extreme bert
1.0.0
Extremebert ist ein Toolkit, das die Vorbereitung und Fülle von Bert auf angepassten Datensätzen beschleunigt. Schauen Sie sich einen kurzen Blick auf unsere Dokumentation und unser Papier.
Wir vereinfachen den Installationsprozess von Abhängigkeiten, die vom Paket erforderlich sind. Sie können einfach durch eine einzelne source install.sh installiert werden. Es sind keine anderen Schritte erforderlich!
Die Zeit für die Vorabstärke kann auf einen zeitbasierten Wert reduziert werden, indem --total_training_time=24.0 (zum Beispiel 24 Stunden) definiert wird. Gemischte Präzision wird durch Hinzufügen --fp16 unterstützt.
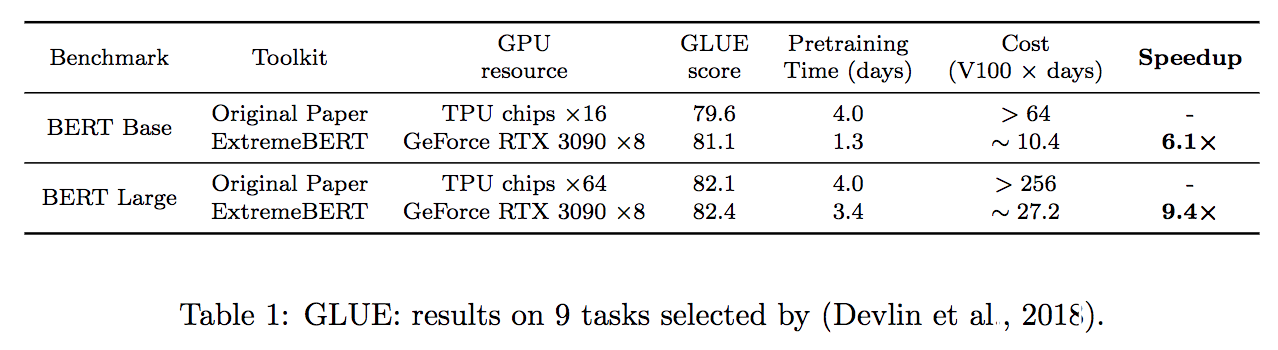
Unterstützen Sie eine große Anzahl von Datensätzen vor dem Training. Benutzer können sie problemlos über den Datensatz von Huggingface -Hub verwenden. Darüber hinaus unterstützen wir den benutzerdefinierten Datensatz von Benutzern.
Es ist schwierig, die Wirksamkeit einer neuen Optimierungsmethode bei LM vor der Ausbildung zu überprüfen. Mit unserem Paket unterstützen wir die Integration maßgeschneiderter Optimierer und Scheduler in die Pipeline, die Forschern in der Optimierungsgemeinschaft dabei helfen, ihre Algorithmen einfach zu überprüfen. Zukünftige Releases werden ebenfalls effiziente Optimierungs- und Datenverarbeitungsalgorithmen hinzugefügt.
| Modell | Status |
|---|---|
| Bert | ✅ unterstützt |
| Roberta, Albert, Deberta | ? Entwicklung |
Zuerst kann man sich auf configs/bert-simple.yaml beziehen und geeignete Konfigurationen für die Pipeline erstellen, einschließlich Datensätze, Anzahl der verfügbaren GPUs usw. Dann wird die gesamte Pipeline durch einfaches Ausführen der gesamten Pipeline nach der Bühne ausgeführt.
source install.sh ; python main.py --config configs/bert-simple.yaml Die Umgebungsinstallation, Datensatzvorberufung, Vorab-, Finetuning- und Testergebnissammlung nacheinander und generieren Sie die Einreichung von .zip -Datei für den Klebetestserver unter output_test_translated/finetune/*/*.zip . Weitere Informationen zur YAML -Konfigurationsdatei finden Sie unter pipeline_config.md.
Die Einzelheiten der einzelnen Stufen sind in den folgenden Abschnitten dargestellt.
Führen Sie source install.sh
Das dataset -Verzeichnis enthält Skripte, um die in unseren Experimenten verwendeten Datensätze (Wikipedia, Bookcorpus) vorzubereiten. Weitere Informationen finden Sie unter Dedicated Readme.
Vorab -Skript: run_pretraining.py
Für alle möglichen Argumente vorab siehe: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Verwenden Sie run_glue.py , um die Finetuning für einen gespeicherten Kontrollpunkt für Kleberaufgaben auszuführen.
Das Finetuning -Skript ist identisch mit dem, das durch Umarmung mit dem Hinzufügen unseres Modells bereitgestellt wird.
Für alle möglichen Argumente vorab siehe: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Wenn Sie dieses Repository nützlich finden, können Sie unser Papier als:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Ein wesentlicher Teil des Codes basiert auf der Ausbildung von Bert mit einem unter Apache 2.0 lizenzierten akademischen Budget.
Für Hilfe oder Probleme mit diesem Paket senden Sie bitte ein GitHub -Problem.
Für persönliche Mitteilung zu diesem Paket wenden Sie sich bitte an Rui Pan ([email protected]) und Shizhe Diao ([email protected]).


