bert_language_understanding
1.0.0
Bertは、最近10を超えるNLPタスクで新しいARTの結果を達成しました。
これは、言語理解のための深い双方向変圧器の事前訓練のターンフローの実装です
(バート)と注意が必要です(トランス)。
更新:これら2つの論文の複製の主なアイデアの大部分が行われました、明らかなパフォーマンスゲインがあります
プリトレインの場合、モデルをゼロからトレーニングすることと比較してモデルと微調整を行います。
バートのバックボーンネットワークを変圧器からtextcnnに置き換える実験を行いましたが、その結果
多くの生データを使用してマスクされた言語モデルを使用したモデルを事前訓練すると、顕著な量でパフォーマンスを向上させることができます。
より一般的には、トレイン前および微調整戦略はモデル独立した、訓練前タスクが独立していると考えています。
そうは言っても、バックボーンネットワークを好きなように交換できます。さらにトレイン前のタスクを追加するか、いくつかの新しいトレイン前タスクを次のように定義します
あなたは、事前訓練がマスクされた言語モデルに限定されたり、次の文のタスクを予測したりすることはできません。私たちが驚いたのはそれです、
ミドルサイズのデータセットを使用して、100万人が外部データを使用しなくても、路線以前のタスクの助けを借りて
マスクされた言語モデルと同様に、パフォーマンスは大きなマージンで向上する可能性があり、モデルはさらに速く収束することができます。いつか
トレーニングは、微調整段階では数個の時代だけが必要です。
オープンソース(tensor2tensor)と公式があります
変圧器とBERTの公式実装の実装はまもなく登場しますが、読みにくい/理解しにくいかもしれません。
私たちは、元の論文を完全に複製するつもりはありませんが、主なアイデアを適用し、NLPの問題をより良い方法で解決するつもりです。
ここでの作業の大部分は、昨年別のリポジトリによって行われました:テキスト分類
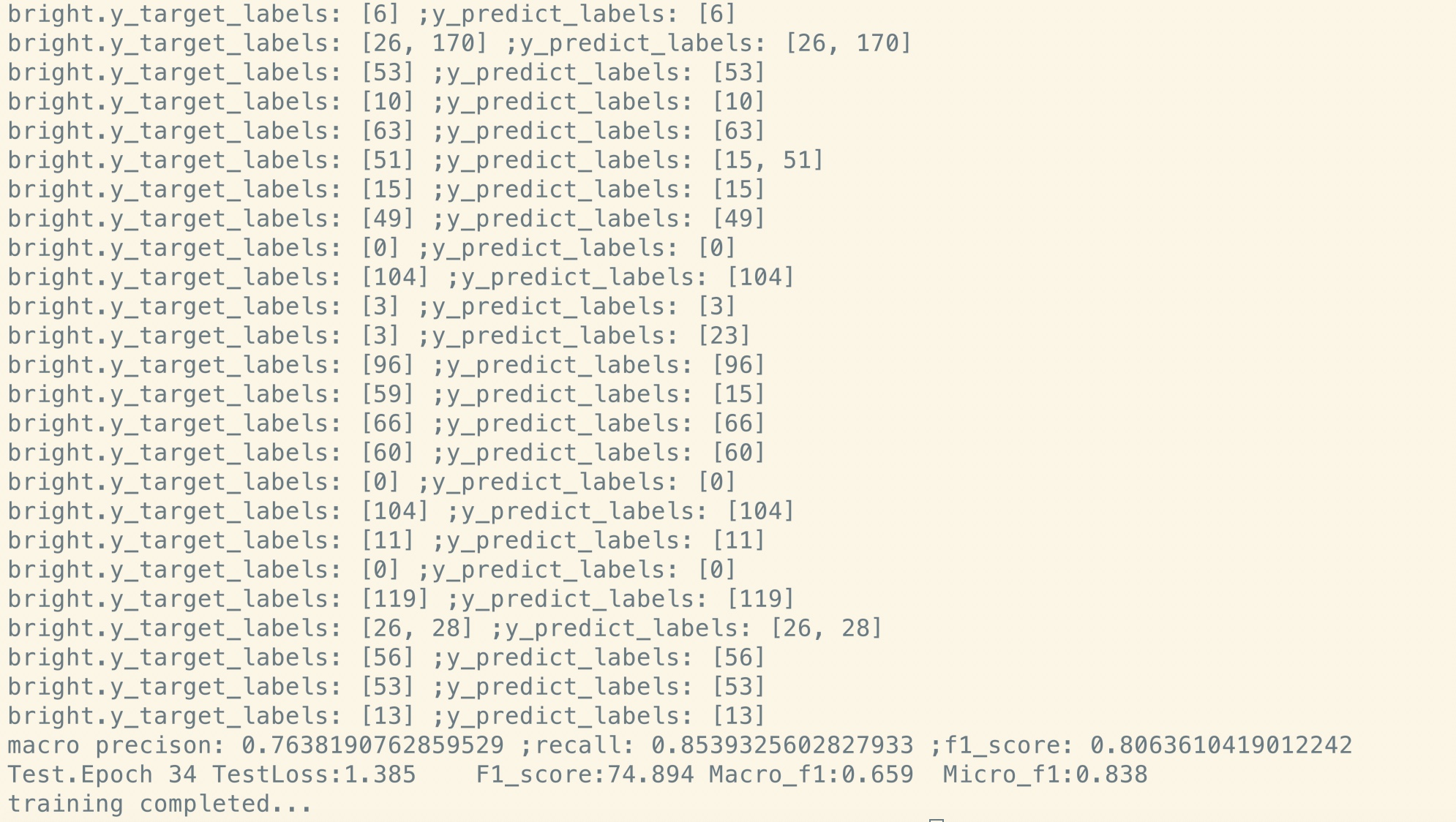
ミドルサイズデータセット(CAIL2018、450K)
| モデル | textcnn(no-pretrain) | textcnn(プレレインフィネチング) | プリトレインから得る |
|---|---|---|---|
| 1エポック後のF1スコア | 0.09 | 0.58 | 0.49 |
| 5エポック後のF1スコア | 0.40 | 0.74 | 0.35 |
| 7時代後のF1スコア | 0.44 | 0.75 | 0.31 |
| 35エポック後のF1スコア | 0.58 | 0.75 | 0.27 |
| 最初のトレーニング損失 | 284.0 | 84.3 | 199.7 |
| 1エポック後の検証損失 | 13.3 | 1.9 | 11.4 |
| 5時代後の検証損失 | 6.7 | 1.3 | 5.4 |
| トレーニング時間(シングルGPU) | 8時間 | 2H | 6H |
知らせ:
A.マックスエポックが35に達したときに7エポックを実行した後、フィンチューニングステージがトレーニングを完了しました。
in fact, fine-tuning stage start training from epoch 27 where pre-train stage ended.
ここで報告されているC.F1スコアは、F1スコアの平均マイクロとマクロの検証セットにあります。
35エポック後のD.F1スコアがテストセットで報告されます。
e。 450kの生のドキュメントから、マスクされた言語モデルの200万人のトレーニングデータを取得した、
pre-train stage finished within 5 hours in single GPU.
トレイン前の微調整:
プリトレインなし:
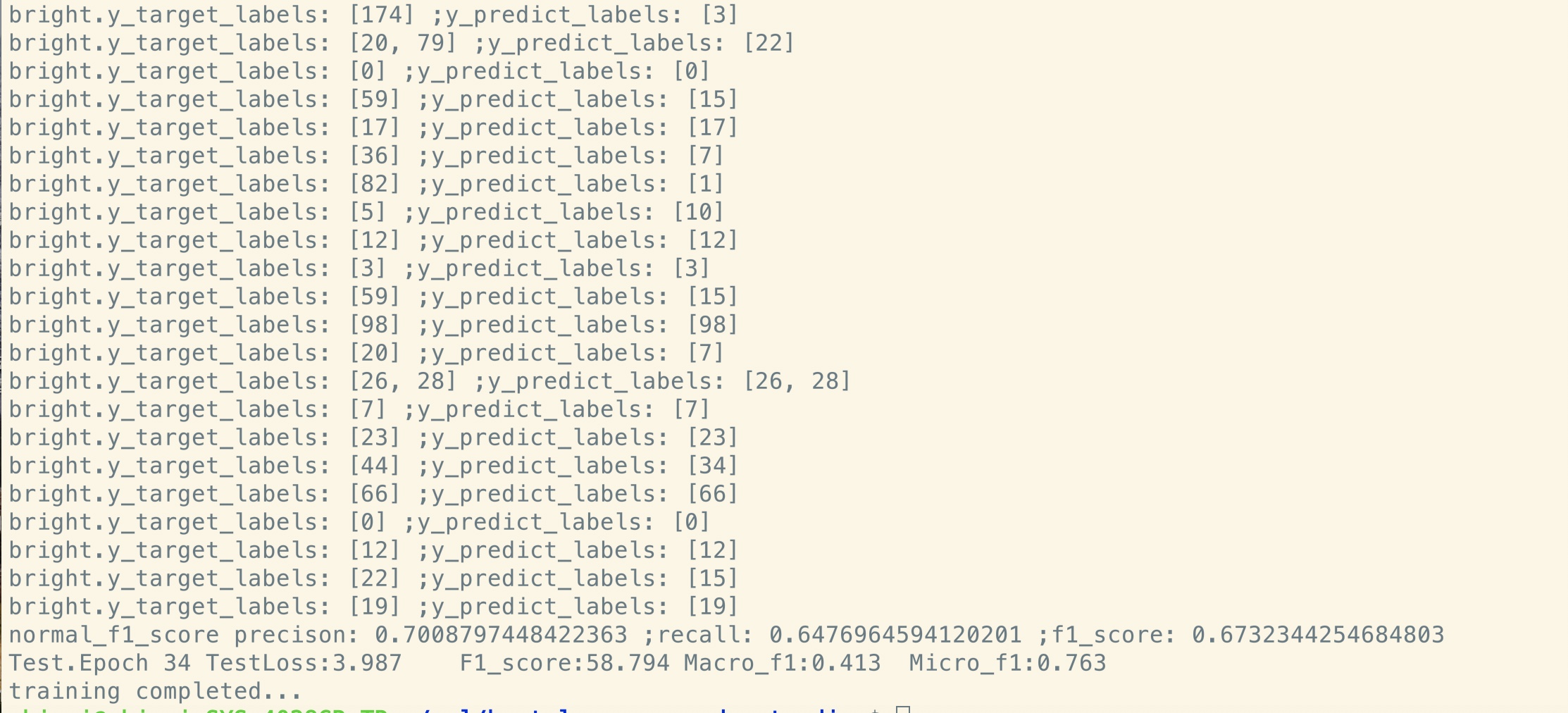
小型データセット(プライベート、100k)
| モデル | textcnn(no-pretrain) | textcnn(プレレインフィネチング) | プリトレインから得る |
|---|---|---|---|
| 1エポック後のF1スコア | 0.44 | 0.57 | 10%+ |
| 1エポック後の検証損失 | 55.1 | 1.0 | 54.1 |
| 最初のトレーニング損失 | 68.5 | 8.2 | 60.3 |
マスクされた言語モデルと微調整の事前トレインでバートを試してみたい場合。 2つのステップを踏む:
python train_bert_lm.py [DONE]
python train_bert_fine_tuning.py [Done]
ご覧のとおり、事前に訓練されたモデルからパラメーターを復元した直後に、微調整の開始点であっても、モデルの損失は小さくなります
完全に新しいスコアからのトレーニングよりも高くなりますが、新しいモデルは0から始まる可能性があります。
注意:最初に新しいアイデアを試すのを助けるために、Hyper-Paramater test_modeをtrueに設定できます。データは少ないデータだけで、迅速にトレーニングを開始します。
python train_transform.py [DONE, but a bug exist prevent it from converge, welcome you to fix, email: [email protected]]
D_Model:モデルの寸法。 [512]
num_layer:レイヤー数。 [6]
num_header:自己関節のヘッダーの数[8]
D_K:キー(k)の寸法。クエリ(q)の寸法は同じです。 [64]
D_V:Vの寸法[64]
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you have want to train the model fast, or has a small data set
or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).
各行は、文書(いくつかの文)または文です。それはあなたが簡単に得ることができるフリーテキストです。
zipファイルでデータ/bert_train.txtまたはbert_train2.txtを確認してください。
入力と出力は同じ行にあり、各ラベルは「ラベル」で開始されます。
入力文字列と最初のラベルの間にはスペースがあり、各ラベルもスペースで分割されます。
例token1 token2 token3 __label__l1 __label__l5 __label__l3
token1 token2 token3 __label__l2 __label__l4
zipファイルでデータ/bert_train.txtまたはbert_train2.txtを確認してください。
サンプルデータの「データ」フォルダーを確認してください。こちらの中間サイズのデータセットをダウンロードします
450k 206クラスの場合、各入力はドキュメントで、平均長は約300、1つまたはマルチラベルが入力に関連しています。
Tencent ailabからトレイン前のワード埋め込みをダウンロードします
物事は簡単になります:
データセット(約200m、450kのデータ、キャッシュファイルを使用して)をダウンロードし、解凍してデータ/フォルダーに入れます。
トレイン前のステップ1を実行し、
微調整のためにステップ2を実行します。
私は3つのステップを超えて終了し、パフォーマンスを向上させたいと思っています。どうすればさらに進めることができます。大きなデータセットを見つける必要がありますか?
いいえ。フリーテキストをダウンロードして、トレイン前の段階でビッグデータセットを生成できます。各行を確認してください
ドキュメントまたは文は、データ/bert_train2.txtを新しいデータファイルに置き換えます。
それ以上は何ですか?
ビッグハイパーパラメーターまたはビッグモデル(バックボーンネットワークを置き換えて)UTILを試してください。すべてのトレイン前のデータを観察できます。
モデルを使用して再生します:Model/BERT_CNN_MODEL.py、またはdata_util_hdf5.pyでpre-processをチェックします。
プレレインマッシュ言語モデルと大規模なコーパスでの次の文予測タスク、
複数層の自己判断モデルに基づいて、分類レイヤーを追加して微調整します。
Bertモデルは変圧器に基づいているため、現在、モデルへの前の追加タスクに取り組んでいます。
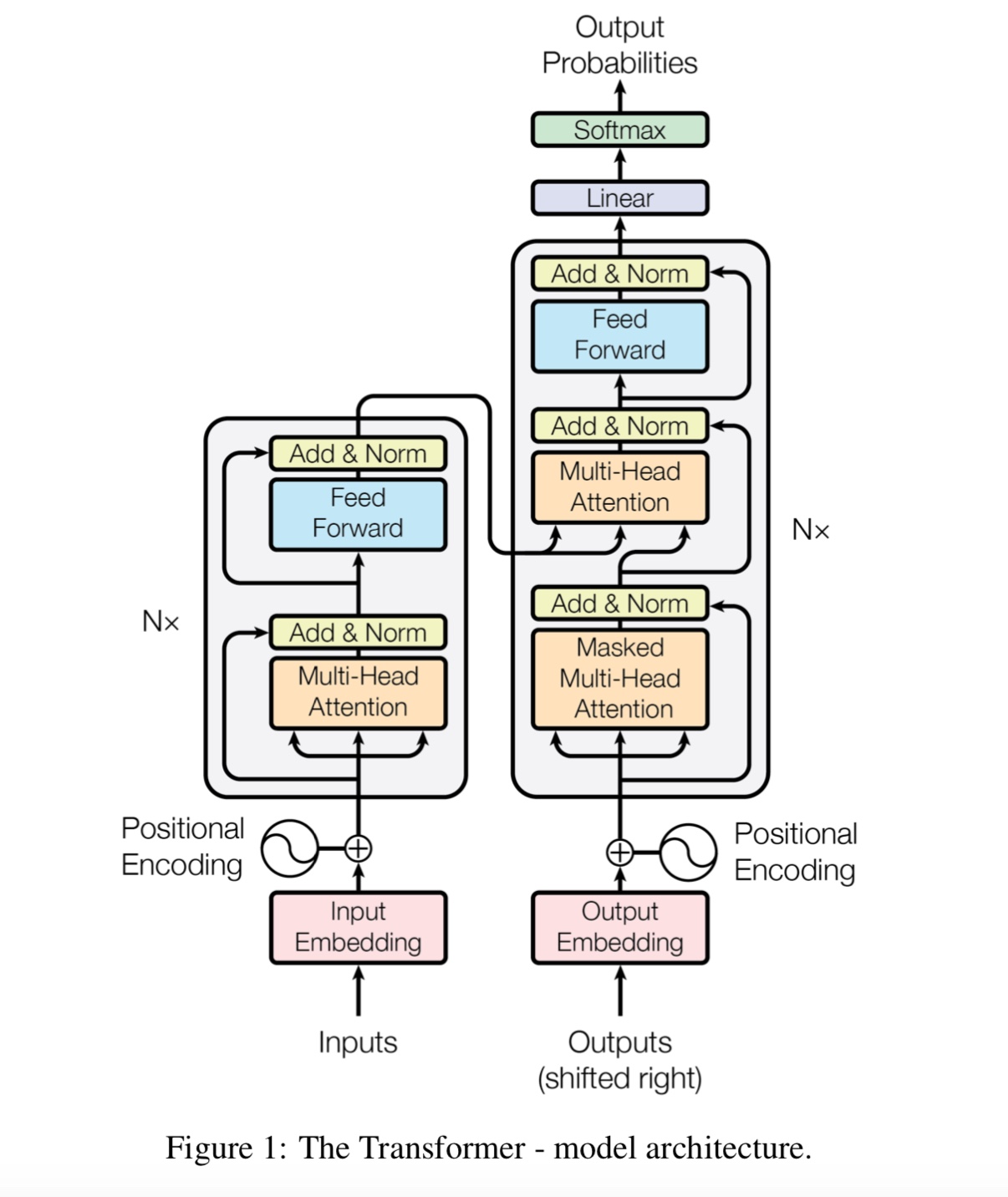
注意:上記のリンクのように、CAIL2018は約450kです。
プライベートデータセットのトレーニングサイズは約100k、クラスの数は9です。入力ごとに1つ以上のラベルが存在します。
CAIL2018のF1スコアは、マイクロF1スコアとして報告されています。
基本的なアイデアは非常に簡単です。数年間、人々は言語モデルとしてDNNSを「事前トレーニング」している非常に良い結果を得ています
そして、いくつかの下流のNLPタスク(質問の回答、自然言語の推論、感情分析など)で微調整。
言語モデルは通常、左から右側です。
"the man went to a store"
P(the | <s>)*P(man|<s> the)*P(went|<s> the man)*…
問題は、下流タスクの場合、通常は言語モデルを望んでいない場合、可能な限り最高のコンテキスト表現が必要であることです。
各単語。各単語が左のコンテキストのみを見ることができる場合、明らかに多くが欠落しています。だから人々がしたトリックの1つは、
右から左のモデル、例:
P(store|</s>)*P(a|store </s>)*…
これで、各単語の2つの表現があり、1つは左から右に右に右に右になり、下流タスクのためにそれらを連結することができます。
しかし、直感的には、双方向である単一のモデルをトレーニングできれば、はるかに優れています。
残念ながら、通常のLMのような深い双方向モデルを訓練することは不可能です。なぜなら、それは単語が間接的に可能なサイクルを作成するからです
「自分自身を見てください」と予測は些細なものになります。
代わりに私たちにできることは、自動エンコーダーの脱色に使用される非常にシンプルなトリックです。ここでは、入力からの単語のいくつかのパーセントをマスクし、
これらの単語を文脈から再構築する必要があります。これを「マスクされたLM」と呼びますが、しばしばクローズタスクと呼ばれます。
ディープトランスエンコーダーを介して入力をフィードし、マスクされた位置に対応する最終的な非表示状態を使用します
言語モデルをトレーニングするのとまったく同じように、どの単語がマスクされたかを予測します。
source_file each line is a sequence of token, can be a sentence.
Input Sequence : The man went to [MASK] store with [MASK] dog
Target Sequence : the his
マスクされた位置の最後の隠された状態を取得するにはどうすればよいですか?
1) we keep a batch of position index,
2) one hot it, multiply with represenation of sequences,
3) everywhere is 0 for the second dimension(sequence_length), only one place is 1,
4) thus we can sum up without loss any information.
詳細については、mask_language_modelの方法をpretrain_task.pyとtrain_vert_lm.のメソッドを確認してください
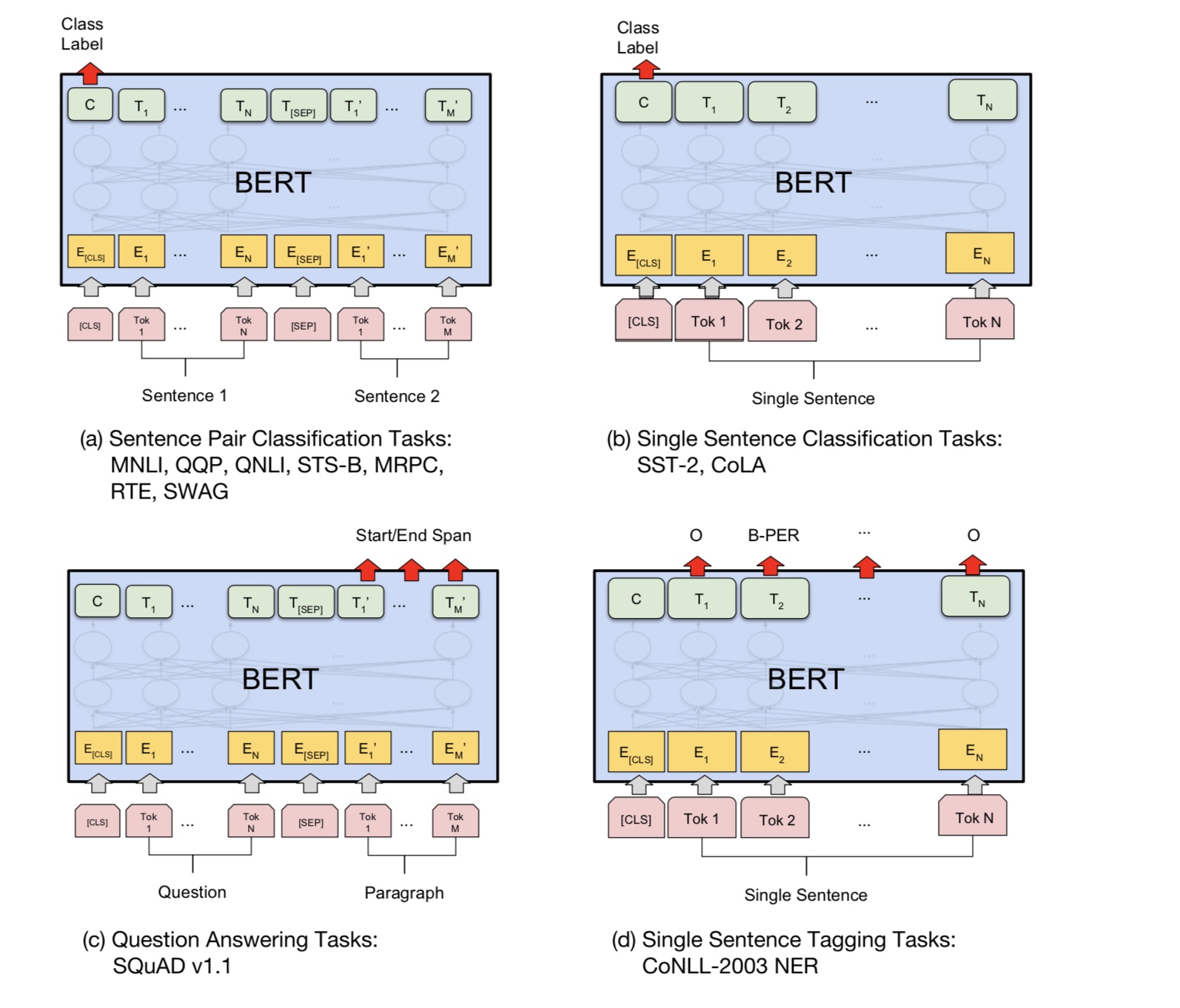
質問の回答、推論、関係のような多くの言語理解タスクは、関係を理解する必要があります
文の間。ただし、言語モデルは文なしでのみ理解することができます。次の文
予測は、この種のタスクでモデルがよりよく理解できるようにするためのサンプルタスクです。
チャンスの50%2番目の文は、最初の文の次の文であり、次の文の50%です。
2文が与えられた場合、モデルは2番目の文が実際の次の文であるかどうかを予測するように求められます
最初のもの。
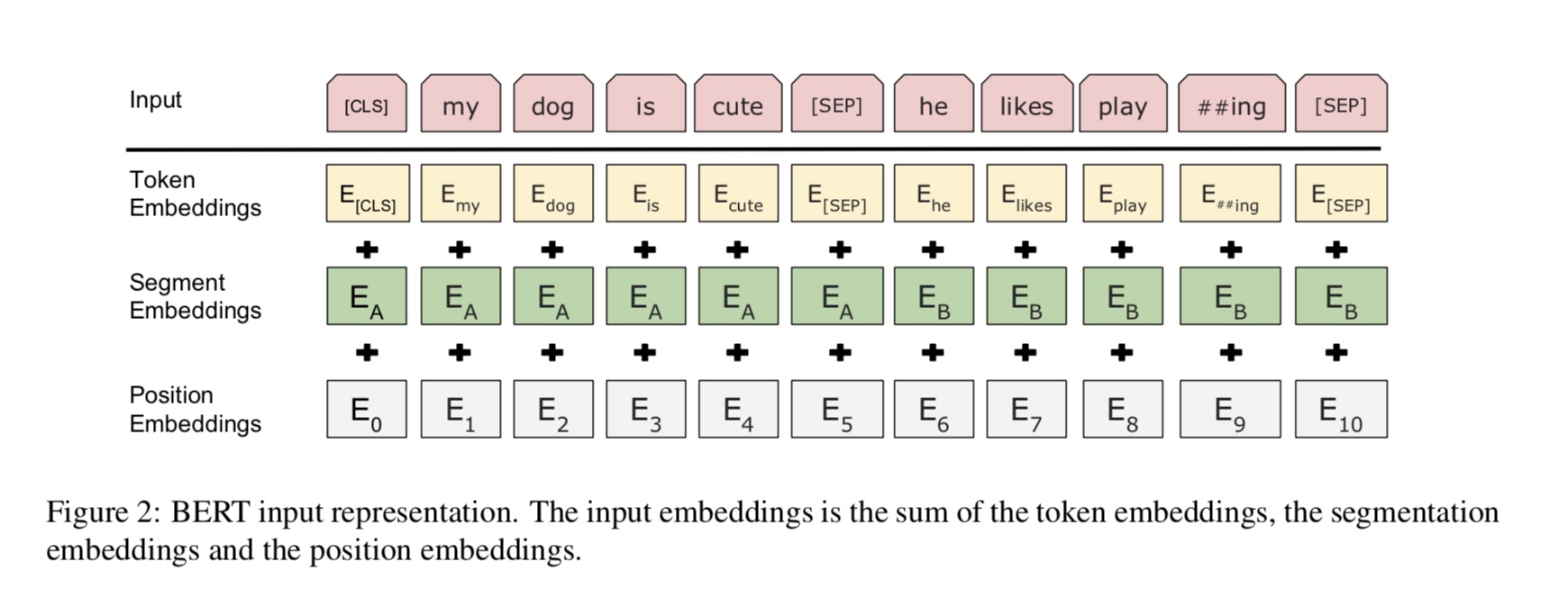
Input : [CLS] the man went to the store [SEP] he bought a gallon of milk [SEP]
Label : Is Next
Input = [CLS] the man heading to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
Python 3+ Tensorflow 1.10
トレイン前と微調整段階の間で共有しないものは何ですか?
1)根拠的には、トレイン前および微調整段階で使用されるバックボーンネットワークのすべてのパラメーターが互いに共有されます。
2)可能な限りパラメーターを共有できるので、微調整段階では少数のことを学ぶ必要があるように
可能な限りパラメーターでは、これら2つの段階の単語埋め込みも共有しました。
3)。したがって、ほとんどのパラメーターは、微調整段階の開始時にすでに学習されていました。
マスクされた言語モデルをどのように実装しますか?
物事を簡単に作成するために、文書から文を生成し、それらを文章に分割します。各文に対して
同じ長さで切り捨ててパディングし、単語をランダムに選択し、[マスク]、その自己とランダムに置き換えます
言葉。
微調整段階をより効率的にする方法は、トレイン前の段階から学んだ結果と知識を破ることはありませんか?
微調整中に少量の学習率を使用しているため、調整はわずかに行われました。
なぜ私たちは自己触たちが必要なのですか?
自己atention新しいタイプのネットワークは最近、ますます注目を集めています。伝統的に使用します
問題を解決するためのRNNまたはCNN。ただし、RNNには並行して問題があり、CNNはモデル位置に敏感なタスクでは良くありません。
自己関節は、長距離依存性をモデル化することができますが、並行して実行できます。
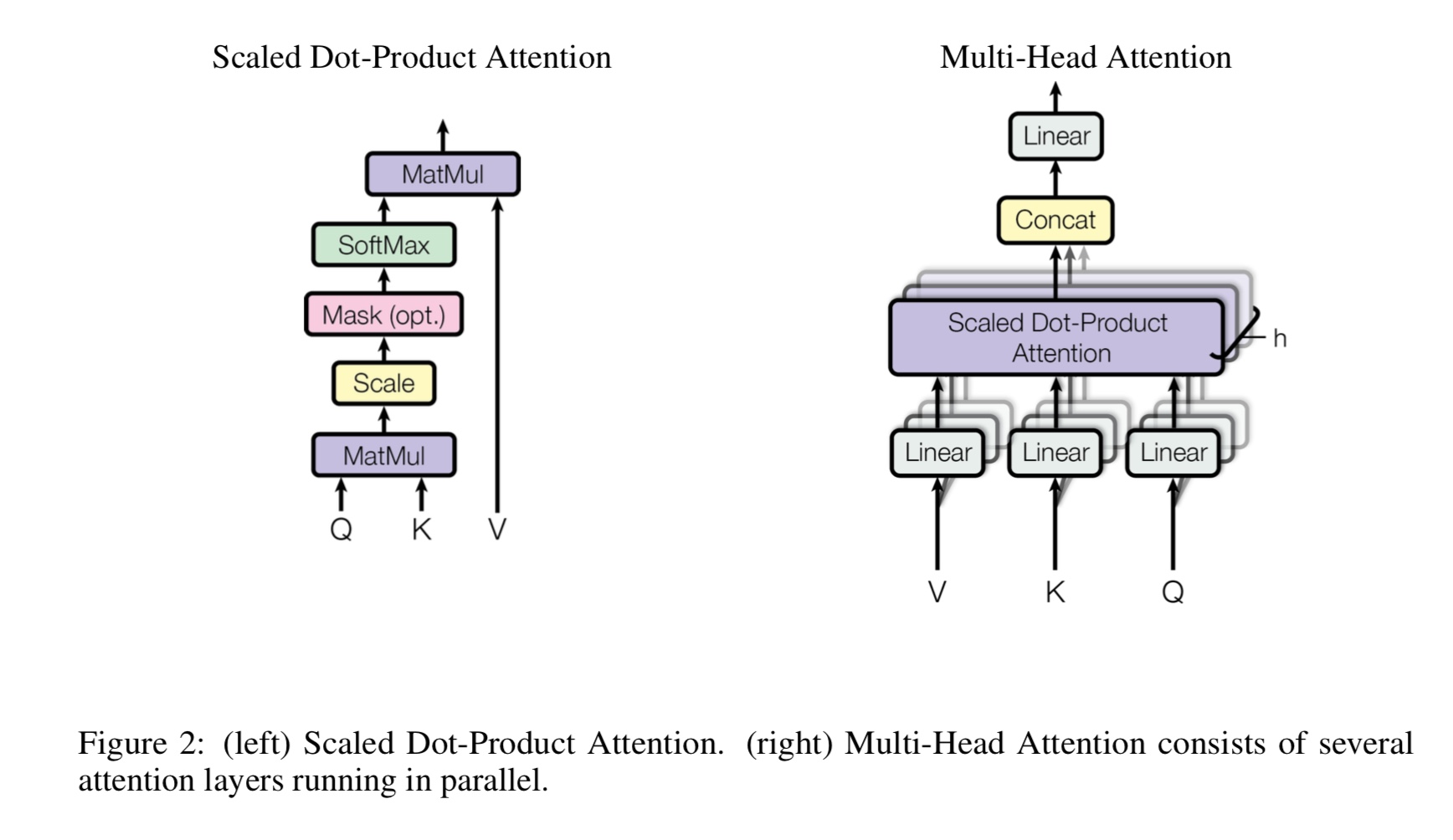
マルチヘッドの自己告発とは何ですか、Q、K、Vは何を表していますか?ここに何かを追加します。
Mulit-Headsの自己attentionは自己attentionであり、QとKをいくつかの異なるサブスペースに分割して投影します。
その後、注意をします。
Q質問の立場、kはキーを立てます。機械翻訳タスクの場合、Qは以前の隠されたデコード状態です。
エンコーダーの隠された状態。 Kの各要素は、qで類似性スコアを計算します。そして、SoftMaxが使用されます
正規スコアを行うために、ウェイトが得られます。最後に、vに適用される重みを使用して加重合計が計算されます。
しかし、自己触たちのシナリオでは、q、k、vは、タスクの入力シーケンスの表現と同じです。
位置的に飼料ファードとは何ですか?
これは、完全に接続された(FC)層とも呼ばれるフィードフォワードレイヤーです。しかし、トランスでは、すべての入力と出力が
レイヤーは、ベクトルのシーケンスです:[Sequence_length、d_model]。通常、入力のベクトルに対してFCを行います。だから私たちはもう一度それをします、
しかし、異なるタイムステップには独自のFCがあります。
バートの主な貢献は何ですか?
プリトレインタスクはすでに長年存在しますが、それは言語モデルを行うための新しい方法(いわゆる双方向)を導入しています
ダウンストリームタスクに使用します。言語モデルのデータはどこにでもあります。それは強力であることが証明されたため、変化しました
NLPワールド。
マスクされた言語モデルのトレーニングデータを生成するときに、著者が3種類のトークンを使用するのはなぜですか?
著者は、微調整段階では[マスク]トークンはないと考えています。したがって、プリトレインと微調整の間の不一致です。
また、モデルに文のすべてのコンテキスト情報に注意を払わせます。
新しい芸術状態を達成するためにBERTモデルが言語を理解することにつながるのはなぜですか?
ビッグモデル、大きな計算、そして最も重要なことは、フリーテキストデータを使用してモデルを事前トレインする新しいアルゴリズムです。
おもちゃのタスクは、実際のデータに依存せずにモデルが適切に動作できるかどうかを確認するために使用されます。
モデルに数値をカウントし、すべての入力を要約するように依頼します。しきい値が使用されます、
合計がしきい値よりも大きい(またはそれ以下)の場合、モデルは1(または0)として予測する必要があります。
内部モデル/transform_model.pyには、列車と予測方法があります。
まず、トレーニング()を実行してトレーニングを開始し、Predict()を実行してトレーニングされたモデルを使用して予測を開始できます。
モデルはかなり大きいため、デフォルトのHyperParamter(D_Model = 512、H = 8、D_V = D_K = 64、num_layer = 6)があるため、収束する前に多くのデータが必要です。
損失が0.1未満になる前に、少なくとも10kステップが必要です。あなたがそれを小さいで速く訓練したいなら
データ、hyperparmeterの小さなセット(d_model = 128、h = 8、d_v = d_k = 16、num_layer = 6)を使用できます。
2つのバイナリ分類、マルチクラス分類、またはマルチラベル分類問題を2つ使用できます。
トレーニング中に損失を印刷し、検証中に各エポックのF1スコアを印刷します。
トランスのバグを修正[重要、チームメンバーを募集し、マージリクエストが必要]
(変圧器:なぜ早い段階では路線以前の段階の損失が減少するのか、しかし、損失はそれほど小さくない(例:損失= 8.0)?
より多くのトレイン前のデータ、損失はまだ小さくありません)
サポート文のペアタスク[重要、チームメンバーを募集し、マージリクエストが必要]
次の文の予測のトレイン前タスクを追加[重要、チームメンバーを募集し、マージリクエストが必要]
感情分析または英語のテキスト分類のためのデータセットが必要です[重要、チームメンバーを募集し、マージリクエストが必要]
ポジションの埋め込みは、まだトレイン前と微調整との間で共有されていません。ここでは、トレイン前のステージの長さで5月になります
微調整段階よりも短い。
入力と分類[完了]としての特別なハンドルファーストトークン[CLS]
fine_tuningを使用したプリトレイン:トレイン前の段階からトークンのロードボキャブラリーが必要ですが、実際のタスクからのラベルが必要です。 [終わり]
微調整の場合、学習率は小さくする必要があります。 [終わり]
プレトレインが必要です。トランスや他の複雑なディープモデルを使用している間、トップパフォーマンスを実現するのに役立ちます
いくつかのタスクでは、膨大な量の生データを使用してTextCNNのような他のモデルとともに前処理し、タスク固有のデータセットでモデルを微調整します。
追加のパフォーマンスを得るのに常に役立ちます。
ここにさらに追加します。
提案、問題、または貢献をしたい、私と連絡を取りたい:[email protected]
注意が必要です
BERT:言語理解のための深い双方向変圧器の事前訓練
神経機械翻訳のTensor2テンソル
文の分類のための畳み込みニューラルネットワーク
CAIL2018:判断予測のための大規模な法的データセット


