BERT Relation Extraction
1.0.0
Uma implementação de Pytorch dos modelos para o artigo "Combinando os espaços em branco: similaridade distributiva para aprendizado de relação" publicada no ACL 2019.
Nota: Este não é um repositório oficial para o artigo.
Modelos adicionais para extração de relações, implementados aqui com base na metodologia do artigo:
Para detalhes conceituais sobre a implementação, consulte https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
Se você gosta do meu trabalho, considere patrocinar clicando no botão Patrocinador na parte superior.
Requisitos: Python (3,8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Modelos Bert pré-treinados (Albert, Bert), cortesia de huggingface.co (https://huggingface.co)
Modelo BioBert pré-treinado cortesia de https://github.com/dmis-lab/biobert
Para usar o BioBert (biobert_v1.1_pubmed), faça o download e descompacte o modelo daqui para ./additional_models.
Execute main_pretraining.py com argumentos abaixo. Os dados de pré-treinamento podem ser qualquer arquivo de texto contínuo .txt.
Utilizamos o PN Spacy para pegar entidades em pares (dentro de um tamanho de janela de 40 tokens de comprimento) do texto para formar declarações de relação para pré-treinamento. O reconhecimento de entidades é baseado no NER e na análise de árvores de dependência de objetos/sujeitos.
Os dados de pré-treinamento retirados do conjunto de dados CNN (cnn.txt) que eu usei podem ser baixados aqui.
Baixe e salve como ./data/cnn.txt
No entanto, observe que o artigo usa dados do Wiki Dumps para o pré-treinamento MTB, que é muito maior que o conjunto de dados da CNN.
Nota: O pré-treinamento pode levar muito tempo, dependendo da GPU disponível. É possível ajustar diretamente a tarefa de extração de relação e ainda obter resultados razoáveis, seguindo a seção abaixo.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Execute main_task.py com argumentos abaixo. Requer o conjunto de dados semeval2010 Task 8, disponível aqui. Download e descompacte para ./data/ pasta.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Para inferir uma frase, você pode anotar entidade1 e entidade2 de interesse dentro da frase com suas respectivas tags de entidades [E1], [E2]. Exemplo:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) O script também pode detectar automaticamente entidades em potencial em uma frase de entrada; nesse caso, todas as combinações possíveis de relação são inferidas:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Faça o download do conjunto de dados do Fewrel 1.0 aqui. e descompacte para ./data/ pasta.
Execute main_task.py com o argumento 'Task' definido como 'poucos'.
python main_task.py --task fewrel Resultados:
(5 vias 1-shot)
Bert EM sem MTB, não treinado em poucos dados
| Tamanho do modelo | Precisão (41646 amostras) |
|---|---|
| Bert-Base-ANSed | 62,229 % |
| Bert-Large-Baseado | 72,766 % |
Sem o pré-treinamento do MTB: os resultados da F1 quando treinados em dados de treinamento 100 %: 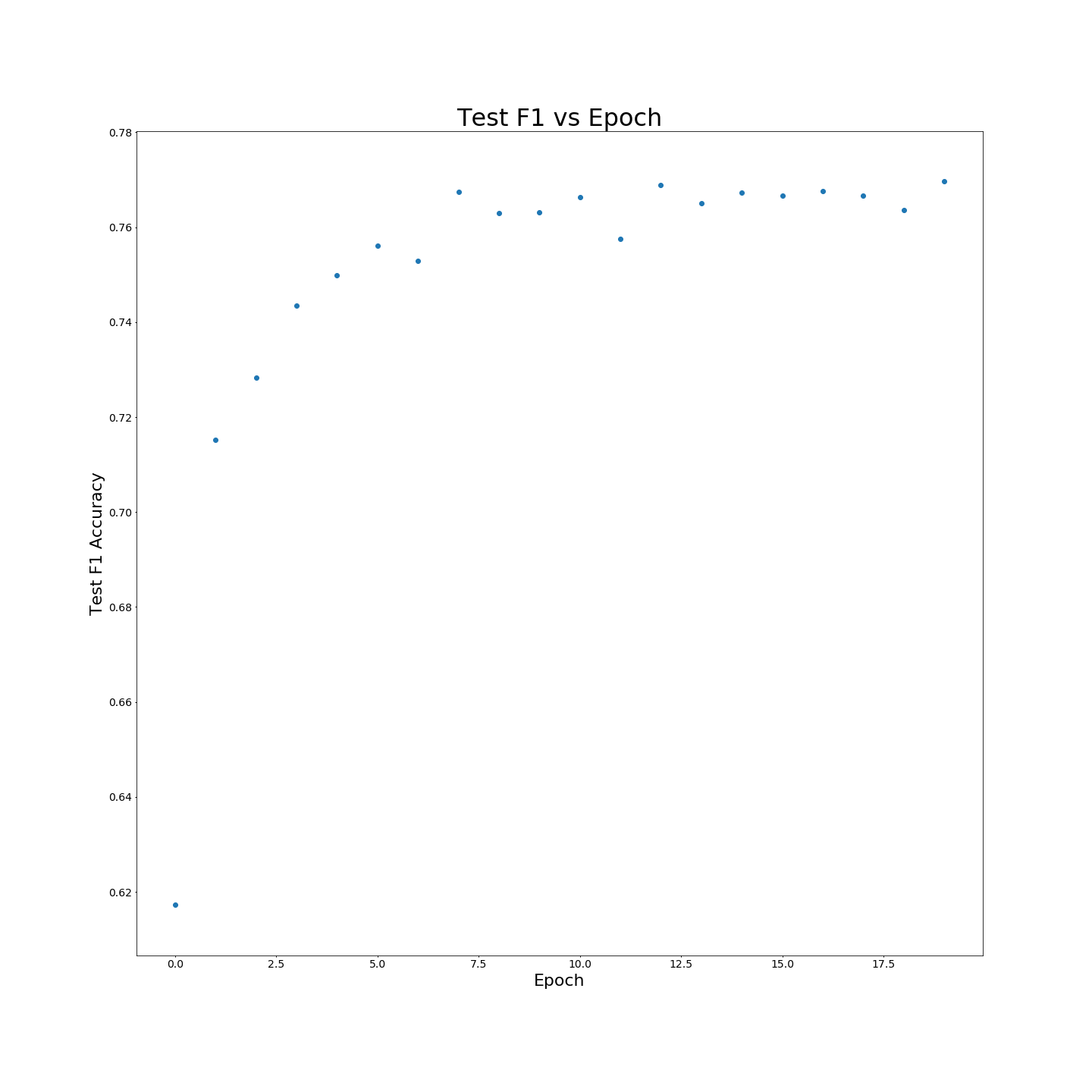
Sem o pré-treinamento do MTB: os resultados da F1 quando treinados em dados de treinamento 100 %: