BERT Relation Extraction
1.0.0
Реализация моделей Pytorch для статьи «Сопоставление пробелов: сходство распределения для обучения отношений», опубликованное в ACL 2019.
Примечание: это не официальное репо для бумаги.
Дополнительные модели для извлечения отношений, реализованные здесь на основе методологии статьи:
Для получения более концептуальных сведений о реализации см. Https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
Если вам нравится моя работа, пожалуйста, рассмотрите возможность спонсоров, нажав кнопку «Спонсор» вверху.
Требования: Python (3,8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Предварительно обученные модели BERT (Albert, Bert) предоставлено Huggingface.co (https://huggingface.co)
Предварительно обученная модель биобарта предоставлена https://github.com/dmis-lab/biobert
Чтобы использовать Biobert (biobert_v1.1_pubmed), загрузите и не разируйте модель отсюда в папку ./additional_models.
Запустите main_pretring.py с аргументами ниже. Данные предварительного обучения могут быть любым непрерывным текстовым файлом .txt.
Мы используем Spacy NLP для захвата парных сущностей (в пределах размера окна 40 токенов длины) из текста в соответствии с операторами отношения для предварительного обучения. Распознавание объектов основано на анализе дерева и субъектов.
Данные предварительного обучения, полученные из набора данных CNN (cnn.txt), могут быть загружены здесь.
Скачать и сохранить как ./data/cnn.txt
Тем не менее, обратите внимание, что в статье используются данные Wiki Damples для предварительного обучения MTB, которые намного больше, чем набор данных CNN.
Примечание. Предварительное обучение может занять много времени, в зависимости от доступного графического процессора. Можно непосредственно точно настроить задачу по отношению к отношению и по-прежнему получить разумные результаты, следуя разделу ниже.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Запустите main_task.py с аргументами ниже. Требуется набор данных Semeval2010 8, доступный здесь. Скачать и раскачивать на ./data/ папка.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Чтобы вывести предложение, вы можете аннотировать Entity1 и Entity2 интереса в предложении с их соответствующими тегами сущностей [E1], [E2]. Пример:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) Сценарий также может автоматически обнаружить потенциальные объекты в входном предложении, и в этом случае выводятся все возможные комбинации отношений:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Загрузите здесь набор данных LestRel 1.0. и разкапли в папке ./data/.
Запустите main_task.py с аргументом «Задача», установленной как «меньше».
python main_task.py --task fewrel Результаты:
(5-й 1-выстрел)
Bert Em без MTB, не обученного каким -либо данным.
| Размер модели | Точность (41646 образцов) |
|---|---|
| Берт-базовая открыта | 62,229 % |
| Берт-широко-проводг | 72,766 % |
Без предварительного обучения MTB: F1 результаты при обучении на 100 % обучающих данных: 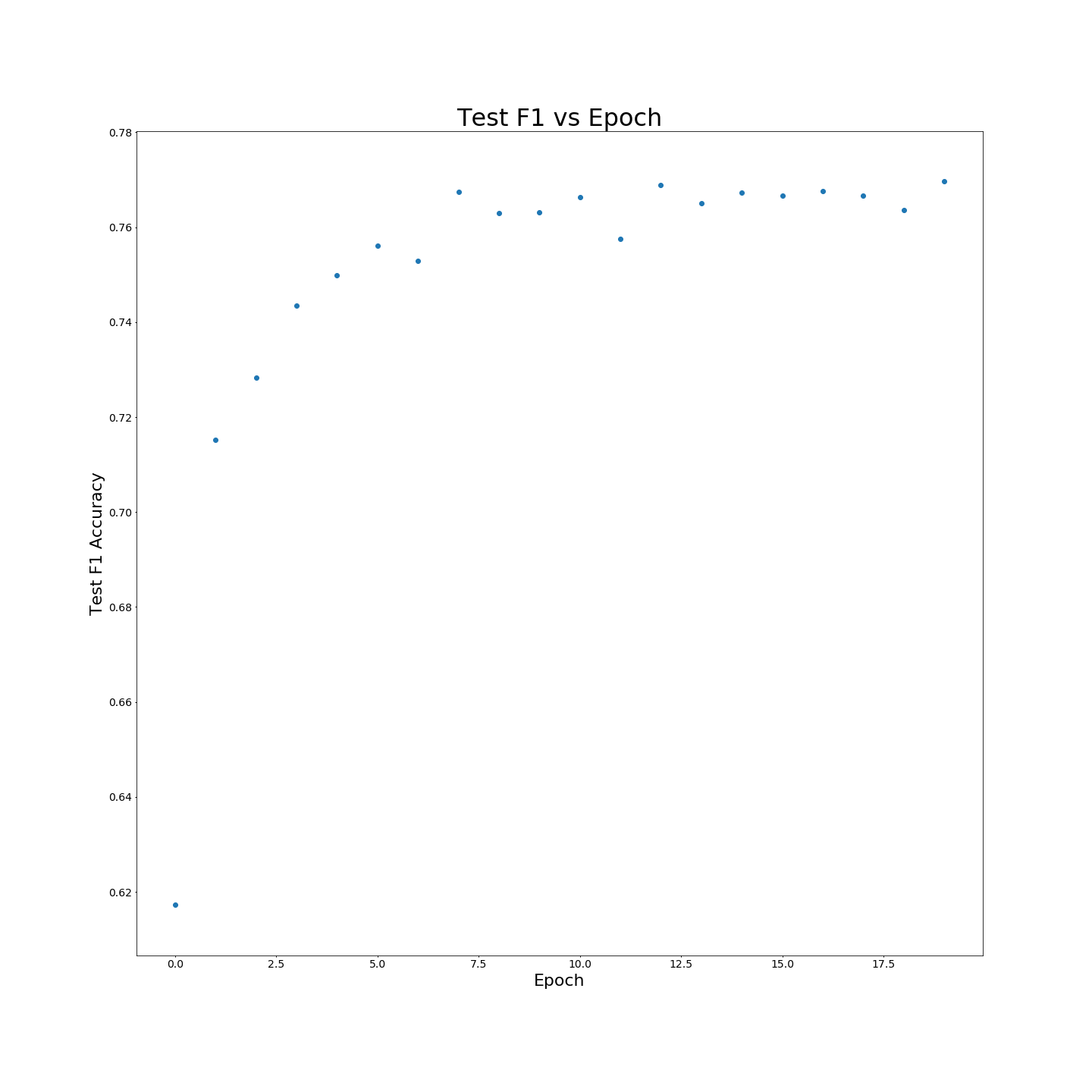
Без предварительного обучения MTB: F1 результаты при обучении на 100 % обучающих данных: