bertviz
v1.4.0
Bertvizは、BERT、GPT2、T5などのトランス語モデルで注意を視覚化するためのインタラクティブなツールです。ほとんどのハギングフェイスモデルをサポートするシンプルなPython APIを介して、JupyterまたはColabノートブック内で実行できます。 Bertvizは、Llion JonesによってTensor2Tensor視覚化ツールを拡張し、それぞれが注意メカニズムにユニークなレンズを提供する複数のビューを提供します。
Twitterでこれと関連するプロジェクトの更新を取得します。
ヘッドビューは、同じレイヤーの1つ以上の注意ヘッドの注意を視覚化します。 Llion Jonesによる優れたTensor2Tensor視覚化ツールに基づいています。
? Interactive Colabチュートリアル(すべての視覚化が事前にロードされた)でヘッドビューを試してみてください。
モデルビューは、すべての層とヘッドにわたる注意の鳥瞰図を示しています。
?インタラクティブコラブチュートリアル(すべての視覚化がプリロードされた)でモデルビューを試してください。

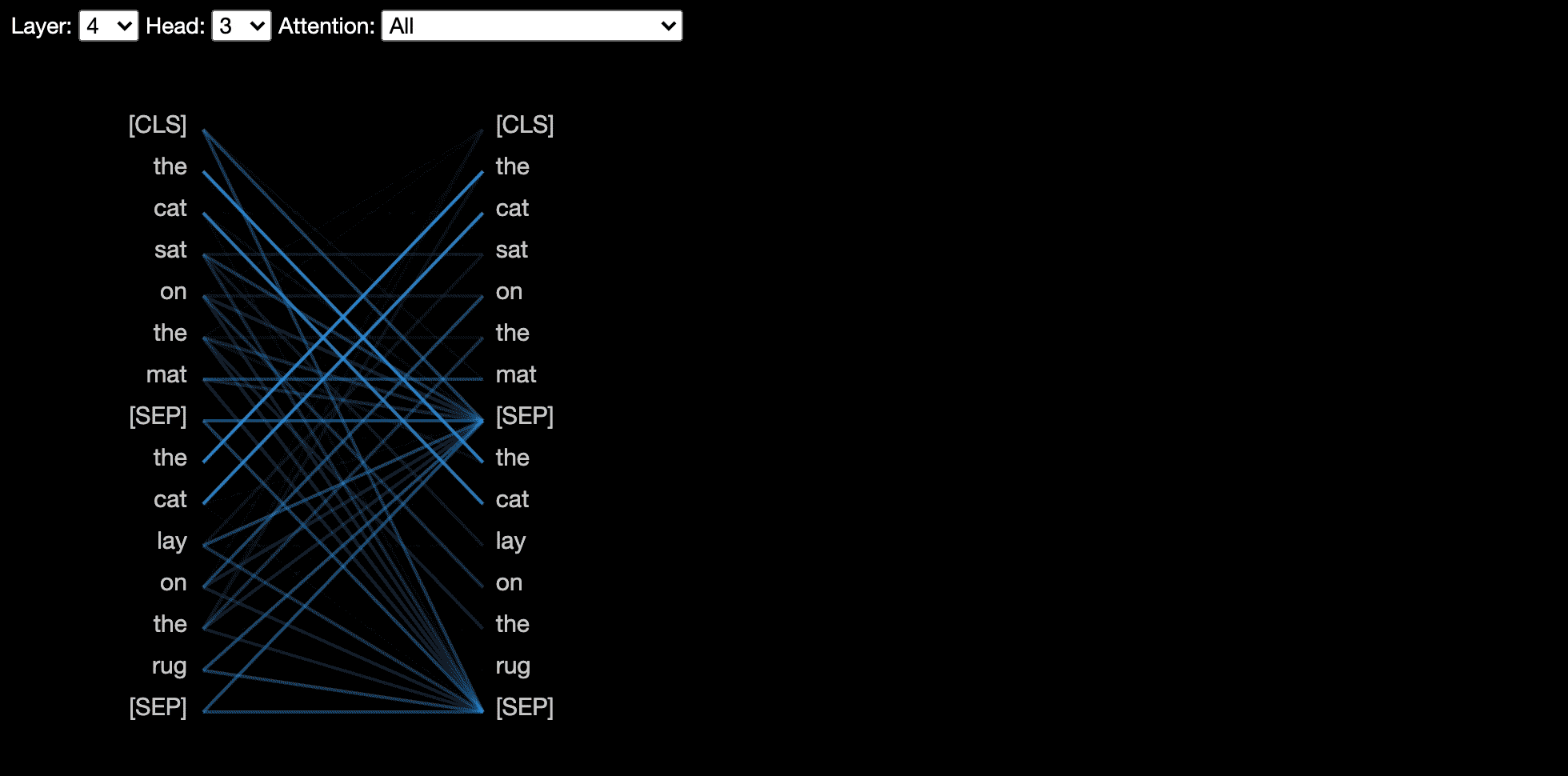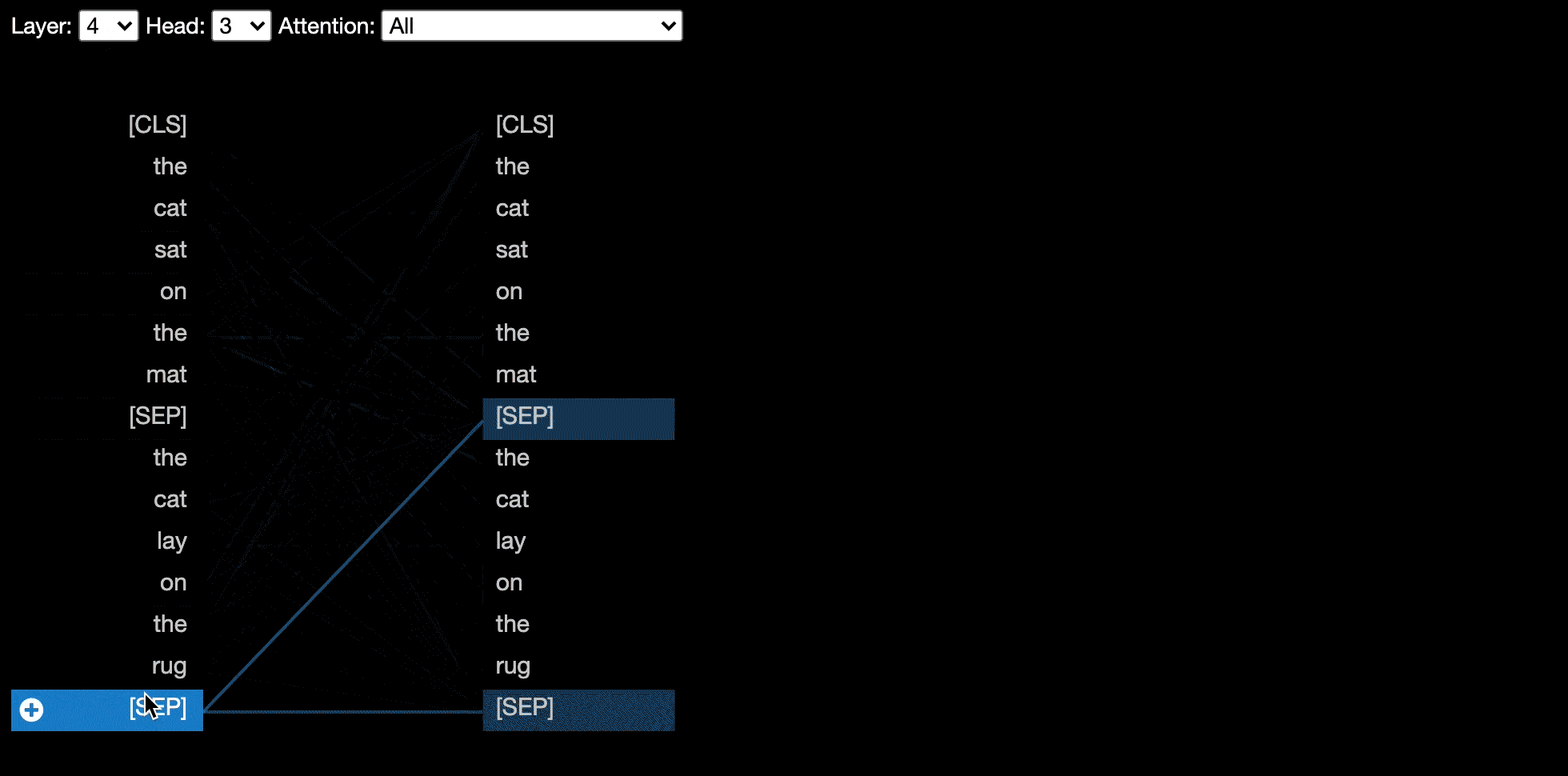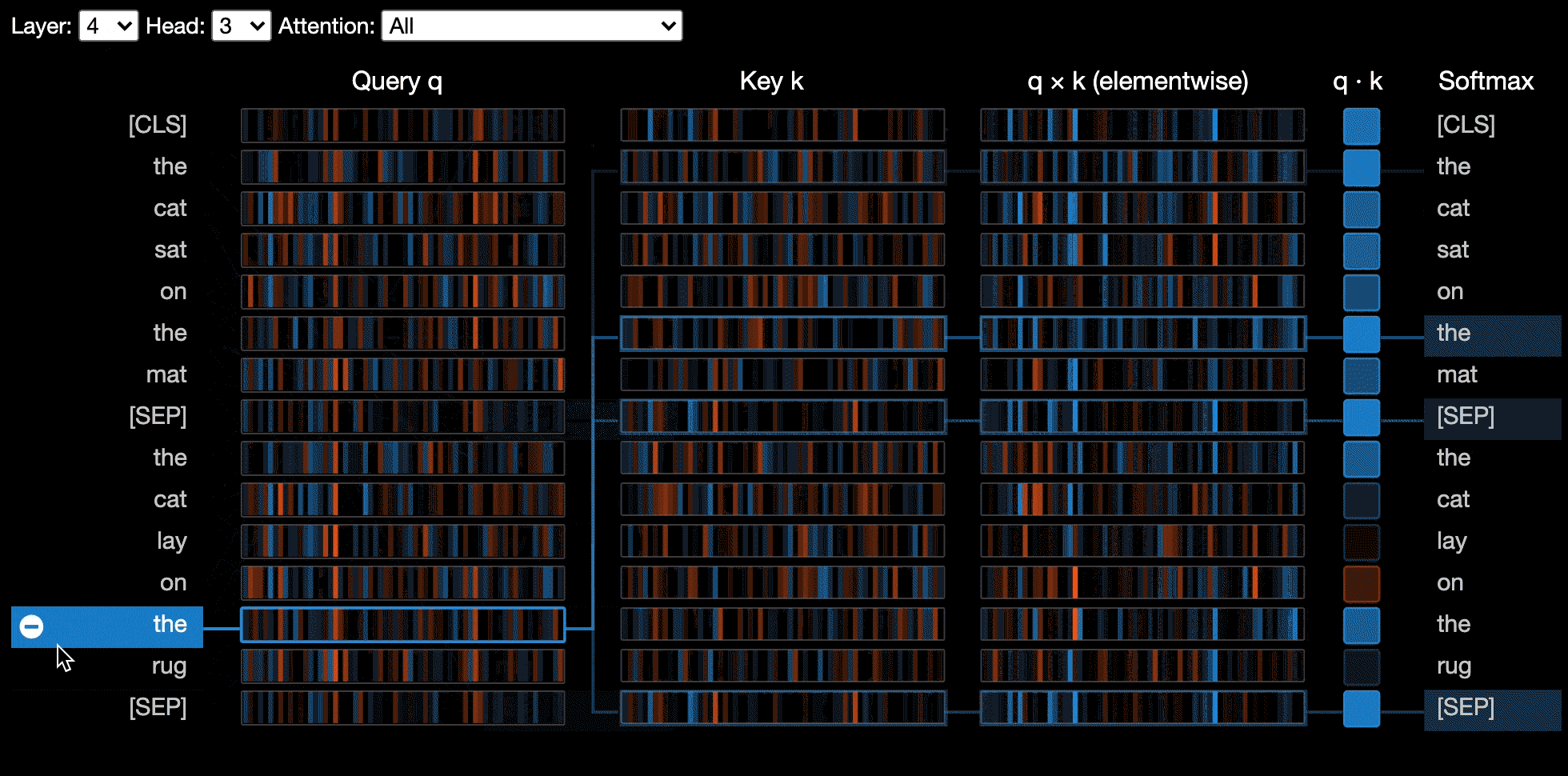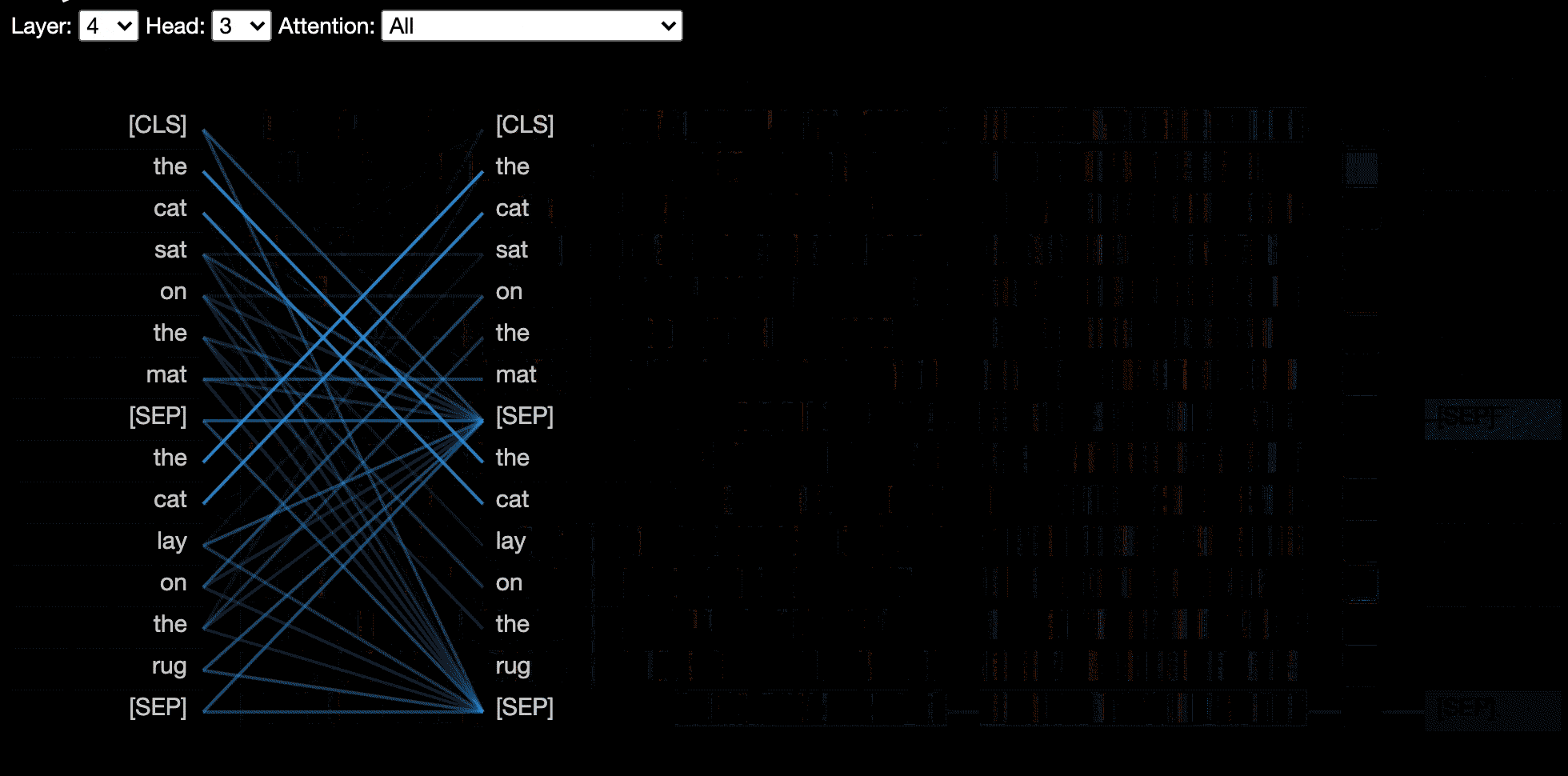
ニューロンビューは、クエリの個々のニューロンを視覚化し、キーベクトルを視覚化し、注意を計算するためにどのように使用されるかを示します。
? Interactive Colabチュートリアルでニューロンビューを試してください(すべての視覚化が事前にロードされています)。
コマンドラインから:
pip install bertvizまた、jupyterノートブックとipywidgetをインストールする必要があります。
pip install jupyterlab
pip install ipywidgets(JupyterまたはiPywidgetsのインストールを問題に遭遇した場合は、こちらとこちらからドキュメントを参照してください。)
新しいJupyterノートブックを作成するには、単に実行してください。
jupyter notebook次に、 Newをクリックして、プロンプトがある場合はPython 3 (ipykernel)を選択します。
colabで実行するには、コラブノートブックの先頭に次のセルを追加するだけです。
!pip install bertviz
次のコードを実行して、 xtremedistil-l12-h384-uncasedモデルをロードし、モデルビューに表示します。
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import model_view
utils . logging . set_verbosity_error () # Suppress standard warnings
model_name = "microsoft/xtremedistil-l12-h384-uncased" # Find popular HuggingFace models here: https://huggingface.co/models
input_text = "The cat sat on the mat"
model = AutoModel . from_pretrained ( model_name , output_attentions = True ) # Configure model to return attention values
tokenizer = AutoTokenizer . from_pretrained ( model_name )
inputs = tokenizer . encode ( input_text , return_tensors = 'pt' ) # Tokenize input text
outputs = model ( inputs ) # Run model
attention = outputs [ - 1 ] # Retrieve attention from model outputs
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) # Convert input ids to token strings
model_view ( attention , tokens ) # Display model view視覚化はロードに数秒かかる場合があります。さまざまな入力テキストとモデルをお気軽に実験してください。追加のユースケースと例、例えばエンコーダーデコーダーモデルについては、ドキュメントを参照してください。
また、Bertvizに含まれるサンプルノートブックを実行することもできます。
git clone --depth 1 [email protected]:jessevig/bertviz.git
cd bertviz/notebooks
jupyter notebookInteractive Colabチュートリアルをチェックして、Bertvizの詳細をご覧ください。ツールをお試しください。注:すべての視覚化は事前にロードされるため、セルを実行する必要はありません。
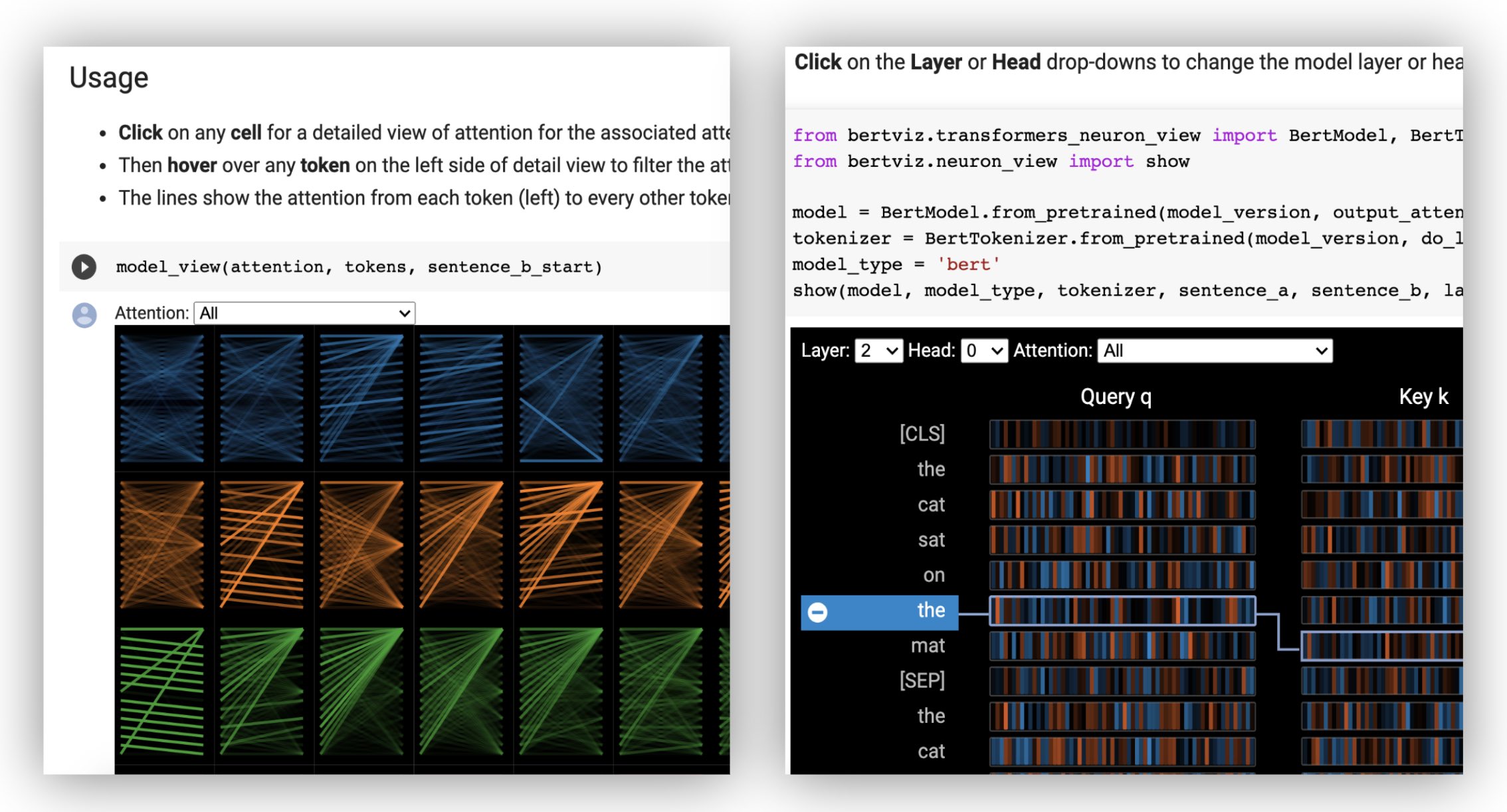
最初に、以下に示すように事前に訓練されたモデルのいずれかまたは独自の微調整されたモデルのいずれかをハグするフェイスモデルをロードします。必ずoutput_attentions=Trueを設定してください。
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )次に、入力を準備し、注意を計算します。
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ]) 最後に、 head_viewまたはmodel_view関数を使用して注意の重みを表示します。
from bertviz import head_view
head_view ( attention , tokens )例:Distilbert(モデルビューノートブック、ヘッドビューノートブック)
完全なAPIについては、ヘッドビューまたはモデルビューのソースコードを参照してください。
ニューロンビューは、モデルのクエリ/キーベクトルへのアクセスが必要であるため、ヘッドビューやモデルビューとは異なる方法で呼び出されます。現在、Bert、GPT-2、およびRobertaのカスタムバージョンに限定されています。
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 )例:Bert(ノート、コラブ)•GPT-2(ノート、コラブ)•ロベルタ(ノートブック)
完全なAPIについては、ソースを参照してください。
ヘッドビューとモデルビューは、両方のサポートエンコーダーデコーダーモデルをサポートしています。
まず、エンコーダーデコーダーモデルをロードします。
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" )
model = AutoModel . from_pretrained ( "Helsinki-NLP/opus-mt-en-de" , output_attentions = True )次に、入力を準備し、注意を計算します。
encoder_input_ids = tokenizer ( "She sees the small elephant." , return_tensors = "pt" , add_special_tokens = True ). input_ids
with tokenizer . as_target_tokenizer ():
decoder_input_ids = tokenizer ( "Sie sieht den kleinen Elefanten." , return_tensors = "pt" , add_special_tokens = True ). input_ids
outputs = model ( input_ids = encoder_input_ids , decoder_input_ids = decoder_input_ids )
encoder_text = tokenizer . convert_ids_to_tokens ( encoder_input_ids [ 0 ])
decoder_text = tokenizer . convert_ids_to_tokens ( decoder_input_ids [ 0 ])最後に、 head_viewまたはmodel_viewいずれかを使用して視覚化を表示します。
from bertviz import model_view
model_view (
encoder_attention = outputs . encoder_attentions ,
decoder_attention = outputs . decoder_attentions ,
cross_attention = outputs . cross_attentions ,
encoder_tokens = encoder_text ,
decoder_tokens = decoder_text
)視覚化の左上隅のドロップダウンから、 Encoder 、 Decoder 、または注意Crossことができます。
例:Marianmt(ノートブック)•BART(ノートブック)
完全なAPIについては、ヘッドビューまたはモデルビューのソースコードを参照してください。
git clone https://github.com/jessevig/bertviz.git
cd bertviz
python setup.py developモデルビューとニューロンビューは、暗いモードとライトモードをサポートしています。 display_modeパラメーターを使用してモードを設定できます。
model_view ( attention , tokens , display_mode = "light" )大きなモデルまたは入力を視覚化するときにツールの応答性を向上させるには、 include_layersパラメーターを設定して、視覚化をレイヤーのサブセットに制限することができます(ゼロインデックス化)。このオプションは、ヘッドビューとモデルビューで使用できます。
例:レイヤー5と6のみが表示されたレンダリングモデルビュー
model_view ( attention , tokens , include_layers = [ 5 , 6 ])モデルビューでは、 include_headsパラメーターを設定することにより、視覚化を注意ヘッドのサブセット(ゼロインデックス)に制限することもできます。
ヘッドビューでは、視覚化が最初にレンダリングするときに、デフォルトの選択として、特定のlayerとheadsのコレクションを選択できます。注:これは、 include_heads / include_layersパラメーター(上記)とは異なり、視覚化からレイヤーとヘッドを完全に削除します。
例:レイヤー2とヘッド3および5でヘッドビューをレンダリングする
head_view ( attention , tokens , layer = 2 , heads = [ 3 , 5 ])また、ニューロンビューの特定のlayerとシングルheadを事前に選択することもできます。
いくつかのモデル、例えばBertは、入力として一対の文を受け入れます。 Bertvizはオプションで、ドロップダウンメニューをサポートします。これにより、ユーザーはトークンがどの文に基づいて注意をフィルタリングできます。
この機能を有効にするには、 head_viewまたはmodel_view関数を呼び出すときに、 sentence_b_startパラメーターを2番目の文の開始インデックスに設定します。このインデックスを計算する方法は、モデルに依存することに注意してください。
例(bert):
from bertviz import head_view
from transformers import AutoTokenizer , AutoModel , utils
utils . logging . set_verbosity_error () # Suppress standard warnings
# NOTE: This code is model-specific
model_version = 'bert-base-uncased'
model = AutoModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = AutoTokenizer . from_pretrained ( model_version )
sentence_a = "the rabbit quickly hopped"
sentence_b = "The turtle slowly crawled"
inputs = tokenizer . encode_plus ( sentence_a , sentence_b , return_tensors = 'pt' )
input_ids = inputs [ 'input_ids' ]
token_type_ids = inputs [ 'token_type_ids' ] # token type id is 0 for Sentence A and 1 for Sentence B
attention = model ( input_ids , token_type_ids = token_type_ids )[ - 1 ]
sentence_b_start = token_type_ids [ 0 ]. tolist (). index ( 1 ) # Sentence B starts at first index of token type id 1
token_ids = input_ids [ 0 ]. tolist () # Batch index 0
tokens = tokenizer . convert_ids_to_tokens ( token_ids )
head_view ( attention , tokens , sentence_b_start )Neuron Viewでこのオプションを有効にするには、 neuron_view.show()にsentence_aとsentence_bパラメーターを設定するだけです。
生成されたHTML表現を取得するためのサポートは、head_view、model_view、およびneuron_viewに追加されています。
「html_action」パラメーターを「return」に設定すると、関数呼び出しがさらに処理できる単一のHTML Pythonオブジェクトを返します。 Python HTMLオブジェクトのデータ属性を使用してHTMLソースにアクセスできることを忘れないでください。
「HTML_ACTION」のデフォルトの動作は「ビュー」です。これは視覚化を表示しますが、HTMLオブジェクトは返されません。
この機能は、必要な場合に役立ちます。
例(ヘッドビューとモデルビュー):
from transformers import AutoTokenizer , AutoModel , utils
from bertviz import head_view
utils . logging . set_verbosity_error () # Suppress standard warnings
tokenizer = AutoTokenizer . from_pretrained ( "bert-base-uncased" )
model = AutoModel . from_pretrained ( "bert-base-uncased" , output_attentions = True )
inputs = tokenizer . encode ( "The cat sat on the mat" , return_tensors = 'pt' )
outputs = model ( inputs )
attention = outputs [ - 1 ] # Output includes attention weights when output_attentions=True
tokens = tokenizer . convert_ids_to_tokens ( inputs [ 0 ])
html_head_view = head_view ( attention , tokens , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/head_view.html" , 'w' ) as file :
file . write ( html_head_view . data )例(ニューロンビュー):
# Import specialized versions of models (that return query/key vectors)
from bertviz . transformers_neuron_view import BertModel , BertTokenizer
from bertviz . neuron_view import show
model_type = 'bert'
model_version = 'bert-base-uncased'
do_lower_case = True
sentence_a = "The cat sat on the mat"
sentence_b = "The cat lay on the rug"
model = BertModel . from_pretrained ( model_version , output_attentions = True )
tokenizer = BertTokenizer . from_pretrained ( model_version , do_lower_case = do_lower_case )
html_neuron_view = show ( model , model_type , tokenizer , sentence_a , sentence_b , layer = 2 , head = 0 , html_action = 'return' )
with open ( "PATH_TO_YOUR_FILE/neuron_view.html" , 'w' ) as file :
file . write ( html_neuron_view . data )ヘッドビューとモデルビューを使用して、注意の重みが利用可能である限り、標準の変圧器モデルの自己関節を視覚化し、 head_viewとmodel_viewで指定された形式に従うことができます(これはHuggingfaceモデルから返される形式です)。場合によっては、Tensorflowチェックポイントは、Huggingfaceドキュメントに記載されているように、ハギングフェイスモデルとしてロードされる場合があります。
include_layersパラメーターを設定することにより、表示されたレイヤーをフィルタリングすることをお勧めします。include_layersパラメーターを設定することにより、表示されたレイヤーをフィルタリングすることをお勧めします。transformers_neuron_viewディレクトリを参照)の変更を必要とするクエリとキーベクトルへのアクセスが必要です。 トランスモデルにおける注意のマルチスケール視覚化(ACLシステムデモンストレーション2019)。
@inproceedings { vig-2019-multiscale ,
title = " A Multiscale Visualization of Attention in the Transformer Model " ,
author = " Vig, Jesse " ,
booktitle = " Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations " ,
month = jul,
year = " 2019 " ,
address = " Florence, Italy " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/P19-3007 " ,
doi = " 10.18653/v1/P19-3007 " ,
pages = " 37--42 " ,
}ジェシー・ヴィグ
次のプロジェクトの著者に感謝します。このプロジェクトは、このリポジトリに組み込まれています。
このプロジェクトはApache 2.0ライセンスの下でライセンスされています - 詳細については、ライセンスファイルを参照してください


