bertviz
v1.4.0
Bertviz es una herramienta interactiva para visualizar la atención en modelos de lenguaje de transformadores como Bert, GPT2 o T5. Se puede ejecutar dentro de un cuaderno de Jupyter o Colab a través de una simple API de Python que admite la mayoría de los modelos de Facingface. Bertviz extiende la herramienta de visualización Tensor2Tensor por Llion Jones, proporcionando múltiples vistas que ofrecen una lente única en el mecanismo de atención.
Obtenga actualizaciones para esto y proyectos relacionados en Twitter.
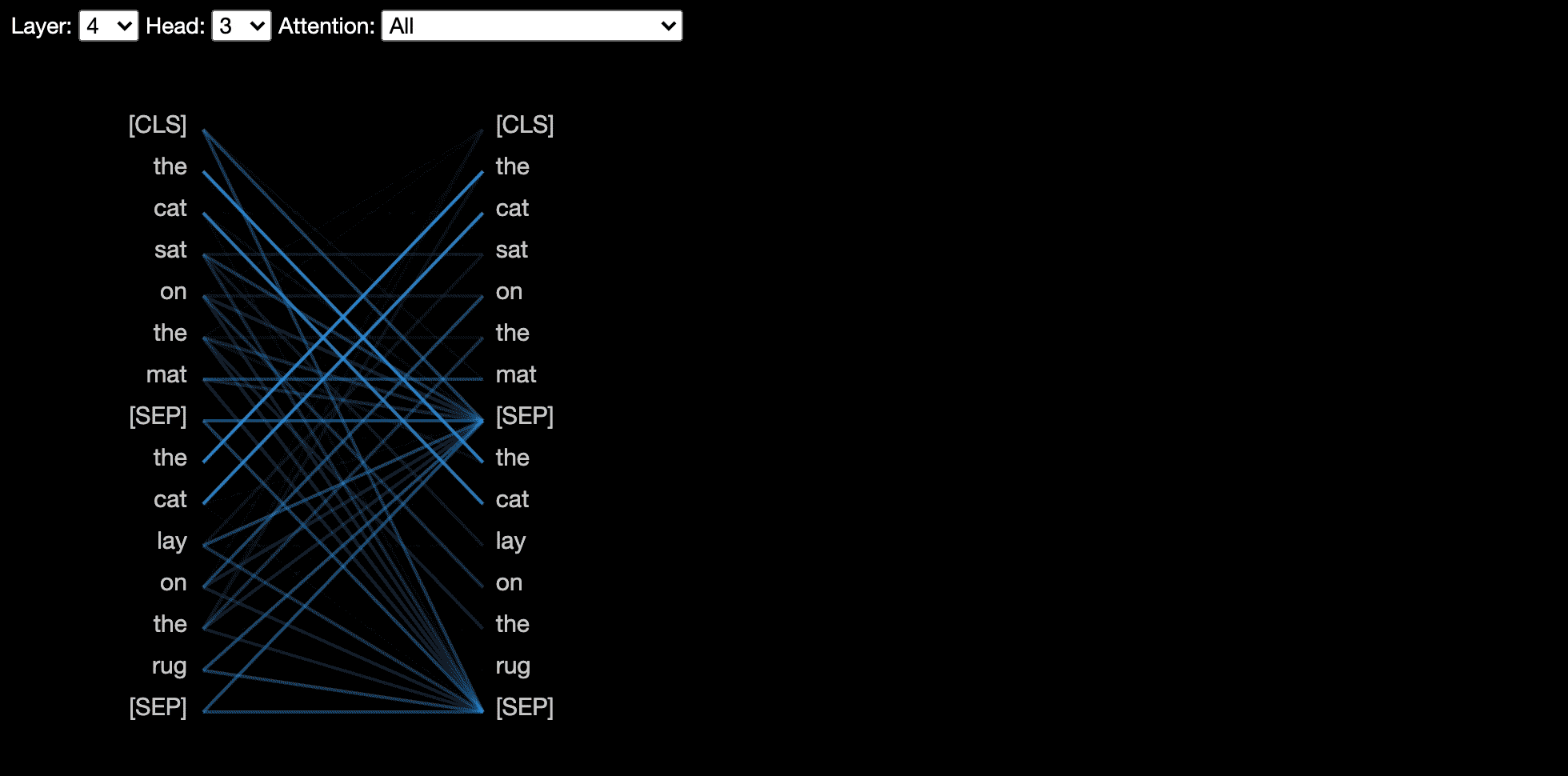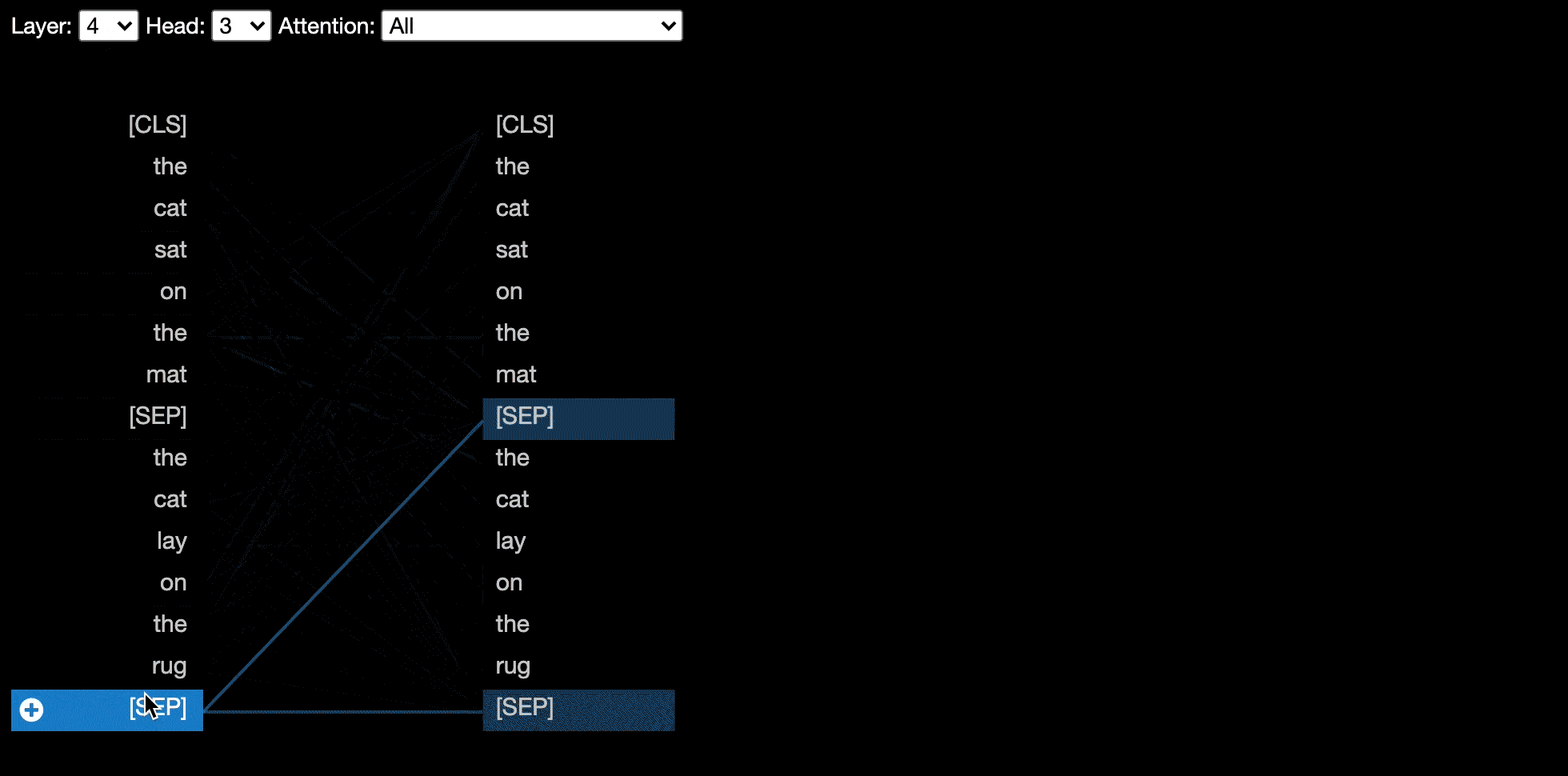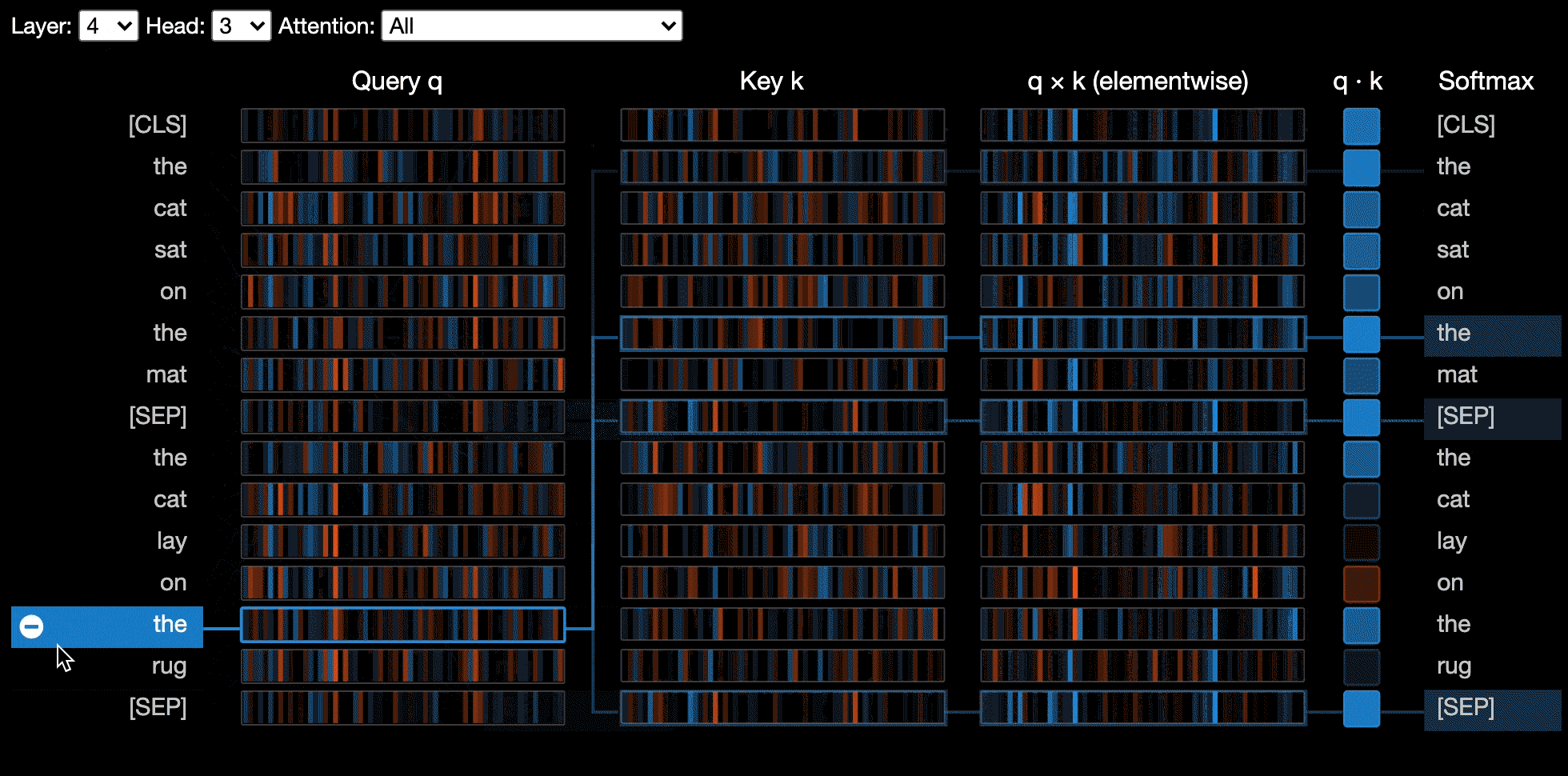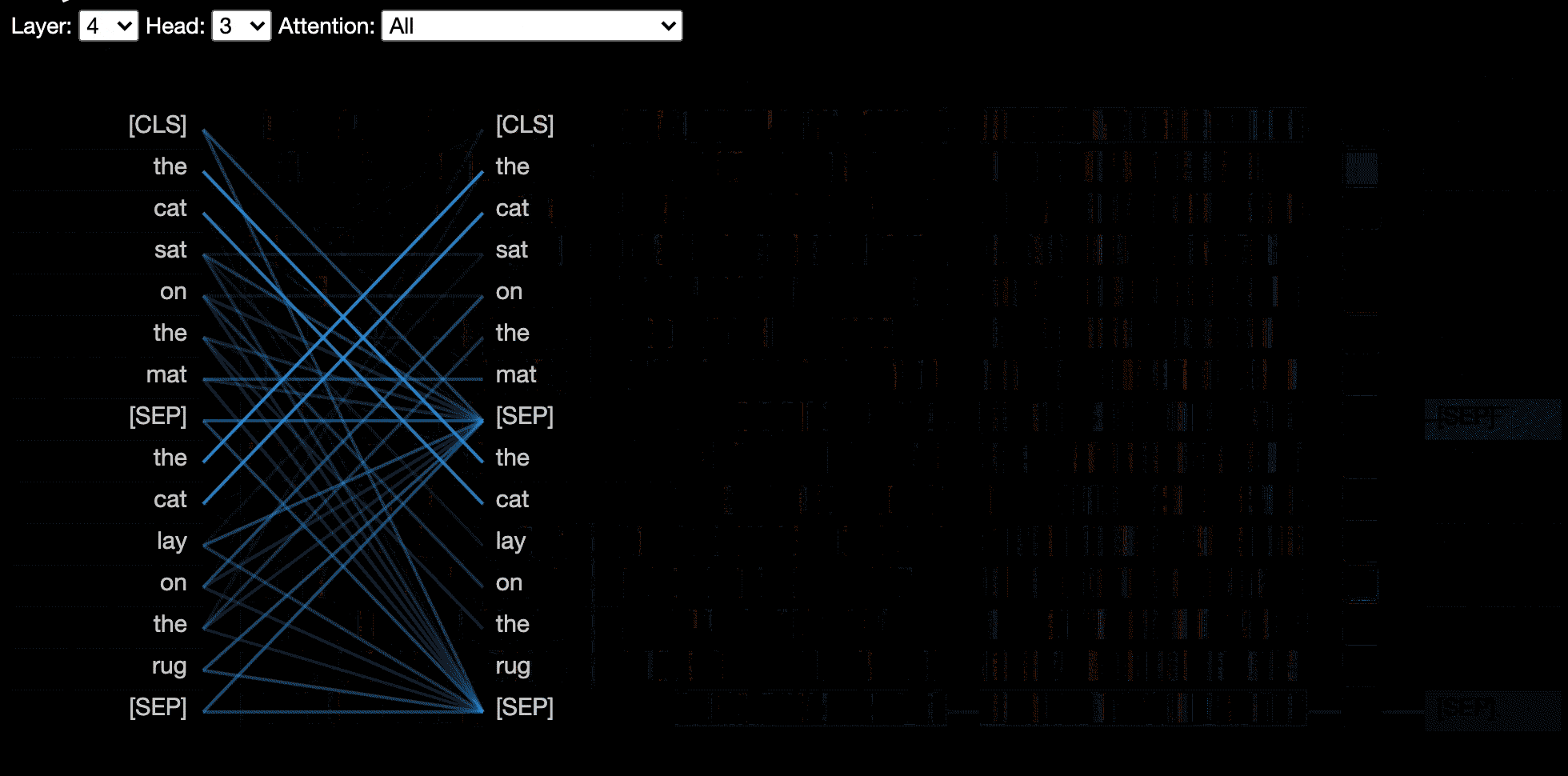
La vista visualiza la atención para uno o más cabezas de atención en la misma capa. Se basa en la excelente herramienta de visualización Tensor2Tensor de Llion Jones.
? Pruebe la vista en la cabeza en el tutorial de Colab interactivo (todas las visualizaciones precargadas).
La vista del modelo muestra una vista de atención de pájaro en todas las capas y cabezas.
? Pruebe la vista del modelo en el tutorial de Colab interactivo (todas las visualizaciones precargadas).

La vista neurona visualiza las neuronas individuales en la consulta y los vectores clave y muestra cómo se usan para calcular la atención.
? Pruebe la vista Neuron en el tutorial de Colab interactivo (todas las visualizaciones precargadas).
Desde la línea de comando:
pip install bertvizTambién debe tener instalados Jupyter Notebook y IpyWidgets:
pip install jupyterlab
pip install ipywidgets(Si se encuentra con algún problema para instalar Jupyter o IpyWidgets, consulte la documentación aquí y aquí).
Para crear un nuevo cuaderno Jupyter, simplemente ejecute:
jupyter notebook Luego haga clic New y seleccione Python 3 (ipykernel) si se le solicita.
Para ejecutar en Colab, simplemente agregue la siguiente celda al comienzo de su cuaderno de Colab:
!pip install bertviz
Ejecute el siguiente código para cargar el modelo xtremedistil-l12-h384-uncased y mostrarlo en la vista del modelo:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewLa visualización puede tardar unos segundos en cargarse. Siéntase libre de experimentar con diferentes textos y modelos de entrada. Consulte la documentación para casos de uso adicionales y ejemplos, por ejemplo, modelos de codificadores codificadores.
También puede ejecutar cualquiera de los cuadernos de muestra incluidos con BertViz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookEcha un vistazo al tutorial interactivo de Colab para obtener más información sobre Bertviz y probar la herramienta. Nota : Todas las visualizaciones están precargadas, por lo que no es necesario ejecutar ninguna celda.
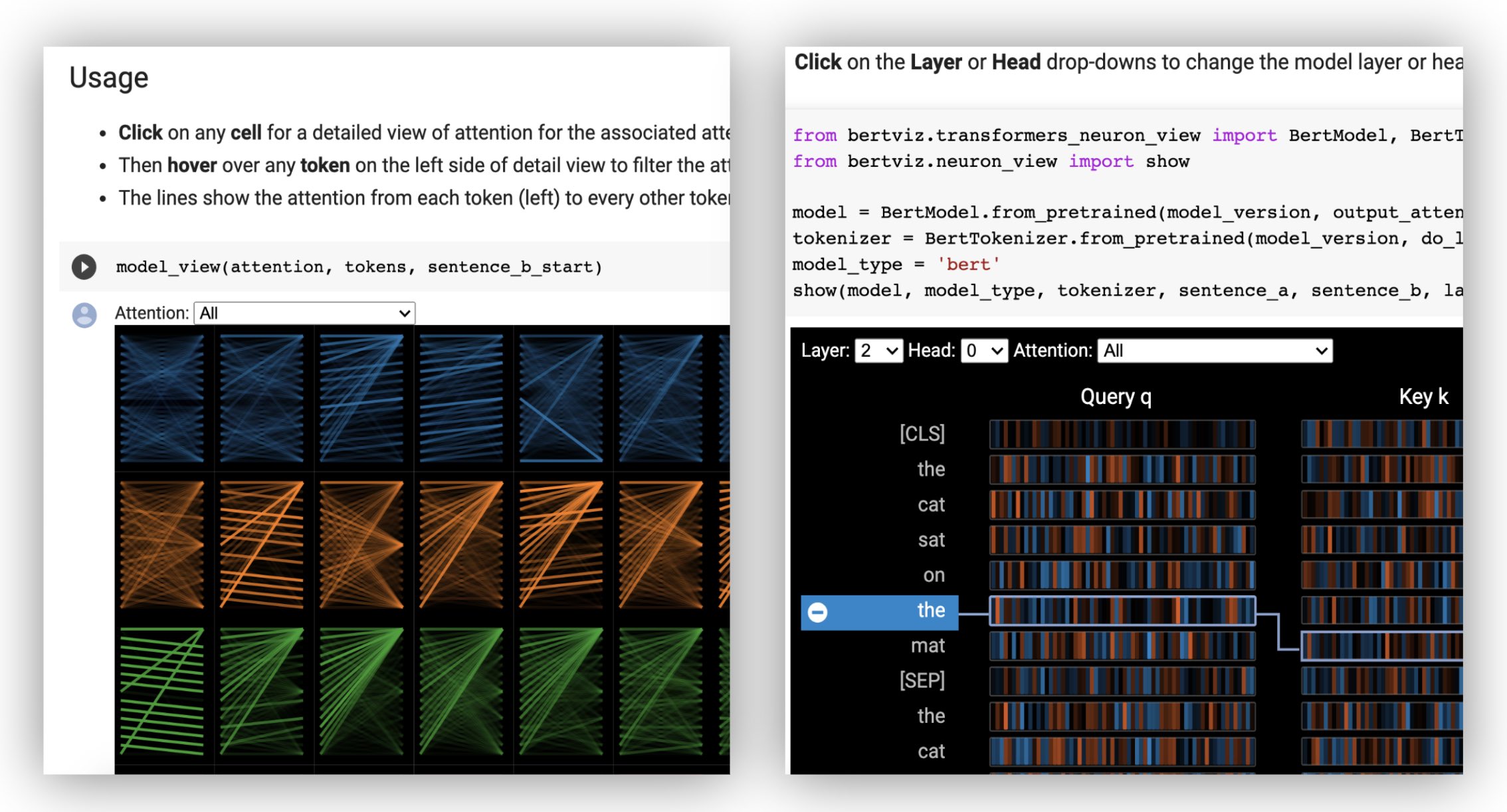
Primero cargue un modelo de cara de abrazo, ya sea un modelo previamente capacitado como se muestra a continuación, o su propio modelo ajustado. Asegúrese de establecer output_attentions=True .
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )Luego prepare entradas y calcule la atención:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) Finalmente, muestre los pesos de atención utilizando las funciones head_view o model_view :
from bertviz import head_view
head_view ( attention , tokens )Ejemplos : Distilbert (Model View Notebook, Notebook View Head)
Para obtener una API completa, consulte el código fuente para la vista de cabeza o la vista del modelo.
La vista de la neurona se invoca de manera diferente a la vista de cabeza o la vista del modelo, debido a que requiere acceso a la consulta/vectores clave del modelo, que no se devuelven a través de la API de Huggingface. Actualmente está limitado a versiones personalizadas de Bert, GPT-2 y Roberta incluidos con Bertviz.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )Ejemplos : Bert (cuaderno, Colab) • GPT-2 (cuaderno, Colab) • Roberta (cuaderno)
Para una API completa, consulte la fuente.
La vista de cabeza y la vista de modelo de soporte modelos de codificadores codificadores.
Primero, cargue un modelo de codificador del codificador:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )Luego prepare las entradas y calcule la atención:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) Finalmente, muestre la visualización utilizando head_view o model_view .
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) Puede seleccionar Encoder , Decoder o Cross la atención del menú desplegable en la esquina superior izquierda de la visualización.
Ejemplos : Marianmt (cuaderno) • Bart (cuaderno)
Para obtener una API completa, consulte el código fuente para la vista de cabeza o la vista del modelo.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop La vista del modelo y la vista de neuronas admiten modos oscuros (predeterminados) y de luz. Puede configurar el modo usando el parámetro display_mode :
model_view ( attention , tokens , display_mode = "light" ) Para mejorar la capacidad de respuesta de la herramienta al visualizar modelos o entradas más grandes, puede establecer el parámetro include_layers para restringir la visualización a un subconjunto de capas (indexada por cero). Esta opción está disponible en la vista Head y la vista de modelo.
Ejemplo: Vista de modelo Render con solo capas 5 y 6 mostradas
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) Para la vista del modelo, también puede restringir la visualización a un subconjunto de cabezales de atención (indexados por cero) estableciendo el parámetro include_heads .
En la vista de la cabeza, puede elegir una layer y colección específicas de heads como selección predeterminada cuando la visualización primero presenta. NOTA: Esto es diferente del parámetro include_heads / include_layers (arriba), que elimina las capas y cabezas de la visualización por completo.
Ejemplo: Renderiza la vista de la cabeza con la capa 2 y las cabezas 3 y 5 preseleccionadas
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) También puede pre-seleccionar una layer específica y un solo head para la vista de neuronas.
Algunos modelos, por ejemplo, Bert, aceptan un par de oraciones como entrada. Bertviz opcionalmente admite un menú desplegable que permite al usuario filtrar la atención en función de la oración en las que se encuentran los tokens, por ejemplo, solo muestra atención entre los tokens en la primera oración y los tokens en la segunda oración.
Para habilitar esta característica al invocar las funciones head_view o model_view , establezca el parámetro sentence_b_start en el índice de inicio de la segunda oración. Tenga en cuenta que el método para calcular este índice dependerá del modelo.
Ejemplo (Bert):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) Para habilitar esta opción en la vista Neuron, simplemente establezca los parámetros de sentence_a y sentence_b en neuron_view.show() .
El soporte para recuperar las representaciones HTML generadas se ha agregado a head_view, model_view y neuron_view.
Configuración del parámetro 'HTML_ACTION' en 'return' hará que la función de la función devuelva un solo objeto HTML Python que se pueda procesar más. Recuerde que puede acceder a la fuente HTML utilizando el atributo de datos de un objeto Python HTML.
El comportamiento predeterminado para 'html_action' es 'ver', que mostrará la visualización pero no devolverá el objeto HTML.
Esta funcionalidad es útil si necesita:
Ejemplo (vistas de cabeza y modelo):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )Ejemplo (vista neuronal):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) La vista de cabeza y la vista del modelo pueden usarse para visualizar la autoatición para cualquier modelo de transformador estándar, siempre que los pesos de atención estén disponibles y sigan el formato especificado en head_view y model_view (que es el formato devuelto de los modelos de Huggingface). En algunos casos, los puntos de control TensorFlow se pueden cargar como modelos Huggingface como se describe en los documentos de Huggingface.
include_layers , como se describió anteriormente.include_layers , como se describió anteriormente.transformers_neuron_view ), que solo se ha realizado para estos tres modelos. Una visualización multiescala de atención en el modelo de transformador (ACL System Demosations 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Jesse Vig
Agradecemos a los autores de los siguientes proyectos, que se incorporan a este repositorio:
Este proyecto tiene licencia bajo la licencia Apache 2.0; consulte el archivo de licencia para obtener más detalles.


