BERT Relation Extraction
1.0.0
ACL 2019에 발표 된 "공백 일치 : 관계 학습을위한 분포 유사성"용지에 대한 모델의 Pytorch 구현.
참고 : 이것은 논문의 공식 리포가 아닙니다.
논문의 방법론을 기반으로 여기에 구현 된 관계 추출에 대한 추가 모델 :
구현에 대한 자세한 내용은 https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4를 참조하십시오.
내 작업이 마음에 들면 상단의 스폰서 버튼을 클릭하여 후원을 고려하십시오.
요구 사항 : 파이썬 (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg 미리 훈련 된 버트 모델 (Albert, Bert) Huggingface.co의 제공 (https://huggingface.co)
미리 훈련 된 바이오 버트 모델 https://github.com/dmis-lab/biobert
biobert (biobert_v1.1_pubmed)를 사용하려면 여기에서 ./additional_models 폴더로 모델을 다운로드하여 압축하십시오.
아래 인수와 함께 main_pretraining.py를 실행하십시오. 사전 훈련 데이터는 .txt 연속 텍스트 파일 일 수 있습니다.
우리는 Spacy NLP를 사용하여 텍스트에서 쌍별 엔티티 (창 크기의 40 개의 토큰 길이)를 잡아 사전 훈련을위한 관계 문을 형성합니다. 엔티티 인식은 물체/피험자의 NER 및 종속성 트리 구문 분석을 기반으로합니다.
내가 사용한 CNN DataSet (CNN.TXT)에서 가져온 사전 훈련 데이터는 여기에서 다운로드 할 수 있습니다.
./data/cnn.txt로 다운로드하고 저장하십시오
그러나이 논문은 CNN 데이터 세트보다 훨씬 큰 MTB 사전 훈련에 Wiki 덤프 데이터를 사용합니다.
참고 : 사전 훈련은 사용 가능한 GPU에 따라 오랜 시간이 걸릴 수 있습니다. 관계 추출 작업을 직접 미세 조정하고 아래 섹션에 따라 여전히 합리적인 결과를 얻을 수 있습니다.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]아래에 인수로 main_task.py를 실행하십시오. SEMEVAL2010 작업 8 데이터 세트가 필요합니다. ./data/ 폴더로 다운로드 및 unzip.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]문장을 추론하기 위해, 당신은 각 엔티티 태그 [e1], [e2]와 함께 문장 내에서 Entity1 & Entity2를 주석을 달 수 있습니다. 예:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) 스크립트는 입력 문장에서 잠재적 엔티티를 자동으로 감지 할 수 있으며,이 경우 가능한 모든 관계 조합이 추론됩니다.
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) 여기에서 FeedRel 1.0 데이터 세트를 다운로드하십시오. 그리고 ./data/ 폴더에 대한 압축을 해제하십시오.
'Fewrel'으로 세트 인 Argument 'task'를 사용하여 main_task.py를 실행하십시오.
python main_task.py --task fewrel 결과:
(5 방향 1- 샷)
MTB가없는 Bert Em , 몇 개의 rel 데이터에 대해 훈련되지 않았습니다.
| 모델 크기 | 정확도 (41646 샘플) |
|---|---|
| 베르트-베이스에 배치 | 62.229 % |
| Bert-large-incased | 72.766 % |
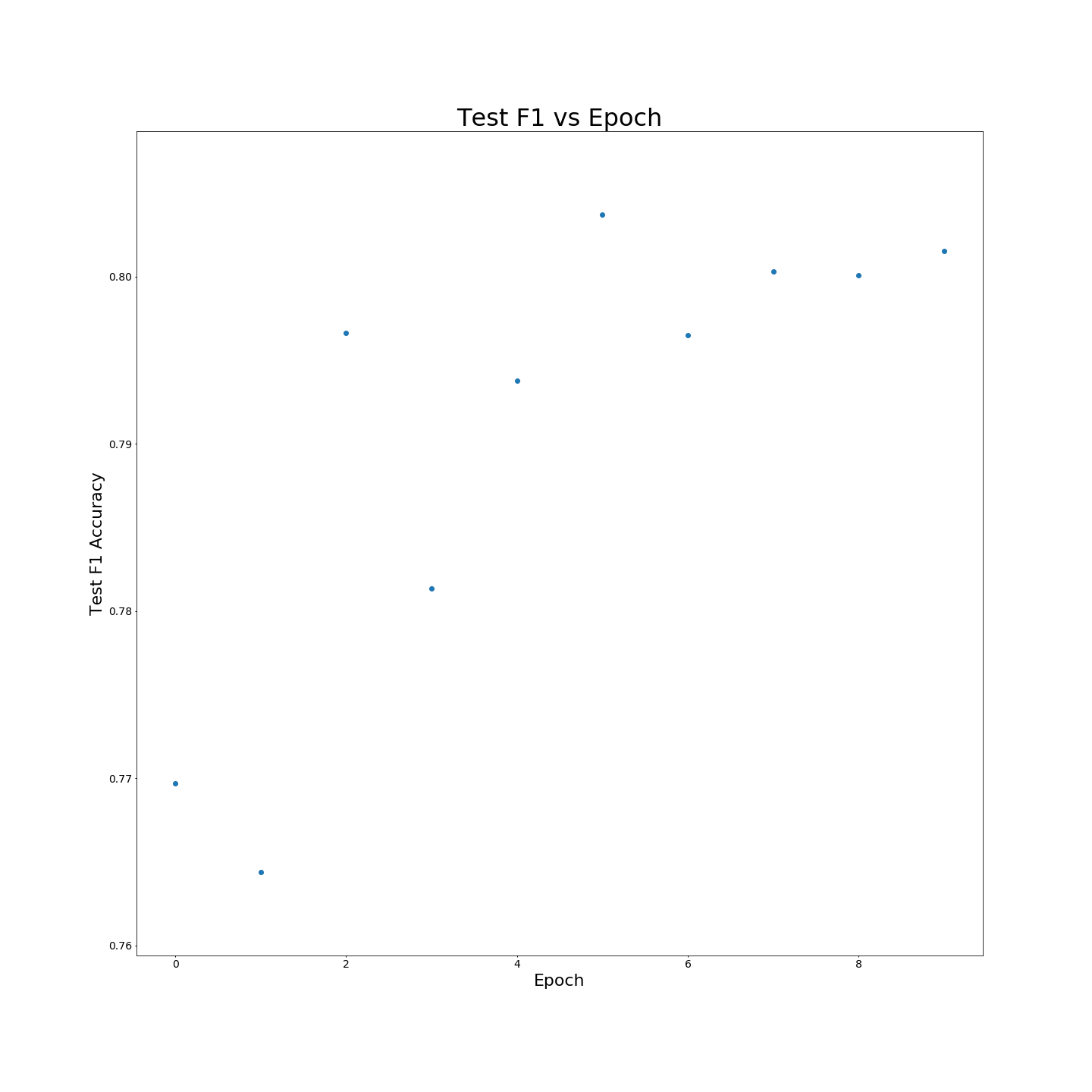
MTB 사전 훈련없이 : 100 % 교육 데이터에 대해 교육을받을 때 F1 결과 : 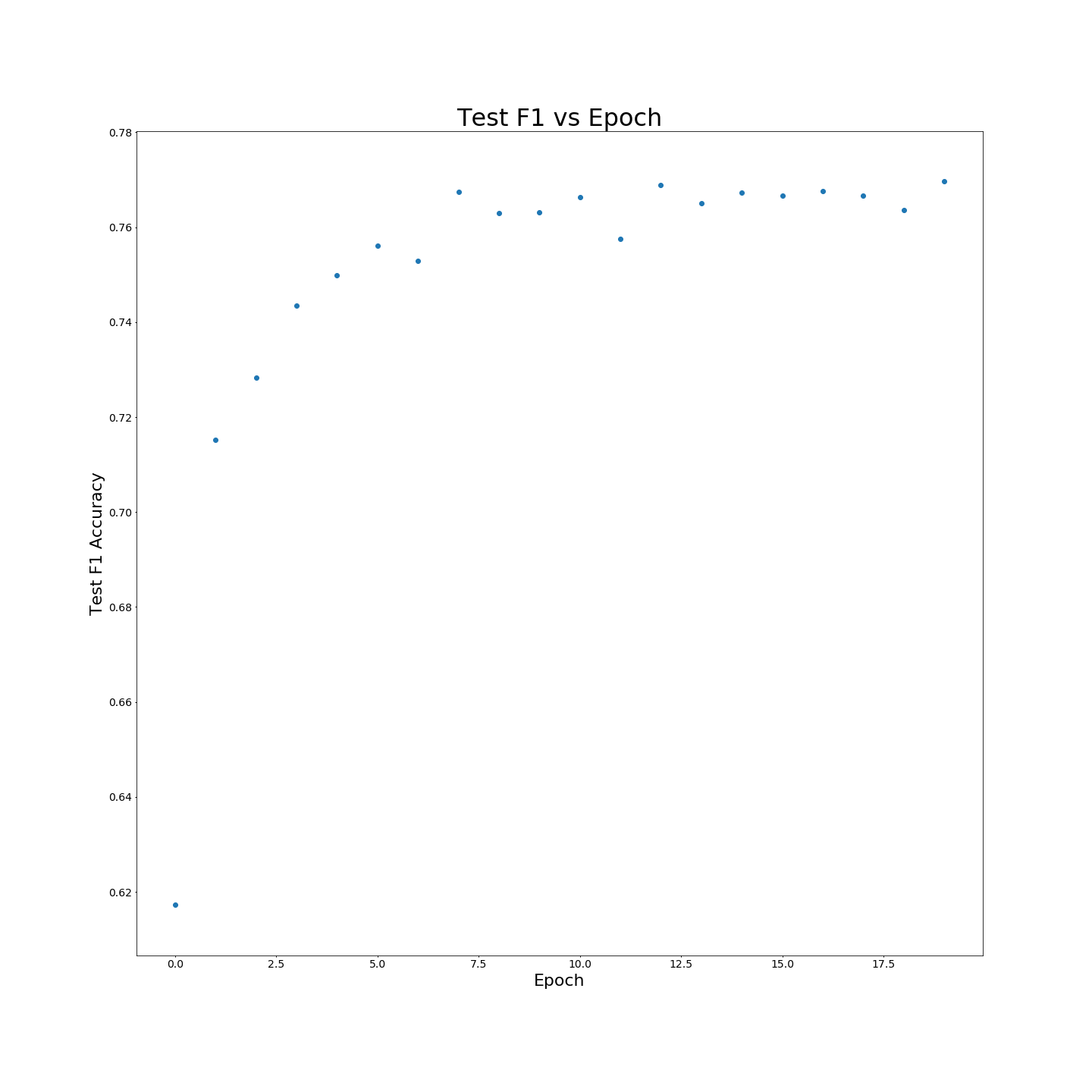
MTB 사전 훈련없이 : 100 % 교육 데이터에 대해 교육을받을 때 F1 결과 :