BERT Relation Extraction
1.0.0
Una implementación de Pytorch de los modelos para el documento "que coincide con los espacios en blanco: similitud de distribución para el aprendizaje de relaciones" publicada en ACL 2019.
Nota: Este no es un repositorio oficial para el periódico.
Modelos adicionales para la extracción de relaciones, implementados aquí basados en la metodología del documento:
Para obtener más detalles conceptuales sobre la implementación, consulte https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
Si le gusta mi trabajo, considere patrocinar haciendo clic en el botón de patrocinador en la parte superior.
Requisitos: Python (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Modelos Bert previamente capacitados (Albert, Bert) cortesía de Huggingface.co (https://huggingface.co)
Modelo de BioBert pre-entrenado cortesía de https://github.com/dmis-lab/biobert
Para usar BIOBERT (BIOBERT_V1.1_PUBMED), descargue y descomprima el modelo de aquí a ./Additional_Models.
Ejecute main_praTraining.py con argumentos a continuación. Los datos de pre-entrenamiento pueden ser cualquier archivo de texto continuo .txt.
Utilizamos Spacy NLP para agarrar entidades por pares (dentro de un tamaño de ventana de 40 tokens de longitud) desde el texto para formar declaraciones de relación para la capacitación previa. El reconocimiento de entidades se basa en el análisis de objetos/sujetos NER y de dependencia de objetos/sujetos.
Los datos de pre-entrenamiento tomados del conjunto de datos CNN (cnn.txt) que he usado se pueden descargar aquí.
Descargar y guardar como ./data/cnn.txt
Sin embargo, tenga en cuenta que el documento utiliza datos de volcados Wiki para el pre-entrenamiento de MTB, que es mucho más grande que el conjunto de datos CNN.
Nota: El pre-entrenamiento puede llevar mucho tiempo, dependiendo de la GPU disponible. Es posible ajustar directamente la tarea de extracción de relación y aún así obtener resultados razonables, siguiendo la sección a continuación.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Ejecute main_task.py con argumentos a continuación. Requiere Semeval2010 Tarea 8 DataSet, disponible aquí. Descargar y descifrar a ./data/ carpeta.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Para inferir una oración, puede anotar la entidad1 y la entidad2 de interés dentro de la oración con sus respectivas entidades Etiquetas [E1], [E2]. Ejemplo:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) El script también puede detectar automáticamente entidades potenciales en una oración de entrada, en cuyo caso se infieren todas las combinaciones de relaciones posibles:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Descargue el conjunto de datos Flewrel 1.0 aquí. y descifrar a ./data/ carpeta.
Ejecute main_task.py con argumento 'Tarea' establecido como 'Fewrel'.
python main_task.py --task fewrel Resultados:
(5-Shot 1-shot)
Bert EM sin MTB, no entrenado en ningún Dato de FleSrel
| Tamaño del modelo | Precisión (41646 muestras) |
|---|---|
| base-base | 62.229 % |
| bert-grande | 72.766 % |
Sin la capacitación de MTB: F1 resulta cuando se entrenan en datos de entrenamiento del 100 %: 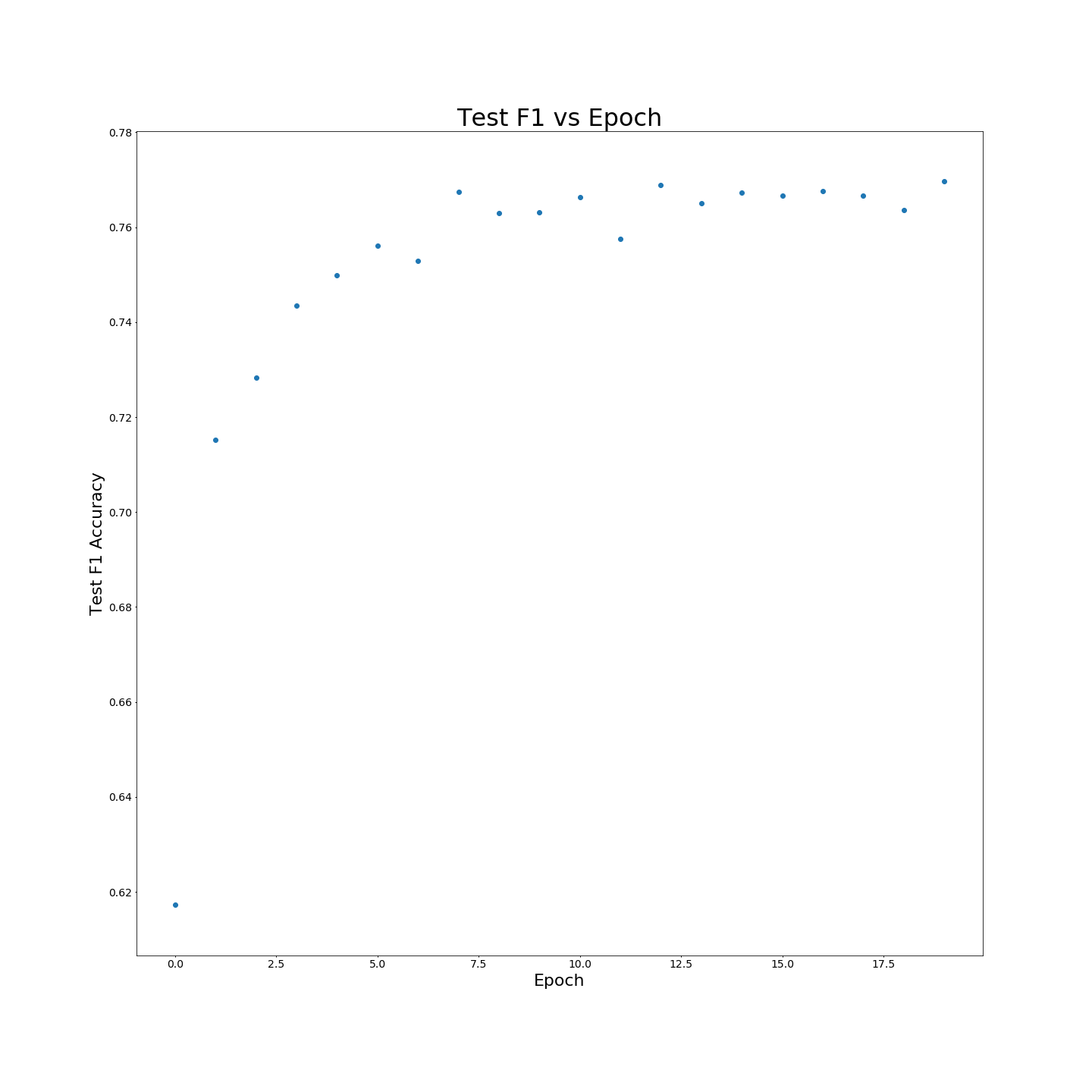
Sin la capacitación de MTB: F1 resulta cuando se entrenan en datos de entrenamiento del 100 %: