extreme bert
1.0.0
ExtremeTert是一种工具包,可加速定制数据集上BERT的预处理和填充。快速查看我们的文档和纸张。
我们简化了软件包所需的依赖关系的安装过程。可以通过单个命令source install.sh轻松安装它们。不需要其他步骤!
通过定义--total_training_time=24.0 (例如24小时),可以将预处理时间简化为基于时间的值。通过添加--fp16支持混合精度。
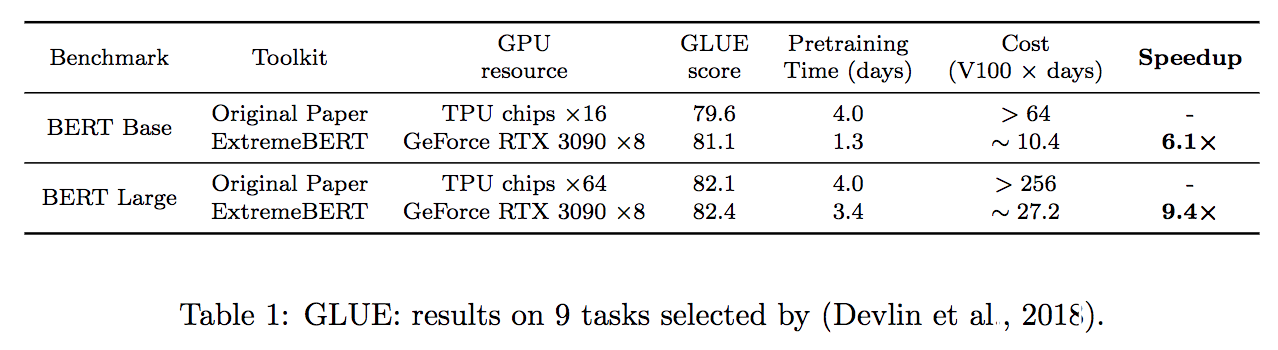
支持大量的预训练数据集。用户可以通过HuggingFace DataSet Hub轻松使用它们。此外,我们还支持用户的自定义数据集。
很难验证新优化方法在LM预训练中的有效性。借助我们的软件包,我们支持将自定义的优化器和调度程序集成到管道中,从而帮助优化社区的研究人员轻松验证其算法。有效的优化和数据处理算法也将添加到将来的发行版中。
| 模型 | 地位 |
|---|---|
| 伯特 | ✅支持 |
| 罗伯塔(Roberta),阿尔伯特(Albert),迪伯塔(Deberta) | ?发展 |
首先,可以参考configs/bert-simple.yaml并为管道制作合适的配置,包括数据集,可用的GPU数量等。
source install.sh ; python main.py --config configs/bert-simple.yaml它将运行环境安装,数据集预处理,预处理,填充和测试结果集合,并在output_test_translated/finetune/*/*.zip下生成.zip文件以提交胶水测试服务器提交的.zip文件。有关YAML配置文件的更多信息,请参考pipeline_config.md。
每个阶段的详细信息在以下各节中进行了说明。
运行source install.sh
dataset集目录包含脚本,以预处理我们在实验中使用的数据集(Wikipedia,bookcorpus)。有关完整的详细信息,请参见专用读书文件。
预读脚本: run_pretraining.py
有关所有可能的预处理的参数,请参见: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16使用run_glue.py在胶水任务上保存的检查点运行Finetuning。
Finetuning脚本与GinggingFace与我们的模型的添加相同。
有关所有可能的预处理的参数,请参见: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50如果您发现此存储库有用,则可以将我们的论文引用为:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
该守则的很大一部分是基于如何使用Apache 2.0许可的学术预算来培训BERT的。
有关使用此软件包的帮助或问题,请提交GitHub问题。
有关与此软件包相关的个人通讯,请联系Rui Pan([email protected])和Shizhe Diao([email protected])。


