bert_language_understanding
1.0.0
Bert mencapai hasil seni baru pada lebih dari 10 tugas NLP baru -baru ini.
Ini adalah implementasi tensorflow pra-pelatihan transformer dua arah yang dalam untuk pemahaman bahasa
(Bert) dan perhatian adalah semua yang Anda butuhkan (transformator).
Pembaruan: Bagian mayoritas dari Ide -ide Utama Replikasi dari kedua makalah ini dilakukan, ada keuntungan kinerja yang jelas
Untuk pra-pelatihan model & fine-tuning dibandingkan dengan melatih model dari awal.
Kami telah melakukan percobaan untuk menggantikan jaringan backbone Bert dari transformator ke textcnn, dan hasilnya adalah itu
Pra-Pelatihan Model dengan model bahasa bertopeng menggunakan banyak data mentah dapat meningkatkan kinerja dalam jumlah yang terkenal.
Secara lebih umum, kami percaya bahwa strategi pra-kereta dan penyempurnaan adalah model independen dan pra-kereta yang independen.
Dengan itu, Anda dapat mengganti jaringan backbone sesuka Anda. dan tambahkan lebih banyak tugas pra-kereta atau tentukan beberapa tugas pra-kereta baru sebagai
Anda bisa, pra-kereta tidak akan terbatas pada model bahasa bertopeng dan atau memprediksi tugas kalimat berikutnya. Yang mengejutkan kami adalah itu,
dengan set data ukuran menengah yang mengatakan, satu juta, bahkan tanpa menggunakan data eksternal, dengan bantuan tugas pra-kereta
Seperti model bahasa bertopeng, kinerja dapat meningkatkan margin besar, dan model dapat menyatu bahkan dengan cepat. beberapa waktu
Pelatihan hanya bisa dalam beberapa zaman dalam tahap penyempurnaan.
Sementara ada open source (tensor2Tensor) dan resmi
Implementasi Transformer dan implementasi resmi Bert segera hadir, tetapi ada/mungkin sulit dibaca, tidak mudah dimengerti.
Kami tidak berniat untuk mereplikasi makalah asli sepenuhnya, tetapi untuk menerapkan ide -ide utama dan menyelesaikan masalah NLP dengan cara yang lebih baik.
Bagian mayoritas untuk bekerja di sini dilakukan oleh repositori lain tahun lalu: klasifikasi teks
Dataset ukuran tengah (Cail2018, 450k)
| Model | Textcnn (no-pretrain) | Textcnn (finetuning pretrain) | Keuntungan dari pra-train |
|---|---|---|---|
| Skor F1 setelah 1 zaman | 0,09 | 0,58 | 0.49 |
| Skor F1 setelah 5 zaman | 0.40 | 0.74 | 0.35 |
| Skor F1 setelah 7 zaman | 0.44 | 0,75 | 0.31 |
| Skor F1 setelah 35 zaman | 0,58 | 0,75 | 0.27 |
| Kehilangan pelatihan di awal | 284.0 | 84.3 | 199.7 |
| Kerugian validasi setelah 1 zaman | 13.3 | 1.9 | 11.4 |
| Kerugian validasi setelah 5 zaman | 6.7 | 1.3 | 5.4 |
| Waktu pelatihan (GPU tunggal) | 8h | 2h | 6h |
Melihat:
A. Tahap tuning fine menyelesaikan pelatihan setelah hanya menjalankan 7 zaman saat max zaman mencapai 35.
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
Skor C.F1 yang dilaporkan di sini ada di set validasi, rata -rata skor mikro dan makro F1.
D.f1 Skor setelah 35 zaman dilaporkan pada set tes.
e. Dari 450 ribu dokumen mentah, mengambil 2 juta data pelatihan untuk model bahasa bertopeng,
pre-train stage finished within 5 hours in single GPU.
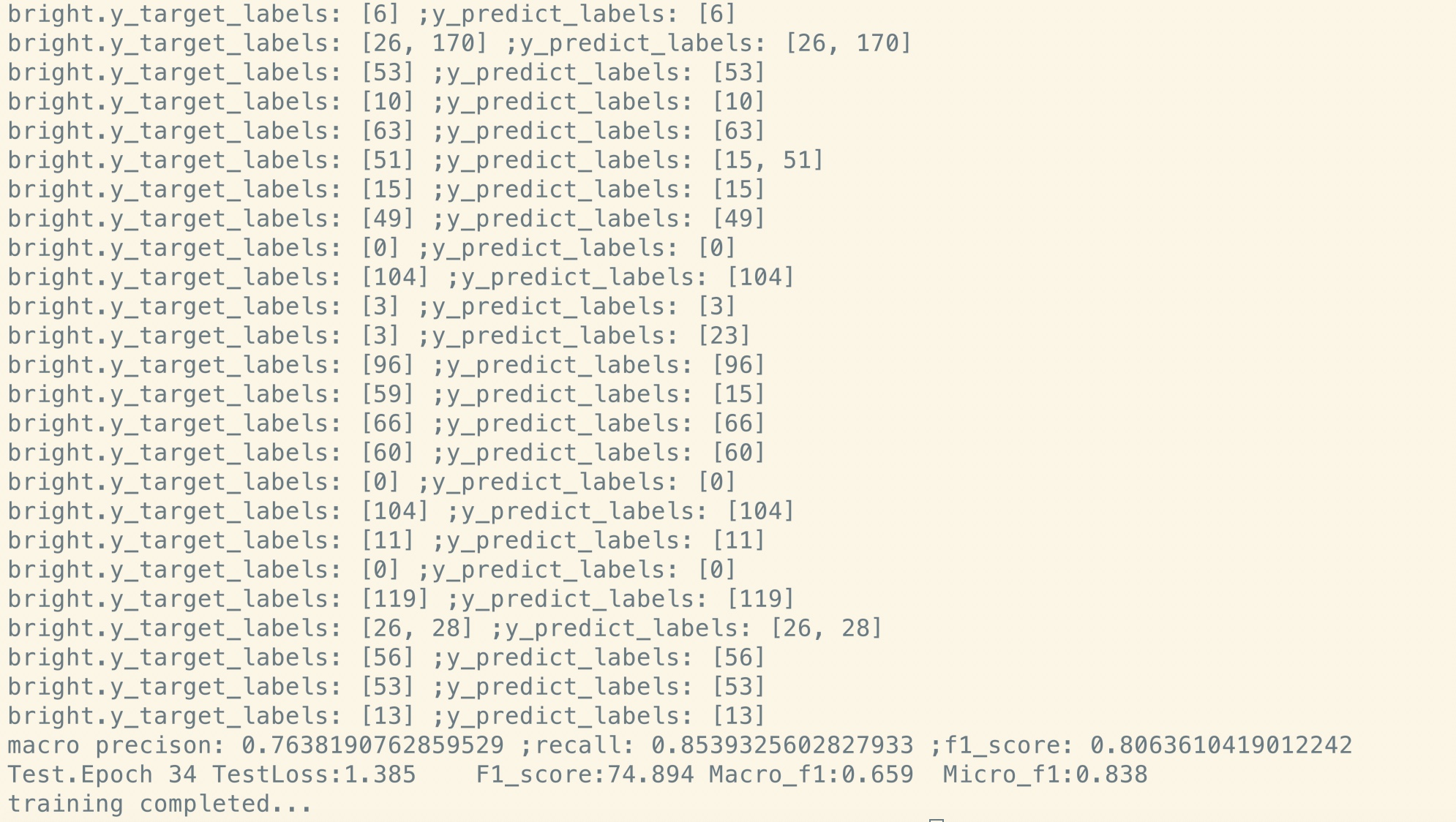
Tuning fine setelah pra-train:
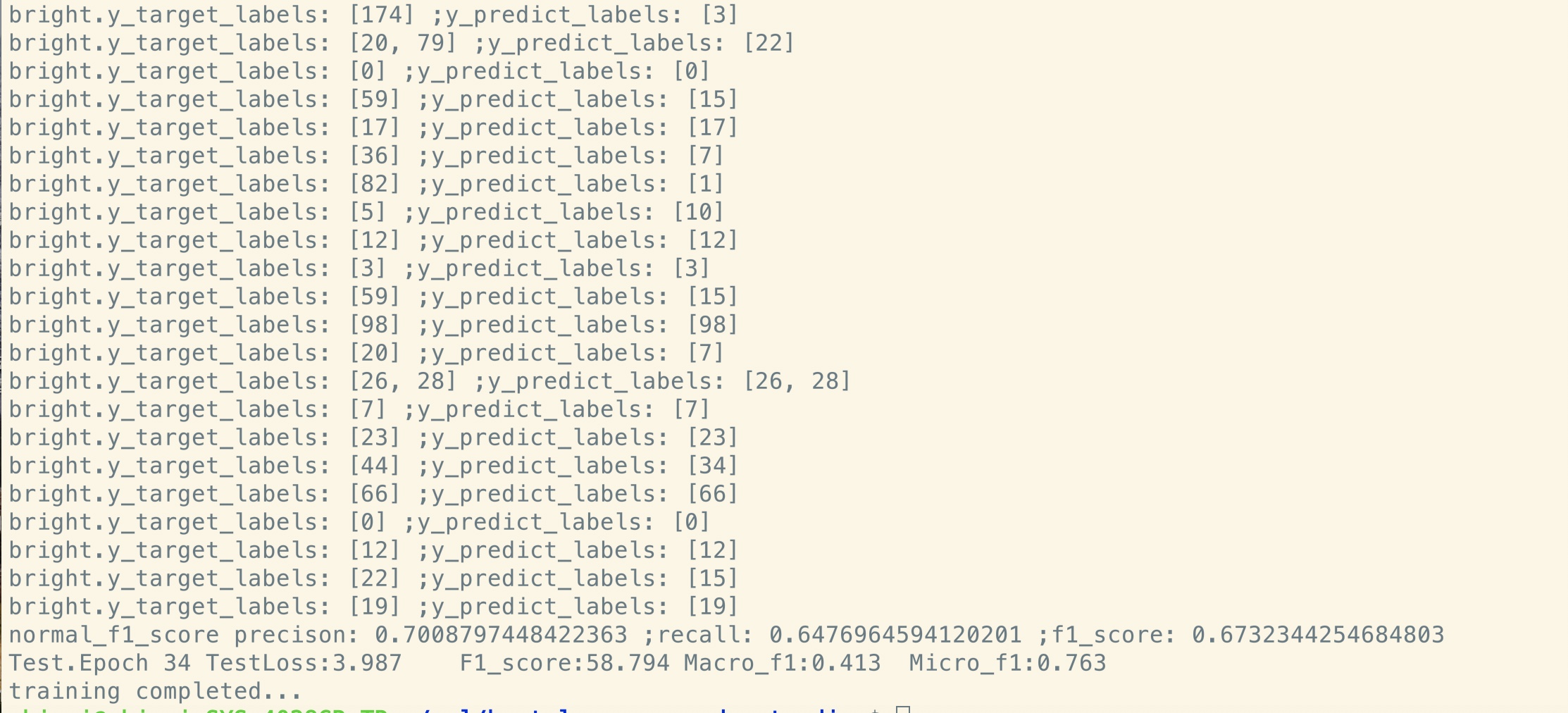
Tidak ada pra-pelatihan:
Dataset ukuran kecil (pribadi, 100k)
| Model | Textcnn (no-pretrain) | Textcnn (finetuning pretrain) | Keuntungan dari pra-train |
|---|---|---|---|
| Skor F1 setelah 1 zaman | 0.44 | 0,57 | 10%+ |
| Kerugian validasi setelah 1 zaman | 55.1 | 1.0 | 54.1 |
| Kehilangan pelatihan di awal | 68.5 | 8.2 | 60.3 |
Jika Anda ingin mencoba Bert dengan pra-kereta model bahasa bertopeng dan fine-tuning. Ambil dua langkah:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
Seperti yang Anda lihat, bahkan pada titik awal fine-tuning, tepat setelah pemulihan parameter dari model pra-terlatih, hilangnya model lebih kecil
Daripada pelatihan dari skor yang benar -benar baru, dan F1 juga lebih tinggi sementara model baru dapat dimulai dari 0.
Perhatikan: Untuk membantu Anda mencoba ide baru terlebih dahulu, Anda dapat mengatur test_mode Hyper-Paramater ke True. Ini hanya akan memuat beberapa data, dan mulai berlatih dengan cepat.
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
d_model: Dimensi model. [512]
num_layer: Jumlah lapisan. [6]
NUM_HEADER: Jumlah header perhatian diri [8]
D_K: Dimensi Key (k). Dimensi kueri (Q) adalah sama. [64]
D_V: Dimensi V. [64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
Setiap baris adalah dokumen (beberapa kalimat) atau kalimat. Itu adalah teks bebas yang bisa Anda dapatkan dengan mudah.
Periksa Data/Bert_train.txt atau Bert_train2.txt di file ZIP.
Input dan output berada di baris yang sama, setiap label mulai dengan ' label '.
Ada ruang antara string input dan label pertama, setiap label juga dipisahkan oleh ruang.
misalnya token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
Periksa Data/Bert_train.txt atau Bert_train2.txt di file ZIP.
Periksa folder 'Data' untuk data sampel. Down Load Set data ukuran tengah di sini
Dengan kelas 450k 206, masing-masing input adalah dokumen, panjang rata-rata sekitar 300, satu atau multi-label terkait dengan input.
Unduh embedding kata pra-pelatihan dari tencent ailab
Hal -hal bisa mudah:
Unduh set data (sekitar 200m, data 450K, dengan beberapa file cache), unzip dan masukkan ke dalam data/ folder,
Jalankan langkah 1 untuk pra-kereta,
dan jalankan langkah 2 untuk fine-tuning.
Saya menyelesaikan di atas tiga langkah, dan ingin memiliki kinerja yang lebih baik, bagaimana saya bisa melakukannya lebih jauh. Apakah saya perlu menemukan dataset besar?
Tidak. Anda dapat menghasilkan set data besar sendiri untuk tahap pra-kereta dengan mengunduh beberapa teks bebas, pastikan setiap baris
adalah dokumen atau kalimat kemudian ganti data/bert_train2.txt dengan file data baru Anda.
Ada apa lagi?
Coba beberapa hiper-parameter besar atau model besar (dengan mengganti jaringan backbone) Anda dapat mengamati semua data pra-pelatihan Anda.
Mainkan Model: Model/Bert_CNN_MODEL.PY, atau periksa pra-proses dengan data_util_hdf5.py.
Model bahasa tumbuk pretrain dan tugas prediksi kalimat berikutnya pada corpus skala besar,
Berdasarkan beberapa model Lapisan Lapisan Diri, kemudian fine tuning dengan menambahkan lapisan klasifikasi.
Karena Bert Model didasarkan pada Transformer, saat ini kami sedang mengerjakan tugas Add Pretrain ke model.
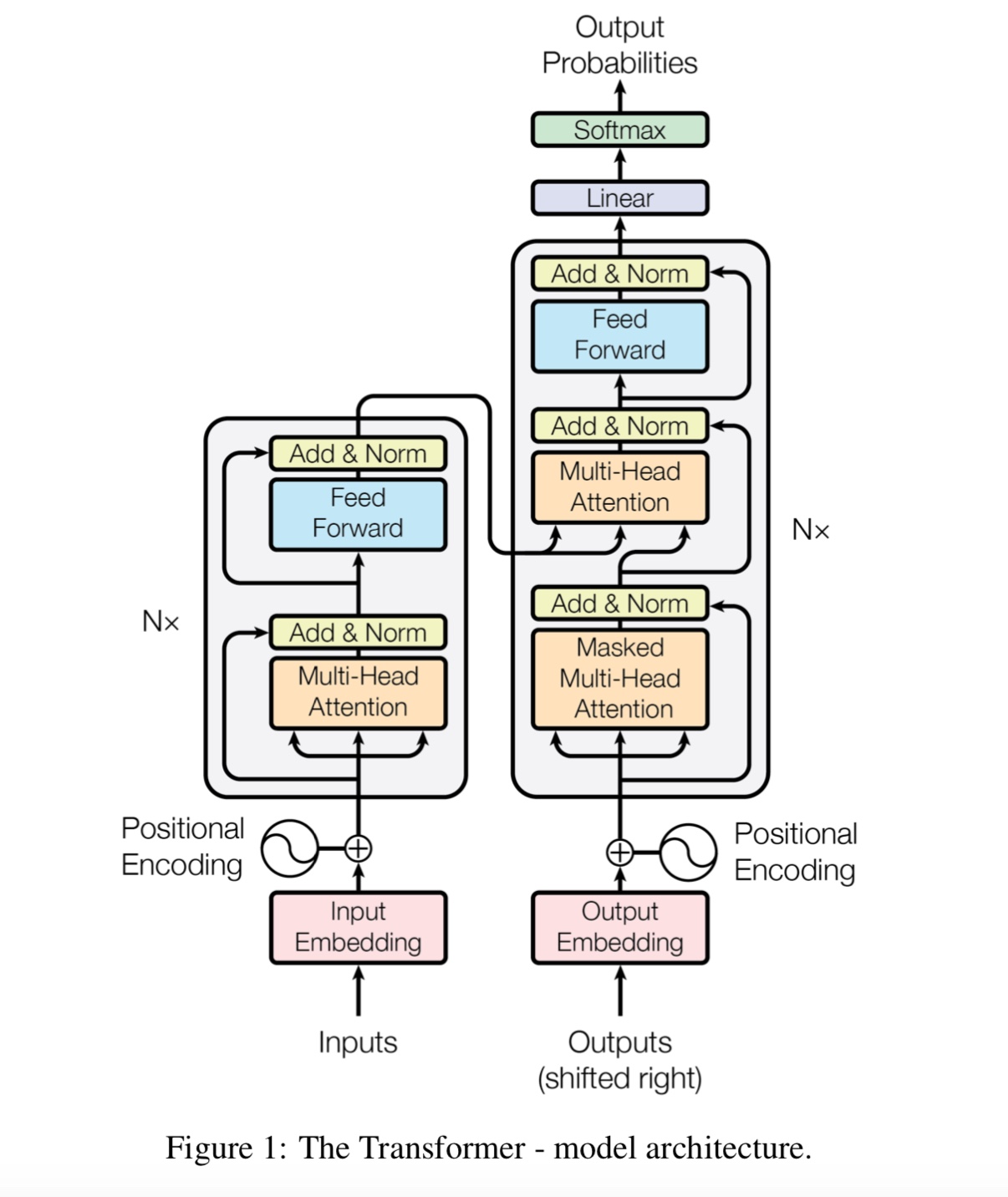
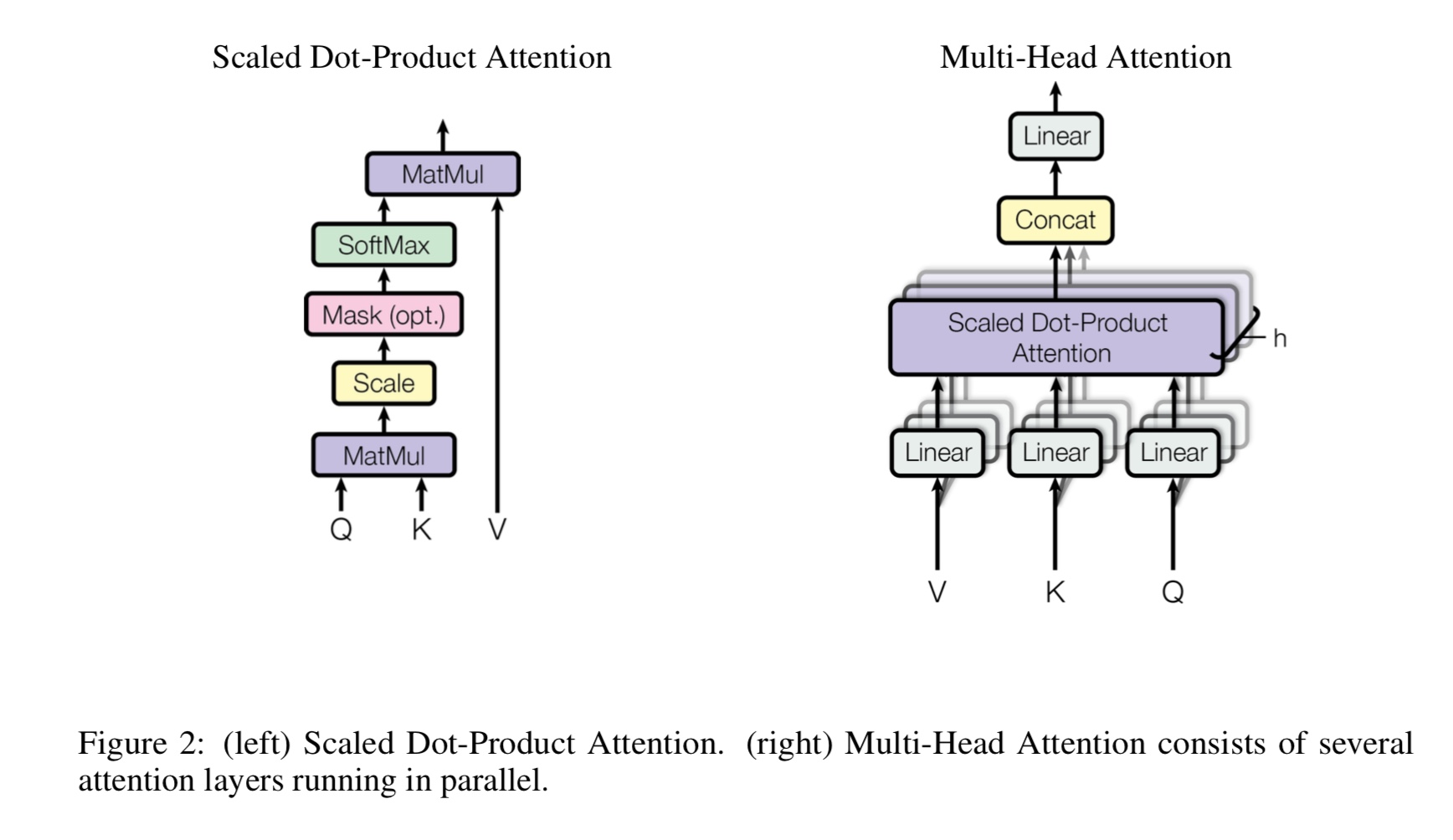
PEMBERITAHUAN: CAIL2018 sekitar 450K sebagai tautan di atas.
Ukuran pelatihan set data pribadi adalah sekitar 100 ribu, jumlah kelas adalah 9, untuk setiap input ada satu atau lebih label.
Skor F1 untuk Cail2018 dilaporkan sebagai skor F1 mikro.
Ide dasarnya sangat sederhana. Selama beberapa tahun, orang telah mendapatkan hasil yang sangat baik "pra-pelatihan" DNN sebagai model bahasa
dan kemudian menyempurnakan beberapa tugas NLP hilir (menjawab pertanyaan, inferensi bahasa alami, analisis sentimen, dll.).
Model bahasa biasanya kiri-ke-kanan, misalnya:
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
Masalahnya adalah untuk tugas hilir yang biasanya tidak Anda inginkan model bahasa, Anda menginginkan representasi kontekstual terbaik dari
setiap kata. Jika setiap kata hanya dapat melihat konteks di sebelah kirinya, jelas banyak yang hilang. Jadi salah satu trik yang telah dilakukan orang adalah juga melatih a
Model kanan-ke-kiri, misalnya:
P(store|</s>)*P(a|store </s>)*…
Sekarang Anda memiliki dua representasi dari setiap kata, satu kiri-ke-kanan dan satu kanan-ke-kiri, dan Anda dapat menyatukannya untuk tugas hilir Anda.
Tapi secara intuitif, akan jauh lebih baik jika kita bisa melatih model tunggal yang sangat dua arah.
Sayangnya tidak mungkin melatih model dua arah yang dalam seperti LM normal, karena itu akan menciptakan siklus di mana kata -kata dapat secara tidak langsung
"Lihat diri mereka sendiri," dan prediksi menjadi sepele.
Yang bisa kita lakukan sebagai gantinya adalah trik yang sangat sederhana yang digunakan dalam menghilangkan pengoder otomatis, di mana kita menutupi beberapa persen kata dari input dan
harus merekonstruksi kata -kata itu dari konteks. Kami menyebutnya "LM bertopeng" tetapi sering disebut tugas cloze.
Kami memberi makan input melalui encoder transformator yang dalam dan kemudian menggunakan keadaan tersembunyi akhir yang sesuai dengan posisi bertopeng untuk
Prediksi kata apa yang ditopang, persis seperti kami akan melatih model bahasa.
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
Bagaimana cara mendapatkan keadaan tersembunyi terakhir dari posisi bertopeng?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
Untuk detail lebih lanjut, periksa metode mask_language_model dari pretrain_task.py dan train_vert_lm.py
Banyak tugas pemahaman bahasa, seperti menjawab pertanyaan, inferensi, perlu memahami hubungan
antara kalimat. Namun, model bahasa hanya dapat memahami tanpa kalimat. kalimat berikutnya
Prediksi adalah tugas sampel untuk membantu model memahami lebih baik dalam tugas semacam ini.
50% kebetulan Kalimat kedua adalah hukuman berikutnya dari yang pertama, 50% dari bukan yang berikutnya.
Mengingat dua kalimat, model ini diminta untuk memprediksi apakah kalimat kedua adalah kalimat berikutnya
yang pertama.
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
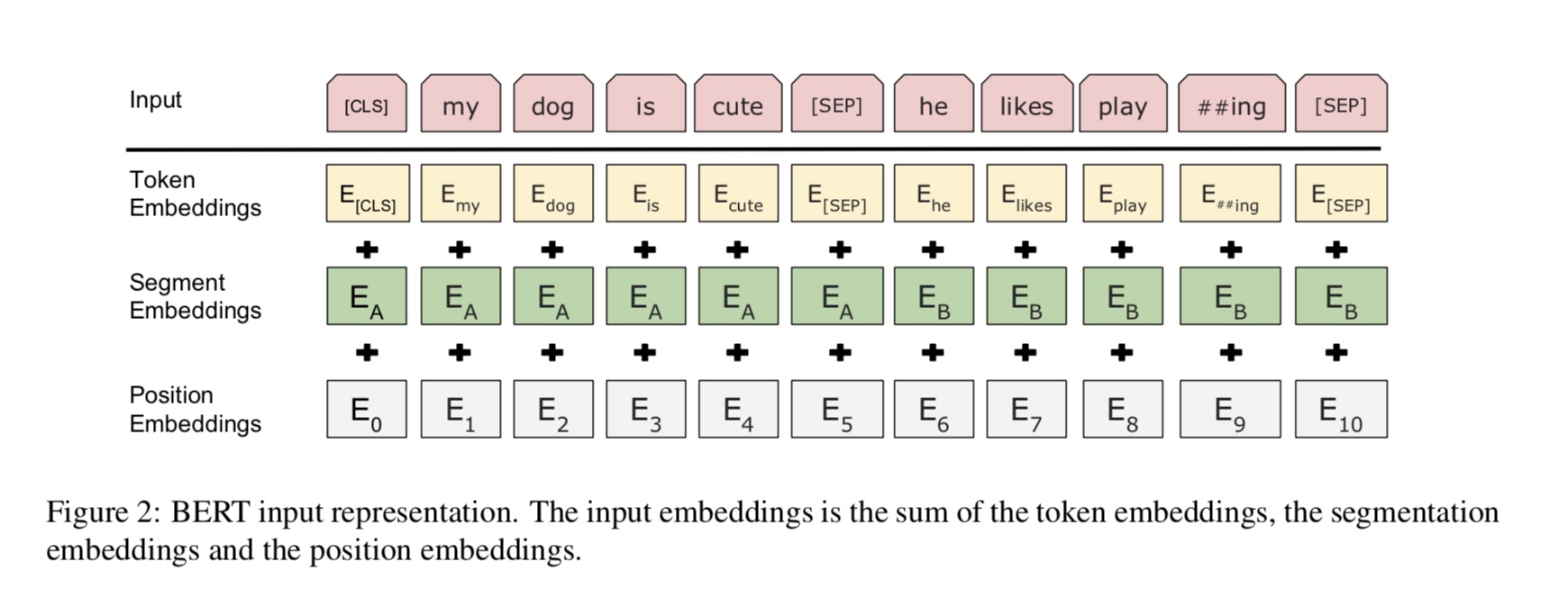
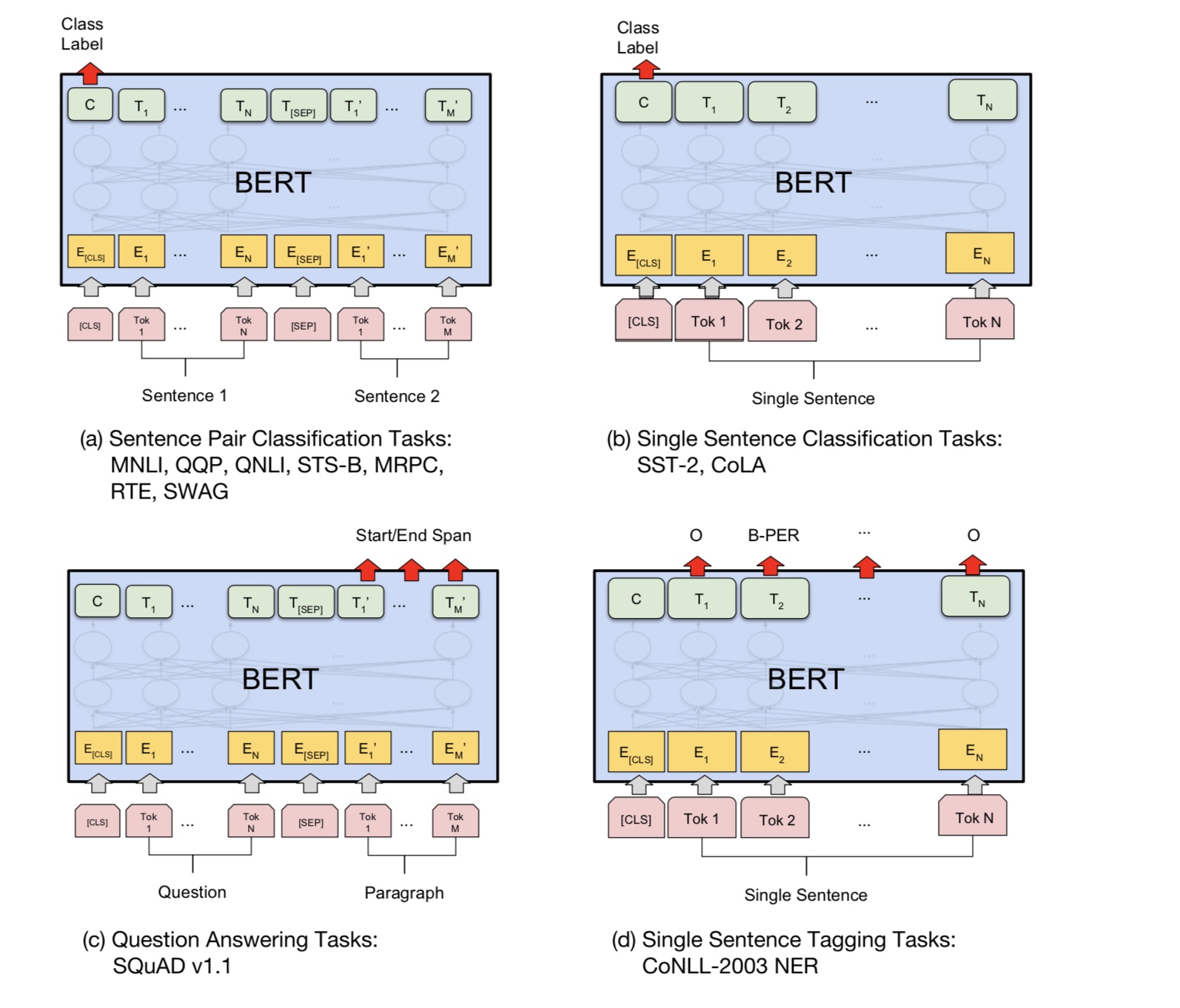
Python 3+ TensorFlow 1.10
Apa yang dibagikan dan tidak dibagikan antara tahap pra-kereta dan penyesuaian?
1). Secara dasar, semua parameter jaringan backbone yang digunakan oleh tahap pra-pelatihan dan penyempurnaan dibagikan satu sama lain.
2) .seable kami bisa untuk berbagi parameter sebanyak mungkin, sehingga selama tahap penyempurnaan kita perlu belajar sedikit
Parameter mungkin, kami juga berbagi kata embedding untuk dua tahap ini.
3). Oleh karena itu sebagian besar parameter sudah dipelajari pada awal tahap penyempurnaan.
Bagaimana kami menerapkan model bahasa bertopeng?
Untuk membuat keadaan dengan mudah, kami menghasilkan kalimat dari dokumen, membaginya menjadi kalimat. untuk setiap kalimat
Kami memotong dan memasukkannya ke panjang yang sama, dan secara acak memilih kata, lalu menggantinya dengan [topeng], diri dan acak
kata.
Bagaimana cara membuat tahap fine-tuning lebih efisien, sementara tidak merusak hasil dan pengetahuan yang kami pelajari dari tahap pra-kereta?
