extreme bert
1.0.0
Extremebert es un kit de herramientas que acelera la preparación y el finete de Bert en conjuntos de datos personalizados. Eche un vistazo rápido a nuestra documentación y papel.
Simplificamos el proceso de instalación de dependencias requeridas por el paquete. Se pueden instalar fácilmente mediante una sola source install.sh . ¡No se necesitan otros pasos!
El tiempo de previación se puede reducir a un valor basado en el tiempo definiendo --total_training_time=24.0 (24 horas por ejemplo). La precisión mixta se admite agregando --fp16 .
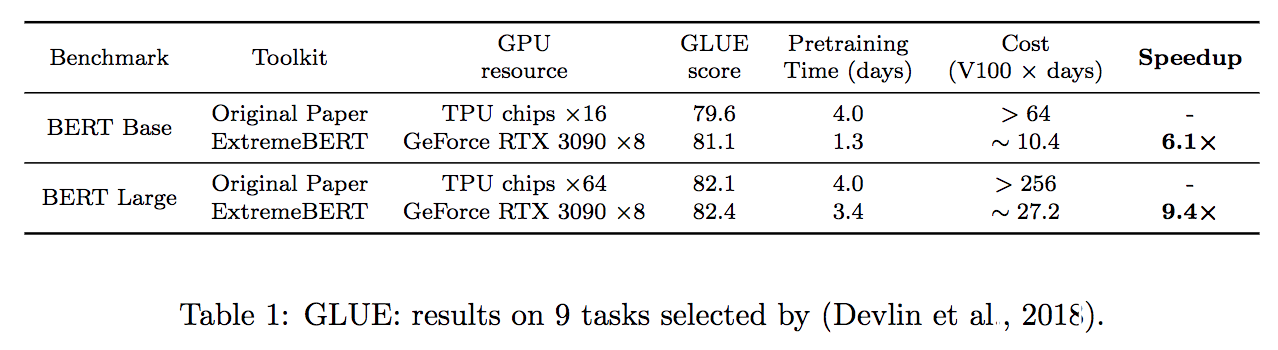
Admite una gran cantidad de conjuntos de datos de pre-entrenamiento. Los usuarios pueden usarlos fácilmente a través de Huggingface DataSet Hub. Además, también admitimos el conjunto de datos personalizado de los usuarios.
Es difícil verificar la efectividad de un nuevo método de optimización en la pre-entrenamiento de LM. Con nuestro paquete, apoyamos la integración de optimizadores y programadores personalizados en la tubería, que ayudan a los investigadores de la comunidad de optimización a verificar fácilmente sus algoritmos. La optimización eficiente y los algoritmos de procesamiento de datos también se agregarán a futuras versiones.
| Modelo | Estado |
|---|---|
| Bert | ✅ Apoyado |
| Roberta, Albert, Deberta | ? Desarrollo |
Primero, uno puede referirse a configs/bert-simple.yaml y hacer configuraciones adecuadas para la tubería, incluidos los conjuntos de datos, el número de GPU disponibles, etc. Luego, simplemente ejecutando el siguiente comando, toda la tubería se ejecutará en la etapa por etapa,
source install.sh ; python main.py --config configs/bert-simple.yaml que ejecutará la instalación del entorno, la prepratación del conjunto de datos, el pretrete, la finidad y la recopilación de resultados de la prueba uno por uno y generarán el archivo .zip para el envío del servidor de prueba de pegamento en output_test_translated/finetune/*/*.zip . Consulte Pipeline_Config.md para obtener más información sobre el archivo de configuración YAML.
Los detalles de cada etapa se ilustran en las siguientes secciones.
Ejecutar source install.sh
El directorio dataset incluye scripts para preprocesar los conjuntos de datos que utilizamos en nuestros experimentos (Wikipedia, BookCorpus). Vea Readme dedicado para obtener todos los detalles.
Script previo a la altura: run_pretraining.py
Para todos los posibles argumentos previos a la altura, consulte: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 Use run_glue.py para ejecutar Finetuning para un punto de control guardado en las tareas de pegamento.
El script Finetuning es idéntico al proporcionado por Huggingface con la adición de nuestro modelo.
Para todos los posibles argumentos previos a la altura, consulte: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50Si encuentra útil este repositorio, puede citar nuestro documento como:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
Una parte significativa del código se basa en cómo capacitar a Bert con un presupuesto académico con licencia bajo Apache 2.0.
Para obtener ayuda o problemas con este paquete, envíe un problema de GitHub.
Para la comunicación personal relacionada con este paquete, comuníquese con Rui Pan ([email protected]) y Shizhe Diao ([email protected]).


