bertviz
v1.4.0
Bertviz ist ein interaktives Werkzeug zur Visualisierung der Aufmerksamkeit in Transformatorsprachenmodellen wie Bert, GPT2 oder T5. Es kann in einem Jupyter- oder Colab -Notizbuch über eine einfache Python -API ausgeführt werden, die die meisten Umarmungsgesichtsmodelle unterstützt. Bertviz erweitert das Tensor2tensor -Visualisierungstool von Llion Jones und bietet mehrere Ansichten, die jeweils ein einzigartiges Objektiv in den Aufmerksamkeitsmechanismus bieten.
Erhalten Sie Updates für diese und verwandte Projekte auf Twitter.
Die Kopfansicht visualisiert die Aufmerksamkeit für einen oder mehrere Aufmerksamkeitsköpfe in derselben Ebene. Es basiert auf dem exzellenten Tensor2tensor -Visualisierungstool von Llion Jones.
? Probieren Sie die Kopfansicht im interaktiven Colab-Tutorial aus (alle Visualisierungen vorbelastet).
Die Modellansicht zeigt eine Vogelperspektive der Aufmerksamkeit über alle Schichten und Köpfe.
? Probieren Sie die Modellansicht im interaktiven Colab-Tutorial aus (alle Visualisierungen vorbelastet).

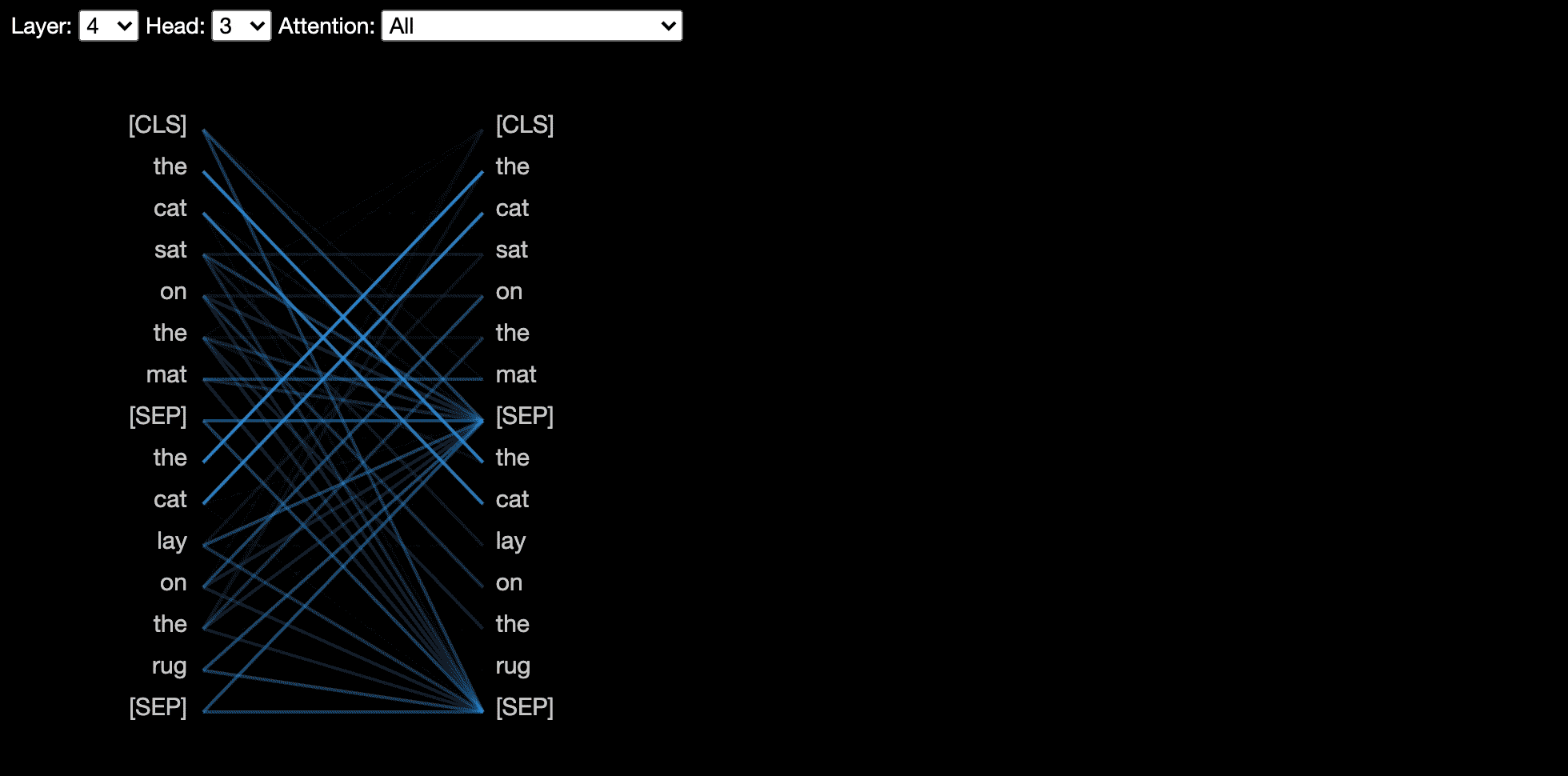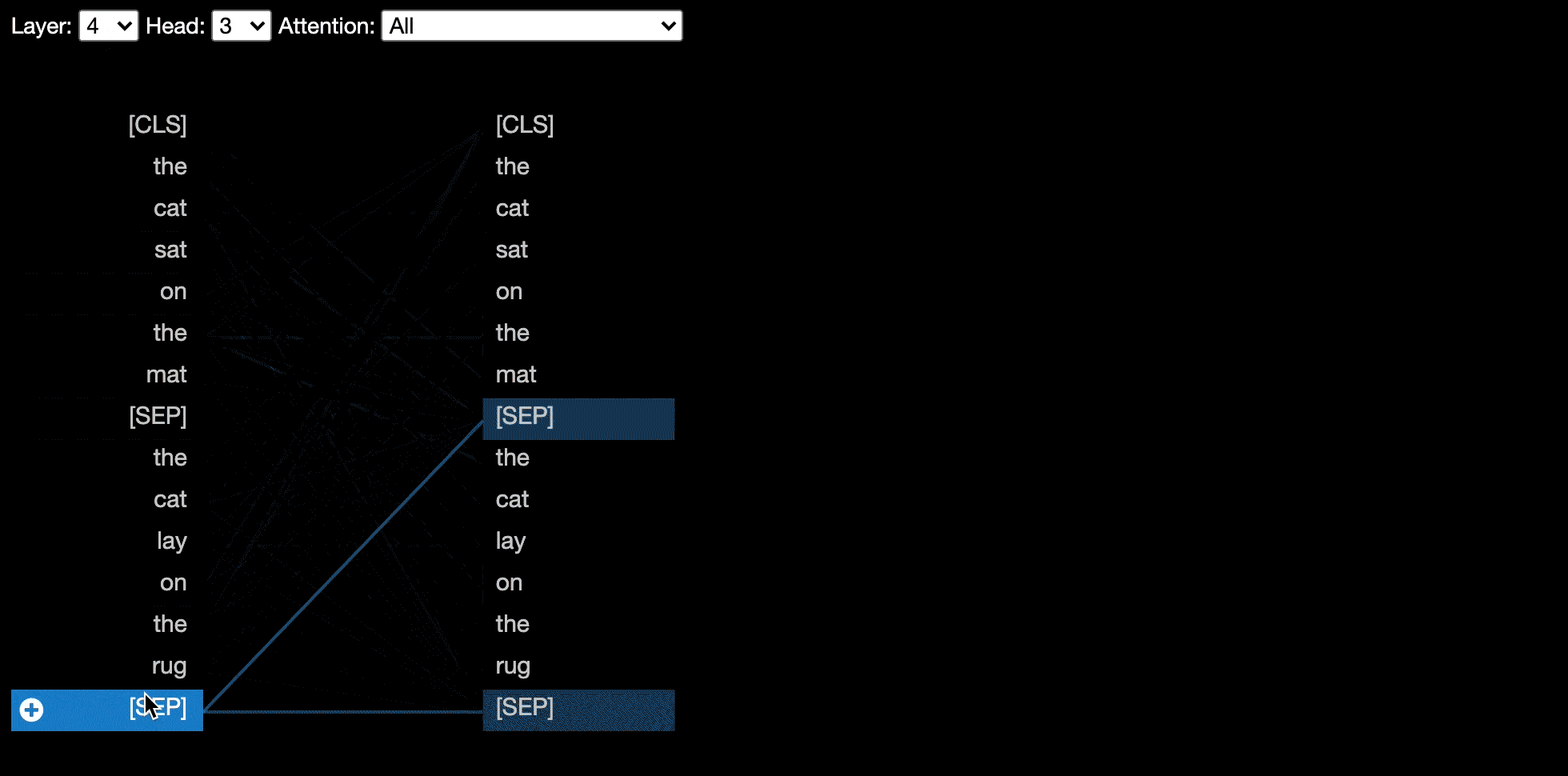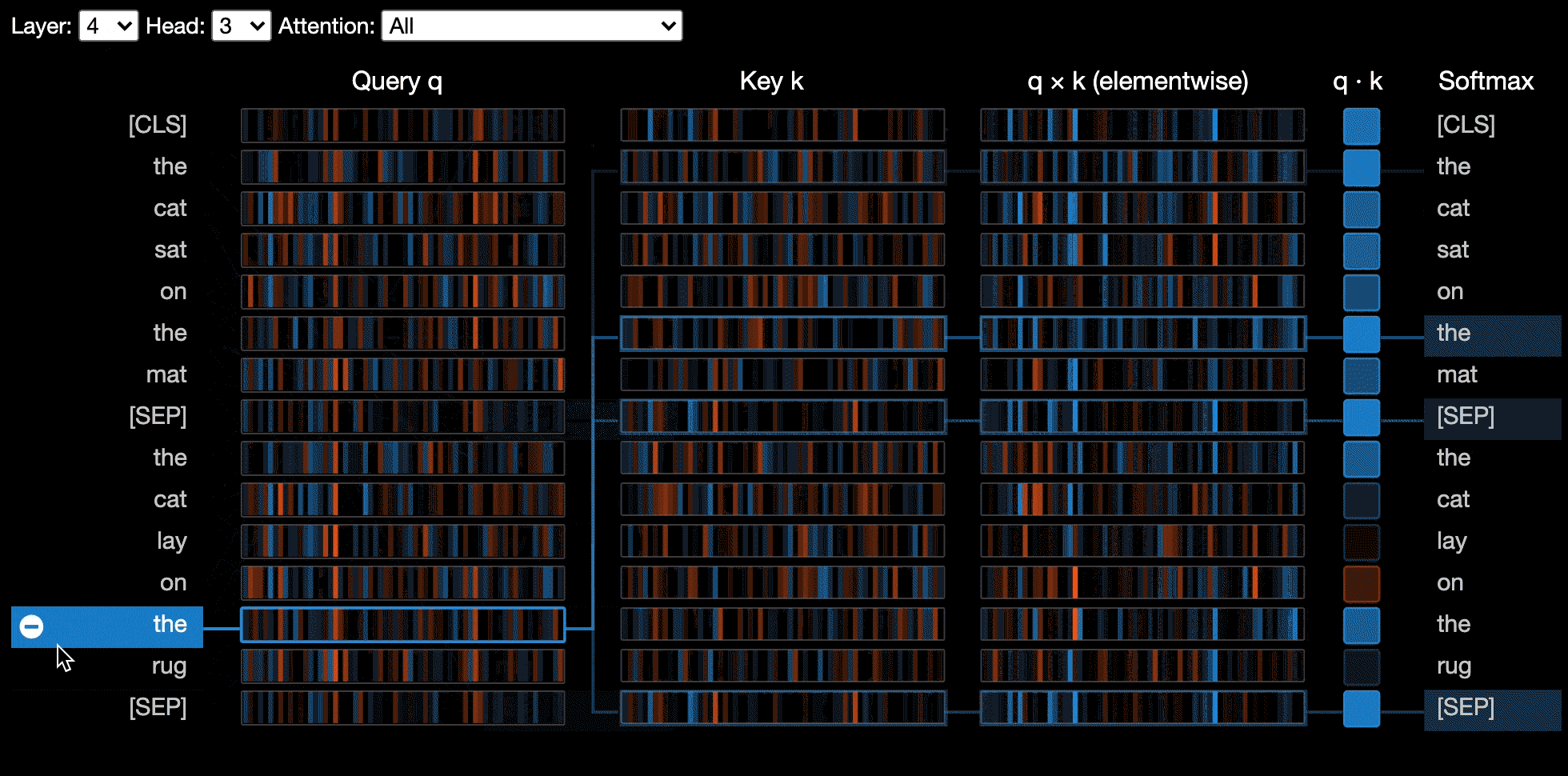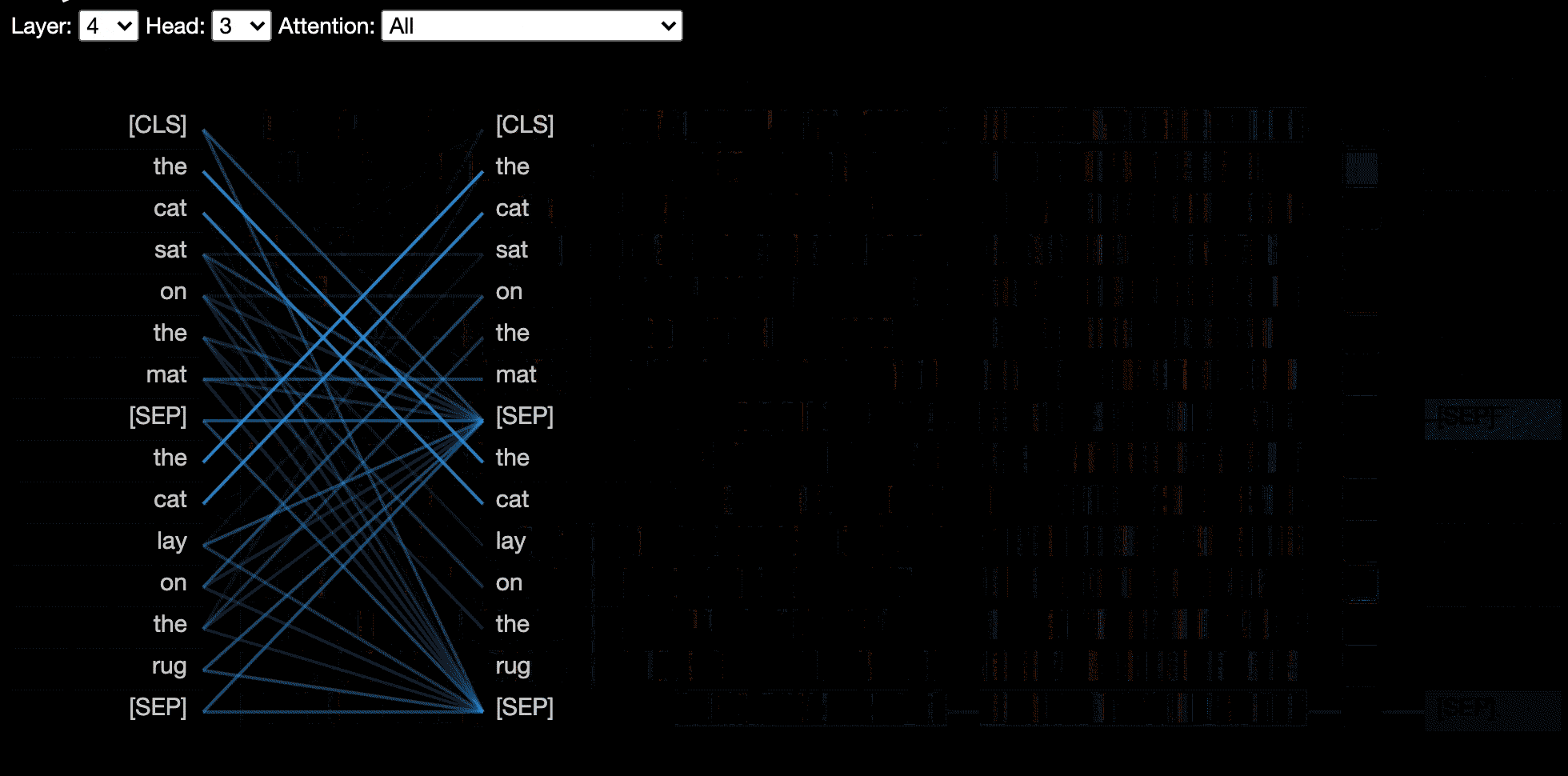
Die Neuronansicht visualisiert einzelne Neuronen in der Abfrage- und Schlüsselvektoren und zeigt, wie sie zur Berechnung der Aufmerksamkeit verwendet werden.
? Probieren Sie die Neuron-Sicht im interaktiven Colab-Tutorial aus (alle Visualisierungen vorgeladen).
Aus der Befehlszeile:
pip install bertvizSie müssen auch Jupyter Notebook und IpyWidgets installiert haben:
pip install jupyterlab
pip install ipywidgets(Wenn Sie Probleme mit der Installation von Jupyter oder IpyWidgets aufnehmen, wenden Sie sich hier und hier an die Dokumentation.)
Um ein neues Jupyter -Notizbuch zu erstellen, rennen Sie einfach:
jupyter notebook Klicken Sie dann auf New und wählen Sie Python 3 (ipykernel) wenn Sie aufgefordert werden.
Um in Colab zu laufen, fügen Sie einfach die folgende Zelle zu Beginn Ihres Colab -Notizbuchs hinzu:
!pip install bertviz
Führen Sie den folgenden Code aus, um das xtremedistil-l12-h384-uncased Modell zu laden und in der Modellansicht anzuzeigen:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewDie Visualisierung kann einige Sekunden dauern, um zu laden. Fühlen Sie sich frei, mit verschiedenen Eingangstexten und Modellen zu experimentieren. Weitere Anwendungsfälle und Beispiele finden Sie unter Dokumentation, z. B. Encoder-Decoder-Modelle.
Sie können auch eines der in Bertviz enthaltenen Beispielnotenbücher ausführen:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookSchauen Sie sich das interaktive Colab -Tutorial an, um mehr über Bertviz zu erfahren und das Tool auszuprobieren. HINWEIS : Alle Visualisierungen sind vorinstalliert, sodass keine Zellen ausgeführt werden müssen.
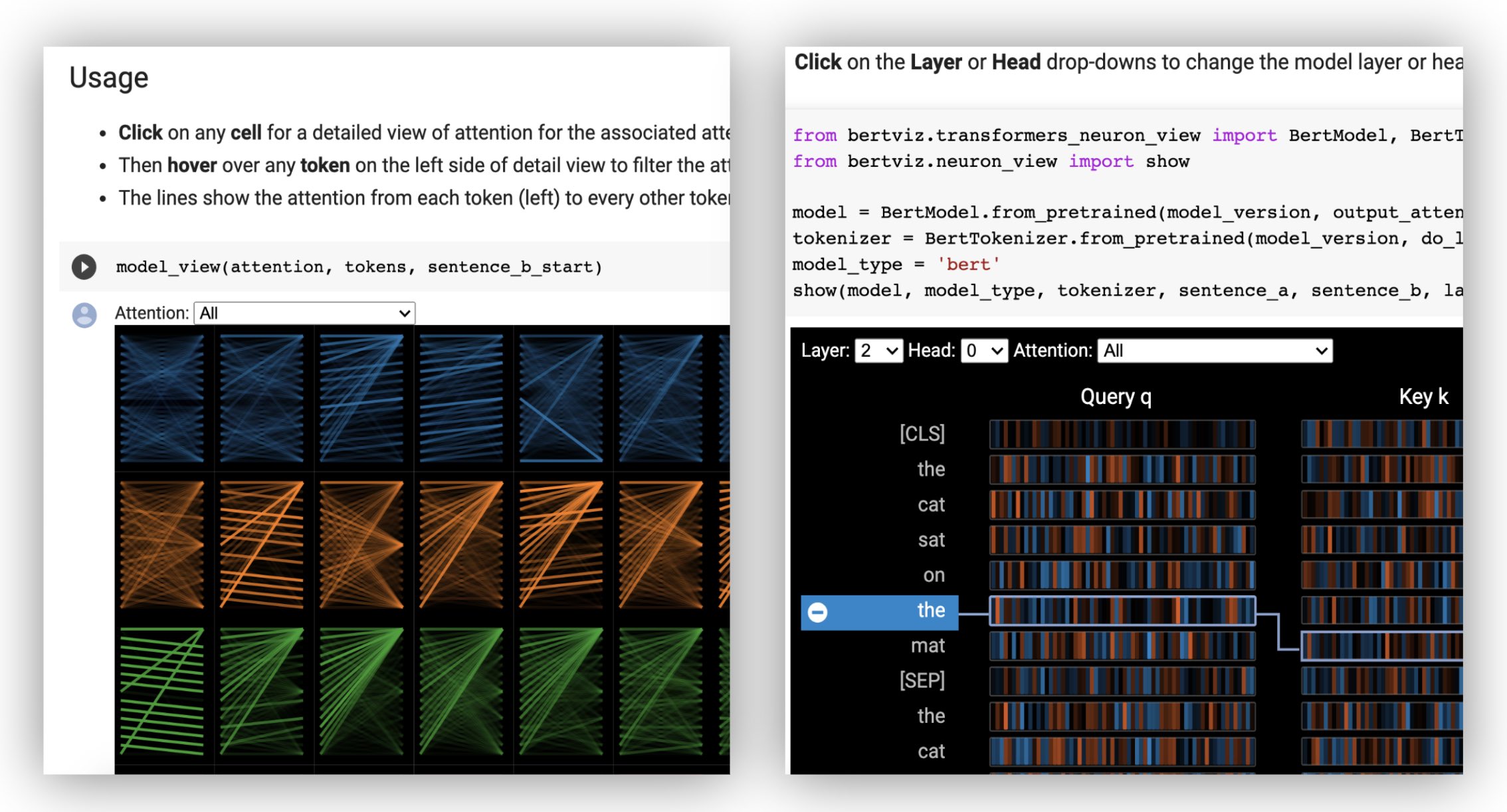
Laden Sie zuerst ein Umarmungsface-Modell, entweder ein vorgebildetes Modell wie unten gezeigt oder Ihr eigenes fein abgestimmeltes Modell. Stellen Sie sicher, dass Sie output_attentions=True festlegen.
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )Erstellen Sie dann Eingänge und berechnen Sie die Aufmerksamkeit:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) Schließlich zeigen Sie die Aufmerksamkeitsgewichte mit den Funktionen head_view oder model_view an:
from bertviz import head_view
head_view ( attention , tokens )Beispiele : Distilbert (Modellansicht Notebook, Kopfansicht Notebook)
Eine vollständige API finden Sie im Quellcode für die Kopfansicht oder die Modellansicht.
Die Neuronansicht wird anders als die Kopfansicht oder die Modellansicht aufgerufen, da der Zugriff auf die Abfrage/die wichtigsten Vektoren des Modells, die nicht über die Huggingface -API zurückgegeben werden, erforderlich sind. Es ist derzeit auf benutzerdefinierte Versionen von Bert, GPT-2 und Roberta beschränkt, die Bertviz enthalten sind.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )Beispiele : Bert (Notebook, Colab) • GPT-2 (Notebook, Colab) • Roberta (Notebook)
Für die vollständige API finden Sie die Quelle.
Die Kopfansicht und die Modellansicht unterstützen beide Encoder-Decoder-Modelle.
Laden Sie zunächst ein Encoder-Decoder-Modell:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )Bereiten Sie dann die Eingänge vor und berechnen Sie die Aufmerksamkeit:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) Zuletzt die Visualisierung entweder head_view oder model_view anzeigen.
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) Sie können Encoder , Decoder oder Cross der Aufmerksamkeit aus der Dropdown in der oberen linken Ecke der Visualisierung auswählen.
Beispiele : Marianmt (Notebook) • BART (Notebook)
Eine vollständige API finden Sie im Quellcode für die Kopfansicht oder die Modellansicht.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop Die Modellansicht und die Neuronansicht unterstützen Dunkel- (Standard-) und Lichtmodi. Sie können den Modus mit dem Parameter display_mode festlegen:
model_view ( attention , tokens , display_mode = "light" ) Um die Reaktionsfähigkeit des Tools bei der Visualisierung größerer Modelle oder Eingaben zu verbessern, können Sie den Parameter include_layers festlegen, um die Visualisierung auf eine Teilmenge von Schichten (null-indexiert) zu beschränken. Diese Option ist in der Kopfansicht und der Modellansicht erhältlich.
Beispiel: Modellansicht mit nur Schichten 5 und 6 angezeigt
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) Für die Modellansicht können Sie die Visualisierung auch auf eine Teilmenge von Aufmerksamkeitsköpfen (null-iNdexed) beschränken, indem Sie den Parameter include_heads festlegen.
In der Kopfansicht können Sie eine bestimmte layer und Sammlung von heads als Standardauswahl auswählen, wenn die Visualisierung zum ersten Mal wiedergegeben wird. HINWEIS: Dies unterscheidet sich von dem Parameter include_heads / include_layers (oben), der Schichten und Köpfe aus der Visualisierung vollständig entfernt.
Beispiel: Die Kopfansicht mit Schicht 2 und den Köpfen 3 und 5 vorgewählt
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) Sie können auch eine bestimmte layer und einen einzelnen head für die Neuronansicht vorab auswählen.
Einige Modelle, z. B. Bert, akzeptieren ein Paar Sätze als Eingabe. Bertviz unterstützt optional ein Dropdown-Menü, mit dem der Benutzer die Aufmerksamkeit auf den Satz der Token eröffnet wird.
Um diese Funktion beim Aufrufen der Funktionen head_view oder model_view zu aktivieren, setzen Sie den Parameter sentence_b_start auf den Startindex des zweiten Satzes. Beachten Sie, dass die Methode zur Berechnung dieses Index vom Modell abhängt.
Beispiel (Bert):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) Um diese Option in der Neuron -Ansicht zu aktivieren, legen Sie einfach die Parameter von sentence_a und sentence_b in neuron_view.show() fest.
Unterstützung beim Abrufen der generierten HTML -Darstellungen wurde zu head_view, model_view und neuron_view hinzugefügt.
Durch das Einstellen des Parameters "html_action" in "Rückgabe" wird der Funktionsaufruf ein einzelnes HTML -Python -Objekt zurückgegeben, das weiter verarbeitet werden kann. Denken Sie daran, Sie können mit dem Datenattribut eines Python -HTML -Objekts auf die HTML -Quelle zugreifen.
Das Standardverhalten für 'html_action' lautet 'Ansicht', wodurch die Visualisierung angezeigt wird, das HTML -Objekt jedoch nicht zurückgibt.
Diese Funktionalität ist nützlich, wenn Sie:
Beispiel (Kopf- und Modellansichten):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )Beispiel (Neuron View):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) Die Kopfansicht und die Modellansicht können verwendet werden, um die Selbstbekämpfung für jedes Standardtransformatormodell zu visualisieren, solange die Aufmerksamkeitsgewichte verfügbar sind und dem in head_view und model_view angegebenen Format folgen (das Format, das aus den Modellen der Umarmung zurückgegeben wird). In einigen Fällen können TensorFlow -Checkpoints als Harmgingface -Modelle geladen werden, wie in den Dokumenten von Suggingface -Dokumenten beschrieben.
include_layers wie oben beschrieben eingestellt wird.include_layers wie oben beschrieben eingestellt wird.transformers_neuron_view -Verzeichnis), das nur für diese drei Modelle durchgeführt wurde. Eine multiskalige Visualisierung der Aufmerksamkeit im Transformatormodell (ACL -Systemdemonstrationen 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Jesse Vig
Wir danken den Autoren der folgenden Projekte, die in dieses Repo aufgenommen werden:
Dieses Projekt ist unter der Lizenz von Apache 2.0 lizenziert - finden Sie in der Lizenzdatei für Details


