extreme bert
1.0.0
Extremebert는 맞춤형 데이터 세트에서 BERT의 사전 여지 및 양조를 가속화하는 툴킷입니다. 문서와 논문을 간단히 살펴보십시오.
패키지에 필요한 종속성의 설치 프로세스를 단순화합니다. 단일 명령 source install.sh 로 쉽게 설치할 수 있습니다. 다른 단계가 필요하지 않습니다!
--total_training_time=24.0 (예 : 24 시간)을 정의함으로써 사전 배송 시간을 시간 기반 값으로 줄일 수 있습니다. 혼합 정밀도는 --fp16 추가하여 지원됩니다.
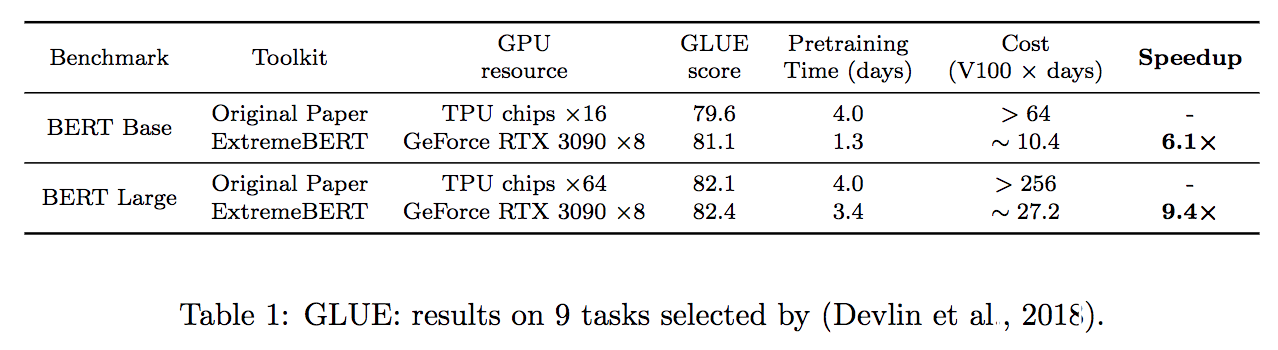
많은 수의 사전 훈련 데이터 세트를 지원합니다. 사용자는 Huggingface DataSet Hub를 통해 쉽게 사용할 수 있습니다. 또한 사용자의 사용자 정의 데이터 세트도 지원합니다.
LM 사전 훈련에서 새로운 최적화 방법의 효과를 확인하기는 어렵습니다. 패키지를 통해 맞춤형 최적화기 및 스케줄러를 파이프 라인에 통합하여 최적화 커뮤니티의 연구원이 알고리즘을 쉽게 확인할 수 있도록 도와줍니다. 효율적인 최적화 및 데이터 처리 알고리즘도 향후 릴리스에 추가됩니다.
| 모델 | 상태 |
|---|---|
| 버트 | ✅ 지원 |
| 로베르타, 앨버트, 디버타 | ? 개발 |
먼저 configs/bert-simple.yaml 참조하고 데이터 세트, 사용 가능한 GPU 수 등을 포함하여 파이프 라인에 적합한 구성을 만들 수 있습니다. 그런 다음 다음 명령을 실행하면 전체 파이프 라인이 스테이지별로 실행됩니다.
source install.sh ; python main.py --config configs/bert-simple.yaml 환경 설치, 데이터 세트 전 준비, 사전 준비, 사전 조정, 미세 조정 및 테스트 결과 수집을 하나씩 실행하고 output_test_translated/finetune/*/*.zip 에서 접착제 테스트 서버 제출 용 .ZIP 파일을 생성합니다. Yaml 구성 파일에 대한 자세한 내용은 Pipeline_config.md를 참조하십시오.
각 단계의 세부 사항은 다음 섹션에 설명되어 있습니다.
source install.sh 실행합니다
dataset 디렉토리에는 실험에서 사용한 데이터 세트 (Wikipedia, BookCorpus)를 사전 프로세스하는 스크립트가 포함되어 있습니다. 자세한 내용은 전용 readme를 참조하십시오.
전 사전 조정 스크립트 : run_pretraining.py
가능한 모든 사전 계약 주장은 다음을 참조하십시오 : python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 run_glue.py 사용하여 접착제 작업에 저장된 체크 포인트를 위해 FinetUning을 실행하십시오.
Finetuning 스크립트는 모델을 추가하여 Huggingface에서 제공 한 스크립트와 동일합니다.
가능한 모든 사전 계약 논쟁은 참조 : python run_glue.py -h 참조하십시오
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50이 저장소가 유용하다고 생각되면 다음과 같이 우리의 논문을 인용 할 수 있습니다.
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
코드의 상당 부분은 Apache 2.0에 따라 라이센스가 부여 된 학업 예산으로 Bert를 훈련시키는 방법을 기반으로합니다.
이 패키지를 사용하는 도움이나 문제는 GitHub 문제를 제출하십시오.
이 패키지와 관련된 개인 커뮤니케이션은 Rui Pan ([email protected])과 Shizhe Diao ([email protected])에게 문의하십시오.


