BERT Relation Extraction
1.0.0
การใช้งาน Pytorch ของแบบจำลองสำหรับกระดาษ "จับคู่ช่องว่าง: ความคล้ายคลึงกันแบบกระจายสำหรับการเรียนรู้ความสัมพันธ์" ที่ตีพิมพ์ใน ACL 2019
หมายเหตุ: นี่ไม่ใช่การซื้อคืนอย่างเป็นทางการสำหรับกระดาษ
แบบจำลองเพิ่มเติมสำหรับการแยกความสัมพันธ์นำไปใช้ที่นี่ตามวิธีการของกระดาษ:
สำหรับรายละเอียดแนวคิดเพิ่มเติมเกี่ยวกับการใช้งานโปรดดู https://towardsdatascience.com/bert-s-for-relation-extraction-in-nlp-2c7c3ab487c4
หากคุณชอบงานของฉันโปรดพิจารณาการสนับสนุนโดยคลิกที่ปุ่มสปอนเซอร์ที่ด้านบน
ข้อกำหนด: Python (3.8+)
python3 -m pip install -r requirements.txt
python3 -m spacy download en_core_web_lg Models Bert ที่ผ่านการฝึกอบรมมาก่อน (Albert, Bert) ได้รับความอนุเคราะห์จาก HuggingFace.co (https://huggingface.co)
รูปแบบ Bibert ที่ผ่านการฝึกอบรมมาก่อน https://github.com/dmis-lab/biobert
หากต้องการใช้ Biobert (BIOBERT_V1.1_PUBMED), ดาวน์โหลดและคลายซิปโมเดลจากที่นี่เป็น ./ADDITIONAL_MODELS โฟลเดอร์
เรียกใช้ main_pretraining.py พร้อมอาร์กิวเมนต์ด้านล่าง ข้อมูลการฝึกอบรมล่วงหน้าอาจเป็นไฟล์ข้อความต่อเนื่อง. txt
เราใช้ Spacy NLP เพื่อคว้าเอนทิตีคู่ (ภายในขนาดหน้าต่างที่มีความยาวโทเค็น 40) จากข้อความเป็นรูปแบบคำสั่งความสัมพันธ์สำหรับการฝึกอบรมล่วงหน้า การรับรู้เอนทิตีขึ้นอยู่กับการแยกวิเคราะห์ต้นไม้และการพึ่งพาของวัตถุ/วิชา
ข้อมูลการฝึกอบรมล่วงหน้าที่นำมาจากชุดข้อมูล CNN (cnn.txt) ที่ฉันใช้สามารถดาวน์โหลดได้ที่นี่
ดาวน์โหลดและบันทึกเป็น./data/cnn.txt
อย่างไรก็ตามโปรดทราบว่ากระดาษใช้ Wiki Dumps Data สำหรับการฝึกอบรมล่วงหน้า MTB ซึ่งมีขนาดใหญ่กว่าชุดข้อมูล CNN มาก
หมายเหตุ: การฝึกอบรมล่วงหน้าอาจใช้เวลานานขึ้นอยู่กับ GPU ที่มีอยู่ เป็นไปได้ที่จะปรับแต่งงานการสกัดสัมพันธ์โดยตรงและยังคงได้รับผลลัพธ์ที่สมเหตุสมผลตามส่วนด้านล่าง
main_pretraining.py [-h]
[--pretrain_data TRAIN_PATH]
[--batch_size BATCH_SIZE]
[--freeze FREEZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]เรียกใช้ main_task.py พร้อมอาร์กิวเมนต์ด้านล่าง ต้องใช้ชุดข้อมูล Semeval2010 TASK 8 มีให้ที่นี่ ดาวน์โหลด & unzip ถึง ./data/ โฟลเดอร์
main_task.py [-h]
[--train_data TRAIN_DATA]
[--test_data TEST_DATA]
[--use_pretrained_blanks USE_PRETRAINED_BLANKS]
[--num_classes NUM_CLASSES]
[--batch_size BATCH_SIZE]
[--gradient_acc_steps GRADIENT_ACC_STEPS]
[--max_norm MAX_NORM]
[--fp16 FP_16]
[--num_epochs NUM_EPOCHS]
[--lr LR]
[--model_no MODEL_NO (0: BERT ; 1: ALBERT ; 2: BioBERT)]
[--model_size MODEL_SIZE (BERT: ' bert-base-uncased ' , ' bert-large-uncased ' ;
ALBERT: ' albert-base-v2 ' , ' albert-large-v2 ' ;
BioBERT: ' bert-base-uncased ' (biobert_v1.1_pubmed))]
[--train TRAIN]
[--infer INFER]ในการอนุมานประโยคคุณสามารถใส่คำอธิบายประกอบ entity1 & entity2 ที่น่าสนใจภายในประโยคด้วยแท็กเอนทิตีของพวกเขา [E1], [e2] ตัวอย่าง:
Type input sentence ( ' quit ' or ' exit ' to terminate):
The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) from src . tasks . infer import infer_from_trained
inferer = infer_from_trained ( args , detect_entities = False )
test = "The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor."
inferer . infer_sentence ( test , detect_entities = False )Sentence: The surprise [E1]visit[/E1] caused a [E2]frenzy[/E2] on the already chaotic trading floor.
Predicted: Cause-Effect(e1,e2) สคริปต์ยังสามารถตรวจจับเอนทิตีที่อาจเกิดขึ้นในประโยคอินพุตโดยอัตโนมัติซึ่งในกรณีนี้การรวมกันของความสัมพันธ์ที่เป็นไปได้ทั้งหมดจะถูกอนุมาน:
inferer = infer_from_trained ( args , detect_entities = True )
test2 = "After eating the chicken, he developed a sore throat the next morning."
inferer . infer_sentence ( test2 , detect_entities = True )Sentence: [E2]After eating the chicken[/E2] , [E1]he[/E1] developed a sore throat the next morning .
Predicted: Other
Sentence: After eating the chicken , [E1]he[/E1] developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , [E2]he[/E2] developed a sore throat the next morning .
Predicted: Other
Sentence: [E1]After eating the chicken[/E1] , he developed [E2]a sore throat[/E2] the next morning .
Predicted: Other
Sentence: After eating the chicken , [E2]he[/E2] developed [E1]a sore throat[/E1] the next morning .
Predicted: Other
Sentence: [E2]After eating the chicken[/E2] , he developed [E1]a sore throat[/E1] the next morning .
Predicted: Cause-Effect(e2,e1) ดาวน์โหลดชุดข้อมูล DILLREL 1.0 ที่นี่ และเปิดเครื่องซิปไปยัง./ data/ โฟลเดอร์
เรียกใช้ main_task.py ด้วยอาร์กิวเมนต์ 'งาน' ตั้งค่าเป็น 'น้อย'
python main_task.py --task fewrel ผลลัพธ์:
(5-way 1-shot)
bert em ไม่มี mtb ไม่ได้รับการฝึกฝนเกี่ยวกับข้อมูลใด ๆ
| ขนาดรุ่น | ความแม่นยำ (41646 ตัวอย่าง) |
|---|---|
| เบิร์ตเบส | 62.229 % |
| เบิร์ต-ไม่มีขนาดใหญ่ | 72.766 % |
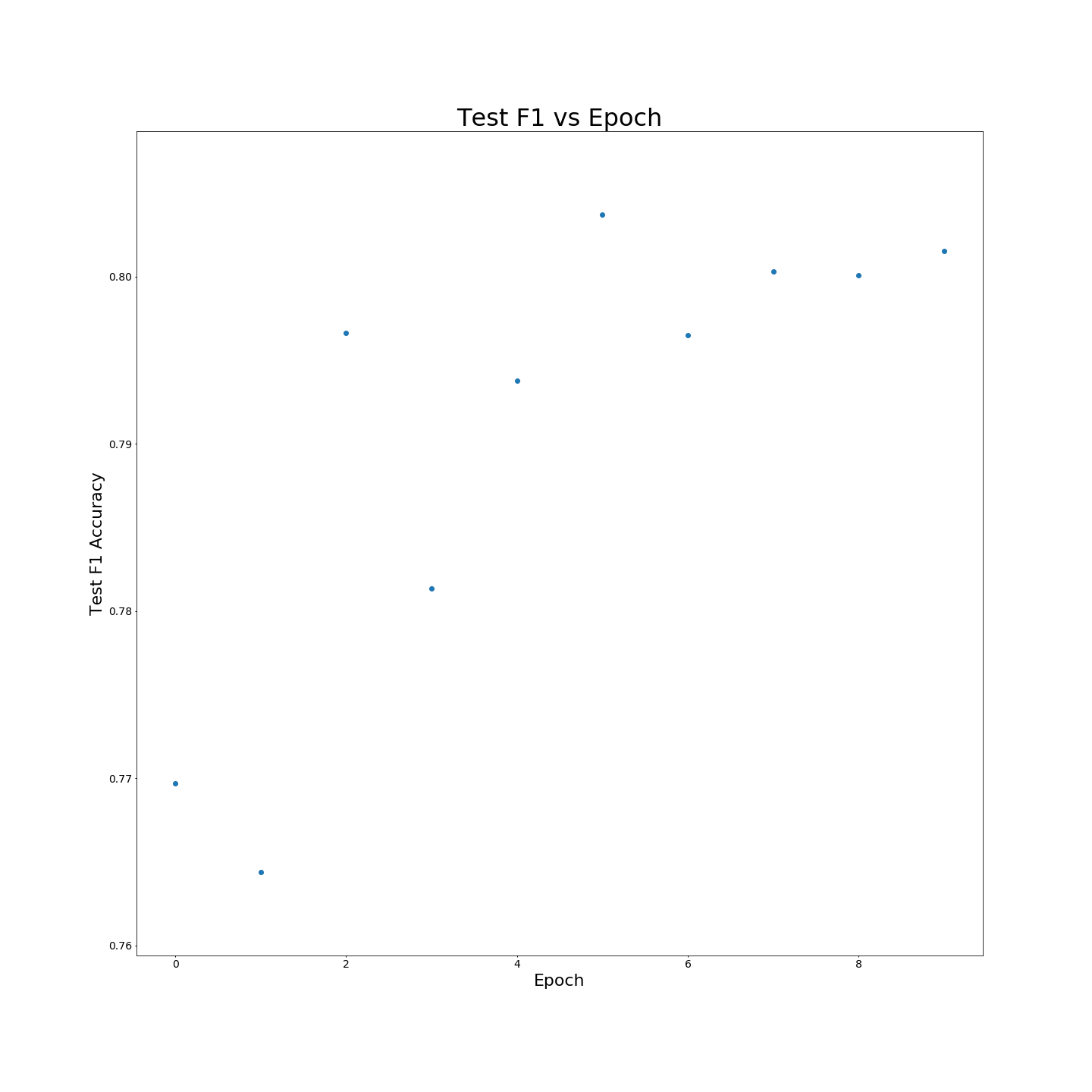
ไม่มีการฝึกอบรมล่วงหน้า MTB: ผลลัพธ์ F1 เมื่อได้รับการฝึกอบรมเกี่ยวกับข้อมูลการฝึกอบรม 100 %: 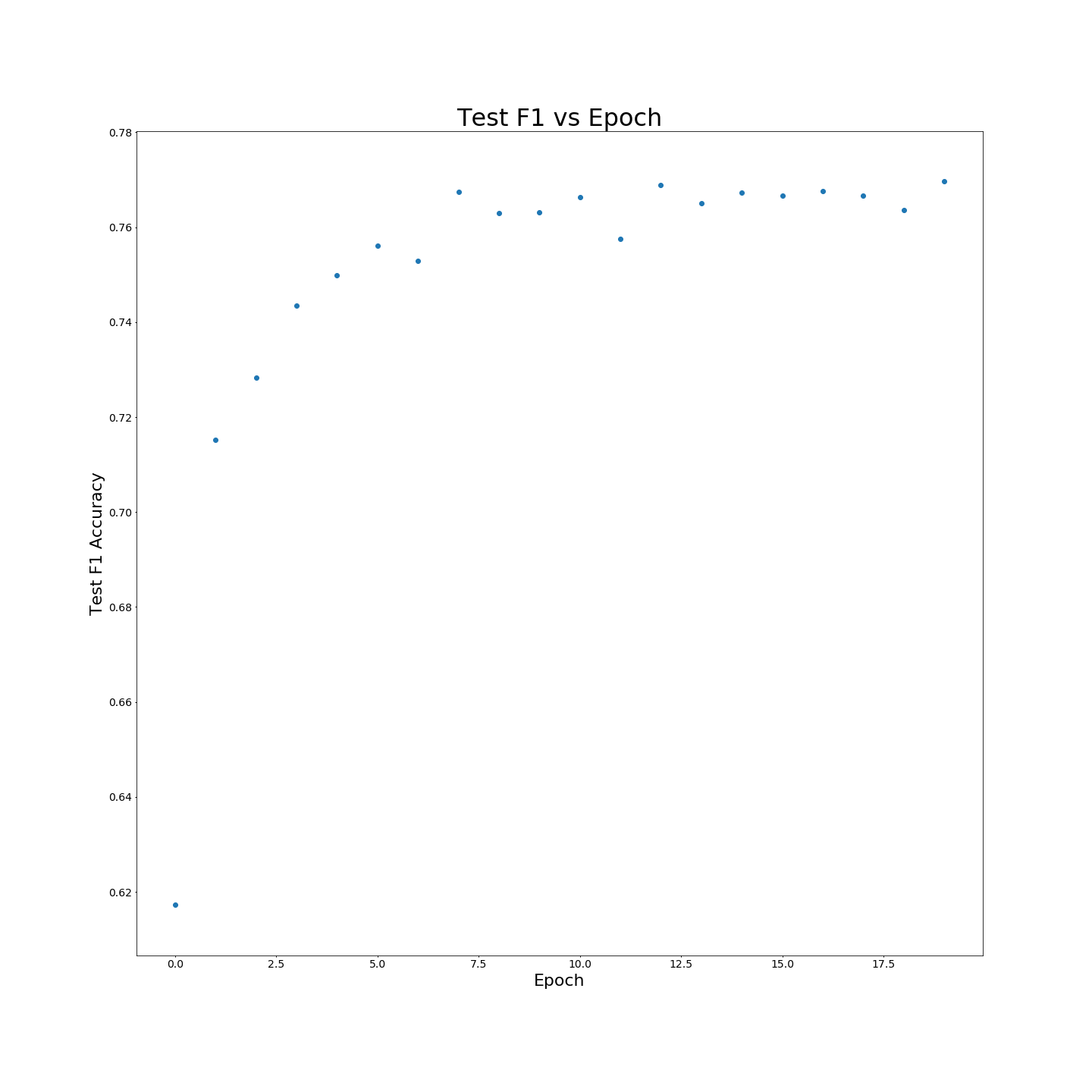
ไม่มีการฝึกอบรมล่วงหน้า MTB: ผลลัพธ์ F1 เมื่อได้รับการฝึกอบรมเกี่ยวกับข้อมูลการฝึกอบรม 100 %: