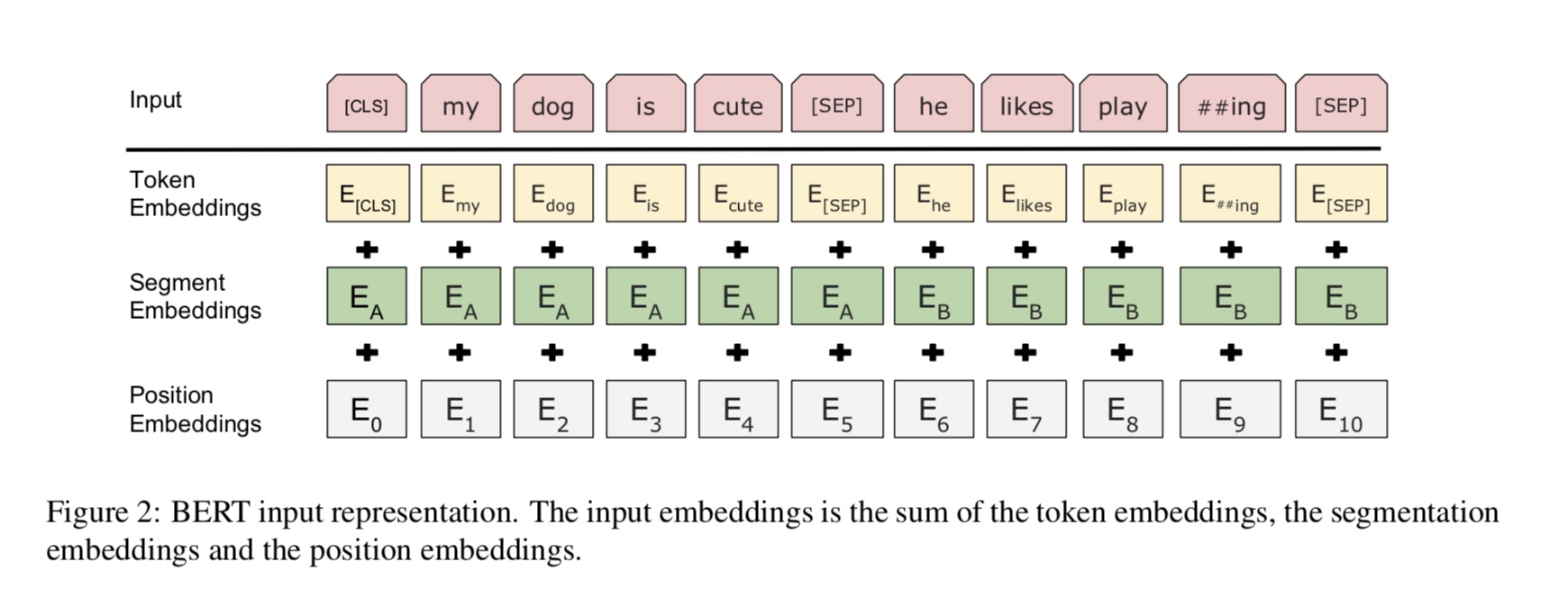
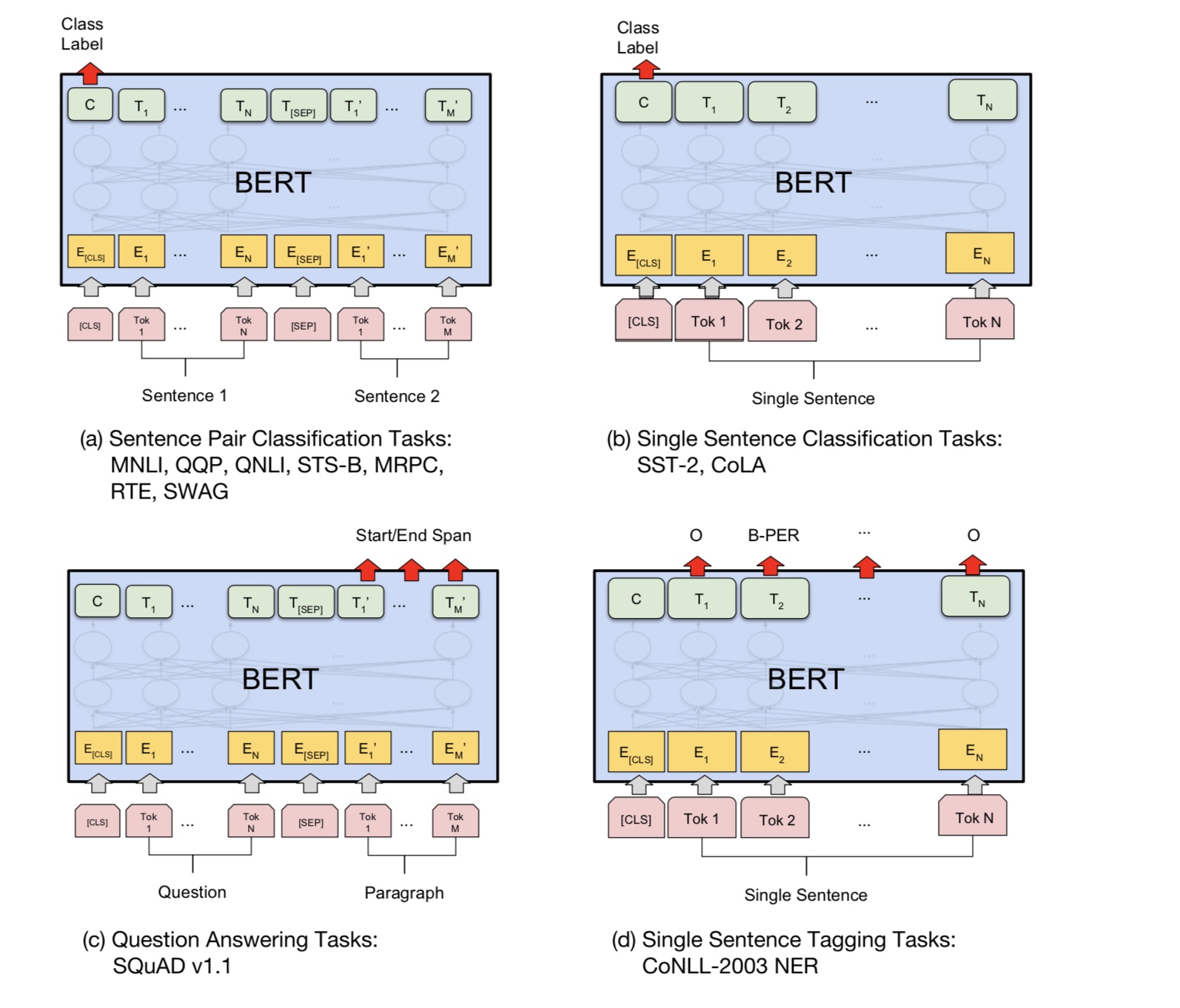
파이썬 3+ 텐서 플로 1.10
사전 훈련과 미세 조정 단계간에 어떤 공유가 공유되지 않습니까?
1) 사전 훈련 및 미세 조정 단계에서 사용하는 백본 네트워크의 모든 매개 변수는 서로 공유됩니다.
2). 가능한 한 많은 매개 변수를 공유 할 수 있으므로 미세 조정 단계에서 우리는 거의 배워야합니다.
매개 변수는 가능한 한이 두 단계에 대한 단어 임베딩도 공유했습니다.
3) 그러면 대부분의 매개 변수는 미세 조정 단계의 시작 부분에서 이미 학습되었습니다.
마스크 언어 모델을 어떻게 구현합니까?
물건을 쉽게 만들기 위해 문서에서 문장을 생성하고 문장으로 나눕니다. 각 문장에 대해
우리는 그것을 동일한 길이로 자르고 패딩하고 단어를 무작위로 선택한 다음 [마스크], 자기 자신과 무작위로 바꾸십시오.
단어.
미세 조정 단계를보다 효율적으로 만드는 방법, 우리가 사전 훈련 단계에서 배운 결과와 지식을 깨뜨리는 방법은 무엇입니까?
우리는 미세 조정 중에 작은 학습 속도를 사용하므로 조정이 적은 정도로 수행되었습니다.
