extreme bert
1.0.0
Extremebert เป็นชุดเครื่องมือที่เร่งการเตรียมการและ finetuning ของ Bert ในชุดข้อมูลที่กำหนดเอง ดูเอกสารและกระดาษของเราอย่างรวดเร็ว
เราทำให้กระบวนการติดตั้งง่ายขึ้นของการพึ่งพาที่ต้องการโดยแพ็คเกจ สามารถติดตั้งได้อย่างง่ายดายโดย source install.sh คำสั่งเดียว ไม่จำเป็นต้องมีขั้นตอนอื่น!
เวลาการเตรียมการสามารถลดลงเป็นค่าตามเวลาโดยการกำหนด --total_training_time=24.0 (ตัวอย่าง 24 ชั่วโมง) ความแม่นยำแบบผสมได้รับการสนับสนุนโดยการเพิ่ม --fp16
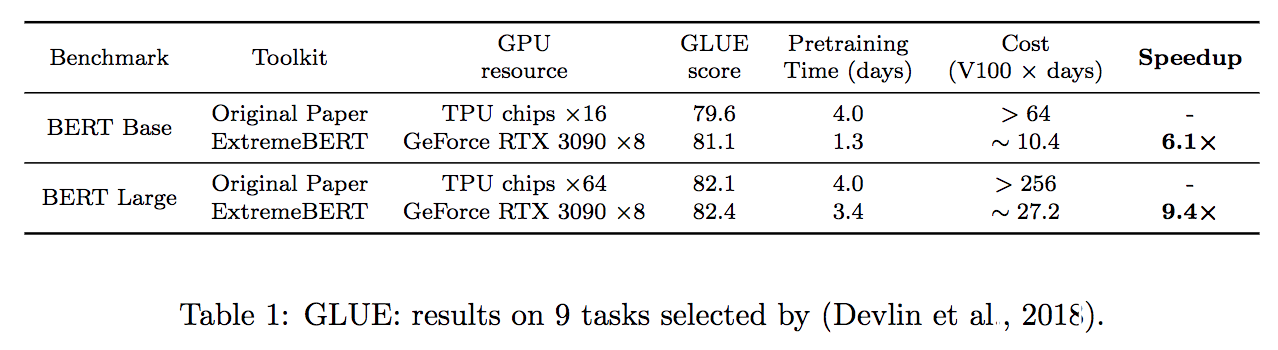
รองรับชุดข้อมูลก่อนการฝึกอบรมจำนวนมาก ผู้ใช้สามารถใช้งานได้อย่างง่ายดายผ่านศูนย์ข้อมูล HuggingFace นอกจากนี้เรายังสนับสนุนชุดข้อมูลที่กำหนดเองของผู้ใช้
เป็นการยากที่จะตรวจสอบประสิทธิภาพของวิธีการเพิ่มประสิทธิภาพใหม่ในการฝึกอบรมล่วงหน้า LM ด้วยแพ็คเกจของเราเราสนับสนุนการรวมตัวของตัวเพิ่มประสิทธิภาพและกำหนดเวลาที่กำหนดเองเข้ากับไปป์ไลน์ซึ่งช่วยให้นักวิจัยในชุมชนการปรับให้เหมาะสมสามารถตรวจสอบอัลกอริทึมของพวกเขาได้อย่างง่ายดาย การเพิ่มประสิทธิภาพที่มีประสิทธิภาพและอัลกอริธึมการประมวลผลข้อมูลจะถูกเพิ่มเข้าไปในการเปิดตัวในอนาคต
| แบบอย่าง | สถานะ |
|---|---|
| เบิร์ต | ✅สนับสนุน |
| Roberta, Albert, Deberta | - การพัฒนา |
ขั้นแรกหนึ่งอาจอ้างถึง configs/bert-simple.yaml และกำหนดค่าที่เหมาะสมสำหรับไปป์ไลน์รวมถึงชุดข้อมูลจำนวน GPU ที่มีอยู่ ฯลฯ จากนั้นเพียงแค่เรียกใช้คำสั่งต่อไปนี้ไปป์ไลน์ทั้งหมดจะดำเนินการตามขั้นตอน
source install.sh ; python main.py --config configs/bert-simple.yaml ซึ่งจะเรียกใช้การติดตั้งสภาพแวดล้อมการเตรียมชุดข้อมูลการเตรียม pretraining, finetuning และการทดสอบผลการทดสอบหนึ่งทีละหนึ่งและสร้างไฟล์. zip สำหรับการส่งเซิร์ฟเวอร์ทดสอบกาวภายใต้ output_test_translated/finetune/*/*.zip โปรดดูที่ pipeline_config.md สำหรับข้อมูลเพิ่มเติมเกี่ยวกับไฟล์กำหนดค่า YAML
รายละเอียดของแต่ละขั้นตอนจะแสดงในส่วนต่อไปนี้
เรียกใช้ source install.sh
ไดเรกทอรี dataset รวมถึงสคริปต์เพื่อประมวลผลชุดข้อมูลที่เราใช้ในการทดลองของเรา (Wikipedia, Bookcorpus) ดู ReadMe เฉพาะสำหรับรายละเอียดทั้งหมด
สคริปต์การเตรียมการ: run_pretraining.py
สำหรับอาร์กิวเมนต์ pretraining ที่เป็นไปได้ทั้งหมดดู: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 ใช้ run_glue.py เพื่อเรียกใช้ finetuning สำหรับจุดตรวจที่บันทึกไว้ในงานกาว
สคริปต์ Finetuning นั้นเหมือนกับที่ได้รับจาก HuggingFace ด้วยการเพิ่มโมเดลของเรา
สำหรับอาร์กิวเมนต์การเตรียมการที่เป็นไปได้ทั้งหมดดู: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50หากคุณพบว่าพื้นที่เก็บข้อมูลนี้มีประโยชน์คุณอาจอ้างถึงกระดาษของเราเป็น:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
ส่วนสำคัญของรหัสขึ้นอยู่กับวิธีการฝึกอบรม Bert ด้วยงบประมาณเชิงวิชาการที่ได้รับอนุญาตภายใต้ Apache 2.0
สำหรับความช่วยเหลือหรือปัญหาที่ใช้แพ็คเกจนี้โปรดส่งปัญหา GitHub
สำหรับการสื่อสารส่วนบุคคลที่เกี่ยวข้องกับแพ็คเกจนี้โปรดติดต่อ Rui Pan ([email protected]) และ Shizhe Diao ([email protected])


