BERT Relation Extraction
1.0.0
Implementasi Pytorch dari model untuk makalah "mencocokkan Blanks: distribusi kesamaan untuk pembelajaran hubungan" yang diterbitkan dalam ACL 2019.
Catatan: Ini bukan repo resmi untuk kertas.
Model tambahan untuk ekstraksi hubungan, diimplementasikan di sini berdasarkan metodologi kertas:
Untuk detail konseptual lebih lanjut tentang implementasi, silakan lihat https://towardsdatacience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
Jika Anda menyukai pekerjaan saya, silakan pertimbangkan untuk mensponsori dengan mengklik tombol sponsor di bagian atas.
Persyaratan: Python (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Model Bert Pra-terlatih (Albert, Bert) milik Huggingface.co (https://huggingface.co)
Model biobert pra-terlatih milik https://github.com/dmis-lab/biobert
Untuk menggunakan biobert (biobert_v1.1_pubmed), unduh & unzip model dari sini ke folder ./additional_models.
Jalankan Main_Pretraining.py dengan argumen di bawah ini. Data pra-pelatihan dapat berupa file teks kontinu .txt.
Kami menggunakan Spacy NLP untuk mengambil entitas berpasangan (dalam ukuran jendela 40 token panjang) dari teks untuk membentuk pernyataan hubungan untuk pra-pelatihan. Pengakuan entitas didasarkan pada NER dan ketergantungan pohon penguraian objek/subjek.
Data pra-pelatihan yang diambil dari Dataset CNN (CNN.TXT) yang saya gunakan dapat diunduh di sini.
Unduh dan simpan sebagai ./data/cnn.txt
Namun, perhatikan bahwa makalah ini menggunakan data wiki dumps untuk pra-pelatihan MTB yang jauh lebih besar dari dataset CNN.
