bertviz
v1.4.0
Bertviz เป็นเครื่องมือเชิงโต้ตอบสำหรับการแสดงภาพความสนใจในรูปแบบภาษาหม้อแปลงเช่น Bert, GPT2 หรือ T5 มันสามารถทำงานภายใน Jupyter หรือ Colab Notebook ผ่าน Python API แบบง่าย ๆ ที่รองรับโมเดล HuggingFace ส่วนใหญ่ Bertviz ขยายเครื่องมือสร้างภาพ Tensor2tensor โดย Llion Jones ซึ่งให้มุมมองหลายครั้งที่แต่ละเลนส์เสนอเลนส์ที่ไม่ซ้ำกันในกลไกความสนใจ
รับการอัปเดตสำหรับโครงการนี้และโครงการที่เกี่ยวข้องบน Twitter
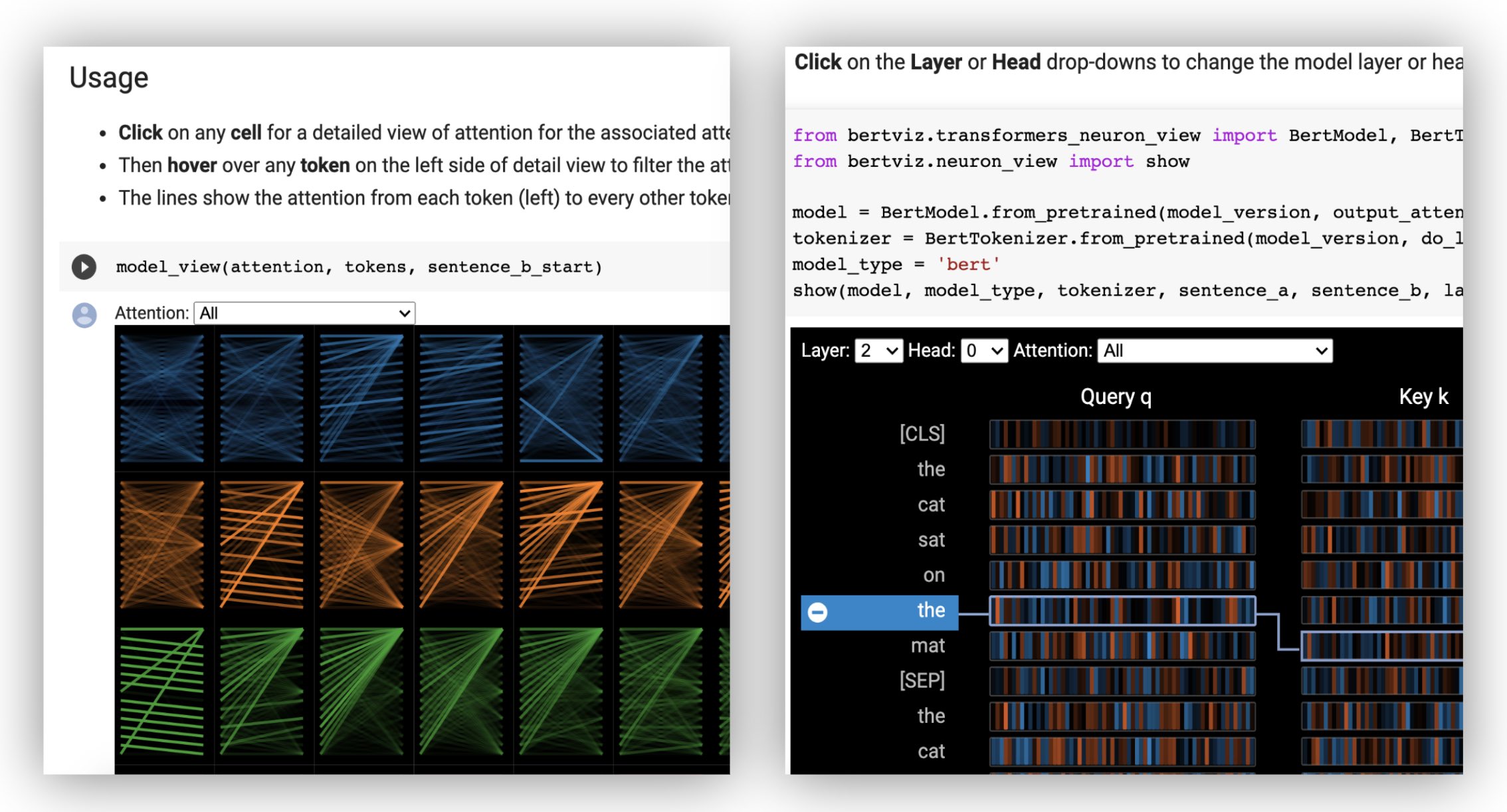
มุมมองหัว แสดงให้เห็นถึงความสนใจสำหรับหัวความสนใจอย่างน้อยหนึ่งหัวในเลเยอร์เดียวกัน มันขึ้นอยู่กับเครื่องมือสร้างภาพ Tensor2tensor ที่ยอดเยี่ยมโดย Llion Jones
- ลองดูมุมมองหัวใน บทช่วยสอน colab แบบโต้ตอบ (การสร้างภาพทั้งหมดล่วงหน้า)
มุมมองแบบจำลอง แสดงมุมมองที่น่าสนใจของนกในทุกเลเยอร์และหัว
- ลองใช้มุมมองโมเดลใน บทช่วยสอน colab แบบโต้ตอบ (การสร้างภาพทั้งหมดล่วงหน้า)

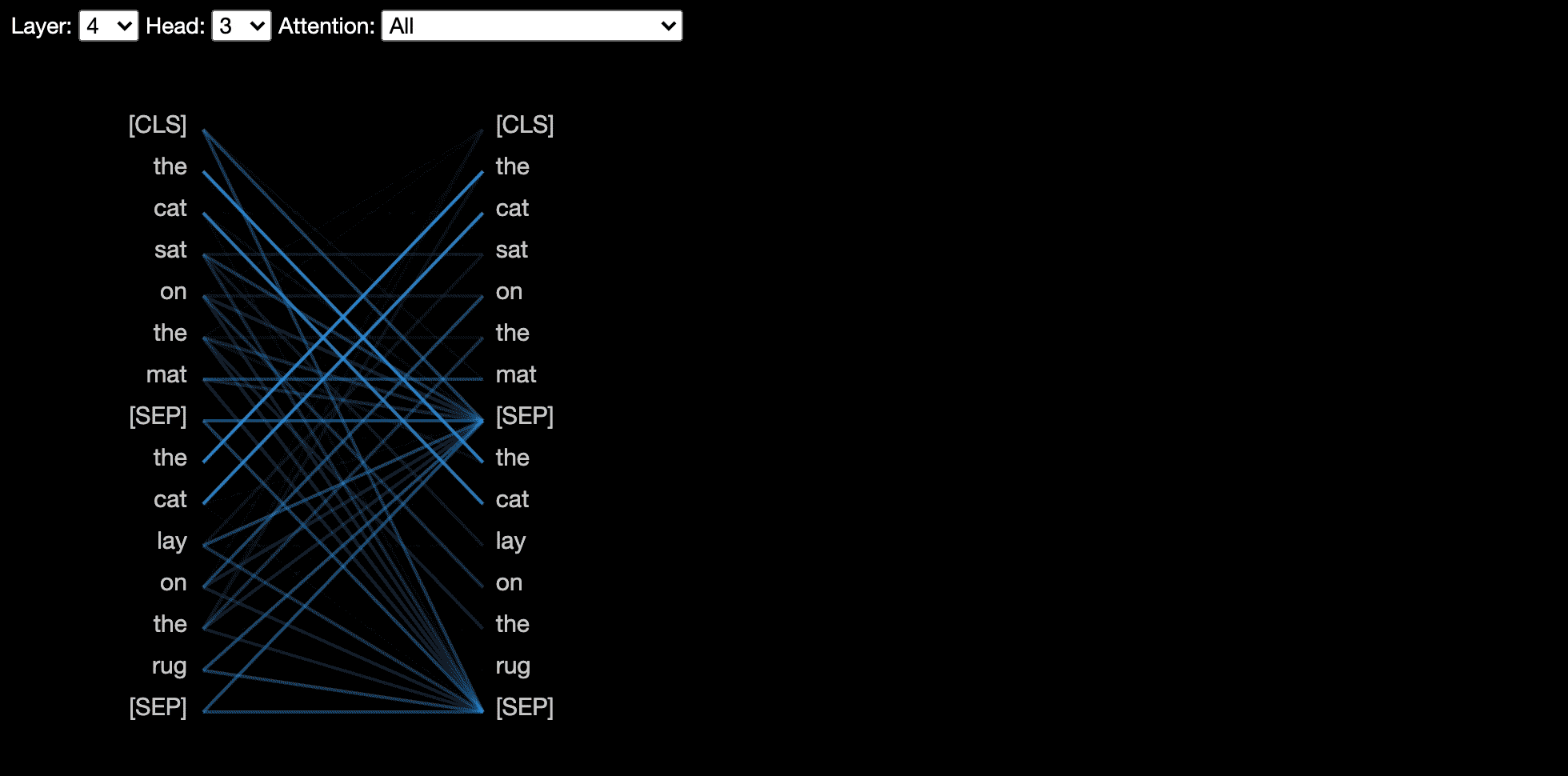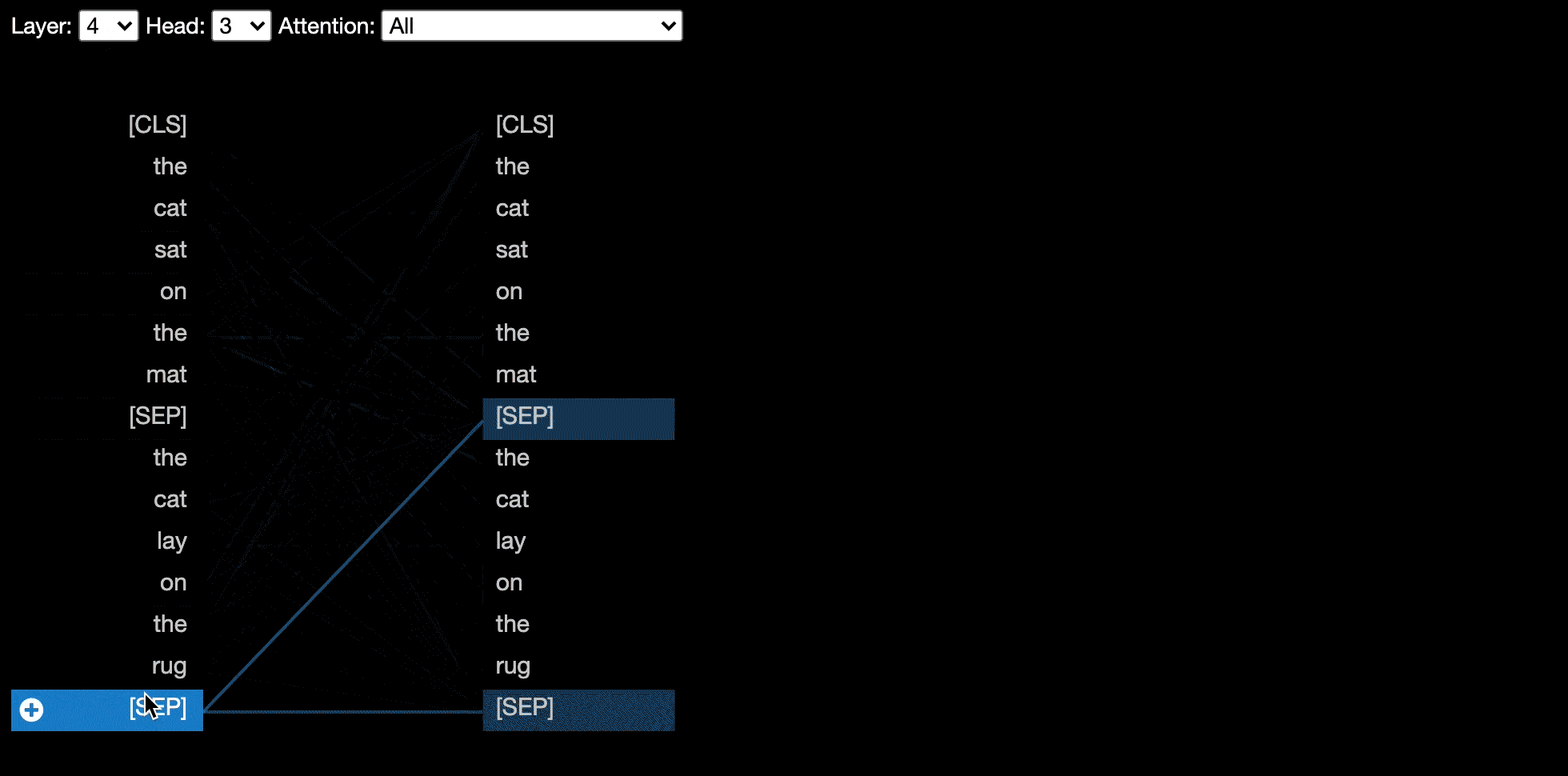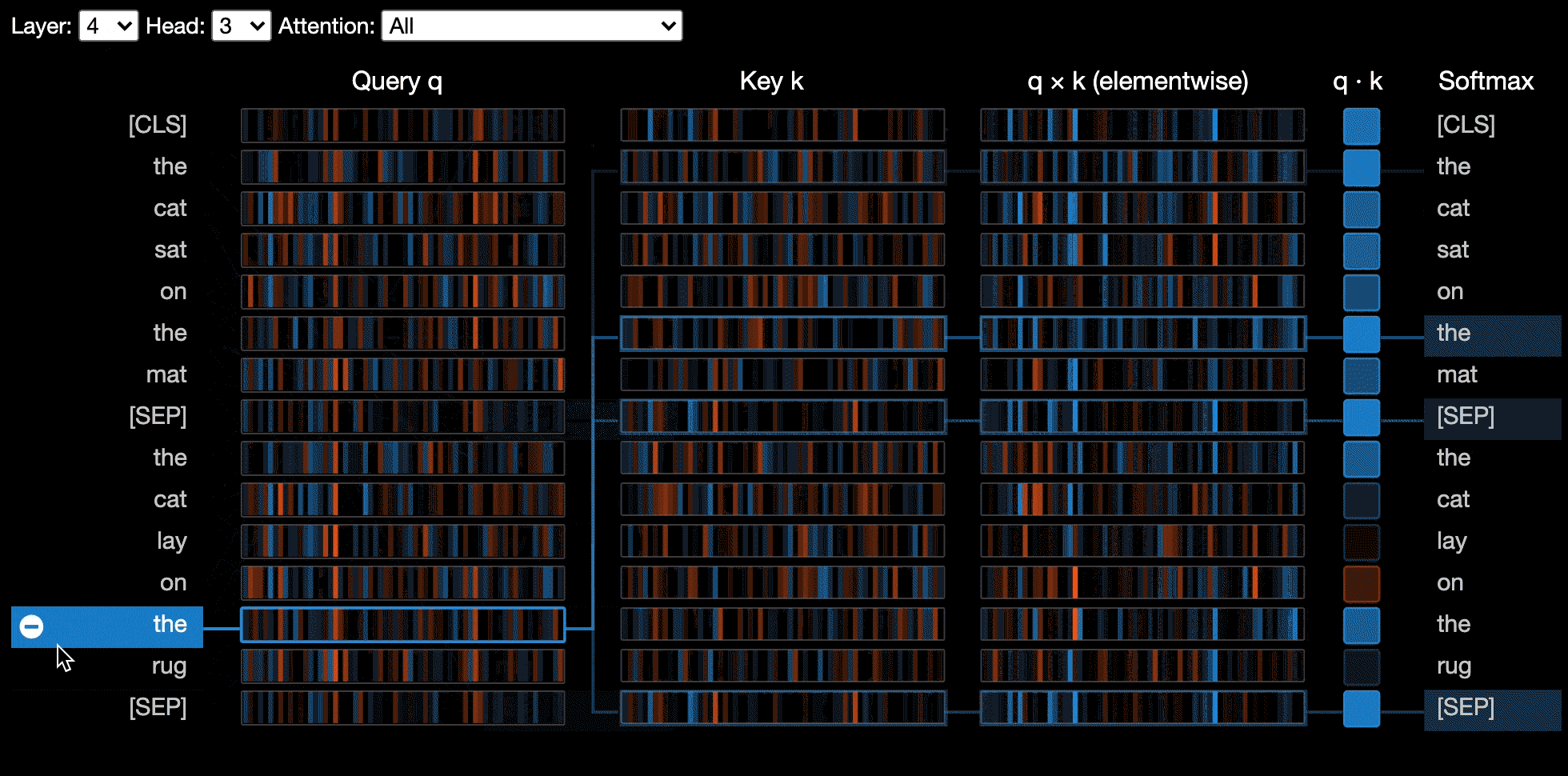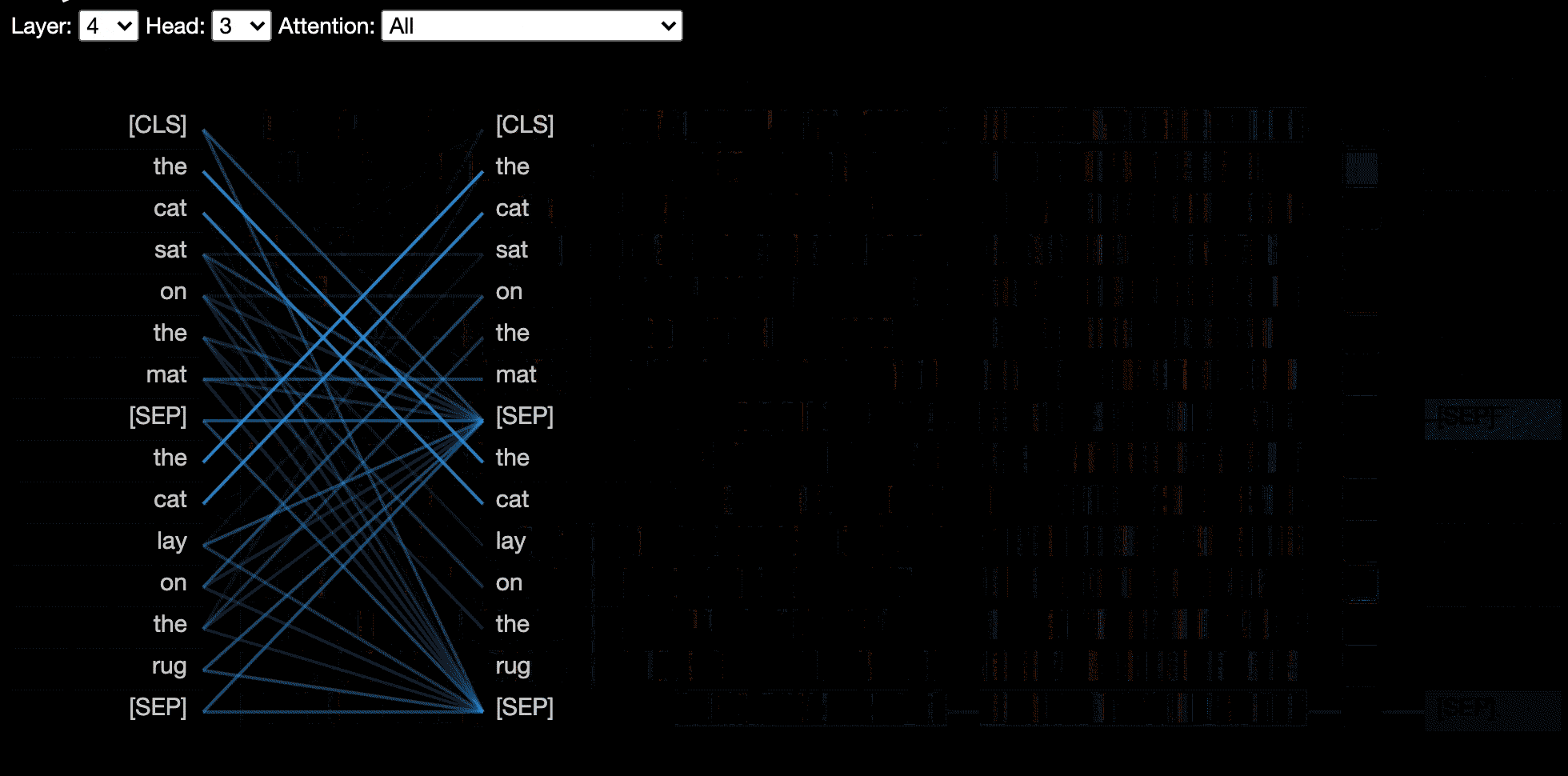
มุมมองของเซลล์ประสาท จะมองเห็นเซลล์ประสาทส่วนบุคคลในแบบสอบถามและเวกเตอร์คีย์และแสดงให้เห็นว่าพวกเขาใช้ในการคำนวณความสนใจอย่างไร
- ลองใช้มุมมองเซลล์ประสาทใน บทช่วยสอน colab แบบโต้ตอบ (การสร้างภาพทั้งหมดล่วงหน้า)
จากบรรทัดคำสั่ง:
pip install bertvizคุณต้องติดตั้งสมุดบันทึก Jupyter และ IpyWidgets:
pip install jupyterlab
pip install ipywidgets(หากคุณพบปัญหาใด ๆ ที่ติดตั้ง Jupyter หรือ IpyWidgets ปรึกษาเอกสารที่นี่และที่นี่)
ในการสร้างสมุดบันทึก Jupyter ใหม่เพียงแค่เรียกใช้:
jupyter notebook จากนั้นคลิก New และเลือก Python 3 (ipykernel) หากได้รับแจ้ง
ในการทำงานใน colab เพียงเพิ่มเซลล์ต่อไปนี้ที่จุดเริ่มต้นของสมุดบันทึก colab ของคุณ:
!pip install bertviz
เรียกใช้รหัสต่อไปนี้เพื่อโหลดโมเดล xtremedistil-l12-h384-uncased และแสดงในมุมมองโมเดล:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewการสร้างภาพอาจใช้เวลาสองสามวินาทีในการโหลด อย่าลังเลที่จะทดลองกับข้อความและโมเดลอินพุตที่แตกต่างกัน ดูเอกสารสำหรับกรณีและตัวอย่างการใช้งานเพิ่มเติมเช่นรุ่นเข้ารหัส-เครื่องบันทึก
นอกจากนี้คุณยังสามารถเรียกใช้สมุดบันทึกตัวอย่างใด ๆ ที่มาพร้อมกับ Bertviz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookตรวจสอบ การสอนแบบอินเทอร์แอคทีฟ เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับ Bertviz และลองใช้เครื่องมือ หมายเหตุ : การสร้างภาพทั้งหมดจะถูกโหลดล่วงหน้าดังนั้นจึงไม่จำเป็นต้องดำเนินการเซลล์ใด ๆ
โหลดโมเดล HuggingFace ก่อนอื่นไม่ว่าจะเป็นรุ่นที่ผ่านการฝึกอบรมมาแล้วตามที่แสดงด้านล่างหรือโมเดลที่ได้รับการปรับแต่งของคุณเอง ตรวจสอบให้แน่ใจว่าได้ตั้งค่า output_attentions=True
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )จากนั้นเตรียมอินพุตและคำนวณความสนใจ:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) สุดท้ายแสดงน้ำหนักความสนใจโดยใช้ฟังก์ชั่น head_view หรือ model_view :
from bertviz import head_view
head_view ( attention , tokens )ตัวอย่าง : Distilbert (Notebook View Model, Head View Notebook)
สำหรับ API เต็มรูปแบบโปรดดูที่ซอร์สโค้ดสำหรับมุมมองส่วนหัวหรือมุมมองรุ่น
มุมมองของเซลล์ประสาทถูกเรียกใช้แตกต่างจากมุมมองส่วนหัวหรือมุมมองรุ่นเนื่องจากต้องเข้าถึงการสืบค้น/เวกเตอร์คีย์ของโมเดลซึ่งไม่ได้ส่งคืนผ่าน API HuggingFace ปัจจุบันมัน จำกัด อยู่ที่ Bert, GPT-2 และ Roberta รุ่นที่กำหนดเองรวมอยู่ใน Bertviz
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )ตัวอย่าง : Bert (Notebook, Colab) • GPT-2 (สมุดบันทึก, colab) • Roberta (Notebook)
สำหรับ API เต็มรูปแบบโปรดดูแหล่งที่มา
มุมมองส่วนหัวและรุ่นดูทั้งรุ่นรองรับการเข้ารหัส
ก่อนอื่นให้โหลดรุ่น Decoder encoder:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )จากนั้นเตรียมอินพุตและคำนวณความสนใจ:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) ในที่สุดแสดงการสร้างภาพโดยใช้ head_view หรือ model_view
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) คุณสามารถเลือก Encoder Decoder หรือ Cross ความสนใจจากดรอปดาวน์ที่มุมซ้ายบนของการสร้างภาพข้อมูล
ตัวอย่าง : Marianmt (สมุดบันทึก) • Bart (Notebook)
สำหรับ API เต็มรูปแบบโปรดดูที่ซอร์สโค้ดสำหรับมุมมองส่วนหัวหรือมุมมองรุ่น
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop มุมมองแบบจำลองและมุมมองเซลล์ประสาทรองรับมืด (ค่าเริ่มต้น) และโหมดแสง คุณสามารถตั้งค่าโหมดโดยใช้พารามิเตอร์ display_mode :
model_view ( attention , tokens , display_mode = "light" ) เพื่อปรับปรุงการตอบสนองของเครื่องมือเมื่อเห็นภาพโมเดลหรืออินพุตขนาดใหญ่คุณอาจตั้งค่าพารามิเตอร์ include_layers เพื่อ จำกัด การสร้างภาพให้เป็นชุดย่อยของเลเยอร์ (zero-amexed) ตัวเลือกนี้มีอยู่ในมุมมองส่วนหัวและมุมมองรุ่น
ตัวอย่าง: แสดงมุมมองโมเดลที่มีเพียงเลเยอร์ 5 และ 6 ที่แสดง
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) สำหรับมุมมองโมเดลคุณอาจ จำกัด การสร้างภาพให้กับชุดย่อยของหัวความสนใจ (Zero-Idexed) โดยการตั้งค่าพารามิเตอร์ include_heads
ในมุมมองหัวคุณอาจเลือก layer เฉพาะและคอลเลกชันของ heads เป็นตัวเลือกเริ่มต้นเมื่อการสร้างภาพแสดงผลครั้งแรกแสดงผล หมายเหตุ: สิ่งนี้แตกต่างจากพารามิเตอร์ include_heads / include_layers (ด้านบน) ซึ่งจะลบเลเยอร์และหัวออกจากการสร้างภาพข้อมูลอย่างสมบูรณ์
ตัวอย่าง: แสดงมุมมองหัวด้วยเลเยอร์ 2 และหัว 3 และ 5 ที่เลือกไว้ล่วงหน้า
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) คุณอาจเลือก layer ที่เฉพาะเจาะจงและ head เดี่ยวสำหรับมุมมองเซลล์ประสาทล่วงหน้า
บางรุ่นเช่นเบิร์ตยอมรับประโยคหนึ่งคู่เป็นอินพุต Bertviz เลือกเมนูแบบเลื่อนลงที่ช่วยให้ผู้ใช้สามารถกรองความสนใจตามประโยคใดที่โทเค็นอยู่ในเช่นแสดงความสนใจระหว่างโทเค็นในประโยคแรกและโทเค็นในประโยคที่สองเท่านั้น
ในการเปิดใช้งานคุณสมบัตินี้เมื่อเรียกใช้ฟังก์ชัน head_view หรือ model_view ให้ตั้งค่าพารามิเตอร์ sentence_b_start เป็นดัชนีเริ่มต้นของประโยคที่สอง โปรดทราบว่าวิธีการคำนวณดัชนีนี้จะขึ้นอยู่กับโมเดล
ตัวอย่าง (เบิร์ต):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) ในการเปิดใช้งานตัวเลือกนี้ในมุมมองเซลล์ประสาทเพียงตั้งค่าพารามิเตอร์ sentence_a และ sentence_b ใน neuron_view.show()
การสนับสนุนเพื่อดึงการแสดง HTML ที่สร้างขึ้นได้ถูกเพิ่มลงใน head_view, model_view และ neuron_view
การตั้งค่าพารามิเตอร์ 'HTML_ACTION' เป็น 'return' จะทำให้การเรียกใช้ฟังก์ชันส่งคืนวัตถุ HTML Python เดียวที่สามารถประมวลผลเพิ่มเติมได้ จำไว้ว่าคุณสามารถเข้าถึงแหล่ง HTML โดยใช้แอตทริบิวต์ข้อมูลของวัตถุ Python HTML
พฤติกรรมเริ่มต้นสำหรับ 'HTML_ACTION' คือ 'มุมมอง' ซึ่งจะแสดงการสร้างภาพข้อมูล แต่จะไม่ส่งคืนวัตถุ HTML
ฟังก์ชั่นนี้มีประโยชน์หากคุณต้องการ:
ตัวอย่าง (มุมมองหัวและแบบจำลอง):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )ตัวอย่าง (มุมมองเซลล์ประสาท):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) มุมมองส่วนหัวและมุมมองแบบจำลองอาจถูกใช้เพื่อแสดงภาพการดูแลตนเองสำหรับโมเดลหม้อแปลงมาตรฐานใด ๆ ตราบใดที่น้ำหนักความสนใจมีอยู่และทำตามรูปแบบที่ระบุใน head_view และ model_view (ซึ่งเป็นรูปแบบที่ส่งคืนจากโมเดล HuggingFace) ในบางกรณีจุดตรวจ Tensorflow อาจโหลดเป็นโมเดล HuggingFace ตามที่อธิบายไว้ในเอกสาร HuggingFace
include_layers ตามที่อธิบายไว้ข้างต้นinclude_layers ตามที่อธิบายไว้ข้างต้นtransformers_neuron_view ) ซึ่งทำเฉพาะสำหรับทั้งสามรุ่นเท่านั้น การแสดงภาพหลายระดับของความสนใจในโมเดลหม้อแปลง (การสาธิตระบบ ACL 2019)
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Jesse Vig
เราขอขอบคุณผู้เขียนโครงการต่อไปนี้ซึ่งรวมอยู่ใน repo นี้:
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต Apache 2.0 - ดูไฟล์ใบอนุญาตสำหรับรายละเอียด