왜 우리는 자기 변호가 필요한가요?
자체 소송 새로운 유형의 네트워크가 최근에 점점 더 많은 관심을받습니다. 전통적으로 우리는 사용합니다
문제를 해결하기 위해 RNN 또는 CNN. 그러나 RNN은 병렬로 문제가 있으며 CNN은 모델 위치에 민감한 작업에 적합하지 않습니다.
자체 변환은 병렬로 실행될 수 있지만 장거리 의존성을 모델링 할 수 있습니다.
멀티 헤드 자체 변환이란 무엇인가, Q, K, V는 무엇을 의미합니까? 여기에 뭔가를 추가하십시오.
Mulit-Heads의 자체 변환은 자체 정보이며, Q와 K는 여러 다른 부분 공간으로 나누고 프로젝트를 나누고 있습니다.
그런 다음주의하십시오.
Q 질문에 대해서는 K가 열쇠를 나타냅니다. 기계 번역 작업의 경우 Q는 이전에 숨겨진 디코드 상태, K는
인코더의 숨겨진 상태. K의 각 요소는 q와 유사성 점수를 계산합니다. 그런 다음 SoftMax가 사용됩니다
점수를 정상화하려면 가중치를 얻습니다. 마지막으로 가중치 합계는 v에 적용되는 가중치를 사용하여 계산됩니다.
그러나 자체 변환 시나리오에서 Q, K, V는 작업의 입력 시퀀스의 표현과 동일합니다.
위치 현행 Feedfoward는 무엇입니까?
