extreme bert
1.0.0
Extrembert adalah toolkit yang mempercepat pretraining dan finetuning dari Bert pada set data yang disesuaikan. Lihatlah dokumentasi dan kertas kami dengan cepat.
Kami menyederhanakan proses instalasi dependensi yang diperlukan oleh paket. Mereka dapat dengan mudah diinstal oleh satu source install.sh . Tidak ada langkah lain yang dibutuhkan!
Waktu pretraining dapat dikurangi menjadi nilai berbasis waktu dengan mendefinisikan --total_training_time=24.0 (misalnya 24 jam). Presisi campuran didukung dengan menambahkan --fp16 .
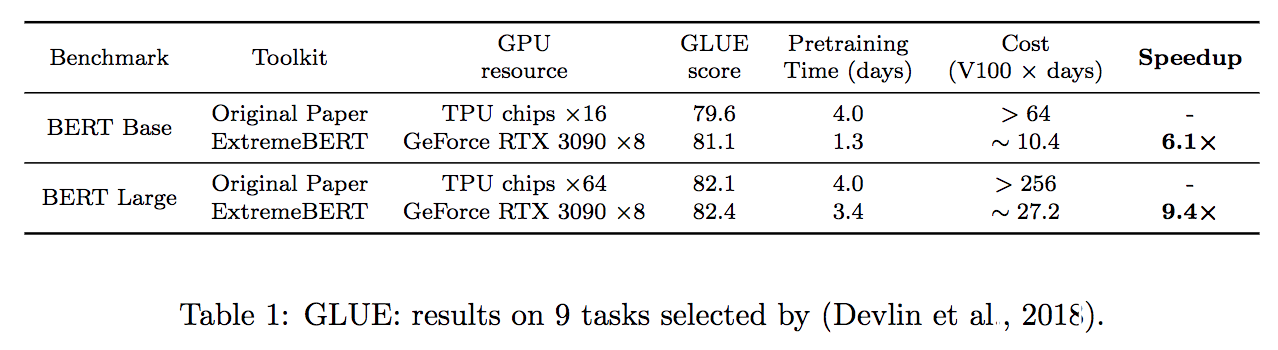
Dukung sejumlah besar set data pra-pelatihan. Pengguna dapat dengan mudah menggunakannya melalui HuggingFace Dataset Hub. Selain itu, kami juga mendukung dataset khusus pengguna.
Sulit untuk memverifikasi efektivitas metode optimasi baru dalam pra-pelatihan LM. Dengan paket kami, kami mendukung integrasi pengoptimal dan penjadwal yang disesuaikan ke dalam pipa, yang membantu para peneliti di komunitas optimisasi untuk dengan mudah memverifikasi algoritma mereka. Algoritma pengoptimalan dan pemrosesan data yang efisien juga akan ditambahkan ke rilis di masa mendatang.
| Model | Status |
|---|---|
| Bert | ✅ didukung |
| Roberta, Albert, DeBerta | ? Berkembang |
Pertama, orang dapat merujuk pada configs/bert-simple.yaml dan membuat konfigurasi yang sesuai untuk pipa, termasuk set data, jumlah GPU yang tersedia, dll. Kemudian, dengan hanya menjalankan perintah berikut, seluruh pipa akan dieksekusi tahap demi tahap,
source install.sh ; python main.py --config configs/bert-simple.yaml yang akan menjalankan instalasi lingkungan, dataset prepration, pretraining, finetuning dan collection hasil tes satu per satu dan menghasilkan file .zip untuk pengiriman server uji lem di bawah output_test_translated/finetune/*/*.zip . Silakan merujuk ke pipeline_config.md untuk informasi lebih lanjut tentang file konfigurasi YAML.
Rincian setiap tahap diilustrasikan dalam bagian berikut.
Jalankan source install.sh
Direktori dataset mencakup skrip untuk pra-proses set data yang kami gunakan dalam percobaan kami (Wikipedia, BookCorpus). Lihat ReadMe khusus untuk detail lengkap.
Script pretraining: run_pretraining.py
Untuk semua argumen pretraining yang mungkin lihat: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Gunakan run_glue.py untuk menjalankan finetuning untuk pos pemeriksaan yang disimpan pada tugas lem.
Skrip finetuning identik dengan yang disediakan oleh Huggingface dengan penambahan model kami.
Untuk semua argumen pretraining yang mungkin lihat: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Jika Anda menemukan repositori ini bermanfaat, Anda dapat mengutip kertas kami sebagai:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Sebagian besar kode didasarkan pada cara melatih Bert dengan anggaran akademik yang dilisensikan di bawah Apache 2.0.
Untuk bantuan atau masalah menggunakan paket ini, silakan kirimkan masalah GitHub.
Untuk komunikasi pribadi yang terkait dengan paket ini, silakan hubungi Rui Pan ([email protected]) dan Shizhe Diao ([email protected]).


