BERT Relation Extraction
1.0.0
Une mise en œuvre en pytorch des modèles pour l'article "Matching the Blanks: Distributional similitude pour l'apprentissage des relations" publié dans ACL 2019.
Remarque: Ce n'est pas un dépôt officiel du journal.
Des modèles supplémentaires d'extraction de relations, mis en œuvre ici sur la base de la méthodologie du document:
Pour plus de détails conceptuels sur la mise en œuvre, veuillez consulter https://towardsdatascience.com/bert-s-for-lalation-extraction-in- nlp-2c7c3ab487c4
Si vous aimez mon travail, envisagez de parrainer en cliquant sur le bouton Sponsor en haut.
Exigences: Python (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Modèles Bert pré-formés (Albert, Bert) gracieuseté de HuggingFace.co (https://huggingface.co)
Modèle de biobert pré-entraîné avec l'aimable autorisation de https://github.com/dmis-lab/biobert
Pour utiliser Biobert (biobert_v1.1_pubmed), téléchargez et dézip le modèle d'ici à ./additional_models.
Exécutez main_pretraining.py avec des arguments ci-dessous. Les données de pré-formation peuvent être n'importe quel fichier texte continu .txt.
Nous utilisons Spacy NLP pour saisir des entités par paire (dans une taille de fenêtre de 40 tutles de longueur) à partir du texte pour former des instructions de relation pour la pré-formation. La reconnaissance des entités est basée sur l'analyse des arbres NER et de dépendance des objets / sujets.
Les données de pré-formation tirées de CNN DataSet (CNN.TXT) que j'ai utilisées peuvent être téléchargées ici.
Télécharger et enregistrer sous ./data/cnn.txt
Cependant, notez que le papier utilise des données de vidage Wiki pour la pré-formation MTB qui est beaucoup plus grande que l'ensemble de données CNN.
Remarque: la pré-formation peut prendre beaucoup de temps, selon le GPU disponible. Il est possible de s'adapter directement à la tâche d'extraction de relation et d'obtenir des résultats raisonnables, suivant la section ci-dessous.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Exécutez main_task.py avec des arguments ci-dessous. Nécessite un ensemble de données SEMEVAL2010 Tâche 8, disponible ici. Téléchargez et dézip dans ./data/ dossier.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Pour déduire une phrase, vous pouvez annoter Entity1 & Entity2 d'intérêt au sein de la phrase avec leurs étiquettes entités respectives [E1], [E2]. Exemple:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) Le script peut également détecter automatiquement les entités potentielles dans une phrase d'entrée, auquel cas toutes les combinaisons de relations possibles sont déduites:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Téléchargez ici l'ensemble de données FewRel 1.0. et unzip to ./data/ dossier.
Exécutez main_task.py avec l'argument «tâche» définir comme «FewRel».
python main_task.py --task fewrel Résultats:
(5 voies 1-Shot)
Bert Em sans VTT, non formé sur des données de quelques-uns
| Taille du modèle | Précision (41646 échantillons) |
|---|---|
| bert-base | 62,229% |
| bert-gard | 72,766% |
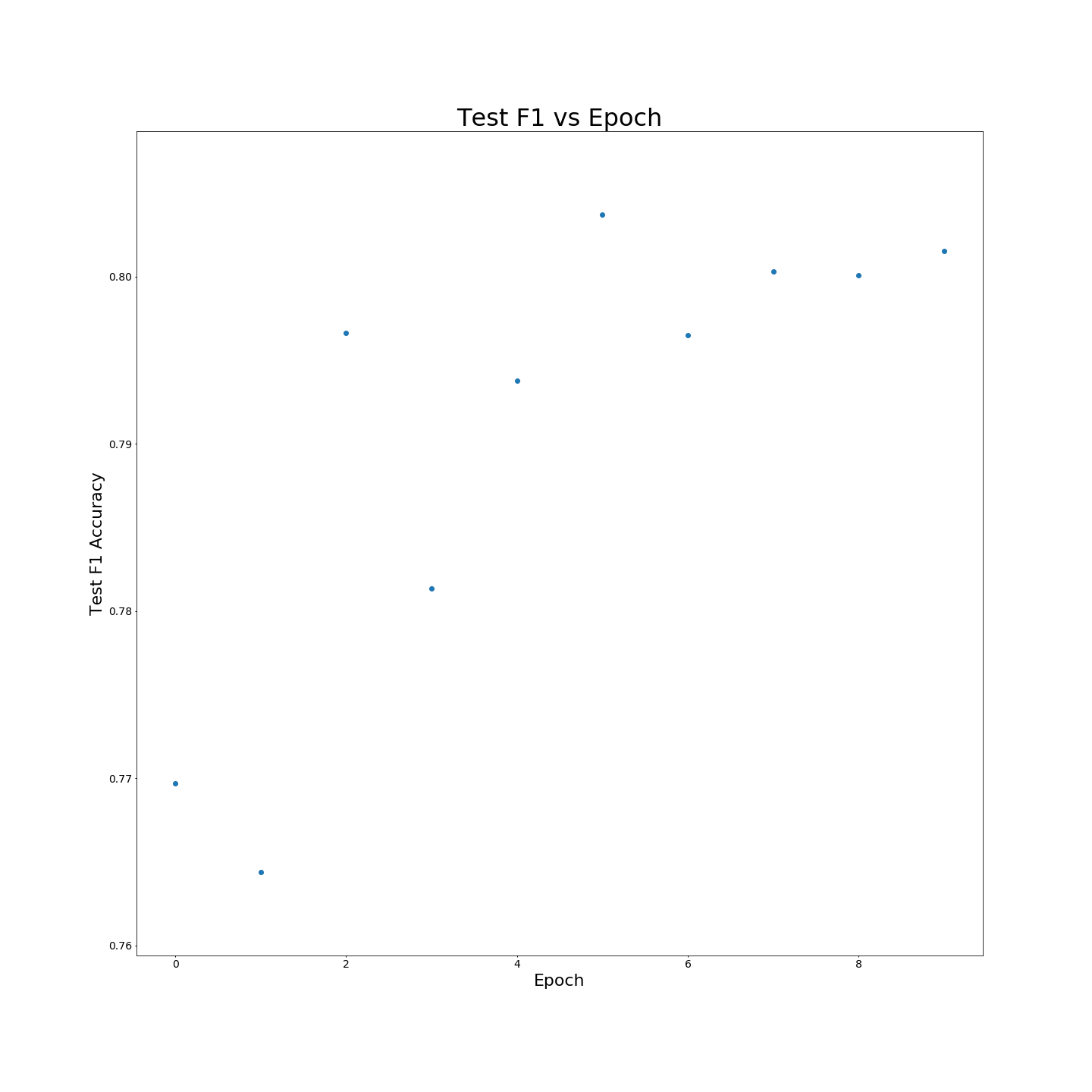
Sans pré-formation VTT: résultats F1 lorsqu'il est formé sur des données de formation à 100%: 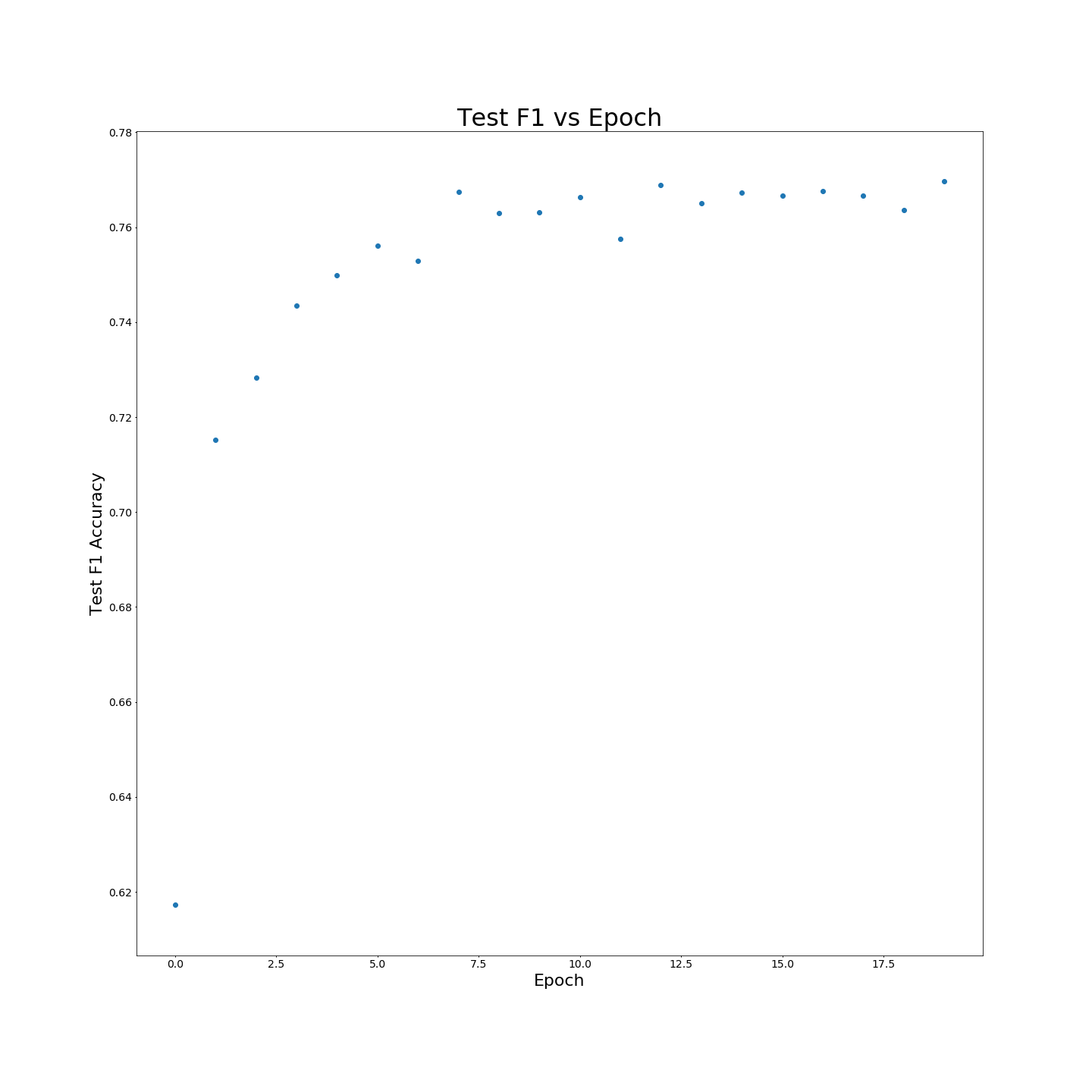
Sans pré-formation VTT: résultats F1 lorsqu'il est formé sur des données de formation à 100%: