extreme bert
1.0.0
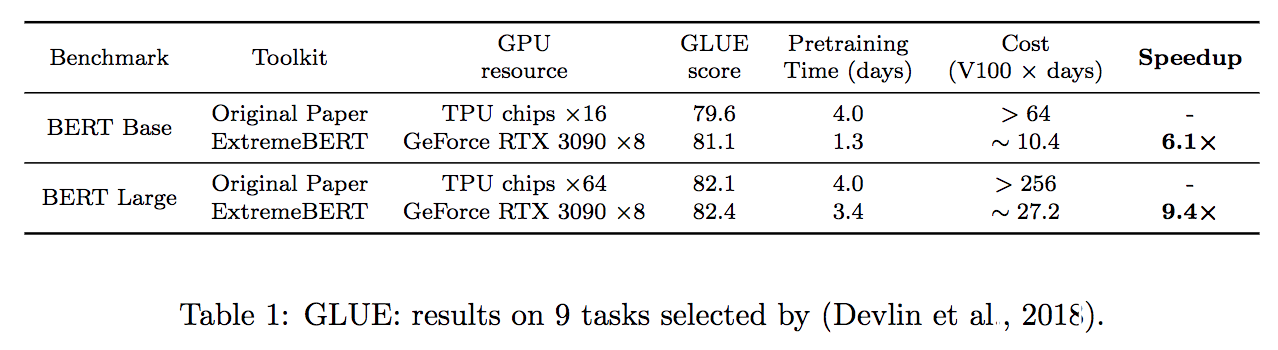
Extremebert - это инструментарий, который ускоряет предварительную подготовку и создание BERT на индивидуальных наборах данных. Посмотрите на нашу документацию и бумагу.
Мы упрощаем процесс установки зависимостей, требуемых пакетом. Они могут быть легко установлены с помощью одного source install.sh команды. Никаких других шагов не требуется!
Время предварительной подготовки может быть сокращено до уровня на основе времени путем определения --total_training_time=24.0 (например, 24 часа). Смешанная точность подтверждается добавлением --fp16 .
Поддержите большое количество наборов данных перед тренировкой. Пользователи могут легко использовать их с помощью Hub Datingface DataSet. Кроме того, мы также поддерживаем пользовательский набор данных пользователей.
Трудно проверить эффективность нового метода оптимизации в предварительной тренировке LM. С помощью нашего пакета мы поддерживаем интеграцию индивидуальных оптимизаторов и планировщиков в трубопровод, которые помогают исследователям в сообществе оптимизации легко проверить свои алгоритмы. Эффективные алгоритмы оптимизации и обработки данных также будут добавлены в будущие выпуски.
| Модель | Статус |
|---|---|
| БЕРТ | ✅ Поддерживается |
| Роберта, Альберт, Деберта | ? Развитие |
Во-первых, можно обратиться к configs/bert-simple.yaml и создать подходящие конфигурации для трубопровода, включая наборы данных, количество доступных графических процессоров и т. Д. Затем, просто выполнив следующую команду, весь конвейер будет выполняться на этапе
source install.sh ; python main.py --config configs/bert-simple.yaml который будет запускать установку среды, предварительное предварительное наборы, предварительное подготовку, создание и сборы результатов теста один за другим и генерируйте файл .zip для представления сервера тестирования клея в рамках output_test_translated/finetune/*/*.zip . Пожалуйста, обратитесь к Pipeline_config.md для получения дополнительной информации о файле конфигурации YAML.
Детали каждого этапа показаны в следующих разделах.
Запустите source install.sh
Каталог dataset включает в себя сценарии для предварительного обработки наборов данных, которые мы использовали в наших экспериментах (Wikipedia, BookCorpus). Смотрите выделенную Readme для получения полной информации.
Предварительный сценарий: run_pretraining.py
Для всех возможных предварительных аргументов см.: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Используйте run_glue.py , чтобы запустить Minetuning для сохраненной контрольной точки на задачах клей.
Сценарий создания идентичен тому, что предоставлено Huggingface с добавлением нашей модели.
Для всех возможных предварительных аргументов см.: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Если вы найдете этот репозиторий полезным, вы можете привести нашу статью как:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Значительная часть кода основана на том, как обучить Берт с академическим бюджетом, лицензированным в соответствии с Apache 2.0.
Для получения помощи или проблем с использованием этого пакета, пожалуйста, отправьте проблему GitHub.
Для личного общения, связанного с этим пакетом, пожалуйста, свяжитесь с Rui Pan ([email protected]) и Shizhe Diao ([email protected]).


