extreme bert
1.0.0
Extremebert est une boîte à outils qui accélère la pré-entraînement et la finetun de Bert sur des ensembles de données personnalisés. Jetez un coup d'œil à notre documentation et à notre papier.
Nous simplifions le processus d'installation des dépendances requise par le package. Ils peuvent être facilement installés par une seule source install.sh . Aucune autre étape n'est nécessaire!
Le temps de pré-formation peut être réduit à une valeur basée sur le temps en définissant --total_training_time=24.0 (24 heures par exemple). La précision mixte est prise en charge par l'ajout --fp16 .
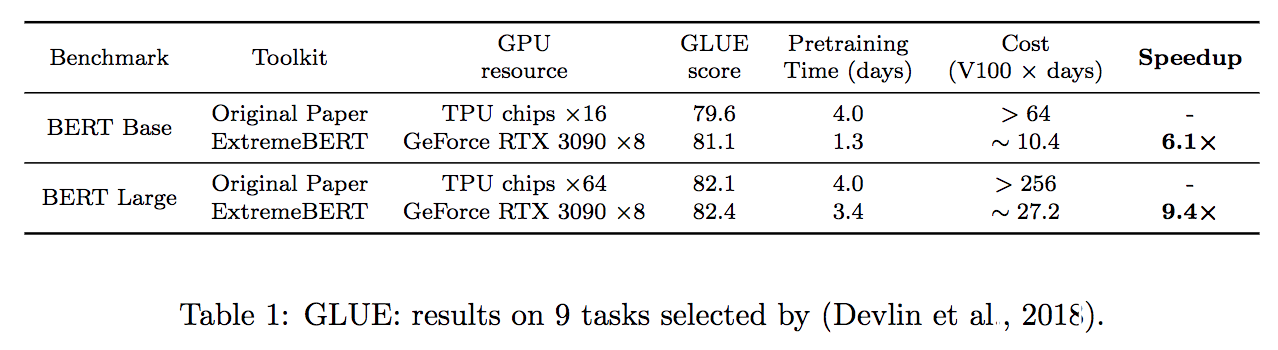
Soutenez un grand nombre d'ensembles de données pré-formation. Les utilisateurs peuvent facilement les utiliser via HuggingFace DataSet Hub. De plus, nous prenons également en charge le jeu de données personnalisé des utilisateurs.
Il est difficile de vérifier l'efficacité d'une nouvelle méthode d'optimisation dans la pré-formation LM. Avec notre package, nous prenons en charge l'intégration d'optimistes et de planificateurs personnalisés dans le pipeline, ce qui aide les chercheurs de la communauté d'optimisation à vérifier facilement leurs algorithmes. Des algorithmes d'optimisation et de traitement des données efficaces seront également ajoutés aux versions futures.
| Modèle | Statut |
|---|---|
| Bert | ✅ Soutenu |
| Roberta, Albert, Deberta | ? Développement |
Tout d'abord, on peut se référer aux configs/bert-simple.yaml et créer des configurations appropriées pour le pipeline, y compris les ensembles de données, le nombre de GPU disponibles, etc. Ensuite, en exécutant simplement la commande suivante, l'ensemble du pipeline sera exécuté par étape, par étape,
source install.sh ; python main.py --config configs/bert-simple.yaml qui exécutera l'installation de l'environnement, la préparation de l'ensemble de données, la pré-entraînement, le beletUning et la collecte de résultats de test un par un et généreront le fichier .zip pour la soumission du serveur de test de colle sous output_test_translated/finetune/*/*.zip . Veuillez vous référer à Pipeline_Config.md pour plus d'informations sur le fichier de configuration YAML.
Les détails de chaque étape sont illustrés dans les sections suivantes.
Exécuter source install.sh
Le répertoire dataset comprend des scripts pour prétraiter les ensembles de données que nous avons utilisés dans nos expériences (Wikipedia, BookCorpus). Voir ReadMe dédié pour plus de détails.
Script de pré-formation: run_pretraining.py
Pour tous les arguments de pré-formation possibles, voir: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Utilisez run_glue.py pour exécuter Finetuning pour un point de contrôle enregistré sur les tâches de colle.
Le script Finetuning est identique à celui fourni par Huggingface avec l'ajout de notre modèle.
Pour tous les arguments de pré-formation possibles, voir: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Si vous trouvez ce référentiel utile, vous pouvez citer notre article comme:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Une partie importante du code est basée sur la façon de former Bert avec un budget académique sous licence Apache 2.0.
Pour obtenir de l'aide ou des problèmes en utilisant ce package, veuillez soumettre un problème GitHub.
Pour la communication personnelle liée à ce package, veuillez contacter Rui Pan ([email protected]) et Shizhe Dioo ([email protected]).


