bertviz
v1.4.0
Bertviz является интерактивным инструментом для визуализации внимания в моделях языка трансформатора, таких как Bert, GPT2 или T5. Его можно запустить внутри ноутбука Jupyter или Colab через простой API Python, который поддерживает большинство моделей объятия. Bertviz расширяет инструмент визуализации Tensor2tensor от Llion Jones, предоставляя несколько видов, которые каждый предлагает уникальный объектив в механизм внимания.
Получите обновления для этого и связанные проекты в Twitter.
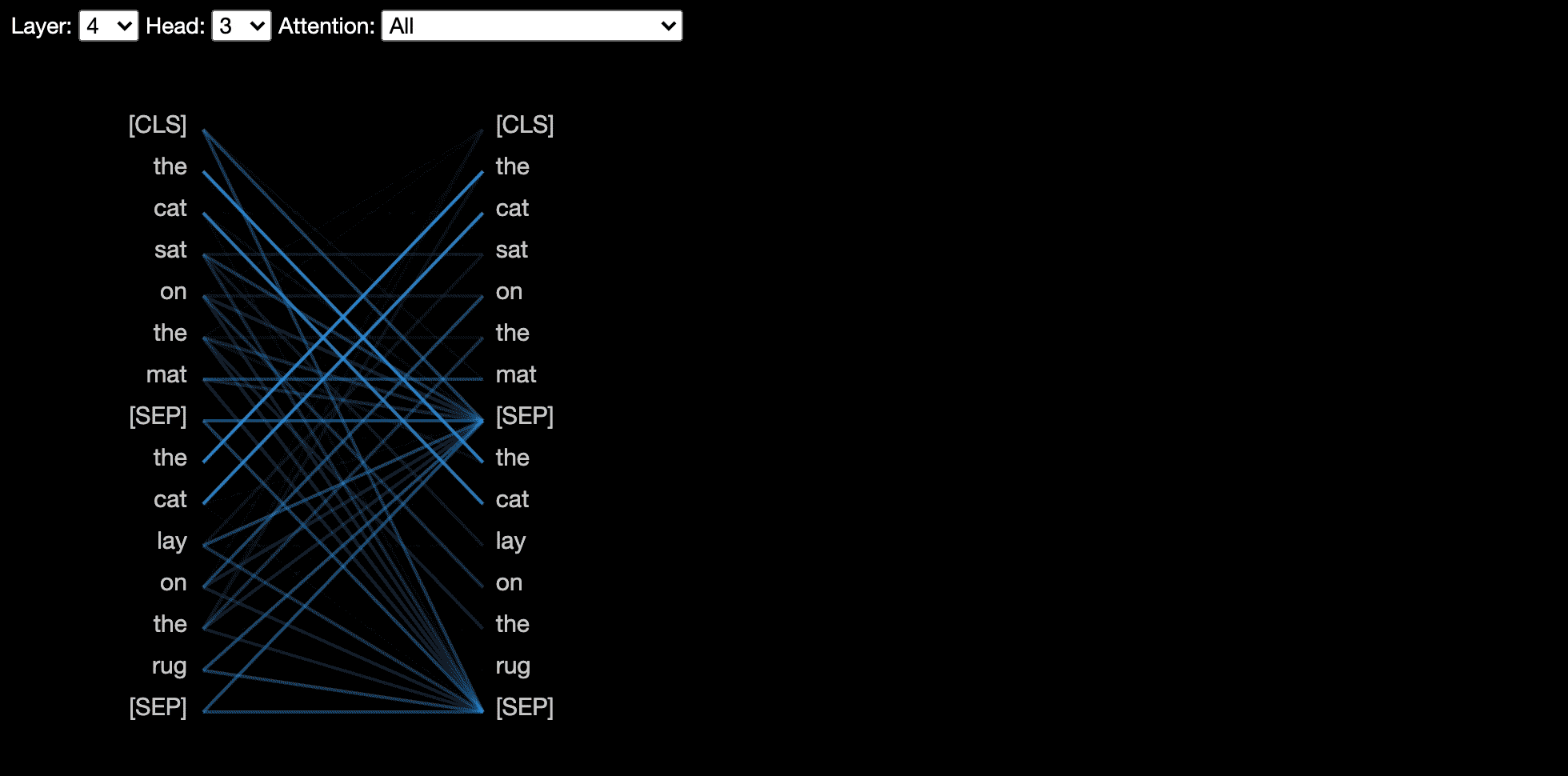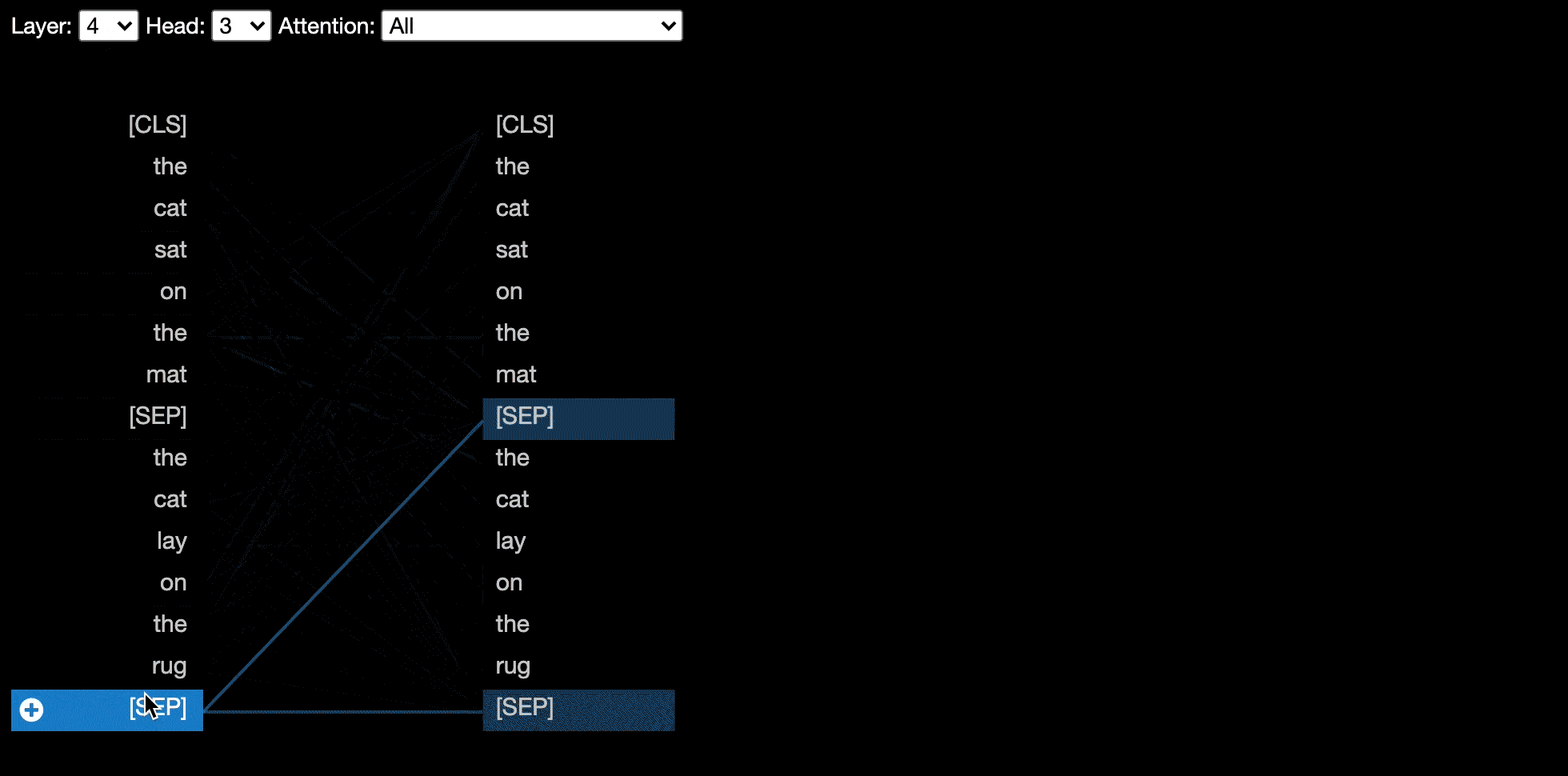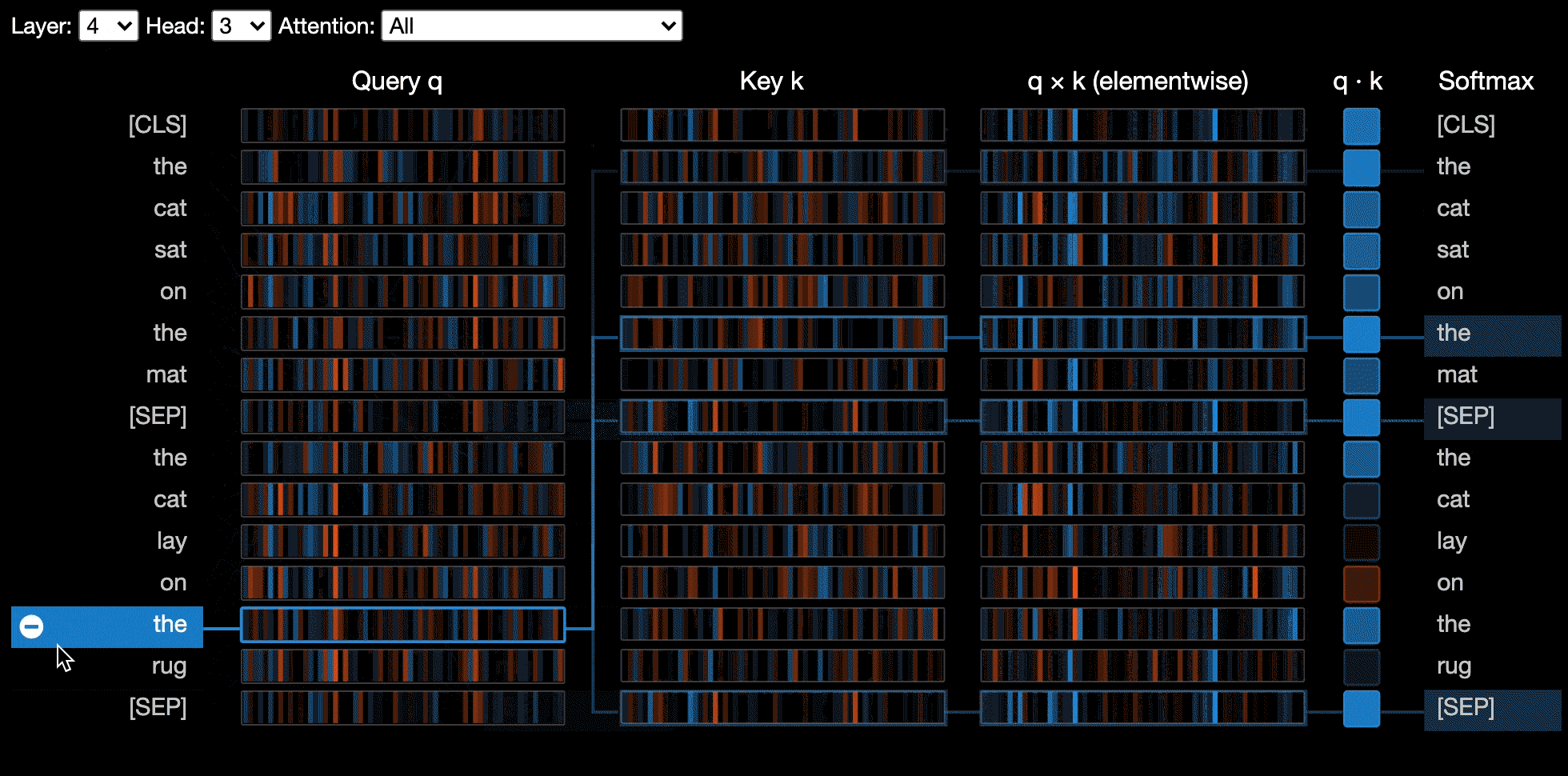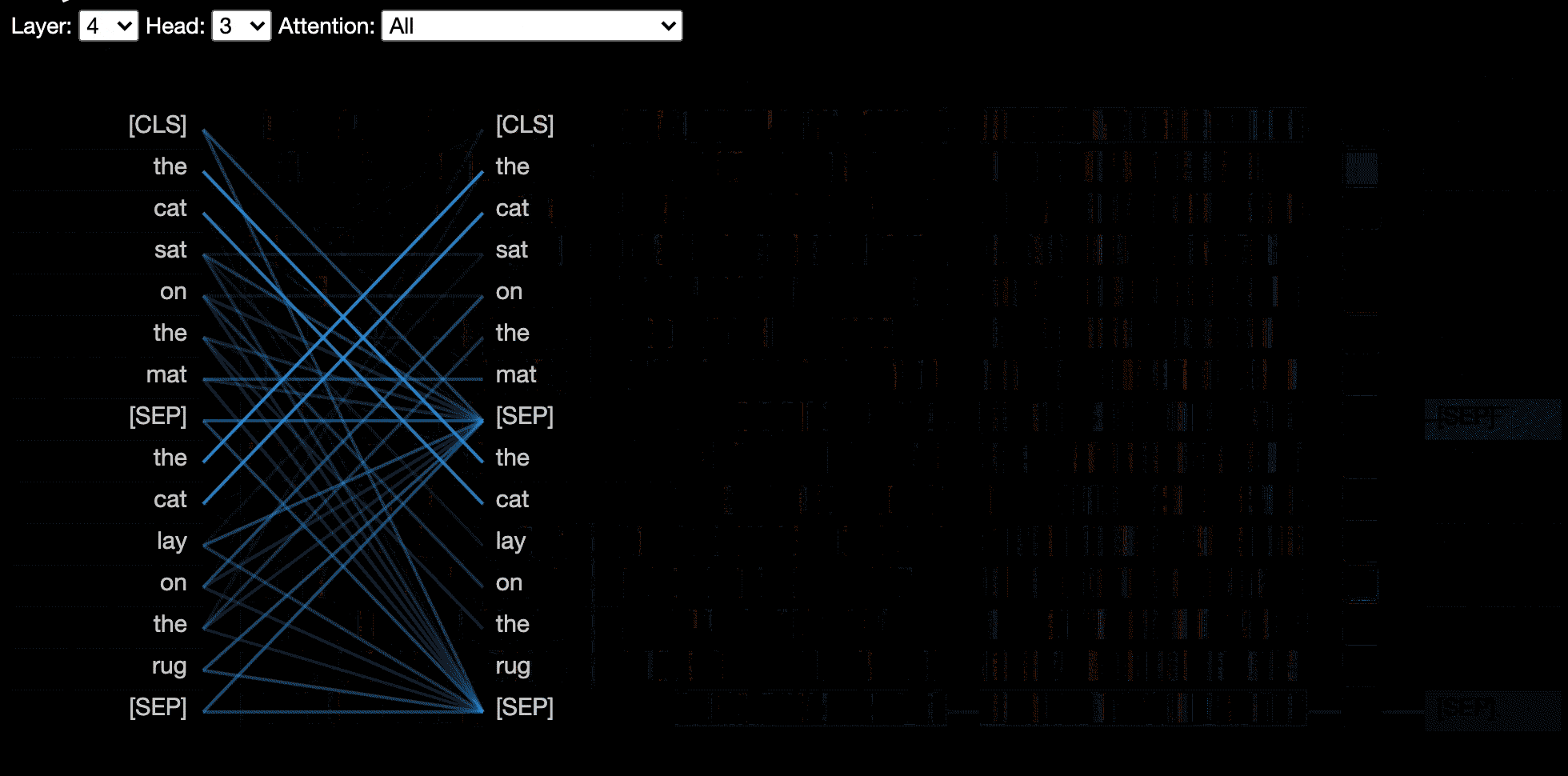
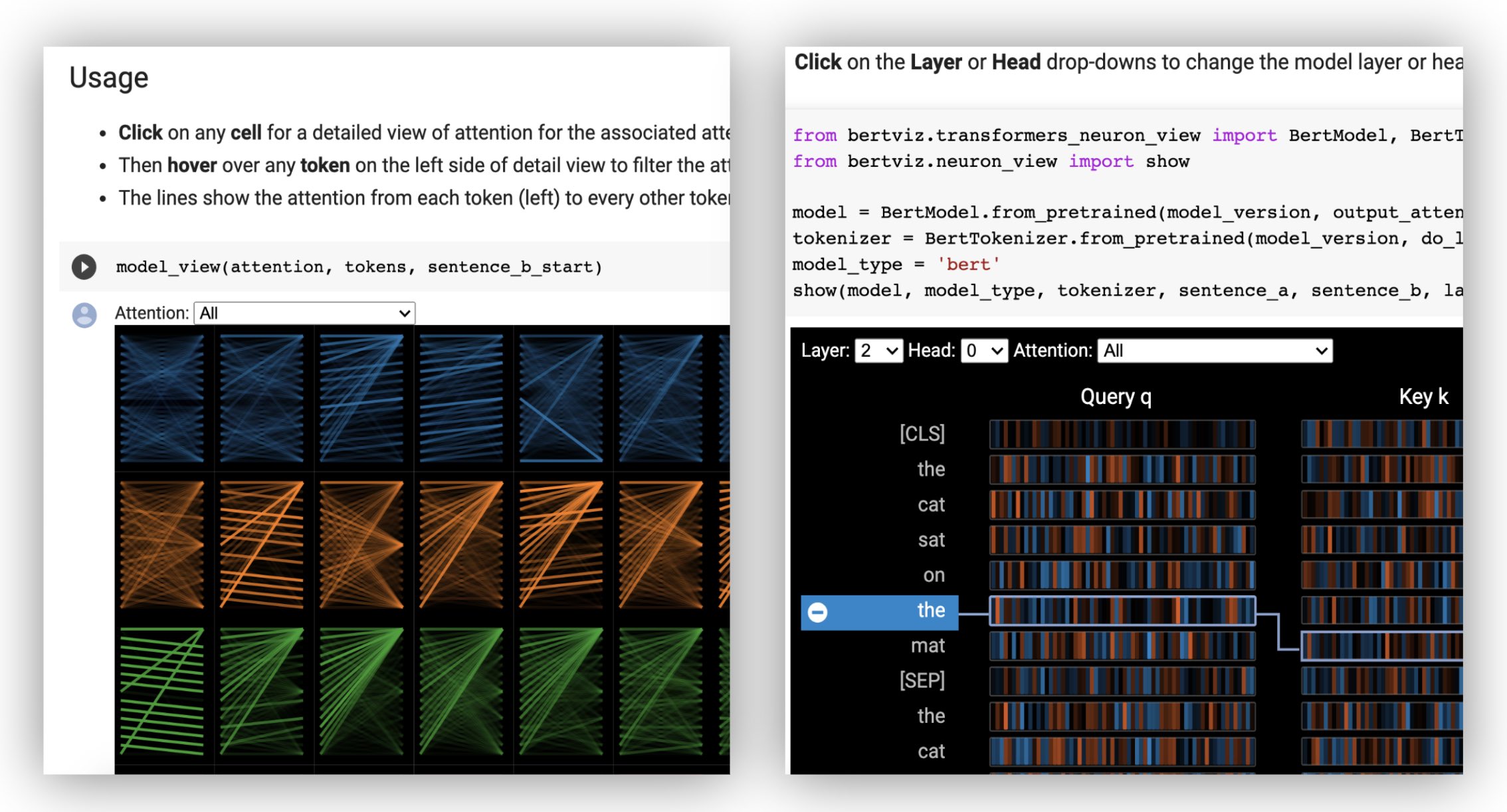
Вид головы визуализирует внимание к одному или нескольким вниманиям в одном и том же слое. Он основан на превосходном инструменте визуализации Tensor2tensor от Llion Jones.
? Попробуйте представление о головке в интерактивном учебном пособии Colab (все визуализации предварительно загружены).
Вид модели показывает вид внимания птичьего полета во всех слоях и головах.
? Попробуйте представление модели в учебном пособии Interactive Colab (все визуализации предварительно загружены).

Взгляд нейронов визуализирует отдельные нейроны в запросе и ключевых векторах и показывает, как они используются для вычисления внимания.
? Попробуйте представление нейронов в интерактивном учебном пособии Colab (все визуализации предварительно загружены).
Из командной строки:
pip install bertvizВы также должны иметь ноутбук Jupyter и ipywidgets:
pip install jupyterlab
pip install ipywidgets(Если вы столкнетесь с любыми проблемами, установленными Jupyter или Ipywidgets, обратитесь к документации здесь и здесь.)
Чтобы создать новую записную книжку Jupyter, просто запустите:
jupyter notebook Затем нажмите New и выберите Python 3 (ipykernel) если он будет предложен.
Чтобы запустить в Колабе, просто добавьте следующую ячейку в начале ноутбука Colab:
!pip install bertviz
Запустите следующий код для загрузки модели xtremedistil-l12-h384-uncased , и отобразить ее в представлении модели:
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model viewВизуализация может занять несколько секунд для загрузки. Не стесняйтесь экспериментировать с различными входными текстами и моделями. См. Документацию для дополнительных вариантов использования и примеров, например, модели Encoder-Decoder.
Вы также можете запустить любой из образцов записных книг, включенных в Bertviz:
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookПроверьте интерактивный учебник Colab, чтобы узнать больше о Bertviz и попробовать инструмент. Примечание . Все визуализации предварительно загружены, поэтому нет необходимости выполнять какие-либо ячейки.
Сначала загрузите модель HuggingFace, либо предварительно обученную модель, как показано ниже, либо ваша собственная тонкая модель. Обязательно установите output_attentions=True .
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )Затем подготовьте входные данные и вычислите внимание:
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) Наконец, отобразите веса внимания, используя функции head_view или model_view :
from bertviz import head_view
head_view ( attention , tokens )Примеры : Distilbert (ноутбук просмотра модели, записная книжка с головой)
Для полного API, пожалуйста, обратитесь к исходному коду для представления головы или модели.
Вид нейронов вызывается иначе, чем представление головы или представление модели, из -за необходимости доступа к векторам модели/ключа, которые не возвращаются через API Huggingface. В настоящее время он ограничен пользовательскими версиями Bert, GPT-2 и Роберты, включенными в Bertviz.
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )Примеры : Bert (Notebook, Colab) • GPT-2 (Notebook, Colab) • Роберта (ноутбук)
Для полного API, пожалуйста, обратитесь к источнику.
Вид головы и модель просмотра как поддерживают модели Encoder-Decoder.
Во-первых, загрузите модель энкодера-декодера:
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )Затем подготовьте входные данные и вычислите внимание:
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ]) Наконец, отобразите визуализацию, используя либо head_view , либо model_view .
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
) Вы можете выбрать Encoder , Decoder или Cross внимание от выпадения в верхнем левом углу визуализации.
Примеры : Marianmt (записная книжка) • Bart (Notebook)
Для полного API, пожалуйста, обратитесь к исходному коду для представления головы или модели.
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py develop Вид модели и нейрон поддержат темные (по умолчанию) и световые режимы. Вы можете установить режим, используя параметр display_mode :
model_view ( attention , tokens , display_mode = "light" ) Чтобы улучшить отзывчивость инструмента при визуализации более крупных моделей или входов, вы можете установить параметр include_layers , чтобы ограничить визуализацию подмножеством слоев (нулевой индекс). Эта опция доступна в представлении головы и модели.
Пример: представление модели рендеринга с отображением только слоев 5 и 6
model_view ( attention , tokens , include_layers = [ 5 , 6 ]) Для представления модели вы также можете ограничить визуализацию подмножеством головок внимания (нулевой индексации), установив параметр include_heads .
В обзоре головы вы можете выбрать определенный layer и коллекцию heads в качестве выбора по умолчанию, когда визуализация впервые отображается. Примечание. Это отличается от параметра include_heads / include_layers (выше), который полностью удаляет слои и головы из визуализации.
Пример: вид головы со слоем 2 и головы 3 и 5 предварительно выбранных
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ]) Вы также можете предварительно выбрать определенный layer и одиночную head для вида нейронов.
Некоторые модели, например, Берт, принимают пару предложений в качестве входных данных. Бертвиз необязательно поддерживает раскрывающееся меню, которое позволяет пользователю фильтровать внимание, основываясь на том, в каком предложении находятся токены, например, только проявляют внимание между токенами в первом предложении и токенами во втором предложении.
Чтобы включить эту функцию при выборе функций head_view или model_view , установите параметр sentence_b_start на индекс начала второго предложения. Обратите внимание, что метод вычисления этого индекса будет зависеть от модели.
Пример (BERT):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start ) Чтобы включить эту опцию в представлении нейрон, просто установите параметры sentence_a и sentence_b в neuron_view.show() .
Поддержка для извлечения сгенерированных представлений HTML была добавлена в Head_View, Model_View и NeuroN_VIEW.
Настройка параметра «html_action» для «return» заставит функцию вызовов возвращать один объект HTML Python, который может быть дополнительно обработана. Помните, что вы можете получить доступ к источнику HTML, используя атрибут данных объекта Python HTML.
Поведение по умолчанию для «html_action» - это «представление», которое будет отображать визуализацию, но не будет возвращать объект HTML.
Эта функция полезна, если вам нужно:
Пример (просмотры головы и модели):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )Пример (представление нейронов):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data ) Вид головы и представление модели могут использоваться для визуализации самостоятельного приспособления для любой стандартной модели трансформатора, если доступны веса внимания, и следуйте формату, указанному в head_view и model_view (который является форматом, возвращаемым из моделей HuggingFace). В некоторых случаях контрольные точки TensorFlow могут быть загружены как модели HuggingFace, как описано в документах HuggingFace.
include_layers , как описано выше.include_layers , как описано выше.transformers_neuron_view Directory), который был сделан только для этих трех моделей. Многомасштабная визуализация внимания в модели трансформатора (ACL System Demancation 2019).
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}Джесси Виг
Мы благодарны авторам следующих проектов, которые включены в это репо:
Этот проект лицензирован по лицензии Apache 2.0 - для получения подробной информации см. Файл лицензии.


