extreme bert
1.0.0
ExtremeBertは、カスタマイズされたデータセットでBERTの前脱出と微調整を加速するツールキットです。ドキュメントと紙を簡単に見てください。
パッケージに必要な依存関係のインストールプロセスを簡素化します。単一のコマンドsource install.shによって簡単にインストールできます。他の手順は必要ありません!
--total_training_time=24.0 (たとえば24時間)を定義することにより、事前削除時間は時間ベースの値に短縮できます。混合精度は、 --fp16を追加することによりサポートされます。
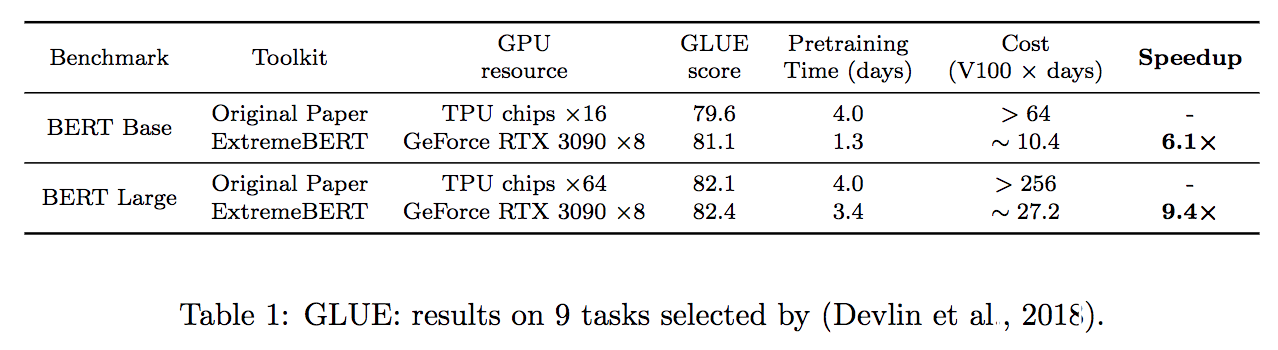
多数のトレーニング前データセットをサポートします。ユーザーは、Huggingface Dataset Hubを使用して簡単に使用できます。さらに、ユーザーのカスタムデータセットもサポートしています。
LMプリトレーニングの新しい最適化方法の有効性を検証することは困難です。パッケージを使用すると、カスタマイズされたオプティマイザーとスケジューラーのパイプラインへの統合をサポートしています。これにより、最適化コミュニティの研究者がアルゴリズムを簡単に検証できるようになります。効率的な最適化とデータ処理アルゴリズムも、将来のリリースに追加されます。
| モデル | 状態 |
|---|---|
| バート | supportサポート |
| ロベルタ、アルバート、デバータ | ?現像 |
まず、 configs/bert-simple.yamlを参照し、データセット、利用可能なGPUの数などを含むパイプラインに適した構成を作成できます。次に、次のコマンドを実行するだけで、パイプライン全体がステージごとに実行されます。
source install.sh ; python main.py --config configs/bert-simple.yaml環境のインストール、データセットの前処理、事前測定、Finetuning、およびテスト結果コレクションを1つずつ実行し、Glue Test Serverの.ZIPファイルを生成しますoutput_test_translated/finetune/*/*.zip YAML構成ファイルの詳細については、pipeline_config.mdを参照してください。
各段階の詳細は、次のセクションに示されています。
source install.sh実行します
datasetディレクトリには、実験で使用したデータセット(Wikipedia、BookCorpus)を前処理するスクリプトが含まれています。詳細については、専用のreadmeを参照してください。
事前削除スクリプト: run_pretraining.py
考えられるすべての事前推定の議論については、 python run_pretraining.py -h参照してください
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16run_glue.pyを使用して、接着剤タスクの保存されたチェックポイントのFinetuningを実行します。
Finetuningスクリプトは、モデルを追加してHuggingfaceによって提供されたスクリプトと同じです。
考えられるすべての事前推定の議論については、 python run_glue.py -h参照してください
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50このリポジトリが便利だと思う場合は、次のように論文を引用できます。
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
コードの大部分は、Apache 2.0に基づいてライセンスされた学術予算でBERTを訓練する方法に基づいています。
このパッケージを使用したヘルプまたは問題については、GitHubの問題を提出してください。
このパッケージに関連する個人的なコミュニケーションについては、Rui Pan([email protected])とshizhe diao([email protected])にお問い合わせください。


