bertviz
v1.4.0
Bertviz是一种交互式工具,可在变压器语言模型(例如BERT,GPT2或T5)中可视化注意力。它可以通过支持大多数拥抱面模型的简单Python API在Jupyter或Colab笔记本中运行。 Bertviz扩展了Llion Jones的Tensor2Tensor可视化工具,提供了多种视图,每个视图都为注意机制提供了独特的镜头。
在Twitter上获取有关此的更新和相关项目。
头视图可视化同一层中一个或多个注意力头的注意力。它基于Llion Jones的出色Tensor2Tensor可视化工具。
?在交互式COLAB教程中尝试使用头视图(所有可视化预载)。
模型视图显示了各个层和头部的鸟眼观点。
?在交互式COLAB教程中尝试模型视图(所有可视化效果预载)。

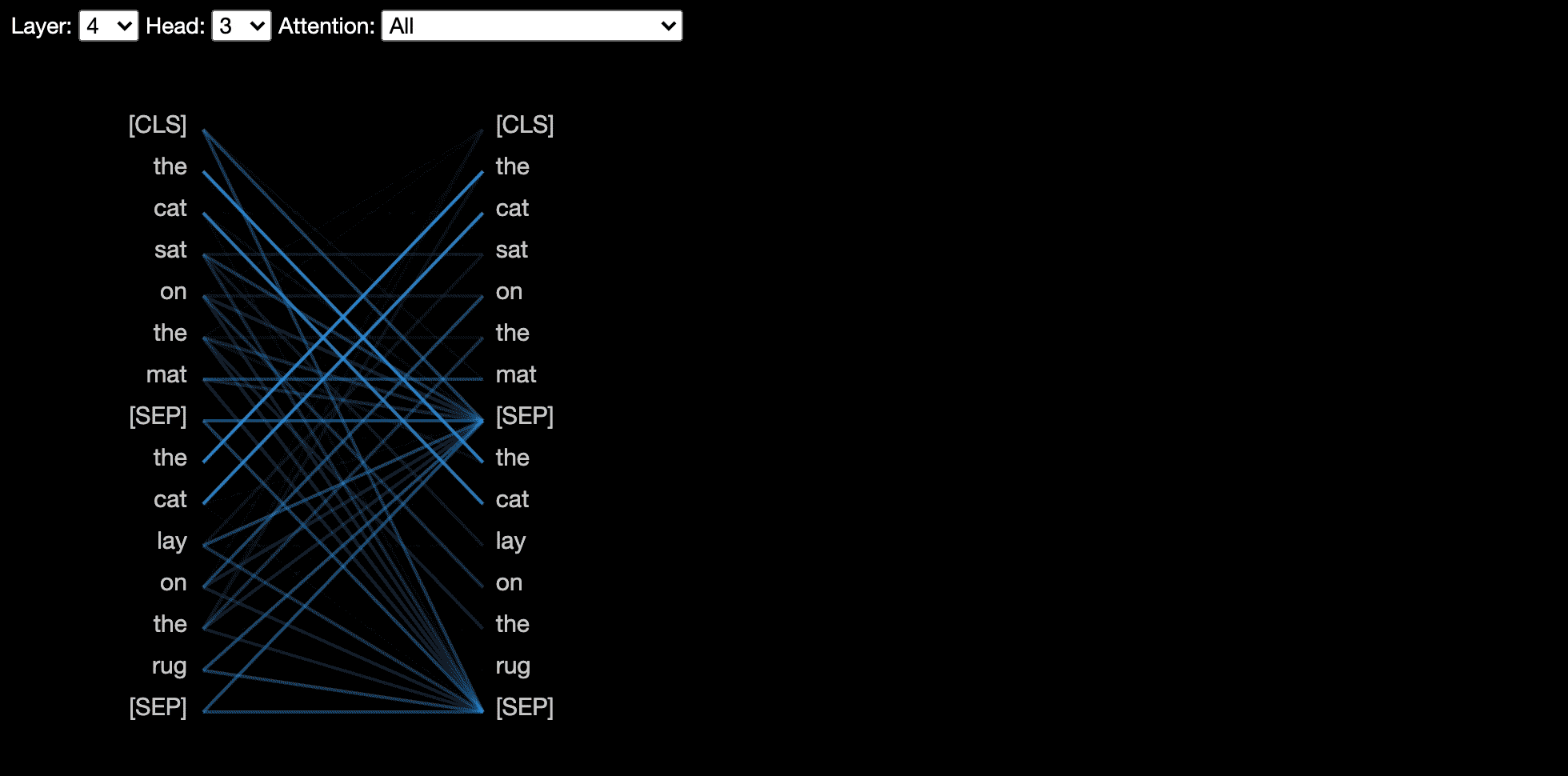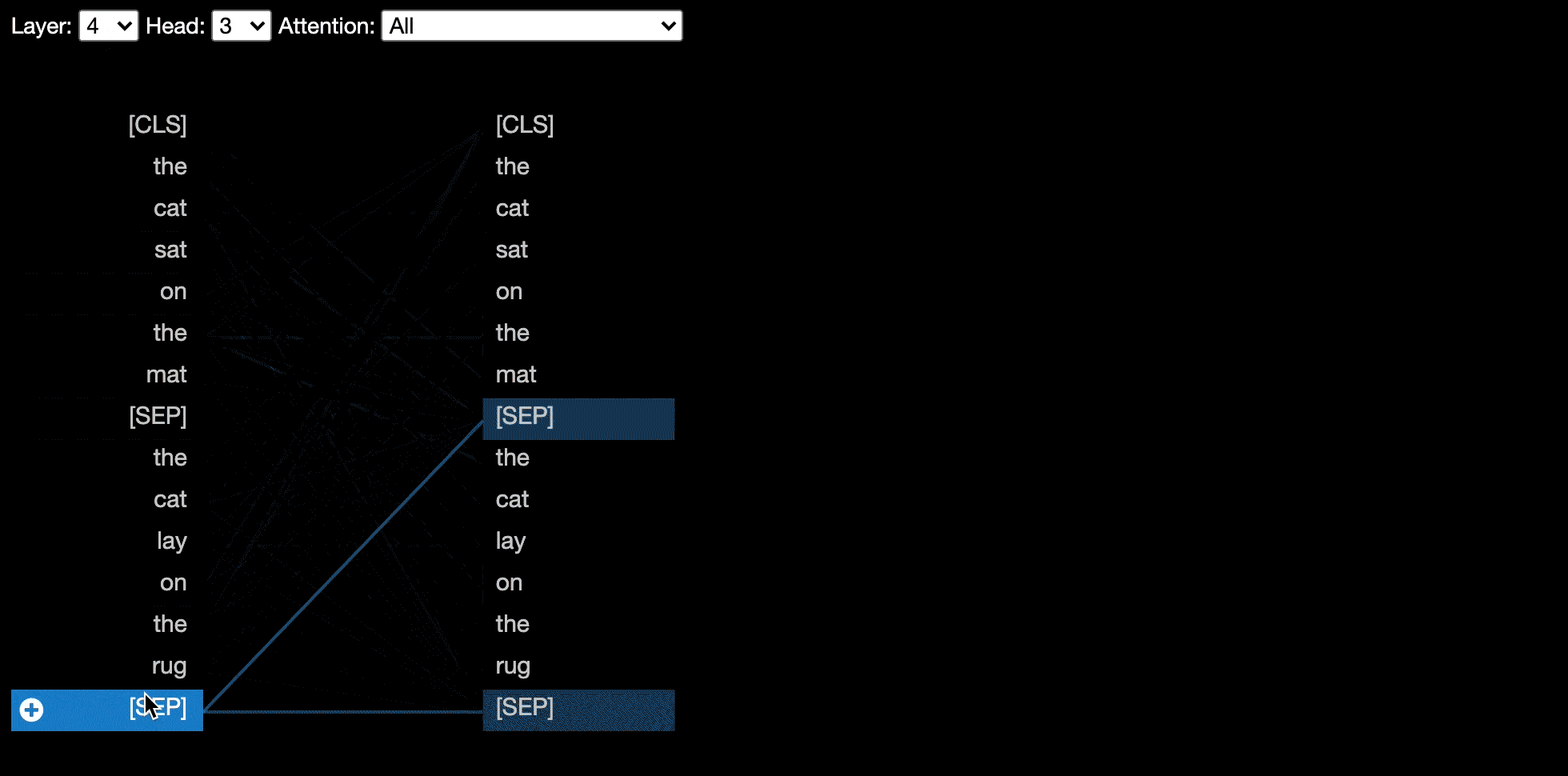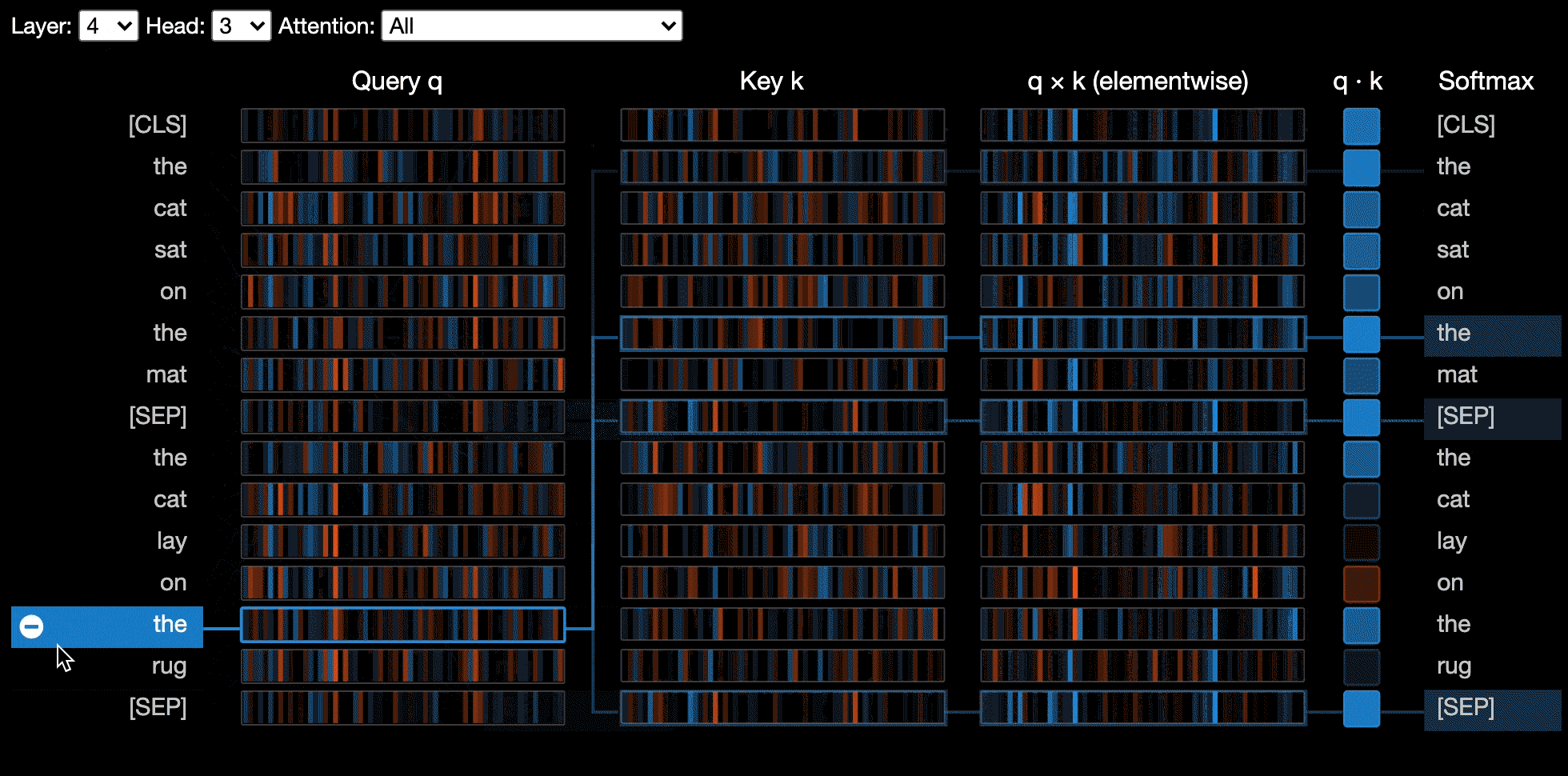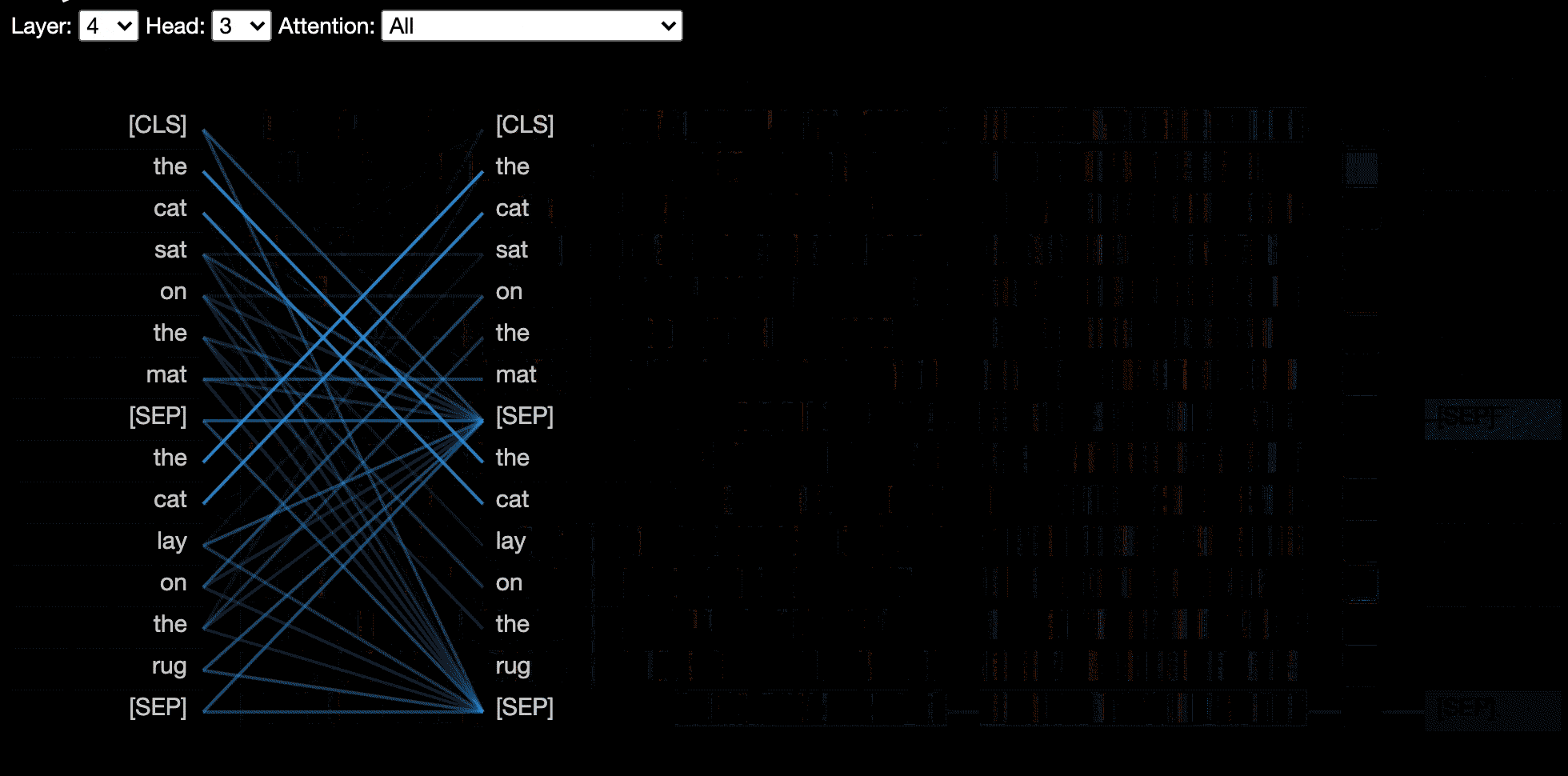
神经元视图可视化查询和关键矢量中的单个神经元,并展示了它们如何用于计算注意力。
?在交互式COLAB教程中尝试使用神经元视图(所有可视化量预载)。
从命令行:
pip install bertviz您还必须安装Jupyter笔记本和IPYWIDGETS:
pip install jupyterlab
pip install ipywidgets(如果您遇到安装jupyter或ipywidgets的任何问题,请在此处和此处咨询文档。)
要创建一个新的Jupyter笔记本电脑,只需运行:
jupyter notebook然后单击New ,然后选择Python 3 (ipykernel) ,如果提示。
要在Colab中运行,只需在Colab笔记本开始时添加以下单元格:
!pip install bertviz
运行以下代码以加载xtremedistil-l12-h384-uncased模型,并将其显示在模型视图中:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model view可视化可能需要几秒钟才能加载。可以随意尝试不同的输入文本和模型。有关其他用例和示例,例如编码器模型,请参见文档。
您还可以运行Bertviz包含的任何示例笔记本:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebook查看交互式COLAB教程,以了解有关Bertviz的更多信息并尝试该工具。注意:所有可视化均已预加载,因此无需执行任何单元格。
首先加载拥抱面模型,即如下所示的预训练模型,或者您自己的微调模型。确保设置output_attentions=True 。
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )然后准备输入并计算注意力:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) 最后,使用head_view或model_view函数显示注意力权重:
from bertviz import head_view
head_view ( attention , tokens )示例:Distilbert(型号查看笔记本,头部查看笔记本)
有关完整的API,请参阅源代码以获取头部视图或模型视图。
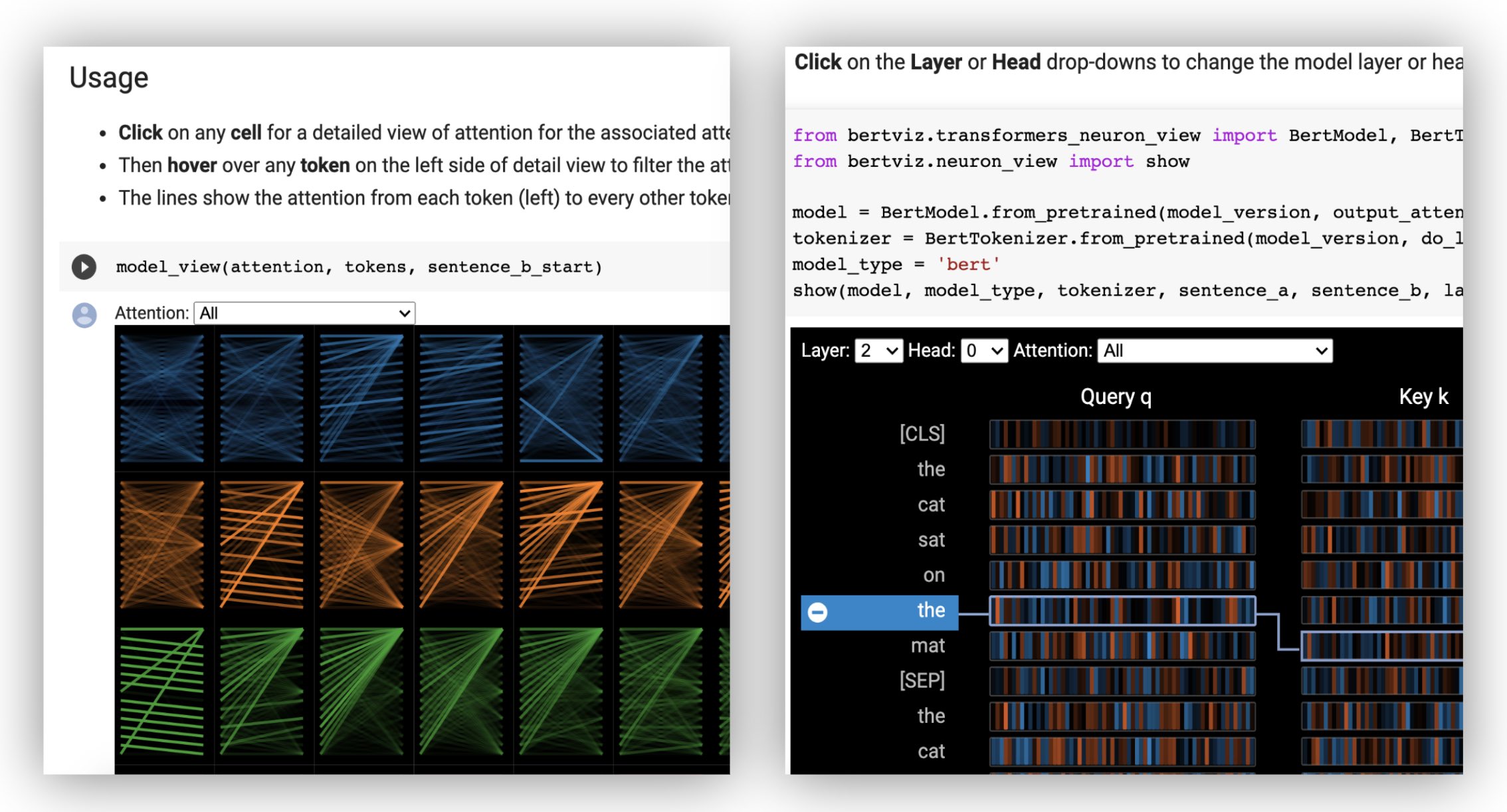
由于需要访问模型的查询/密钥向量,因此对神经元视图的调用与头部视图或模型视图的调用不同,而这些查询/密钥向量未通过HuggingFace API返回。目前,它仅限于Bertviz随附的Bert,GPT-2和Roberta的定制版本。
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )示例:Bert(笔记本,COLAB)•GPT-2(笔记本,Colab)•Roberta(笔记本)
有关完整的API,请参考来源。
头视图和模型视图两个支持编码器模型。
首先,加载编码器模型:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )然后准备输入并计算注意力:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ])最后,使用head_view或model_view显示可视化。
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
)您可以从可视化的左上角的下拉角落选择Encoder , Decoder或Cross注意。
示例:Marianmt(笔记本)•BART(笔记本)
有关完整的API,请参阅源代码以获取头部视图或模型视图。
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop模型视图和神经元视图支持黑暗(默认)和光模式。您可以使用display_mode参数设置模式:
model_view ( attention , tokens , display_mode = "light" )为了提高工具可视化较大的模型或输入时的响应能力,您可以将include_layers参数设置为限制可视化到层的子集(零索引)。此选项可在Head View和Model View中使用。
示例:仅显示图层5和6的渲染模型视图
model_view ( attention , tokens , include_layers = [ 5 , 6 ])对于模型视图,您还可以通过设置include_heads参数将可视化限制为注意头的子集(零索引)。
在头视图中,当可视化首次渲染时,您可以选择特定的layer和heads作为默认选择。注意:这与include_heads / include_layers参数(上)不同,该参数完全从可视化中删除了图层和头部。
示例:使用第2层和头部3和5预选的头部视图
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ])您也可以为神经元视图预选特定layer和单head 。
某些模型(例如Bert)接受一对句子作为输入。伯特维兹(Bertviz)可选支持下拉菜单,该菜单允许用户根据令牌所处的句子过滤注意力,例如,仅在第一个句子中的令牌和第二句中的令牌之间显示出注意力。
要启用此功能在调用head_view或model_view功能时,将sentence_b_start参数设置为第二句的开始索引。请注意,计算此索引的方法将取决于模型。
示例(伯特):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start )要在神经元视图中启用此选项,只需在neuron_view.show()中设置sentence_a和sentence_b参数即可。
支持检索生成的HTML表示形式的支持已添加到HEAD_VIEW,model_view和neuron_view中。
将“ HTML_ACTION”参数设置为“返回”将使函数调用返回一个可以进一步处理的HTML Python对象。请记住,您可以使用Python HTML对象的数据属性访问HTML源。
“ HTML_ACTION”的默认行为是“视图”,它将显示可视化,但不会返回HTML对象。
如果您需要:此功能很有用:
示例(头和模型视图):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )示例(神经元视图):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data )只要可用注意权重并遵循head_view和model_view中指定的格式(这是从huggingface模型返回的格式),就可以使用头部视图和模型视图来可视化任何标准变压器模型的自我注意力。在某些情况下,如HuggingFace文档中所述,可以将TensorFlow检查点作为拥抱面模型加载。
include_layers参数(如上所述)来过滤所显示的图层。include_layers参数(如上所述)来过滤所显示的图层。transformers_neuron_view目录),这仅针对这三个模型完成。 变压器模型中注意力的多尺度可视化(ACL系统演示2019)。
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}杰西·维格
我们感谢以下项目的作者,这些项目已纳入此存储库:
该项目已在Apache 2.0许可证下获得许可 - 有关详细信息,请参见许可证文件


