extreme bert
1.0.0
Extremebert é um kit de ferramentas que acelera a pré -treinamento e o Finetuning do BERT em conjuntos de dados personalizados. Dê uma olhada rápida em nossa documentação e papel.
Simplificamos o processo de instalação das dependências exigidas pelo pacote. Eles podem ser facilmente instalados por uma única source install.sh . Não são necessárias outras etapas!
O tempo de pré-treinamento pode ser reduzido a um valor baseado no tempo, definindo --total_training_time=24.0 (24 horas, por exemplo). A precisão mista é suportada adicionando --fp16 .
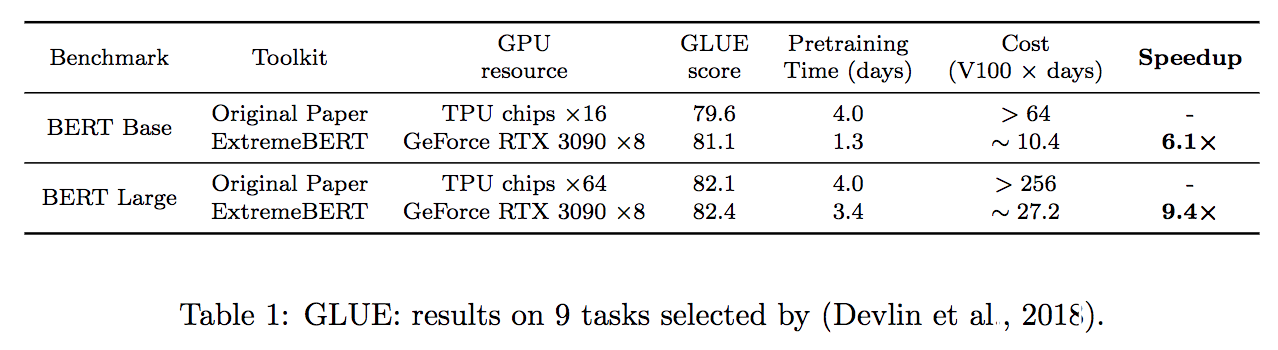
Suporte um grande número de conjuntos de dados de pré-treinamento. Os usuários podem usá -los facilmente através do hub do conjunto de dados HuggingFace. Além disso, também oferecemos suporte ao conjunto de dados personalizado dos usuários.
É difícil verificar a eficácia de um novo método de otimização no pré-treinamento LM. Com o nosso pacote, apoiamos a integração de otimizadores e agendadores personalizados no pipeline, que ajudam os pesquisadores da comunidade de otimização a verificar facilmente seus algoritmos. Os algoritmos eficientes de otimização e processamento de dados também serão adicionados a versões futuras.
| Modelo | Status |
|---|---|
| Bert | ✅ Suporte |
| Roberta, Albert, Deberta | ? Em desenvolvimento |
Primeiro, pode-se se referir a configs/bert-simple.yaml e fazer configurações adequadas para o pipeline, incluindo conjuntos de dados, número de GPUs disponíveis, etc. Então, simplesmente executando o seguinte comando, todo o pipeline será executado estágio por estágio por estágio,
source install.sh ; python main.py --config configs/bert-simple.yaml que executarão a instalação do ambiente, a pré -retração, a pré -treinamento, a Finetuning e o resultado da coleta de resultados um por um e gerará o arquivo .zip para o envio do servidor de teste de cola em output_test_translated/finetune/*/*.zip . Consulte o pipeline_config.md para obter mais informações sobre o arquivo de configuração YAML.
Os detalhes de cada estágios são ilustrados nas seções a seguir.
Execute source install.sh
O diretório dataset inclui scripts para pré-processar os conjuntos de dados que usamos em nossos experimentos (Wikipedia, Bookcorpus). Consulte Readme dedicado para obter detalhes completos.
Script pré -treinamento: run_pretraining.py
Para todos os argumentos possíveis de pré -treinamento, consulte: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Use run_glue.py para executar o Finetuning para um ponto de verificação salvo nas tarefas de cola.
O script Finetuning é idêntico ao fornecido pelo HuggingFace com a adição do nosso modelo.
Para todos os argumentos possíveis de pré -treinamento, consulte: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Se você achar esse repositório útil, poderá citar nosso artigo como:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Uma parte significativa do código é baseada em como treinar Bert com um orçamento acadêmico licenciado no Apache 2.0.
Para obter ajuda ou problemas usando este pacote, envie um problema do GitHub.
Para comunicação pessoal relacionada a este pacote, entre em contato com Rui Pan ([email protected]) e shizhe diao ([email protected]).