Catatan: Pra-pelatihan bisa memakan waktu lama, tergantung pada GPU yang tersedia. Dimungkinkan untuk secara langsung menyempurnakan tugas ekstraksi hubungan dan masih mendapatkan hasil yang masuk akal, mengikuti bagian di bawah ini.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Jalankan Main_task.py dengan argumen di bawah ini. Membutuhkan SEMEVAL2010 Dataset Tugas 8, tersedia di sini. Unduh & unzip ke ./data/ folder.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Untuk menyimpulkan sebuah kalimat, Anda dapat memberi anotasi entitas1 & entitas2 yang menarik dalam kalimat dengan tag entitas masing -masing [E1], [E2]. Contoh:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) Skrip juga dapat secara otomatis mendeteksi entitas potensial dalam kalimat input, dalam hal ini semua kemungkinan kombinasi hubungan disimpulkan:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Unduh dataset Sewrel 1.0 di sini. dan unzip ke ./data/ folder.
Jalankan Main_Task.py dengan argumen 'tugas' ditetapkan sebagai 'fewrel'.
python main_task.py --task fewrel Hasil:
(5 arah 1-shot)
Bert em tanpa mtb, tidak dilatih pada data apa pun
| Ukuran model | Akurasi (41646 sampel) |
|---|---|
| Bert-Base-Incased | 62.229 % |
| Bert-Large-Incased | 72.766 % |
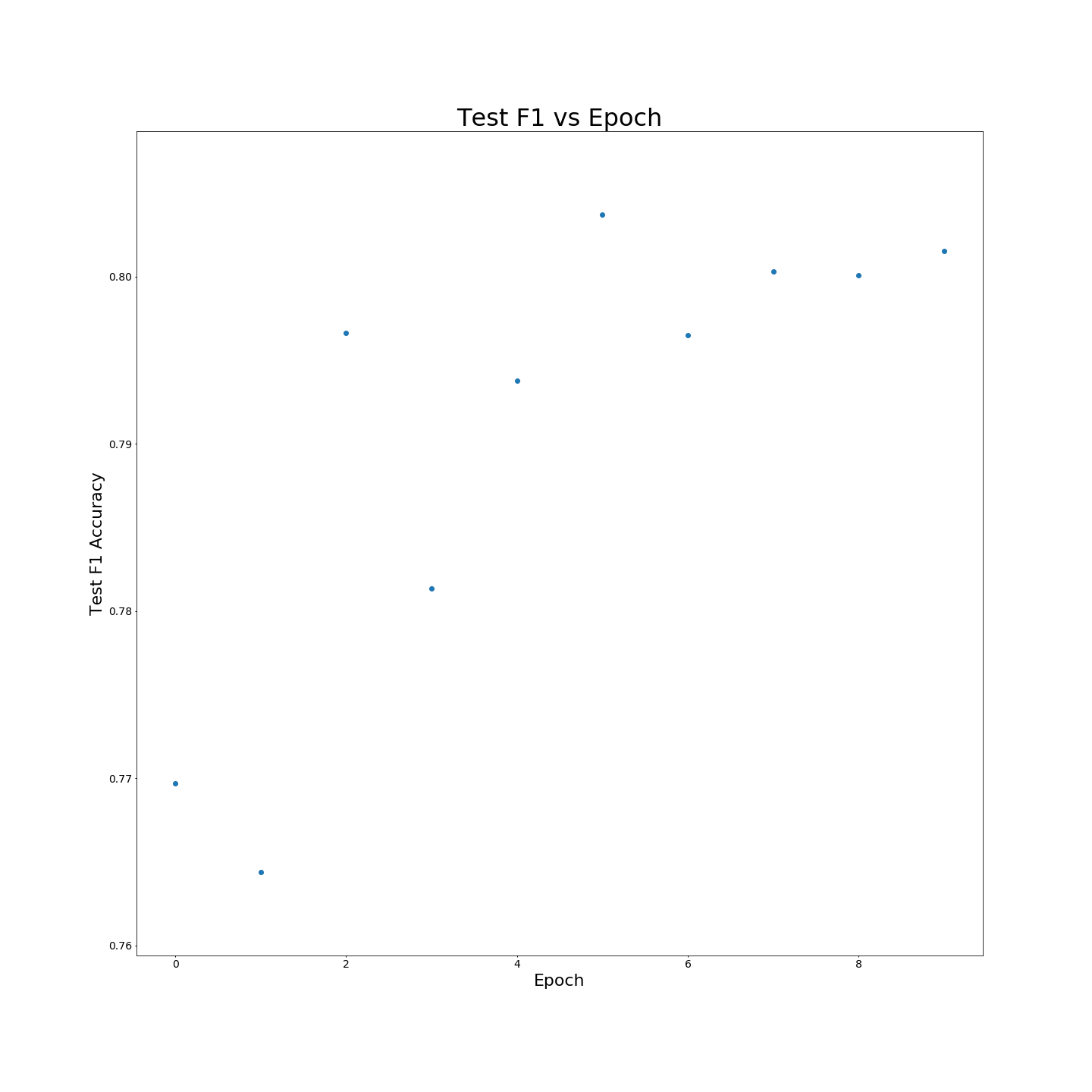
Tanpa pra-pelatihan MTB: Hasil F1 saat dilatih pada data pelatihan 100 %: 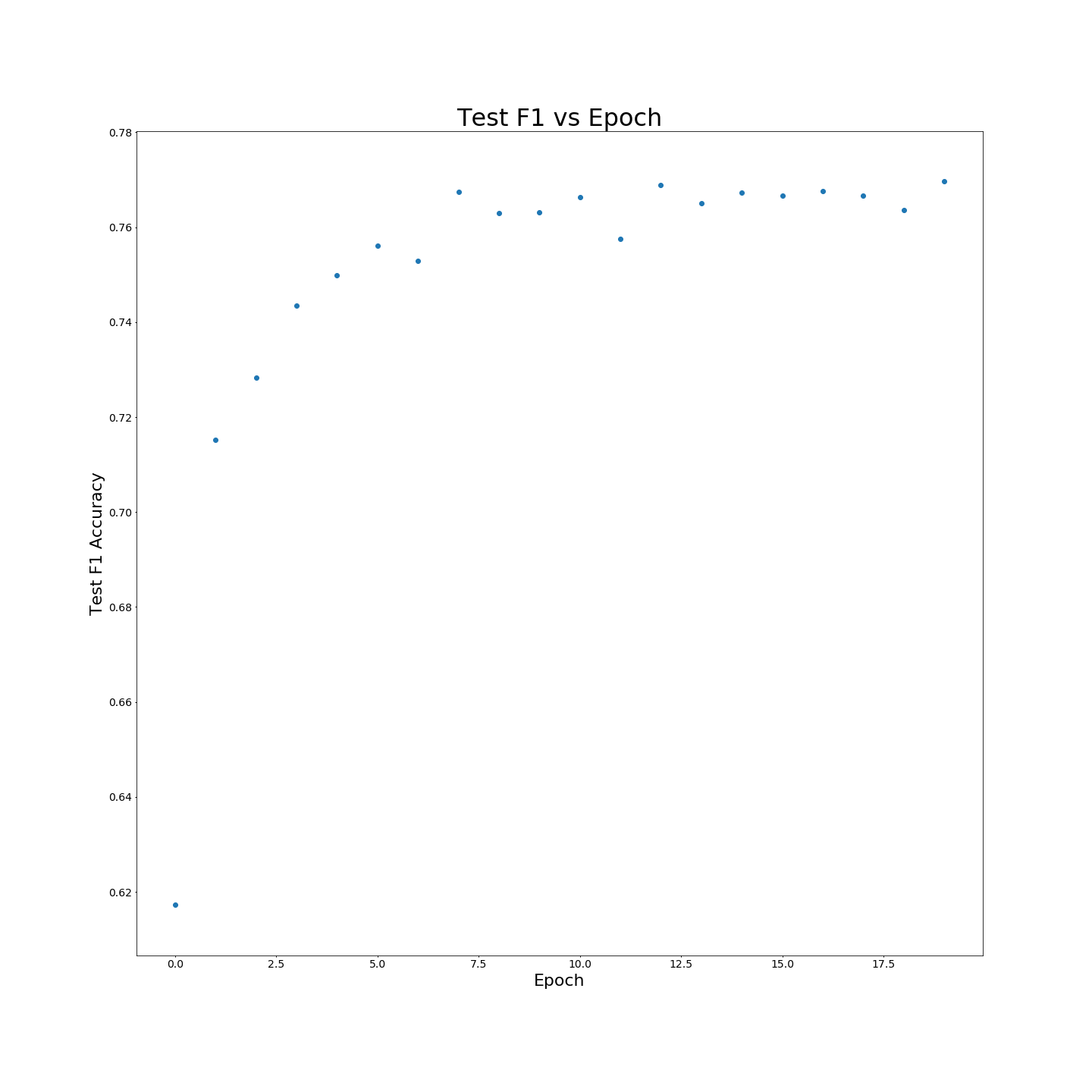
Tanpa pra-pelatihan MTB: Hasil F1 saat dilatih pada data pelatihan 100 %: