BERT Relation Extraction
1.0.0
在ACL 2019中发布的论文“与空白:关系学习的分布相似性相匹配”的模型的Pytorch实施。
注意:这不是该论文的正式回购。
基于本文的方法论,此处实施的其他关系提取的其他模型:
有关实施的更多概念详细信息,请参阅https://towardsdatascience.com/bert-s-for-relation-traction-nlp-2c7c3ab487c4
如果您喜欢我的工作,请考虑通过单击顶部的赞助商按钮来赞助。
要求:Python(3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg预先训练的BERT模型(Albert,Bert)由HuggingFace.co(https://huggingface.co)提供
https://github.com/dmis-lab/biobert提供的预培训的生物模型
要使用biobert(biobert_v1.1_pubmed),请从此处下载并解开该模型。
在下面的参数中运行main_pretraining.py。预培训数据可以是任何.txt连续文本文件。
我们使用Spacy NLP从文本中获取成对实体(窗口大小在40个令牌长度内),以形成与预训练的关系语句。实体识别基于对象/受试者的依赖树解析。
我使用的从CNN数据集(CNN.TXT)获取的预培训数据可以在此处下载。
下载并另存为./data/cnn.txt
但是,请注意,本文使用Wiki转储数据进行MTB预训练,该数据比CNN数据集大得多。
注意:根据可用的GPU,预培训可能需要很长时间。遵循以下部分,可以直接对关系撤销任务进行微调,并仍然获得合理的结果。
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]在下面的参数上运行main_task.py。需要SEMEVAL2010任务8数据集,可在此处提供。下载&UNZIP到./data/文件夹。
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]要推断句子,您可以在句子中注释entity1&entity2 in and and in suntions and tity and int sunts and tity and in sunts and sunts的实体标签[E1],[E2]。例子:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) 该脚本还可以自动检测输入句子中的潜在实体,在这种情况下,都会推断出所有可能的关系组合:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) 在此处下载少数1.0数据集。并解开为./data/文件夹。
使用参数'task'设置为“少数”,运行main_task.py。
python main_task.py --task fewrel结果:
(5向1杆)
没有MTB的BERT EM ,未接受任何少数数据的培训
| 型号大小 | 准确性(41646个样本) |
|---|---|
| Bert-base-uncund | 62.229% |
| Bert-large uncund | 72.766% |
没有MTB预培训:对100%培训数据进行培训时F1结果: 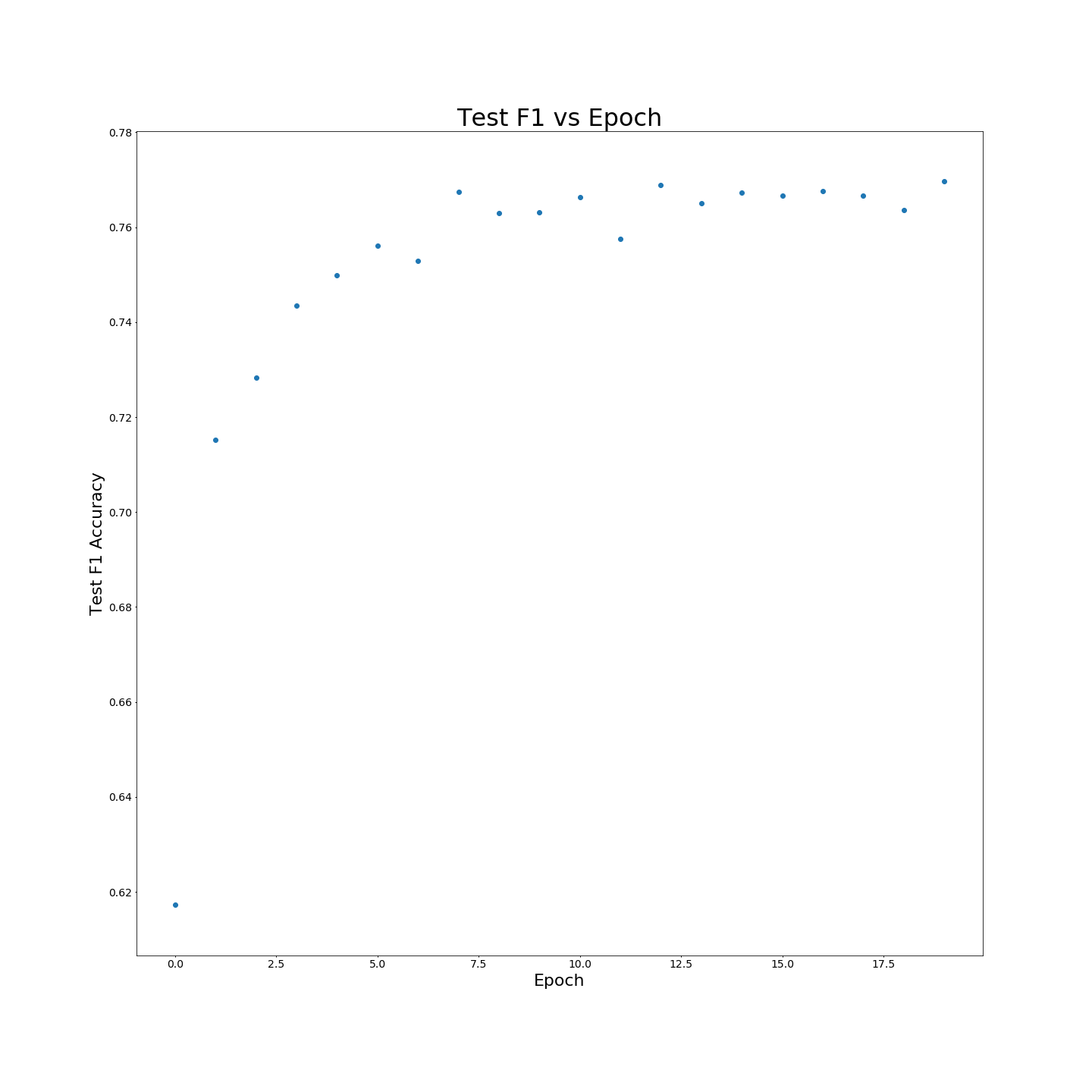
没有MTB预培训:对100%培训数据进行培训时F1结果: