bertviz
v1.4.0
Bertviz هي أداة تفاعلية لتصور الانتباه في نماذج لغة المحولات مثل BERT أو GPT2 أو T5. يمكن تشغيله داخل دفتر Jupyter أو Colab من خلال واجهة برمجة تطبيقات Python بسيطة تدعم معظم طرز المعانقة. يمتد Bertviz أداة تصور Tensor2Tensor بواسطة Llion Jones ، مما يوفر طرقًا متعددة توفر كل منها عدسة فريدة من نوعها في آلية الانتباه.
احصل على تحديثات لهذا والمشاريع ذات الصلة على Twitter.
تصور عرض الرأس الانتباه لرؤوس الاهتمام أو أكثر في نفس الطبقة. يعتمد على أداة تصور Tensor2Tensor الممتازة بواسطة Llion Jones.
؟ جرب عرض الرأس في البرنامج التعليمي التفاعلي Colab (جميع التصورات التي تم تحميلها مسبقًا).
يُظهر طريقة عرض النموذج رؤية للعين للانتباه في جميع الطبقات والرؤوس.
؟ جرب عرض النموذج في البرنامج التعليمي التفاعلي Colab (جميع التصورات التي تم تحميلها مسبقًا).

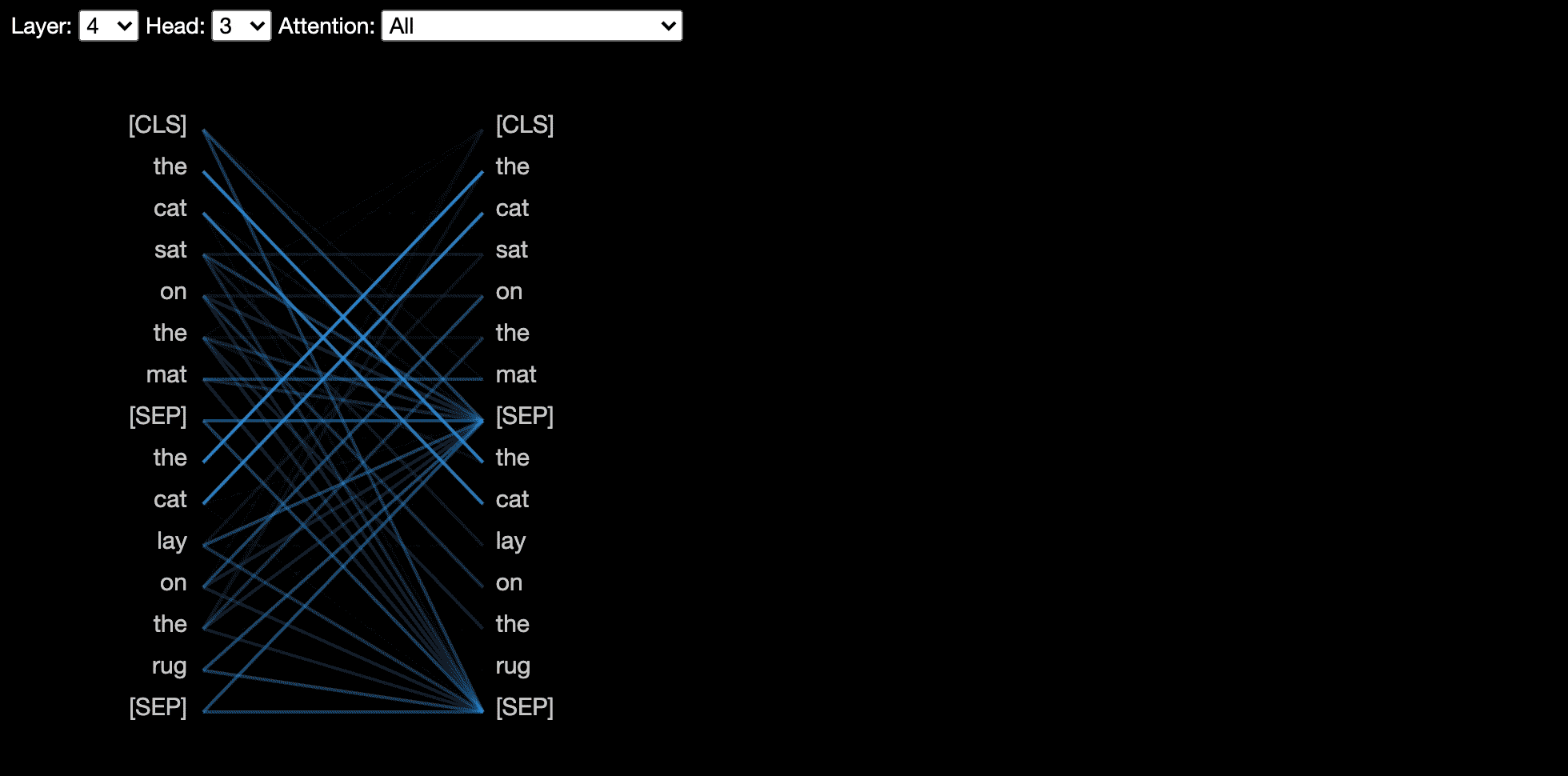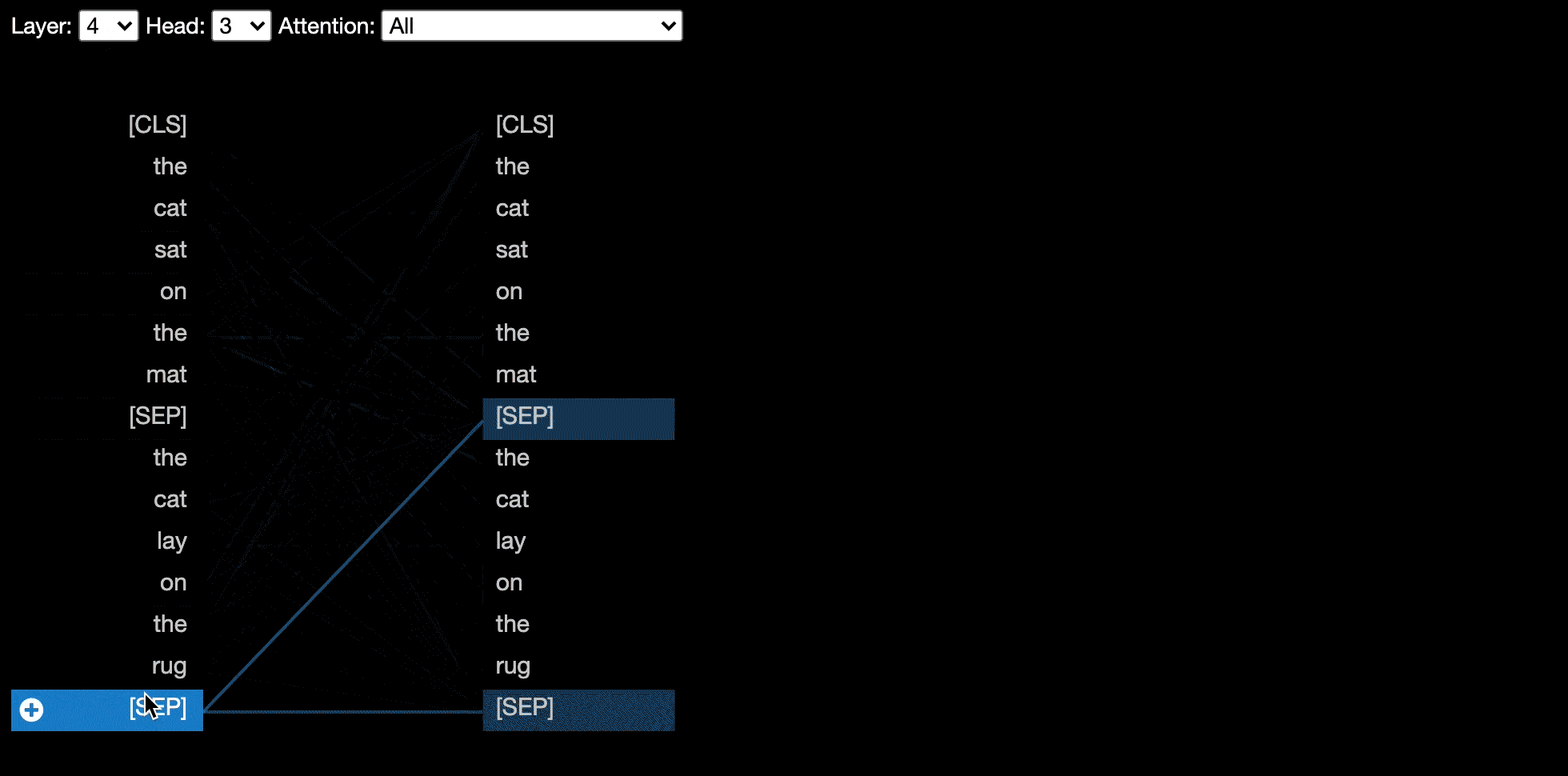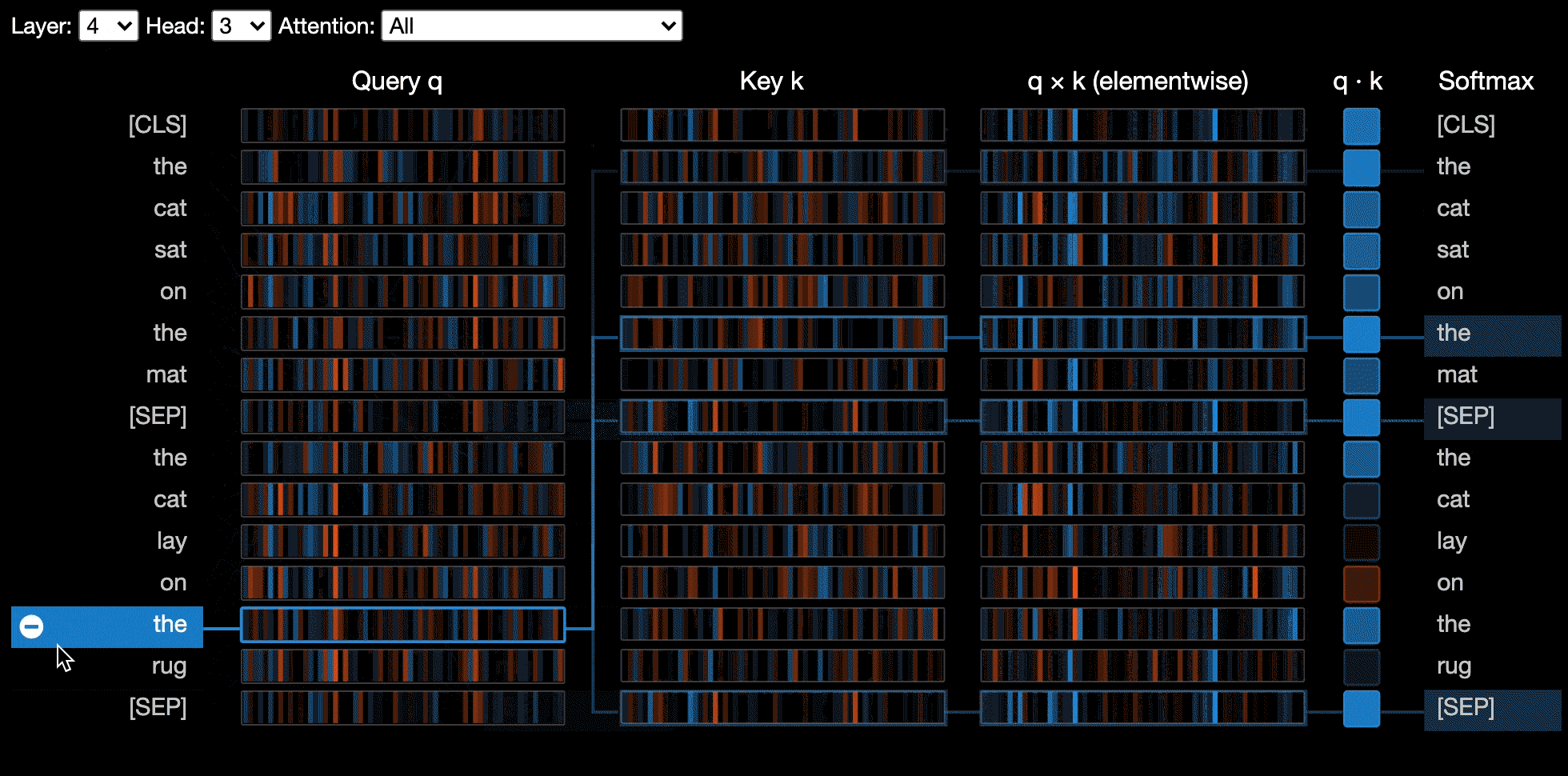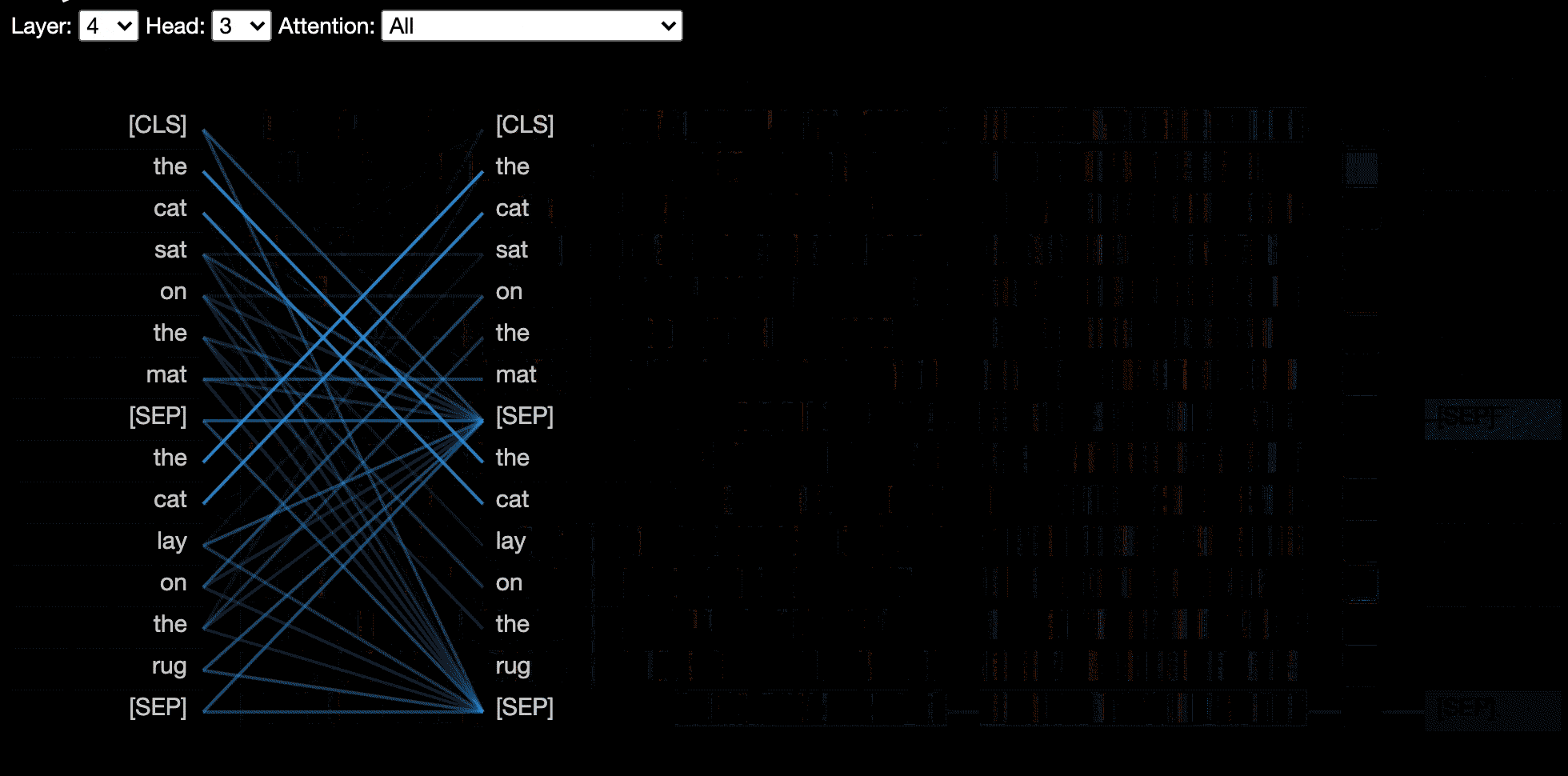
تصور طريقة عرض الخلايا العصبية الخلايا العصبية الفردية في المتجهات الاستعلام والمفتاح وتظهر كيف يتم استخدامها لحساب الانتباه.
؟ جرب عرض الخلايا العصبية في البرنامج التعليمي التفاعلي Colab (جميع التصورات التي تم تحميلها مسبقًا).
من سطر الأوامر:
pip install bertvizيجب أن يكون لديك أيضًا دفتر Jupyter و IpyWidgets المثبتون:
pip install jupyterlab
pip install ipywidgets(إذا واجهت أي مشكلات في تثبيت jupyter أو ipywidgets ، فاستشر الوثائق هنا وهنا.)
لإنشاء دفتر جديد Jupyter ، ما عليك سوى التشغيل:
jupyter notebook ثم انقر فوق New وحدد Python 3 (ipykernel) إذا تمت مطالبته.
للتشغيل في كولاب ، ما عليك سوى إضافة الخلية التالية في بداية دفتر كولاب الخاص بك:
!pip install bertviz
قم بتشغيل الكود التالي لتحميل نموذج xtremedistil-l12-h384-uncased وعرضه في عرض النموذج:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewقد يستغرق التصور بضع ثوان لتحميل. لا تتردد في تجربة نصوص ونماذج إدخال مختلفة. راجع الوثائق للحصول على حالات الاستخدام الإضافية والأمثلة ، على سبيل المثال ، نماذج ترميز التشفير.
يمكنك أيضًا تشغيل أي من أجهزة الكمبيوتر المحمولة العينة المضمنة في Bertviz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookتحقق من البرنامج التعليمي التفاعلي كولاب لمعرفة المزيد عن بيرفيز وجرب الأداة. ملاحظة : يتم تحميل جميع التصورات مسبقًا ، لذلك ليست هناك حاجة لتنفيذ أي خلايا.
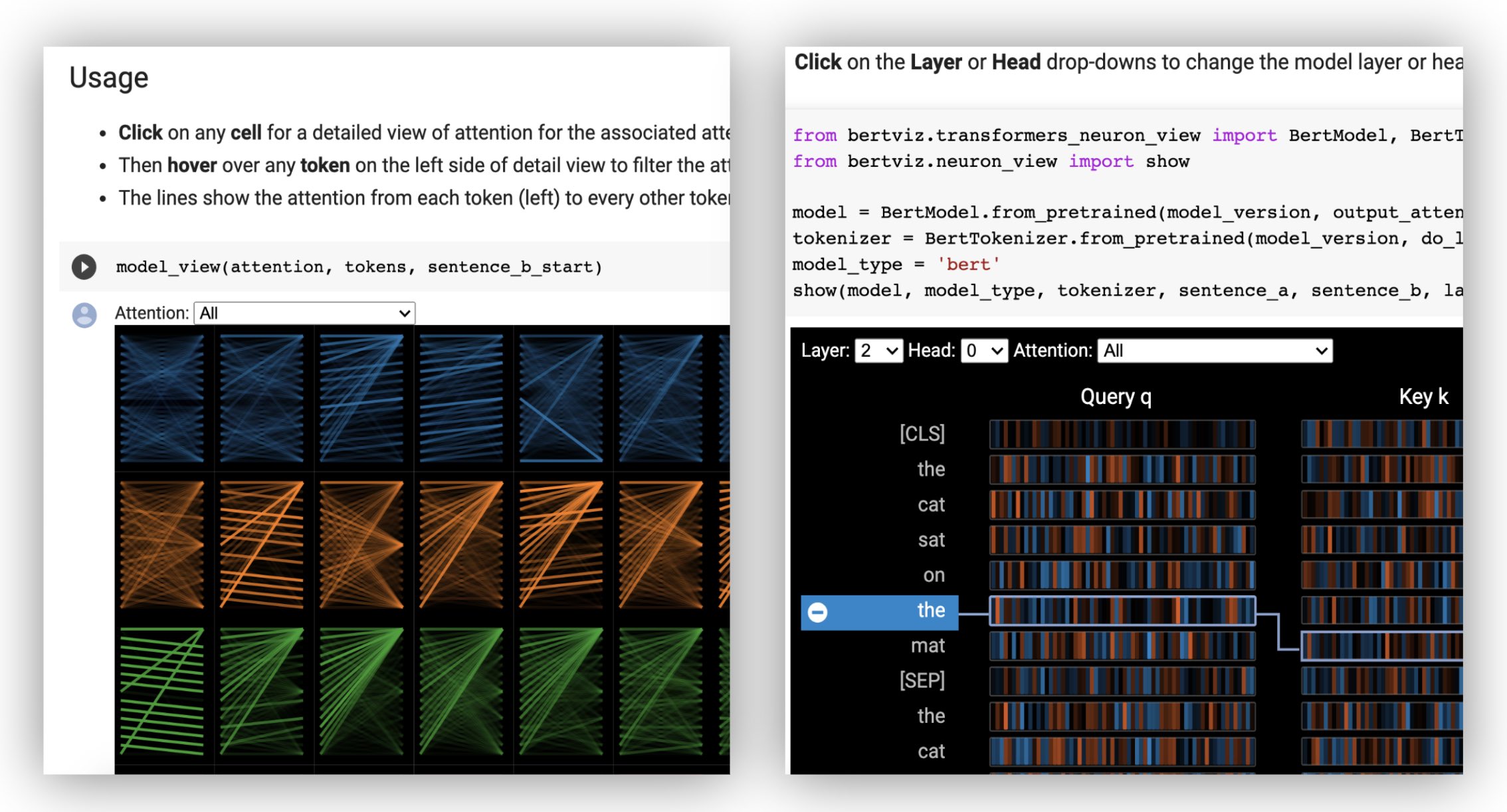
قم أولاً بتحميل نموذج Luggingface ، إما نموذج تدريب مسبقًا كما هو موضح أدناه ، أو نموذجك الخاص. تأكد من تعيين output_attentions=True .
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )ثم قم بإعداد المدخلات وحساب الانتباه:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) أخيرًا ، عرض أوزان الانتباه باستخدام وظائف head_view أو model_view :
from bertviz import head_view
head_view ( attention , tokens )أمثلة : Distilbert (دفتر ملاحظات عرض النموذج ، دفتر عرض الرأس)
للحصول على واجهة برمجة التطبيقات الكاملة ، يرجى الرجوع إلى الكود المصدري لعرض الرأس أو عرض النموذج.
يتم استدعاء طريقة عرض الخلايا العصبية بشكل مختلف عن عرض الرأس أو عرض النموذج ، نظرًا لطلب الوصول إلى متجهات الاستعلام/المفاتيح للنموذج ، والتي لا يتم إرجاعها من خلال واجهة برمجة تطبيقات Luggingface. يقتصر حاليًا على الإصدارات المخصصة من BERT و GPT-2 و Roberta مدرجة في Bertviz.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )أمثلة : Bert (دفتر ملاحظات ، كولاب) • GPT-2 (دفتر ملاحظات ، كولاب) • روبرتا (دفتر ملاحظات)
للحصول على واجهة برمجة التطبيقات الكاملة ، يرجى الرجوع إلى المصدر.
يدعم عرض الرأس وعرض النموذج كلا من نماذج ترميز التشفير.
أولاً ، قم بتحميل نموذج ترميز التشفير:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )ثم قم بإعداد المدخلات وحساب الانتباه:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) أخيرًا ، عرض التصور باستخدام إما head_view أو model_view .
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) يمكنك تحديد Encoder أو Cross Decoder أو الانتباه من المنسدلة في الزاوية اليسرى العلوية من التصور.
أمثلة : Marianmt (دفتر ملاحظات) • بارت (دفتر ملاحظات)
للحصول على واجهة برمجة التطبيقات الكاملة ، يرجى الرجوع إلى الكود المصدري لعرض الرأس أو عرض النموذج.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop يدعم عرض النموذج وعرض الخلايا العصبية المظلمة (الافتراضية) والضوء. يمكنك تعيين الوضع باستخدام معلمة display_mode :
model_view ( attention , tokens , display_mode = "light" ) لتحسين استجابة الأداة عند تصور النماذج أو المدخلات الأكبر ، يمكنك تعيين معلمة include_layers لتقييد التصور على مجموعة فرعية من الطبقات (مفهرس صفر). يتوفر هذا الخيار في عرض الرأس وعرض النموذج.
مثال: عرض عرض الطراز مع الطبقات 5 و 6 فقط
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) بالنسبة لعرض النموذج ، يمكنك أيضًا تقييد التصور على مجموعة فرعية من رؤوس الاهتمام (مفهرسة صفر) عن طريق تعيين معلمة include_heads .
في عرض الرأس ، يمكنك اختيار layer محددة ومجموعة من heads كتحديد افتراضي عندما يقدم التصور أولاً. ملاحظة: يختلف هذا عن معلمة include_heads / include_layers (أعلاه) ، والتي تزيل الطبقات والرؤوس من التصور تمامًا.
مثال: عرض عرض الرأس مع الطبقة 2 والرؤوس 3 و 5 تم اختيارهم مسبقًا
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) يمكنك أيضًا تحديد layer محددة head واحد لعرض الخلايا العصبية.
بعض النماذج ، على سبيل المثال بيرت ، تقبل زوجًا من الجمل كمدخلات. يدعم Bertviz اختياريًا قائمة منسدلة تسمح للمستخدم بتصفية الانتباه بناءً على الجملة التي توجد بها الرموز ، على سبيل المثال ، تظهر فقط الانتباه بين الرموز في الجملة الأولى والرموز في الجملة الثانية.
لتمكين هذه الميزة عند استدعاء وظائف head_view أو model_view ، قم بتعيين المعلمة sentence_b_start إلى فهرس البدء في الجملة الثانية. لاحظ أن طريقة حساب هذا الفهرس تعتمد على النموذج.
مثال (بيرت):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) لتمكين هذا الخيار في عرض الخلايا العصبية ، ما عليك سوى تعيين معلمات sentence_a و sentence_b في neuron_view.show() .
تمت إضافة دعم لاسترداد تمثيل HTML الذي تم إنشاؤه إلى Head_View و Model_View و Neuron_View.
سيؤدي تعيين معلمة "HTML_ACTION" إلى "الإرجاع" إلى جعل استدعاء الوظيفة إرجاع كائن HTML Python واحد يمكن معالجته بشكل أكبر. تذكر أنه يمكنك الوصول إلى مصدر HTML باستخدام سمة البيانات لكائن Python HTML.
السلوك الافتراضي لـ "HTML_ACTION" هو "عرض" ، والذي سيعرض التصور ولكنه لن يعيد كائن HTML.
هذه الوظيفة مفيدة إذا كنت بحاجة إلى:
مثال (طرق عرض الرأس والنموذج):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )مثال (عرض الخلايا العصبية):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) يمكن استخدام عرض الرأس وعرض النموذج لتصور الاهتمام الذاتي لأي نموذج محول قياسي ، طالما أن أوزان الاهتمام متوفرة وتتبع التنسيق المحدد في head_view و model_view (وهو التنسيق الذي تم إرجاعه من نماذج Luggingface). في بعض الحالات ، قد يتم تحميل نقاط تفتيش TensorFlow كنماذج عناق كما هو موضح في مستندات Huggingface.
include_layers ، كما هو موضح أعلاه.include_layers ، كما هو موضح أعلاه.transformers_neuron_view ) ، والذي تم القيام به فقط لهذه النماذج الثلاثة. تصور متعدد المقاييس للانتباه في نموذج المحولات (مظاهرات نظام ACL 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}جيسي فيج
نحن ممتنون لمؤلفي المشاريع التالية ، والتي تم دمجها في هذا الريبو:
تم ترخيص هذا المشروع بموجب ترخيص Apache 2.0 - راجع ملف الترخيص للحصول على التفاصيل