완전히 연결된 (FC) 층이라고도하는 피드 포워드 레이어입니다. 그러나 변압기에서는 모든 입력 및 출력이
층은 벡터의 시퀀스입니다 : [sequence_length, d_model]. 우리는 일반적으로 입력 벡터에 FC를 수행합니다. 그래서 우리는 그것을 다시합니다.
그러나 다른 시간 단계에는 자체 FC가 있습니다.
Bert의 주요 기여는 무엇입니까?
사전 훈련 작업은 이미 수년 동안 존재하지만 언어 모델을 수행하는 새로운 방법 (양방향)을 소개합니다.
다운 스트림 작업에 사용하십시오. 언어 모델의 데이터가 어디에나 있습니다. 그것은 강력한 것으로 판명되었으므로 재구성되었습니다
NLP 세계.
왜 저자는 마스킹 언어 모델의 훈련 데이터를 생성 할 때 세 가지 유형의 토큰을 사용합니까?
저자들은 미세 조정 단계에는 [마스크] 토큰이 없다고 생각합니다. 따라서 사전 훈련과 미세 조정 사이에 불일치합니다.
또한 모델이 문장의 모든 문맥 정보에 관심을 갖도록 강요합니다.
언어 이해 작업에 새로운 예술 최신 상태를 달성하기 위해 Bert 모델을 만든 이유는 무엇입니까?
큰 모델, 큰 계산 및 가장 중요한 것은 무료 텍스트 데이터를 사용하여 모델을 사전 트레인합니다.
장난감 작업은 실제 데이터에 의존하지 않고 모델이 제대로 작동 할 수 있는지 확인하는 데 사용됩니다.
모델에 숫자를 계산하고 모든 입력을 요약하도록 요청합니다. 임계 값이 사용됩니다.
요약이 임계 값보다 크거나 작 으면 모델은 1 (또는 0)으로 예측해야합니다.
내부 모델/transform_model.py에는 기차와 예측 방법이 있습니다.
먼저 Train ()을 실행하여 훈련을 시작한 다음 predict ()를 실행하여 훈련 된 모델을 사용하여 예측을 시작할 수 있습니다.
기본 하이퍼 파 램터 (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6)와 함께 모델이 꽤 크기 때문에 수렴되기 전에 많은 데이터가 필요합니다.
손실이 0.1보다 작아지기 전에 최소 10k 단계가 필요합니다. 작게 훈련하고 싶다면
데이터, 소형 하이퍼 파미터 세트 (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)를 사용할 수 있습니다.
두 가지 해결 바이너리 분류, 멀티 클래스 분류 또는 멀티 라벨 분류 문제를 사용할 수 있습니다.
훈련 중 손실을 인쇄하고 검증 중 각 에포크에 대한 F1 점수를 인쇄합니다.
변압기에서 버그 수정 [중요, 팀원을 모집하고 병합 요청이 필요합니다]
(Transformer : 초기 단계에서 사전 훈련 단계의 손실이 감소하는 이유는 있지만 손실은 여전히 그리 작지 않습니다 (예 : 손실 = 8.0).
더 많은 사전 훈련 데이터, 손실은 여전히 작지 않습니다)
지원 문장 쌍 작업 [중요한, 팀원을 모집하고 병합 요청이 필요합니다]
다음 문장 예측의 사전 훈련 작업 추가 [중요, 팀원을 모집하고 병합 요청이 필요합니다]
영어로 감정 분석 또는 텍스트 분류를위한 데이터 세트가 필요합니다 [중요, 팀원을 모집하고 병합 요청이 필요합니다].
위치 임베딩은 아직 사전 훈련과 미세 조정 사이에서 공유되지 않습니다. 여기에서 사전 훈련 단계 길이가 있기 때문에 5 월
미세 조정 단계보다 짧습니다.
특수 핸들 첫 토큰 [CLS] 입력 및 분류 [완료]
FINE_TUNING과 함께 사전 트레인 : 사전 훈련 단계에서 토큰의 부하 어휘가 필요하지만 실제 작업의 레이블이 필요합니다. [완료]
미세 조정할 때 학습 속도가 더 작아야합니다. [완료]
사전 훈련 만 있으면됩니다. Transformer 또는 다른 복잡한 딥 모델을 사용하는 동안 최고의 성능을 달성 할 수 있습니다.
일부 작업에서는 TextCNN과 같은 다른 모델을 사용하여 엄청난 양의 원시 데이터를 사용한 후 작업 별 데이터 세트에서 모델을 미세 조정하고,
항상 추가 성능을 얻는 데 도움이됩니다.
여기에 더 추가하십시오.
제안, 문제 또는 기부금을 추가하고, 나와 연락을 오신 것을 환영합니다 : [email protected]
주의를 기울이기 만하면됩니다
BERT : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련
신경 기계 번역을위한 Tensor2tensor
문장 분류를위한 컨볼 루션 신경 네트워크
CAIL2018 : 판단 예측을위한 대규모 법적 데이터 세트


