bertviz
v1.4.0
O Bertviz é uma ferramenta interativa para visualizar a atenção em modelos de linguagem de transformadores como BERT, GPT2 ou T5. Ele pode ser executado dentro de um notebook Jupyter ou Colab através de uma API Python simples que suporta a maioria dos modelos Huggingface. O Bertviz estende a ferramenta de visualização do Tensor2tensor da Llion Jones, fornecendo várias visualizações que oferecem uma lente exclusiva no mecanismo de atenção.
Obtenha atualizações para isso e projetos relacionados no Twitter.
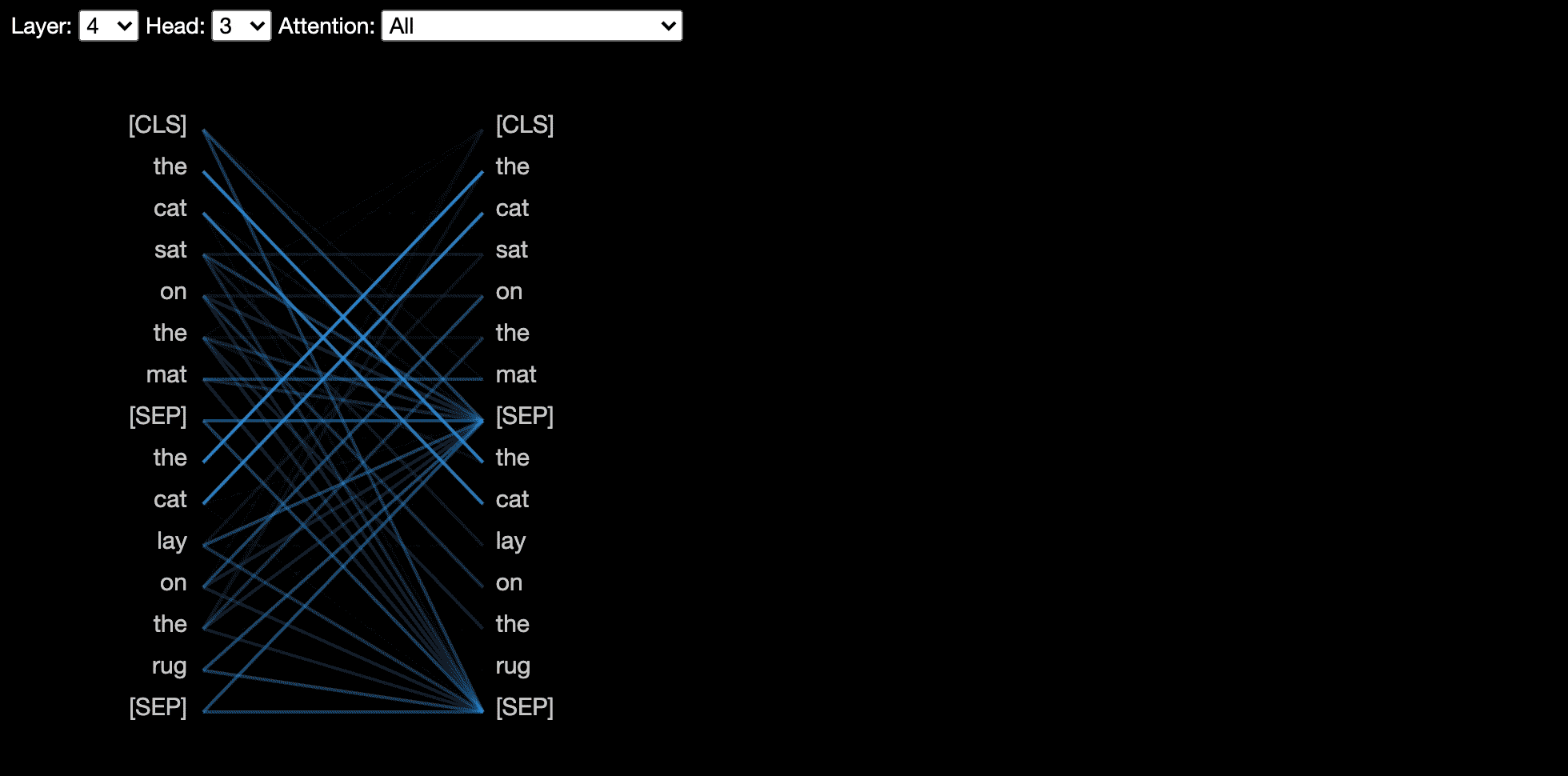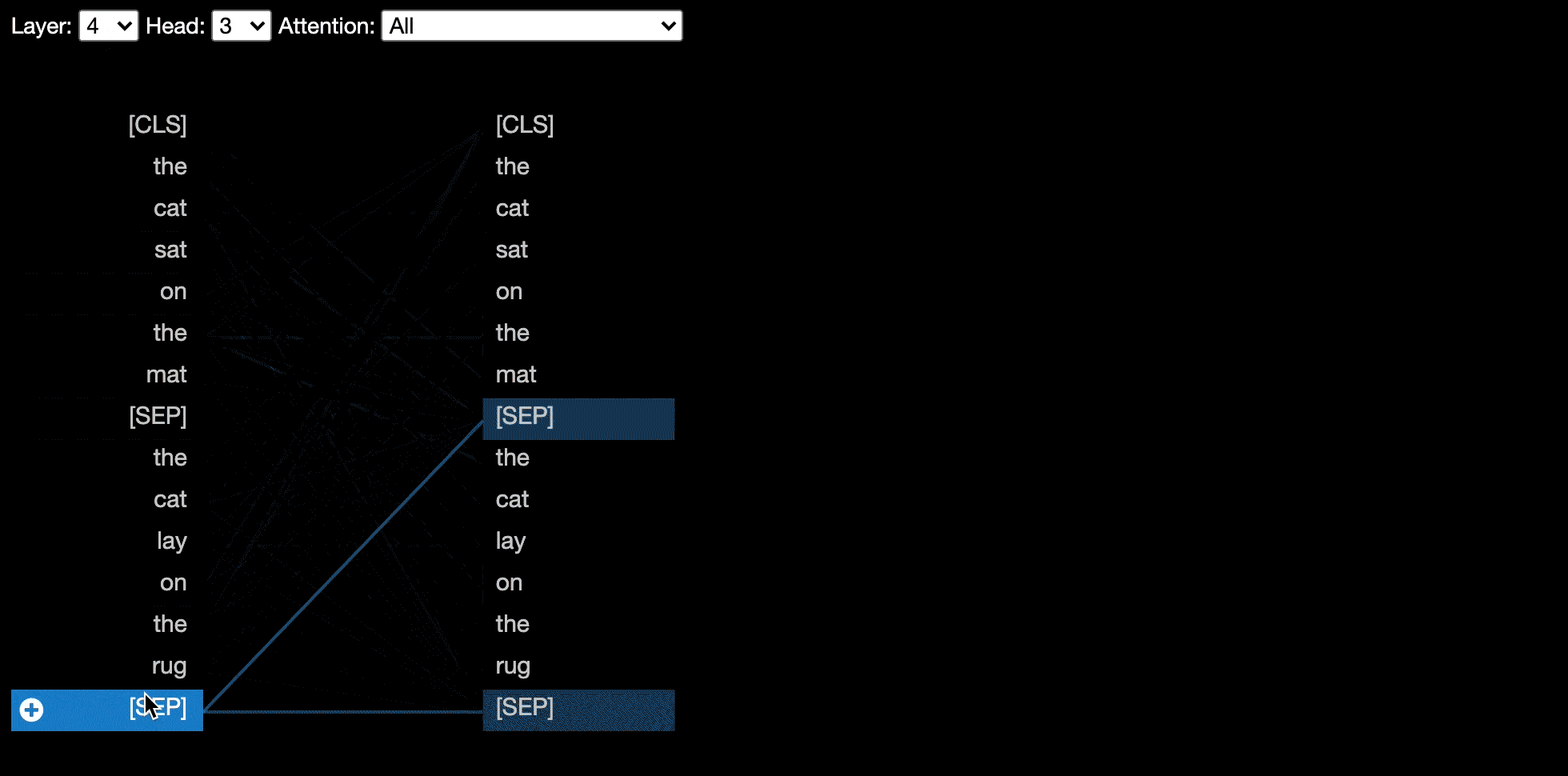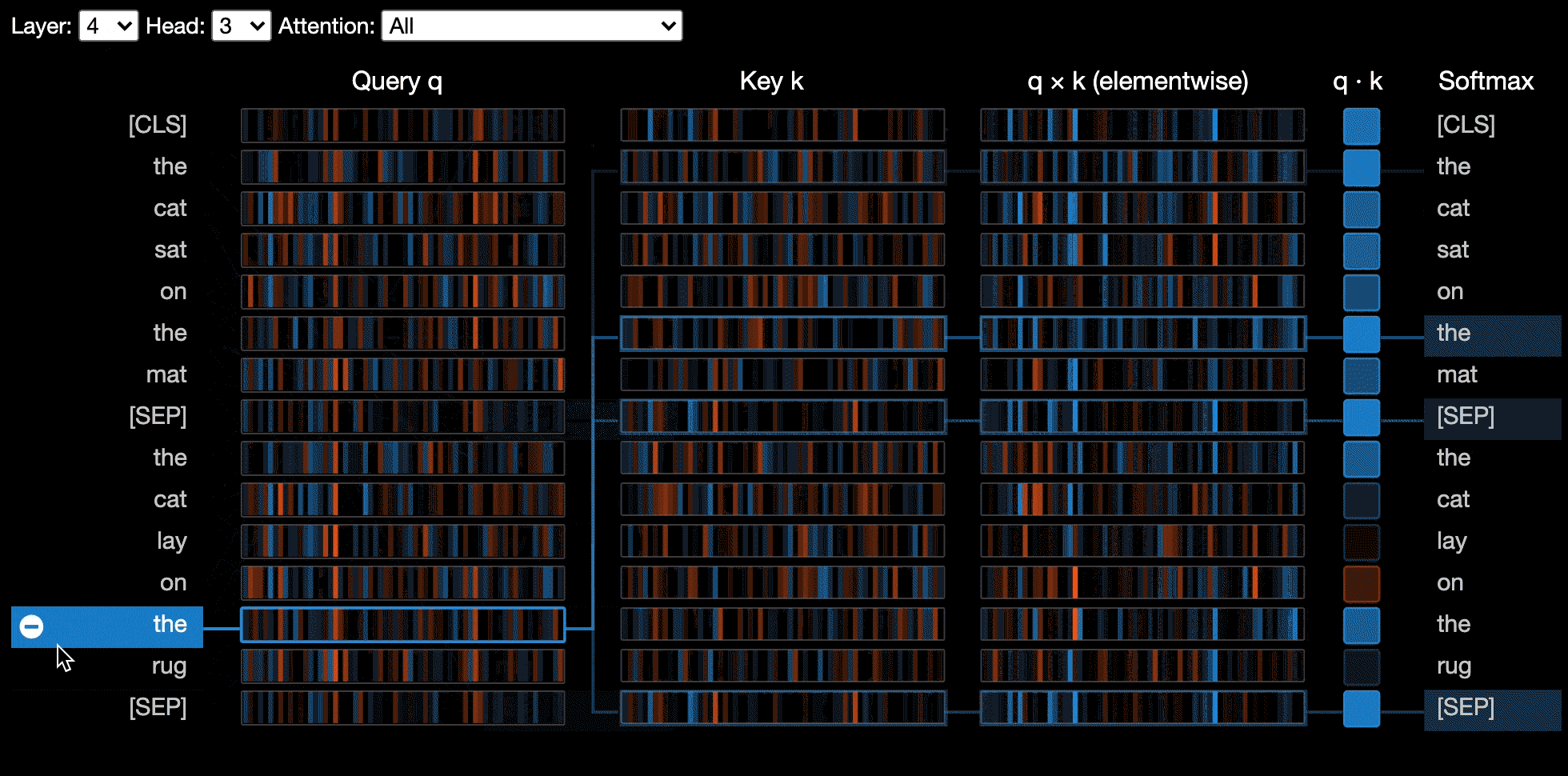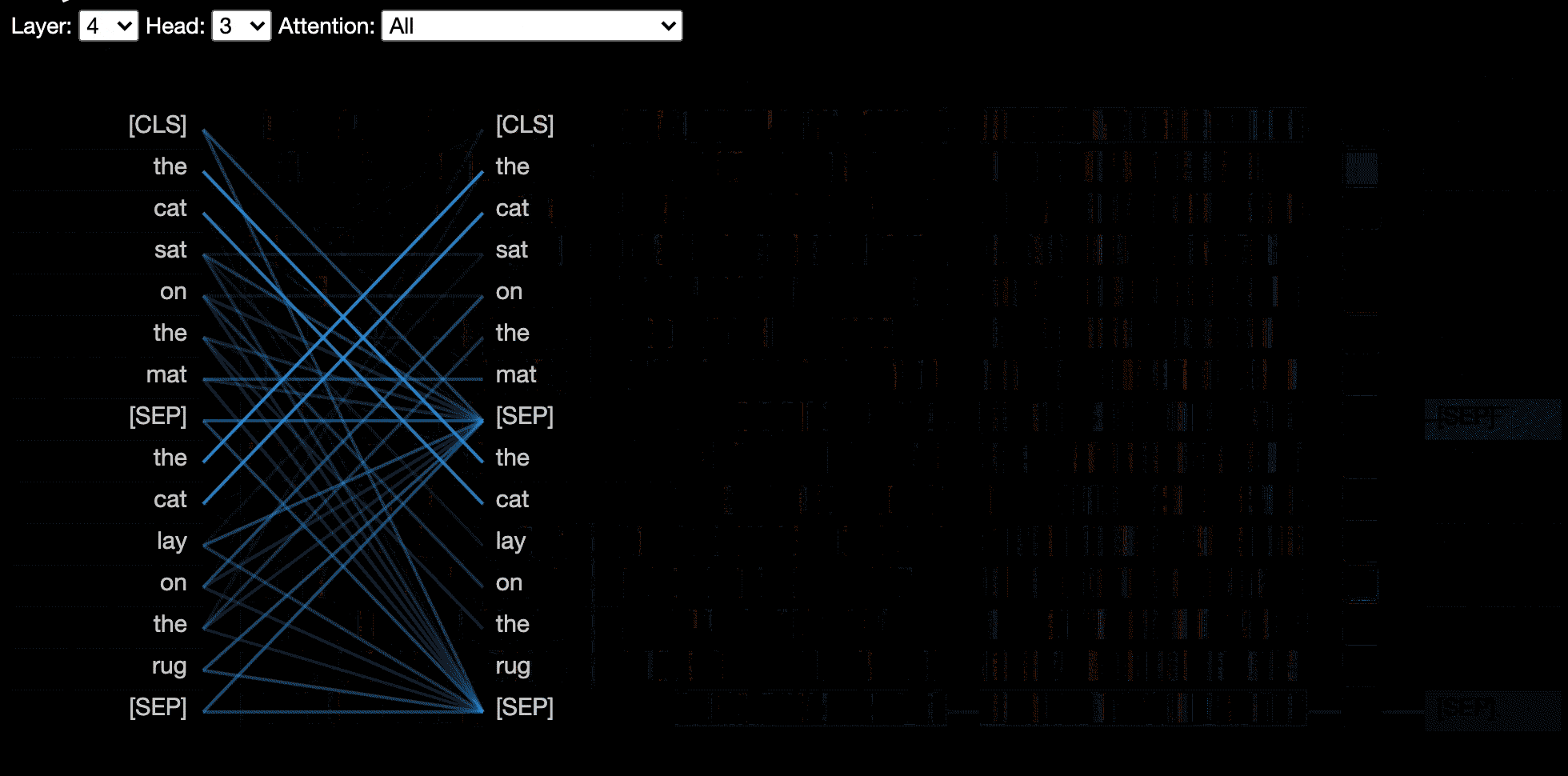
A vista da cabeça visualiza a atenção para uma ou mais cabeças de atenção na mesma camada. É baseado na excelente ferramenta de visualização do Tensor2tensor por Llion Jones.
? Experimente a visualização da cabeça no tutorial interativo do COLAB (todas as visualizações pré-carregadas).
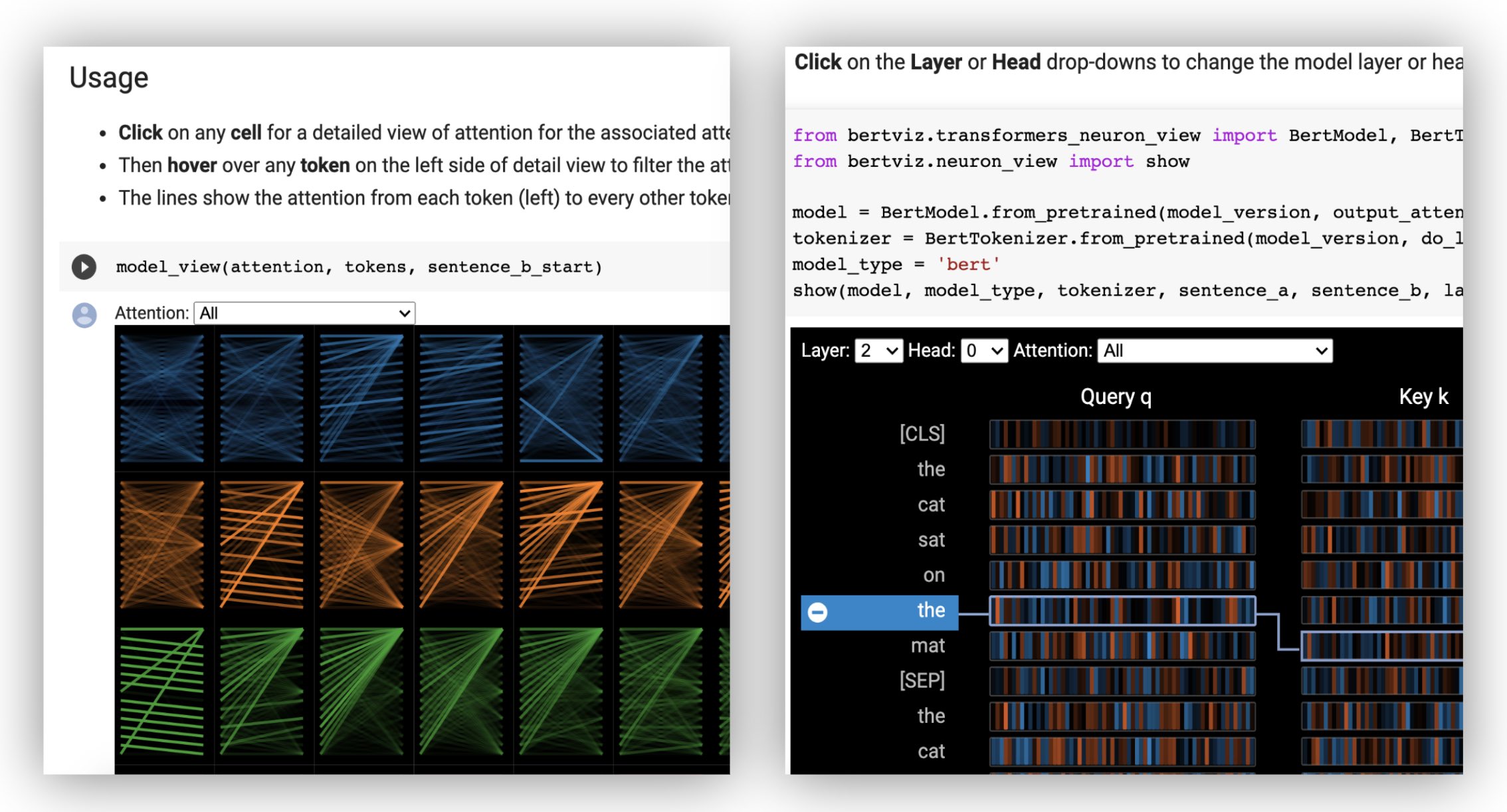
A visão do modelo mostra uma visão de atenção de todas as camadas e cabeças.
? Experimente a exibição do modelo no tutorial interativo do COLAB (todas as visualizações pré-carregadas).

A exibição de neurônios visualiza os neurônios individuais nas consultas e os principais vetores e mostra como eles são usados para calcular a atenção.
? Experimente a visualização do neurônio no tutorial interativo do COLAB (todas as visualizações pré-carregadas).
Da linha de comando:
pip install bertvizVocê também deve ter notebook Jupyter e ipywidgets instalados:
pip install jupyterlab
pip install ipywidgets(Se você tiver algum problema instalando Jupyter ou IpyWidgets, consulte a documentação aqui e aqui.)
Para criar um novo notebook Jupyter, basta executar:
jupyter notebook Em seguida, clique em New e selecione Python 3 (ipykernel) se solicitado.
Para executar no Colab, basta adicionar a célula a seguir no início do seu notebook Colab:
!pip install bertviz
Execute o código a seguir para carregar o modelo xtremedistil-l12-h384-uncased e exibi-lo na visualização do modelo:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewA visualização pode levar alguns segundos para carregar. Sinta -se à vontade para experimentar diferentes textos e modelos de entrada. Consulte a documentação para casos e exemplos de uso adicionais, por exemplo, modelos de codificadores-decodificadores.
Você também pode executar qualquer um dos notebooks de amostra incluídos no Bertviz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookConfira o tutorial interativo do COLAB para saber mais sobre o Bertviz e experimente a ferramenta. Nota : Todas as visualizações são pré-carregadas, portanto, não há necessidade de executar nenhuma célula.
Primeiro, carregue um modelo Huggingface, um modelo pré-treinado, como mostrado abaixo, ou seu próprio modelo de ajuste fino. Certifique -se de definir output_attentions=True .
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )Em seguida, prepare entradas e calcule a atenção:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) Por fim, exiba os pesos de atenção usando as funções head_view ou model_view :
from bertviz import head_view
head_view ( attention , tokens )Exemplos : Distilbert (Modelo View Notebook, Notebook da Visualização da Cabeça)
Para uma API completa, consulte o código -fonte para a visualização da cabeça ou a visualização do modelo.
A visualização do neurônio é invocada de maneira diferente da visualização da cabeça ou do modelo, devido à exigência de acesso aos vetores de consulta/chaves do modelo, que não são devolvidos pela API do HuggingFace. Atualmente, está limitado a versões personalizadas de Bert, GPT-2 e Roberta incluídas no Bertviz.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )Exemplos : Bert (Notebook, Colab) • GPT-2 (Notebook, Colab) • Roberta (Notebook)
Para API completa, consulte a fonte.
A visualização da cabeça e a exibição do modelo suportam os modelos de decodificadores do codificador.
Primeiro, carregue um modelo de codificador-decodificador:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )Em seguida, prepare as entradas e calcule a atenção:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) Por fim, exiba a visualização usando head_view ou model_view .
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) Você pode selecionar Encoder , Decoder ou Cross a atenção do suspensão no canto superior esquerdo da visualização.
Exemplos : Marianmt (Notebook) • Bart (notebook)
Para uma API completa, consulte o código -fonte para a visualização da cabeça ou a visualização do modelo.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop A visualização do modelo e a visão de neurônios suportam modos escuros (padrão) e de luz. Você pode definir o modo usando o parâmetro display_mode :
model_view ( attention , tokens , display_mode = "light" ) Para melhorar a capacidade de resposta da ferramenta ao visualizar modelos ou entradas maiores, você pode definir o parâmetro include_layers para restringir a visualização a um subconjunto de camadas (indexado zero). Esta opção está disponível na visualização da cabeça e no modelo.
Exemplo: Render Model View com apenas as camadas 5 e 6 exibidas
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) Para a visualização do modelo, você também pode restringir a visualização a um subconjunto de cabeças de atenção (indexado zero) definindo o parâmetro include_heads .
Na visualização da cabeça, você pode escolher uma layer específica e uma coleção de heads como seleção padrão quando a visualização renderiza primeiro. NOTA: Isso é diferente do parâmetro include_heads / include_layers (acima), que remove completamente as camadas e as cabeças da visualização.
Exemplo: renderizar a vista da cabeça com a camada 2 e as cabeças 3 e 5 pré-selecionadas
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) Você também pode pré-selecionar uma layer específica e uma única head para a vista do neurônio.
Alguns modelos, por exemplo, Bert, aceitam um par de frases como entrada. Opcionalmente, o Bertviz suporta um menu suspenso que permite ao usuário filtrar a atenção com base em qual frase em que os tokens estão, por exemplo, mostram apenas atenção entre os tokens na primeira frase e os tokens na segunda frase.
Para ativar esse recurso ao invocar as funções head_view ou model_view , defina o parâmetro sentence_b_start como o índice inicial da segunda frase. Observe que o método para calcular esse índice dependerá do modelo.
Exemplo (Bert):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) Para ativar esta opção na visualização do neurônio, basta definir os parâmetros sentence_a e sentence_b em neuron_view.show() .
O suporte para recuperar as representações HTML gerado foi adicionado ao Head_View, Model_View e Neuron_View.
A definição do parâmetro 'html_action' como 'return' fará com que a chamada de função retorne um único objeto HTML Python que pode ser mais processado. Lembre -se de que você pode acessar a fonte HTML usando o atributo de dados de um objeto Python HTML.
O comportamento padrão para 'html_action' é 'visualização', que exibirá a visualização, mas não retornará o objeto HTML.
Esta funcionalidade é útil se você precisar:
Exemplo (vistas de cabeça e modelo):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )Exemplo (Visualização de Neurônios):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) A visualização da cabeça e a visualização do modelo podem ser usadas para visualizar a auto-distribuição para qualquer modelo de transformador padrão, desde que os pesos de atenção estejam disponíveis e siga o formato especificado em head_view e model_view (que é o formato retornado dos modelos Huggingface). Em alguns casos, os pontos de verificação do tensorflow podem ser carregados como modelos Huggingface, conforme descrito nos documentos HuggingFace.
include_layers , conforme descrito acima.include_layers , conforme descrito acima.transformers_neuron_view ), que só foi feito para esses três modelos. Uma visualização em várias escalas de atenção no modelo do transformador (Demonstrações do Sistema ACL 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Jesse Vig
Somos gratos aos autores dos seguintes projetos, que são incorporados a este repo:
Este projeto está licenciado sob a licença Apache 2.0 - consulte o arquivo de licença para obter detalhes


