BERT Relation Extraction
1.0.0
ACL 2019で公開された論文「ブランクと一致する:関係学習の分布類似性」のペーパーのモデルのPytorch実装。
注:これは論文の公式リポジトリではありません。
関係抽出のための追加モデル。論文の方法論に基づいてここで実装されています。
実装の詳細については、https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4を参照してください。
私の仕事が気に入っている場合は、スポンサーボタンを上部にクリックしてスポンサーを検討してください。
要件:Python(3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg事前に訓練されたBERTモデル(Albert、Bert)Huggingface.co(https://huggingface.co)の厚意により
https://github.com/dmis-lab/biobertの提供により、事前に訓練されたBiobertモデル
Biobert(biobert_v1.1_pubmed)を使用するには、モデルをここから./additional_modelsフォルダーにダウンロードして解凍します。
以下の引数でmain_pretraining.pyを実行します。トレーニング前のデータは、任意の.txt連続テキストファイルにすることができます。
Spacy NLPを使用して、テキストからペアワイズエンティティ(ウィンドウサイズ40トークンの長さ)をつかんで、トレーニング前の関係ステートメントをフォームにつかみます。エンティティの認識は、オブジェクト/被験者のNERおよび依存性ツリー解析に基づいています。
私が使用したCNNデータセット(CNN.TXT)から取得したトレーニング前のデータは、ここからダウンロードできます。
./data/cnn.txtとしてダウンロードして保存します
ただし、このペーパーでは、CNNデータセットよりもはるかに大きいMTBプリトレーニングにWikiダンプデータを使用していることに注意してください。
注:利用可能なGPUに応じて、トレーニング前に長い時間がかかる場合があります。関係と抽出タスクを直接微調整し、以下のセクションに従って合理的な結果を得ることができます。
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]以下の引数でmain_task.pyを実行します。 Semeval2010タスク8データセットが必要です。ここで入手できます。 ./data/フォルダーにダウンロードして解凍します。
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]文を推測するには、それぞれのエンティティタグ[E1]、[E2]を使用して、対象のエンティティ1とエンティティ2に注釈を付けることができます。例:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) スクリプトは、入力文の潜在的なエンティティを自動的に検出することもできます。この場合、すべての可能な関係の組み合わせが推測されます。
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Fearlel 1.0データセットをこちらからダウンロードしてください。および./data/フォルダーに解凍します。
引数「タスク」が「少ないレル」として設定されたMain_Task.pyを実行します。
python main_task.py --task fewrel結果:
(5ウェイ1ショット)
MTBなしでbertem 、少数のデータでトレーニングされていません
| モデルサイズ | 精度(41646サンプル) |
|---|---|
| Bert-Base-Uncased | 62.229% |
| Bert-Large-Uncased | 72.766% |
MTBなしの事前トレーニング:F1は、100%のトレーニングデータでトレーニングされた場合の結果: 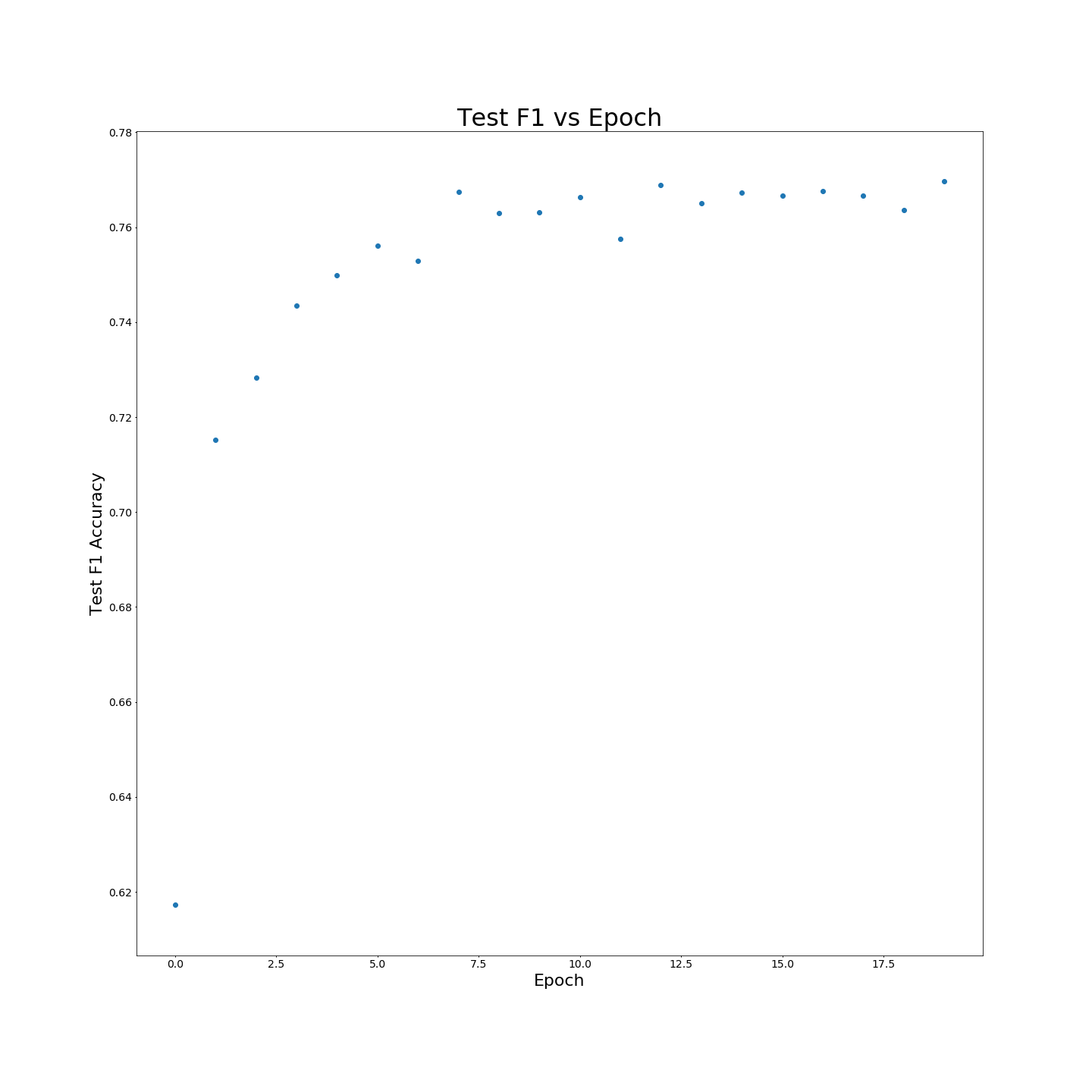
MTBなしの事前トレーニング:F1は、100%のトレーニングデータでトレーニングされた場合の結果: