BERT Relation Extraction
1.0.0
Eine in der ACL 2019 veröffentlichte Pytorch -Implementierung der Modelle für das Papier "Matching the Rohles: Distributional Eyeity for Relation Learning".
Hinweis: Dies ist kein offizielles Repo für das Papier.
Zusätzliche Modelle für die Beziehungsextraktion, die hier basierend auf der Methodik des Papiers implementiert wurde:
Weitere konzeptionelle Details zur Implementierung finden Sie unter https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
Wenn Ihnen meine Arbeit gefällt, sollten Sie das Sponsoring in Betracht ziehen, indem Sie oben auf die Schaltfläche Sponsor klicken.
Anforderungen: Python (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Vorausgebildete Bert-Modelle (Albert, Bert) mit freundlicher Genehmigung von Huggingface.co (https://huggingface.co)
Vorausgebildeter Biobert-Modell mit freundlicher Genehmigung von https://github.com/dmis-lab/biobert
Um Biobert (Biobert_v1.1_Pubmed) zu verwenden, laden Sie das Modell von hier nach ./Additional_Models Ordner herunter und entpacken Sie.
Führen Sie Main_Pretraining.py mit Argumenten unten aus. Voraussetzungsdaten können eine beliebige kontinuierliche Textdatei von .txt sein.
Wir verwenden Spacy NLP, um paarweise Entitäten (innerhalb einer Fenstergröße von 40 Token-Länge) vom Text zur Formulierung von Relation-Anweisungen für die Vorausbildung zu greifen. Die Erkennung von Entitäten basiert auf NER- und Abhängigkeitsbaum -Parsen von Objekten/Subjekten.
Die von CNN Dataset (cnn.txt), die ich verwendeten CNN-Dataset (CNN.TXT), entnommen werden können, können hier heruntergeladen werden.
Download und speichern as ./data/cnn.txt
