bertviz
v1.4.0
Bertviz est un outil interactif pour visualiser l'attention dans les modèles de langage transformateur tels que Bert, GPT2 ou T5. Il peut être exécuté dans un cahier Jupyter ou Colab via une simple API Python qui prend en charge la plupart des modèles HuggingFace. Bertviz étend l'outil de visualisation tensor2tenseurs par Llion Jones, offrant plusieurs vues qui offrent chacune une lentille unique dans le mécanisme d'attention.
Obtenez des mises à jour pour cela et les projets connexes sur Twitter.
La vue de tête visualise l'attention pour une ou plusieurs têtes d'attention dans la même couche. Il est basé sur l'excellent outil de visualisation Tensor2Stenseurs par Llion Jones.
? Essayez la vue de tête dans le didacticiel interactif Colab (toutes les visualisations préchargées).
La vue du modèle montre une vue d'attention de l'attention sur toutes les couches et têtes.
? Essayez la vue du modèle dans le didacticiel interactif Colab (toutes les visualisations préchargées).

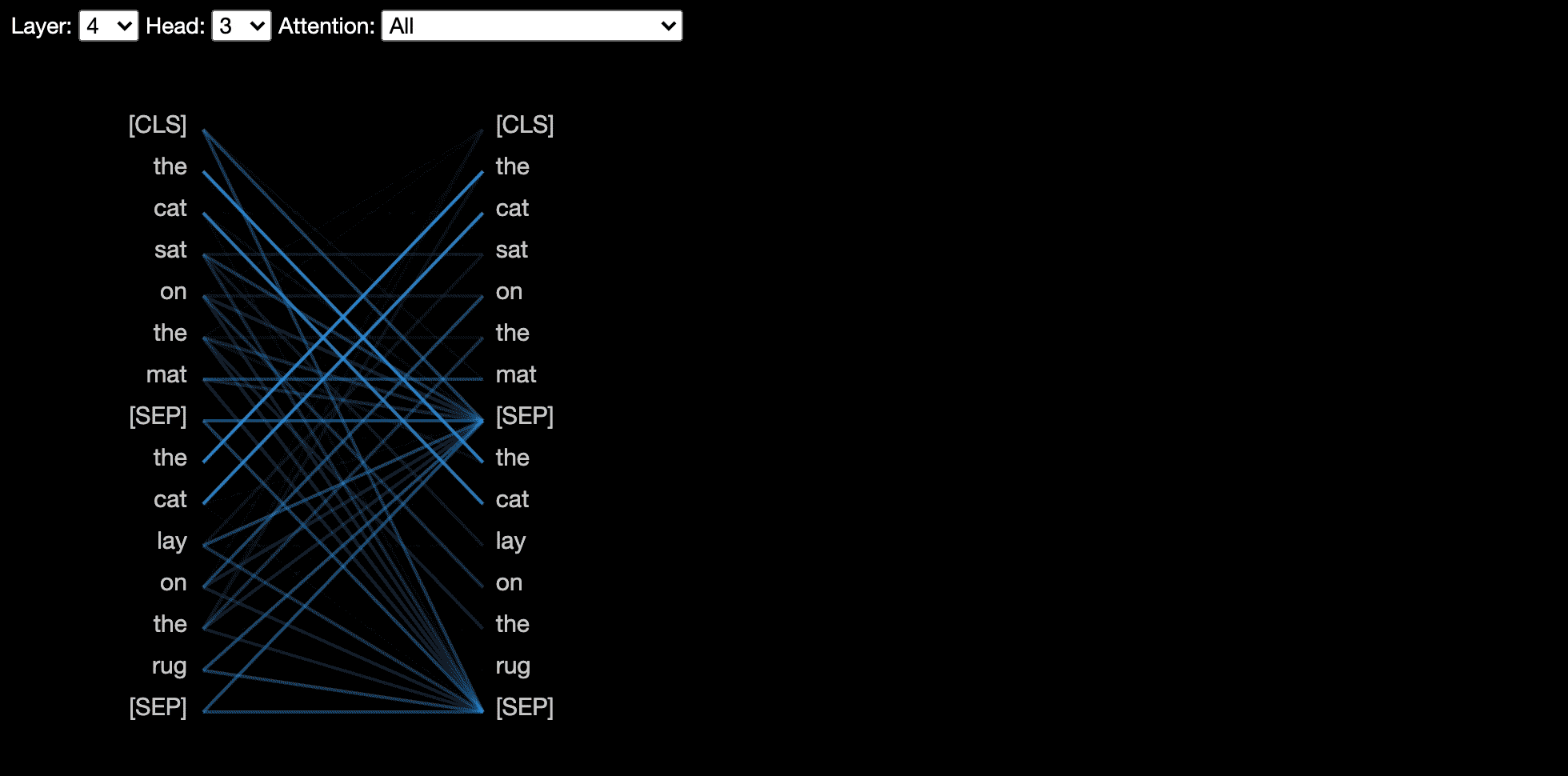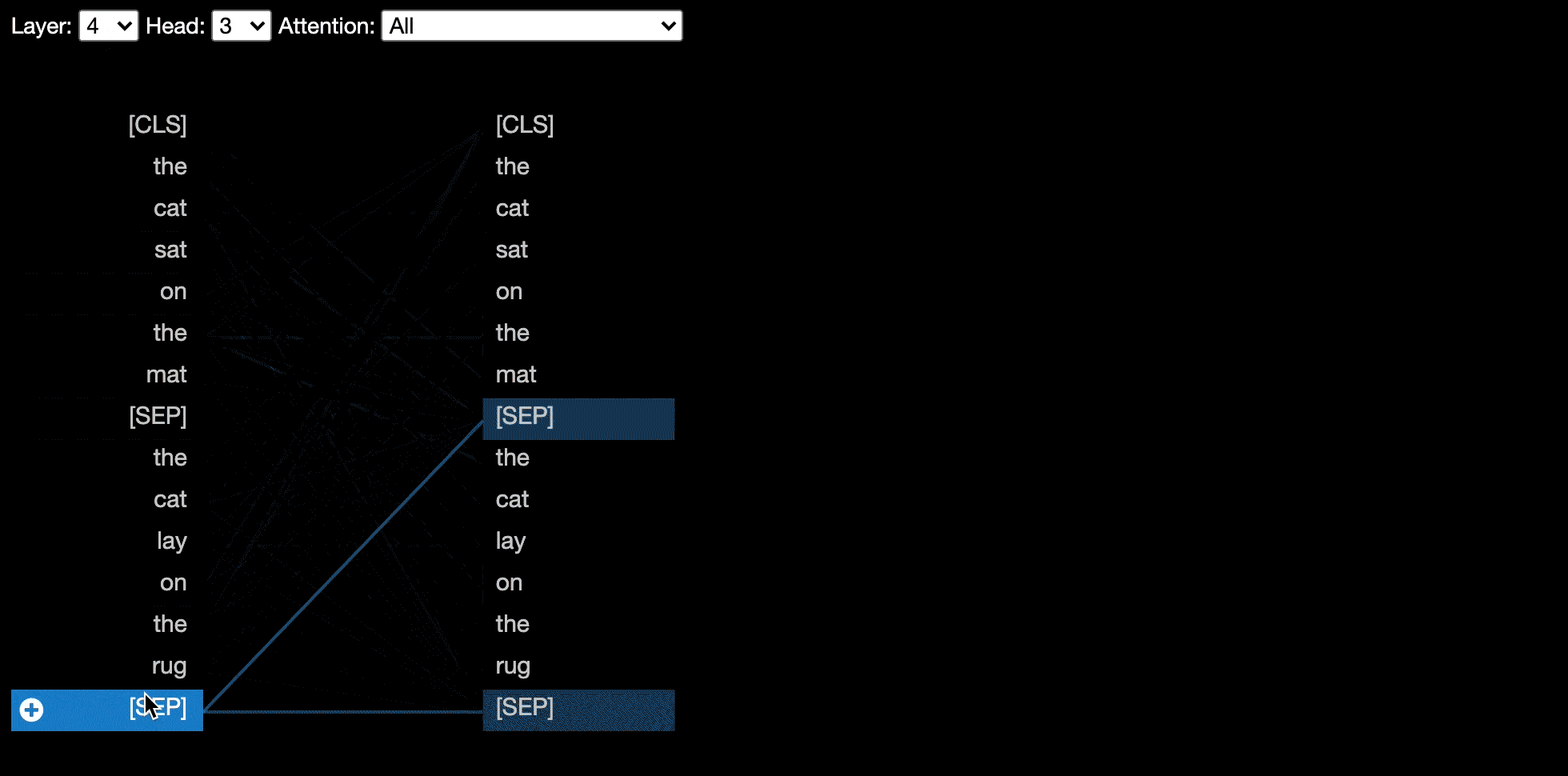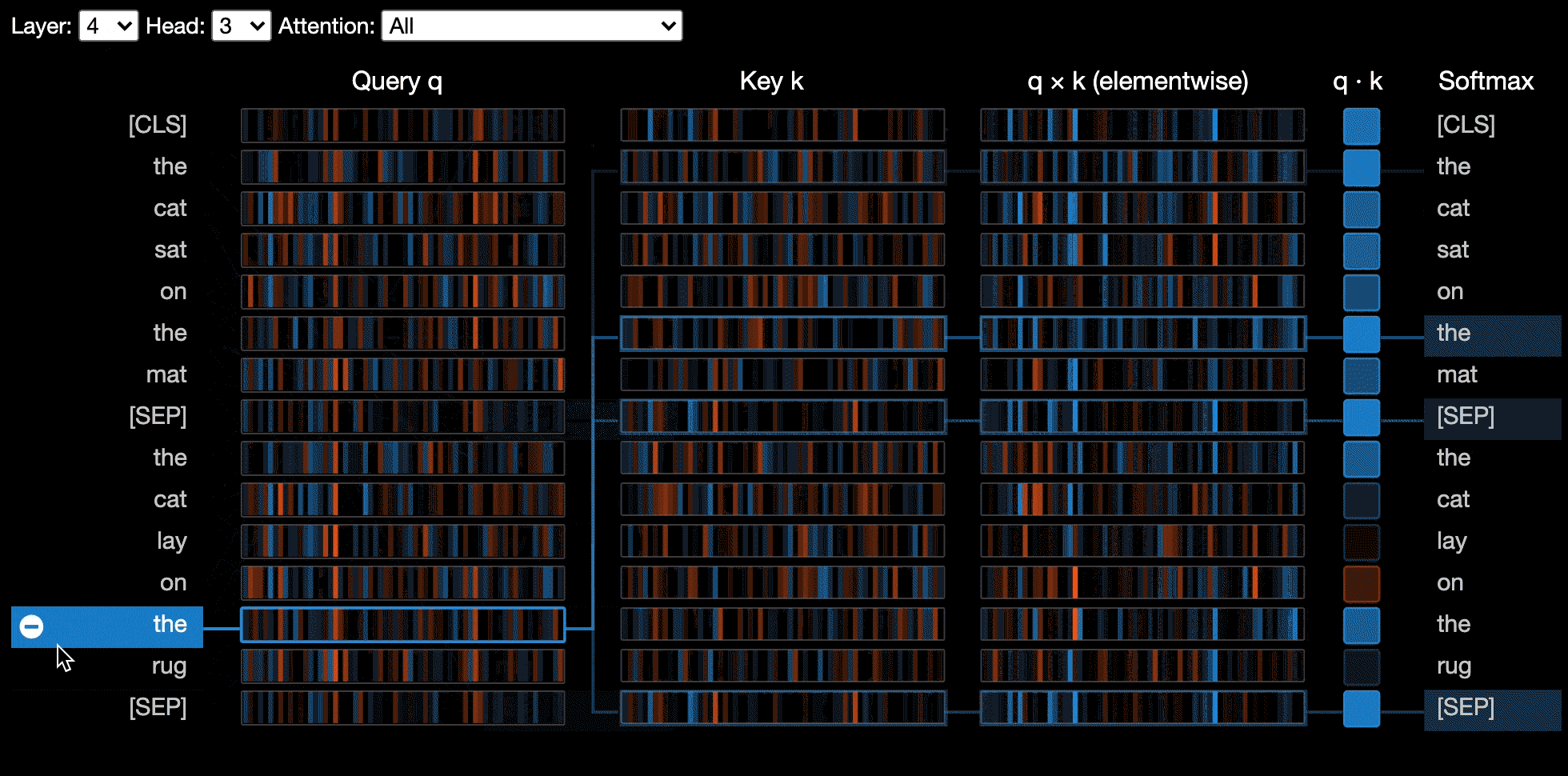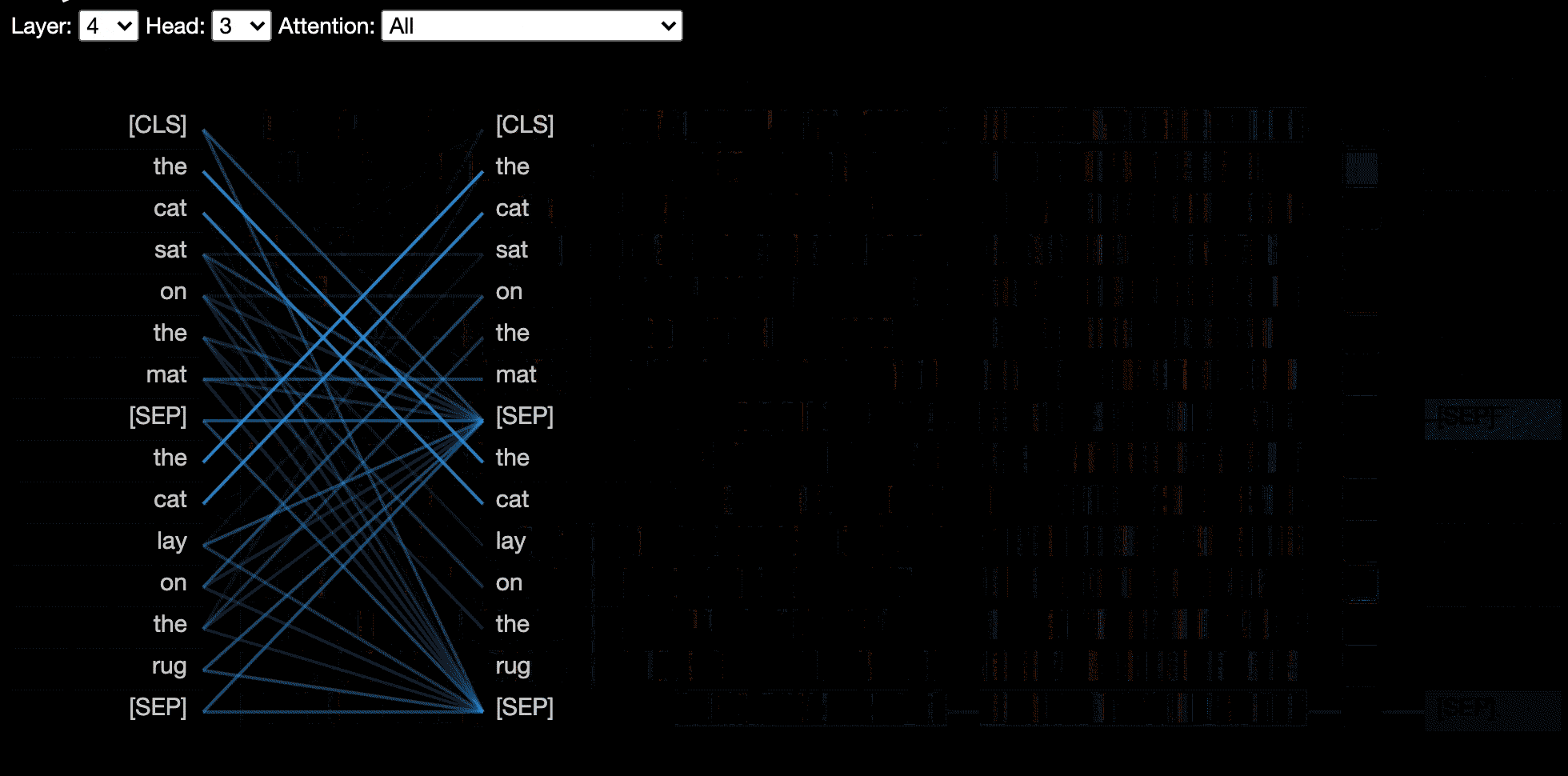
La vision des neurones visualise les neurones individuels dans la requête et les vecteurs clés et montre comment ils sont utilisés pour calculer l'attention.
? Essayez la vue des neurones dans le tutoriel interactif Colab (toutes les visualisations préchargées).
De la ligne de commande:
pip install bertvizVous devez également installer un cahier Jupyter et iPyWidgets:
pip install jupyterlab
pip install ipywidgets(Si vous rencontrez des problèmes pour installer Jupyter ou IpyWidget, consultez la documentation ici et ici.)
Pour créer un nouveau cahier Jupyter, exécutez simplement:
jupyter notebook Cliquez ensuite sur New et sélectionnez Python 3 (ipykernel) si vous êtes invité.
Pour fonctionner à Colab, ajoutez simplement la cellule suivante au début de votre cahier Colab:
!pip install bertviz
Exécutez le code suivant pour charger le modèle xtremedistil-l12-h384-uncased et l'afficher dans la vue du modèle:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewLa visualisation peut prendre quelques secondes à charger. N'hésitez pas à expérimenter différents textes et modèles d'entrée. Voir la documentation pour des cas d'utilisation supplémentaires et des exemples, par exemple, les modèles d'encodeur.
Vous pouvez également exécuter l'un des exemples de cahiers inclus avec Bertviz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookConsultez le tutoriel interactif Colab pour en savoir plus sur Bertviz et essayez l'outil. Remarque : Toutes les visualisations sont préchargées, il n'est donc pas nécessaire d'exécuter des cellules.
Chargez d'abord un modèle HuggingFace, soit un modèle pré-formé comme indiqué ci-dessous, soit votre propre modèle affiné. Assurez-vous de définir output_attentions=True .
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )Préparez ensuite les entrées et calculez l'attention:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) Enfin, affichez les poids d'attention à l'aide des fonctions head_view ou model_view :
from bertviz import head_view
head_view ( attention , tokens )Exemples : Distilbert (Notebook de vue du modèle, cahier de vue de tête)
Pour l'API complète, veuillez vous référer au code source de la vue de tête ou de la vue du modèle.
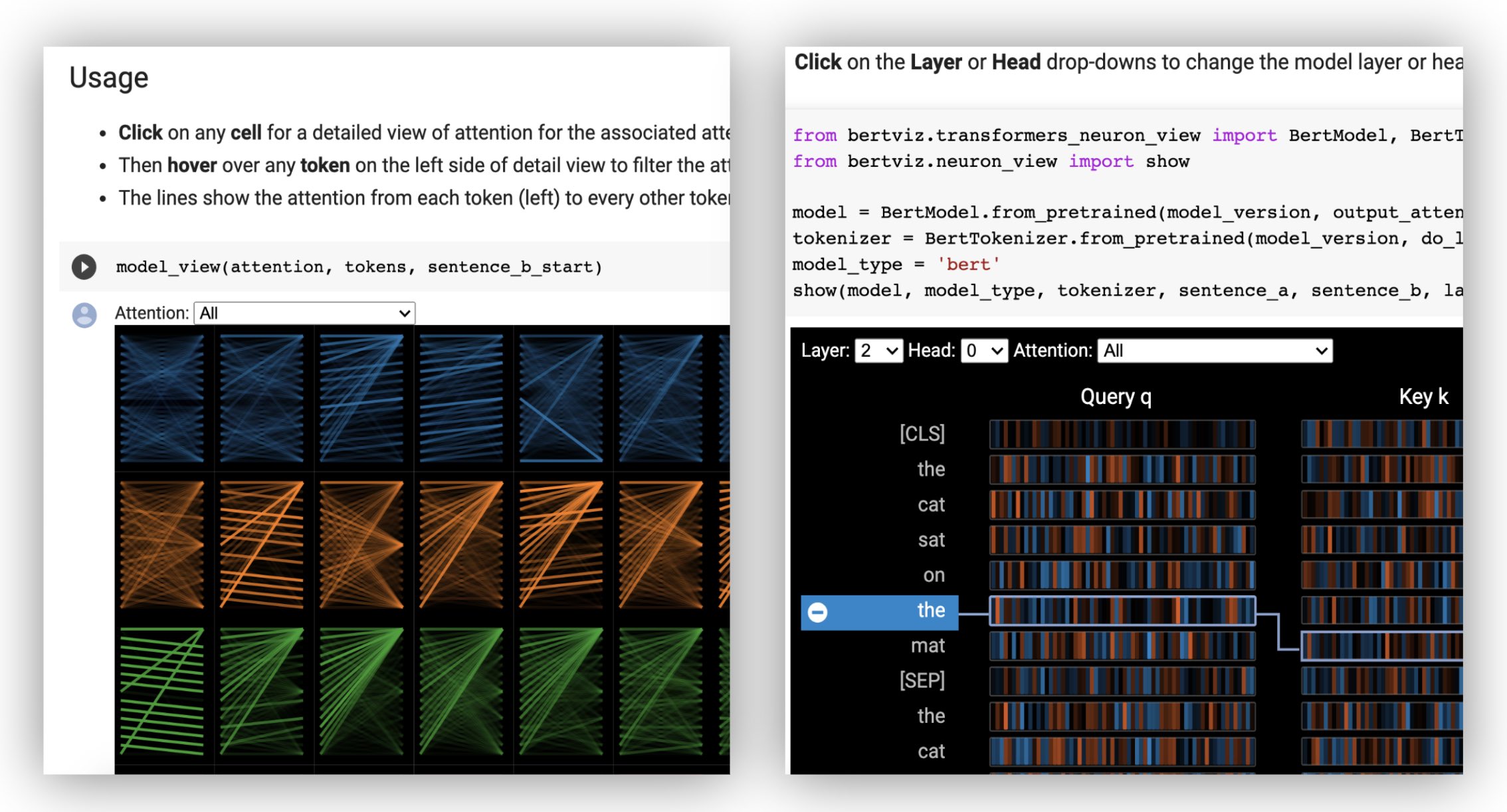
La vue des neurones est invoquée différemment de la vue de la tête ou de la vue du modèle, en raison de l'accès aux vecteurs de requête / clés du modèle, qui ne sont pas retournés via l'API HuggingFace. Il est actuellement limité aux versions personnalisées de Bert, GPT-2 et Roberta incluses avec Bertviz.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )Exemples : Bert (Notebook, Colab) • GPT-2 (Notebook, Colab) • Roberta (Notebook)
Pour une API complète, veuillez vous référer à la source.
La vue de tête et la vue du modèle prennent en charge les modèles d'encodeur-décodeur.
Tout d'abord, chargez un modèle d'encodeur-décodeur:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )Préparez ensuite les entrées et calculez l'attention:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) Enfin, affichez la visualisation à l'aide head_view ou model_view .
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) Vous pouvez sélectionner Encoder , Decoder ou l'attention Cross attention à partir de la liste déroulante dans le coin supérieur gauche de la visualisation.
Exemples : Marianmt (Notebook) • Bart (Notebook)
Pour l'API complète, veuillez vous référer au code source de la vue de tête ou de la vue du modèle.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop La vue du modèle et la vue des neurones prennent en charge les modes sombres (par défaut) et lumineux. Vous pouvez définir le mode à l'aide du paramètre display_mode :
model_view ( attention , tokens , display_mode = "light" ) Pour améliorer la réactivité de l'outil lors de la visualisation de modèles ou d'entrées plus grands, vous pouvez définir le paramètre include_layers pour restreindre la visualisation à un sous-ensemble de couches (indexé zéro). Cette option est disponible dans la vue de tête et la vue du modèle.
Exemple: Rendre la vue du modèle avec seulement les couches 5 et 6 affichées
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) Pour la vue du modèle, vous pouvez également restreindre la visualisation à un sous-ensemble de têtes d'attention (indexé zéro) en définissant le paramètre include_heads .
Dans la vue de la tête, vous pouvez choisir une layer et une collection spécifiques de heads comme sélection par défaut lorsque la visualisation rend pour la première fois. Remarque: Ceci est différent du paramètre include_heads / include_layers (ci-dessus), qui supprime complètement les couches et les têtes de la visualisation.
Exemple: Rendez la vue de la tête avec la couche 2 et les têtes 3 et 5 présélectionnées
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) Vous pouvez également présélectionner une layer spécifique et head unique pour la vue des neurones.
Certains modèles, par exemple Bert, acceptent une paire de phrases en entrée. Bertviz prend en charge éventuellement un menu déroulant qui permet à l'utilisateur de filtrer l'attention en fonction de la phrase dans laquelle les jetons se trouvent, par exemple, ne montrez que l'attention entre les jetons dans la première phrase et les jetons en deuxième phrase.
Pour activer cette fonctionnalité lors de l'invocation des fonctions head_view ou model_view , définissez le paramètre sentence_b_start dans l'index de démarrage de la deuxième phrase. Notez que la méthode de calcul de cet index dépendra du modèle.
Exemple (Bert):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) Pour activer cette option dans la vue des neurones, définissez simplement les paramètres sentence_a et sentence_b dans neuron_view.show() .
La prise en charge de la récupération des représentations HTML générées a été ajoutée à Head_View, Model_View et Neuron_View.
La définition du paramètre 'html_action' sur 'return' fera que l'appel de fonction renvoie un seul objet html python qui peut être traité davantage. N'oubliez pas que vous pouvez accéder à la source HTML à l'aide de l'attribut de données d'un objet HTML Python.
Le comportement par défaut pour «html_action» est «View», qui affichera la visualisation mais ne renverra pas l'objet HTML.
Cette fonctionnalité est utile si vous avez besoin de:
Exemple (vues de tête et de modèle):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )Exemple (vue des neurones):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) La vue de la tête et la vue du modèle peuvent être utilisées pour visualiser l'auto-agence pour tout modèle de transformateur standard, tant que les poids d'attention sont disponibles et suivent le format spécifié dans head_view et model_view (qui est le format renvoyé des modèles HuggingFace). Dans certains cas, les points de contrôle TensorFlow peuvent être chargés comme des modèles HuggingFace comme décrit dans les documents HuggingFace.
include_layers , comme décrit ci-dessus.include_layers , comme décrit ci-dessus.transformers_neuron_view ), ce qui n'a été fait que pour ces trois modèles. Une visualisation à plusieurs échelles de l'attention dans le modèle de transformateur (ACL System Demonstations 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Jesse Vig
Nous sommes reconnaissants aux auteurs des projets suivants, qui sont incorporés dans ce dépôt:
Ce projet est concédé sous licence Apache 2.0 - voir le fichier de licence pour plus de détails