Kami menggunakan tingkat pembelajaran yang kecil selama penyempurnaan, sehingga penyesuaian dilakukan dalam waktu yang kecil.
Mengapa kita membutuhkan perhatian diri?
Perhatian diri Jenis jaringan baru baru-baru ini mendapatkan lebih banyak perhatian. secara tradisional kami gunakan
rnn atau cnn untuk menyelesaikan masalah. Namun RNN memiliki masalah secara paralel, dan CNN tidak pandai dalam tugas -tugas yang sensitif terhadap posisi model.
Perhatian diri dapat berjalan secara paralel, sementara mampu memodelkan ketergantungan jarak jauh.
Apa sendirinya multi-head, apa yang dimaksud dengan Q, K, V? Tambahkan sesuatu di sini.
Mulit-Heads Self-Itention adalah perhatian diri, sementara itu membagi dan memproyeksikan Q dan K menjadi beberapa subruang yang berbeda,
lalu lakukan perhatian.
Q Berdiri untuk pertanyaan, k adalah singkatan dari Keys. Untuk tugas terjemahan mesin, Q adalah keadaan tersembunyi sebelumnya dari decodes, k mewakili
keadaan tersembunyi dari encoder. Masing -masing elemen K akan menghitung skor kesamaan dengan Q. dan kemudian softmax akan digunakan
Untuk melakukan skor normalisasi, kami akan mendapatkan beban. Akhirnya jumlah tertimbang dihitung dengan menggunakan bobot berlaku untuk V.
Tetapi dalam skenario perhatian, Q, K, V semuanya sama, seperti representasi urutan input dari suatu tugas.
Apa itu FeedFoward Posisi-bijaksana?
Ini adalah lapisan umpan ke depan, juga disebut lapisan yang sepenuhnya terhubung (FC). tetapi karena dalam transformator, semua input dan output dari
Lapisan adalah urutan vektor: [sequence_length, d_model]. Kami biasanya melakukan FC ke vektor input. Jadi kami melakukannya lagi,
Tetapi langkah waktu yang berbeda memiliki FC sendiri.
Apa kontribusi utama Bert?
Sementara tugas pra-kereta sudah ada selama bertahun-tahun, itu memperkenalkan cara baru (disebut bi-directional) untuk melakukan model bahasa
dan menggunakannya untuk tugas Down Stream. karena data untuk model bahasa ada di mana -mana. itu terbukti kuat, dan karenanya membentuk kembali
Dunia NLP.
Mengapa penulis menggunakan tiga jenis token yang berbeda saat menghasilkan data pelatihan dari model bahasa bertopeng?
Para penulis percaya bahwa dalam tahap penyempurnaan tidak ada token [topeng]. Jadi tidak cocok antara pra-kereta dan penyesuaian.
Ini juga memaksa model untuk memperhatikan semua informasi konteks dalam sebuah kalimat.
Apa model Bert untuk mencapai hasil seni baru dalam tugas pemahaman bahasa?
Model besar, perhitungan besar, dan yang paling penting-algoritma baru pra-pelatihan model menggunakan data teks bebas.
Tugas mainan digunakan untuk memeriksa apakah model dapat bekerja dengan baik tanpa bergantung pada data nyata.
Ini meminta model untuk menghitung angka, dan merangkum semua input. dan ambang batas digunakan,
Jika penjumlahan lebih besar (atau kurang) dari ambang batas, maka model perlu memprediksi sebagai 1 (atau 0).
Di dalam model/transform_model.py, ada metode kereta dan prediksi.
Pertama, Anda dapat menjalankan kereta () untuk memulai pelatihan, kemudian menjalankan prediksi () untuk memulai prediksi menggunakan model terlatih.
Karena modelnya cukup besar, dengan hyperparamter default (d_model = 512, h = 8, d_v = d_k = 64, num_layer = 6), ia membutuhkan banyak data sebelum dapat menyatu.
Setidaknya 10 ribu langkah diperlukan, sebelum kerugian menjadi kurang dari 0,1. Jika Anda ingin melatihnya dengan cepat
Data, Anda dapat menggunakan set kecil hyperparmeter (d_model = 128, h = 8, d_v = d_k = 16, num_layer = 6)
Anda dapat menggunakannya dua Klasifikasi Biner, Klasifikasi Multi-Kelas atau Masalah Klasifikasi Multi-Label.
Ini akan mencetak kehilangan selama pelatihan, dan mencetak skor F1 untuk setiap zaman selama validasi.
Perbaiki bug di transformator [penting, rekrut anggota tim dan memerlukan permintaan gabungan]
(Transformer: Mengapa hilangnya tahap pra-kereta berkurang untuk tahap awal, tetapi kehilangan masih belum begitu kecil (misalnya kehilangan = 8.0)? Bahkan dengan
lebih banyak data pra-pelatihan, kerugian masih belum kecil)
Dukungan Tugas Pasangan Kalimat [Penting, Rekrut Anggota Tim dan Butuh Permintaan Gabungan]
Tambahkan tugas pra-kereta dari prediksi kalimat berikutnya [penting, rekrut anggota tim dan memerlukan permintaan gabungan]
memerlukan kumpulan data untuk analisis sentimen atau klasifikasi teks dalam bahasa Inggris [penting, merekrut anggota tim dan memerlukan permintaan gabungan]
Embedding posisi belum dibagi antara dengan pra-kereta dan fine-tuning. karena di sini pada panjang panggung pra-kereta mungkin
lebih pendek dari tahap fine-tuning.
Pegangan Khusus Token Pertama [CLS] Sebagai input dan klasifikasi [selesai]
Pra-pelatihan dengan fine_tuning: Perlu kosakata beban token dari tahap pra-kereta, tetapi label dari tugas nyata. [SELESAI]
Tingkat pembelajaran harus lebih kecil saat menyempurnakan. [Selesai]
Pra-Train adalah yang Anda butuhkan. Saat menggunakan transformator atau model Deep kompleks lainnya dapat membantu Anda mencapai kinerja terbaik
Dalam beberapa tugas, pretrain dengan model lain seperti TextCnn menggunakan data mentah dalam jumlah besar kemudian menyempurnakan model Anda pada kumpulan data spesifik tugas,
akan selalu membantu Anda mendapatkan kinerja tambahan.
Tambahkan lebih banyak di sini.
Tambahkan saran, masalah, atau ingin memberikan kontribusi, selamat datang untuk menghubungi saya: [email protected]
Perhatian adalah semua yang Anda butuhkan
Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa
Tensor2Tensor untuk terjemahan mesin saraf
Jaringan Saraf Konvolusional untuk Klasifikasi Kalimat
Cail2018: Dataset hukum skala besar untuk prediksi penilaian