Beachten Sie jedoch, dass das Papier Wiki-Dump-Daten für MTB-Voraussetzungen verwendet, die viel größer sind als der CNN-Datensatz.
Hinweis: Je nach verfügbarem GPU kann es lange dauern. Es ist möglich, die Relation-Extraction-Aufgabe direkt zu optimieren und immer noch angemessene Ergebnisse zu erzielen, folgt dem folgenden Abschnitt.
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]Führen Sie Main_task.py mit Argumenten unten aus. Benötigt Semeval2010 Aufgabe 8 Datensatz, hier verfügbar. Download & Unzipp auf ./data/ Ordner.
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]Um einen Satz zu schließen, können Sie Entity1 & Entity2 von Interesse innerhalb des Satzes mit ihren jeweiligen Entitäten -Tags [E1], [E2] kommentieren. Beispiel:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) Das Skript kann auch potenzielle Entitäten in einem Eingabegestand automatisch erkennen. In diesem Fall werden alle möglichen Beziehungskombinationen abgeleitet:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) Laden Sie hier den Dataset Fewsrel 1.0 herunter. und entpacken Sie zu ./data/ Ordner.
Führen Sie main_task.py mit Argument 'Task' als "WegeRel" aus.
python main_task.py --task fewrel Ergebnisse:
(5-Wege 1-Shot)
Bert EM ohne MTB, nicht auf irgendwelchen Daten ausgebildet
| Modellgröße | Genauigkeit (41646 Proben) |
|---|---|
| Bert-Base-Unbekannt | 62,229 % |
| Bert-large-unbekannt | 72,766 % |
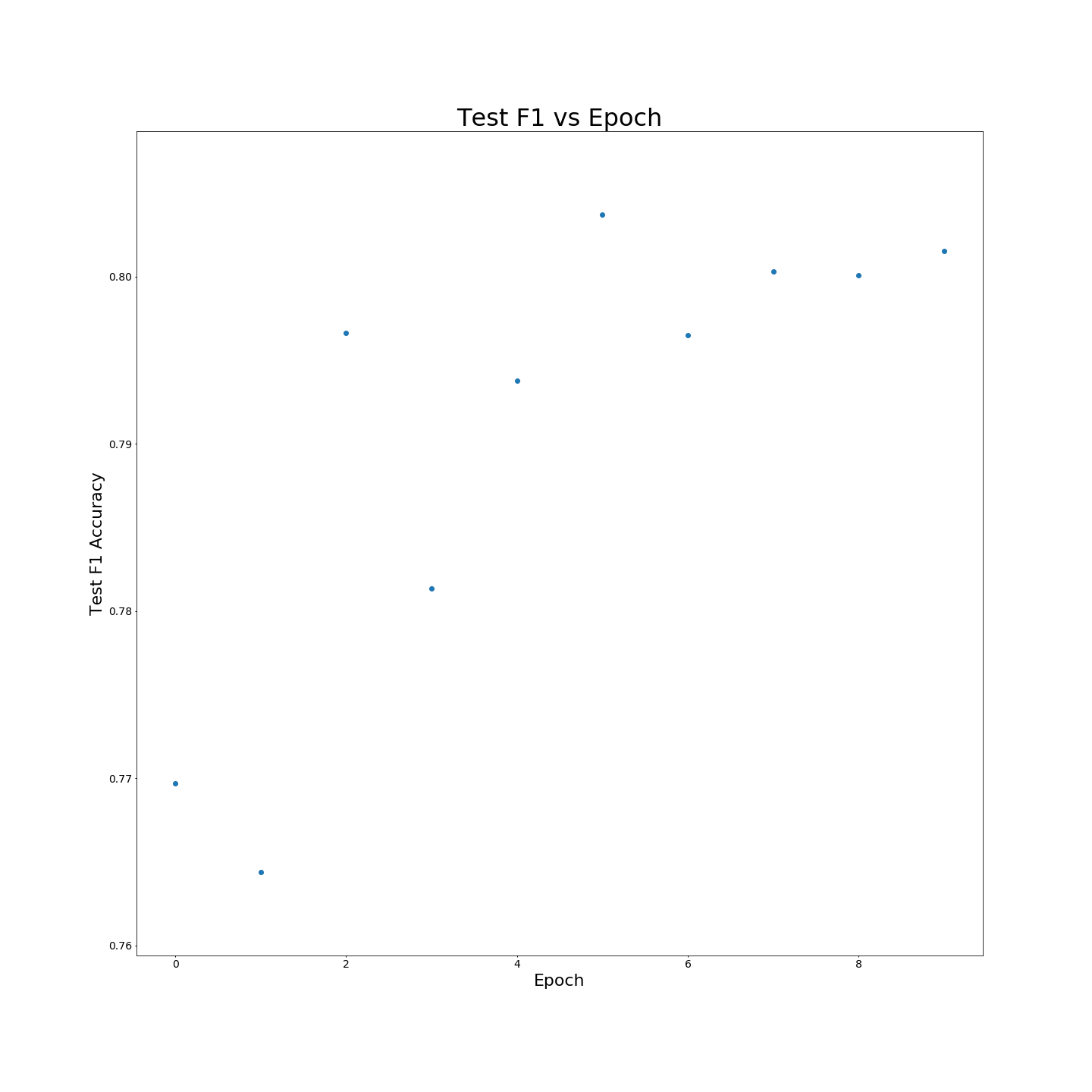
Ohne MTB-Vorausbildung: F1 Ergebnisse bei trainierenden 100 % igen Trainingsdaten: 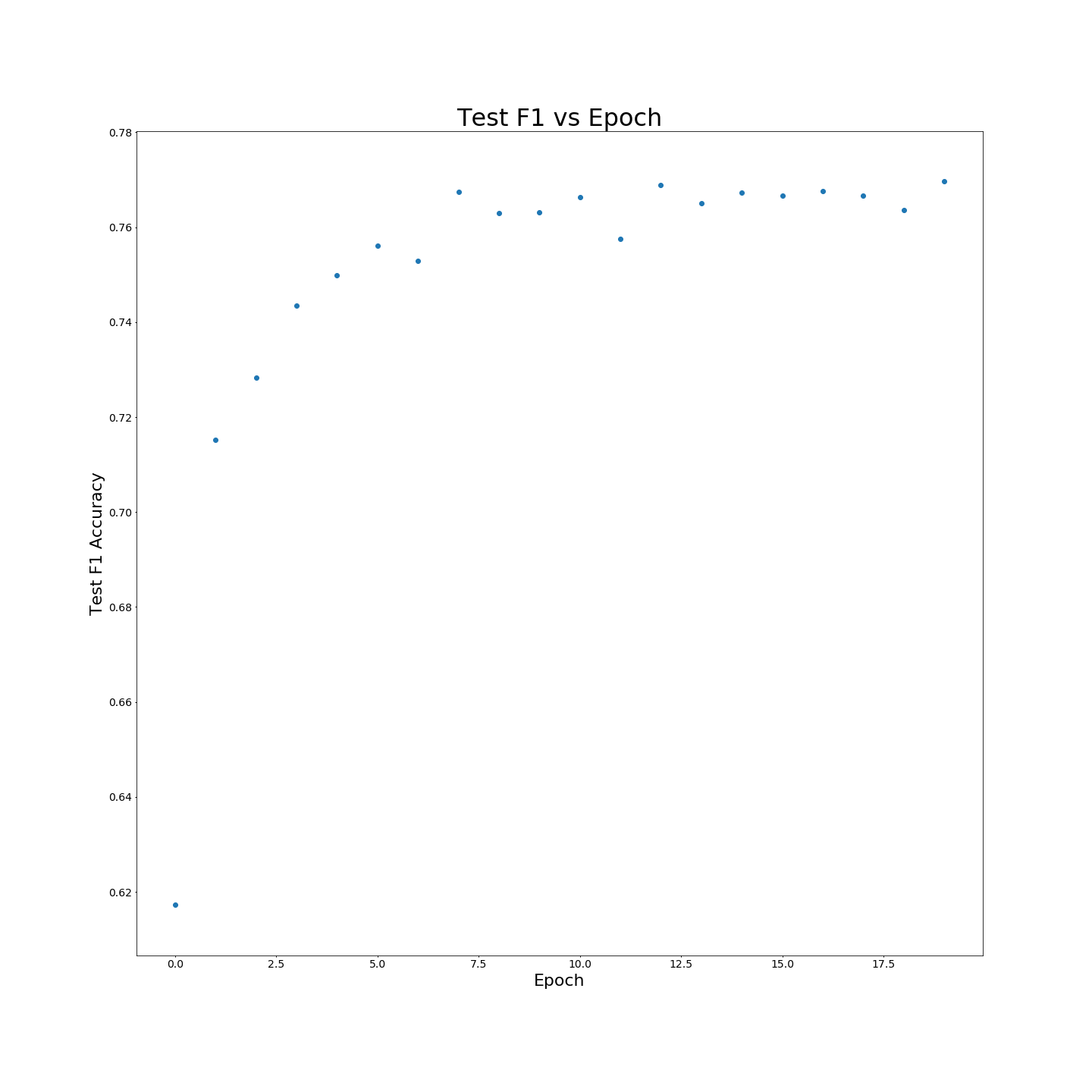
Ohne MTB-Vorausbildung: F1 Ergebnisse bei trainierenden 100 % igen Trainingsdaten: