extreme bert
1.0.0
Extremebert هي مجموعة أدوات تسرع في Bert و Finetuning من Bert على مجموعات البيانات المخصصة. ألق نظرة سريعة على وثائقنا وورقنا.
نقوم بتبسيط عملية تثبيت التبعيات المطلوبة بواسطة الحزمة. يمكن تثبيتها بسهولة بواسطة source install.sh الأمر. لا توجد حاجة إلى خطوات أخرى!
يمكن تقليل وقت التدريب إلى قيمة قائمة على الوقت من خلال تحديد- --total_training_time=24.0 (24 ساعة على سبيل المثال). يتم دعم الدقة المختلطة عن طريق إضافة --fp16 .
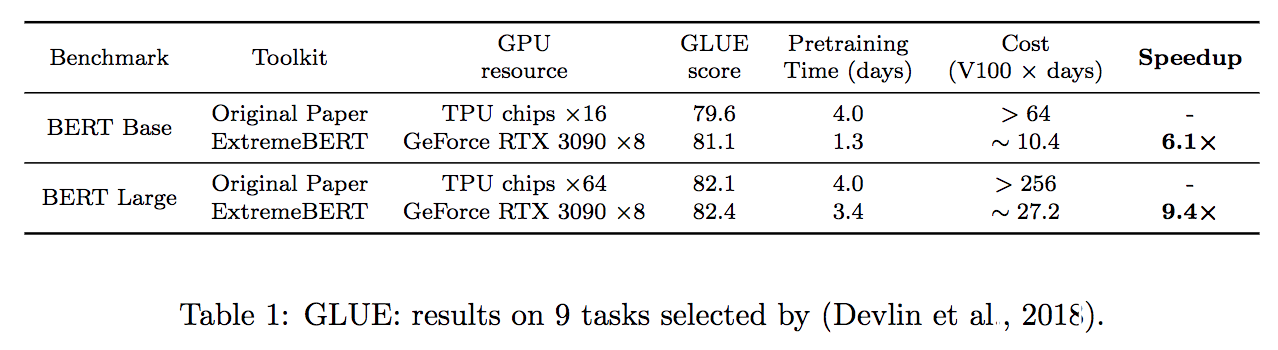
دعم عدد كبير من مجموعات البيانات قبل التدريب. يمكن للمستخدمين استخدامها بسهولة عبر Huggingface Tet Hub. بالإضافة إلى ذلك ، ندعم أيضًا مجموعة البيانات المخصصة للمستخدمين.
من الصعب التحقق من فعالية طريقة التحسين الجديدة في التدريب قبل التدريب. من خلال الحزمة الخاصة بنا ، فإننا ندعم تكامل المُحسِّنات والمجاوئة المخصصة في خط الأنابيب ، مما يساعد الباحثين في مجتمع التحسين على التحقق من خوارزمياتهم بسهولة. سيتم أيضًا إضافة خوارزميات التحسين الفعالة ومعالجة البيانات إلى الإصدارات المستقبلية.
| نموذج | حالة |
|---|---|
| بيرت | ✅ مدعوم |
| روبرتا ، ألبرت ، ديبرتا | ؟ النمو |
أولاً ، يمكن للمرء أن يشير إلى configs/bert-simple.yaml ويقوم بتكوينات مناسبة لخط الأنابيب ، بما في ذلك مجموعات البيانات ، وعدد وحدات معالجة الرسومات المتاحة ، وما إلى ذلك ، عن طريق تشغيل الأمر التالي ، سيتم تنفيذ خط الأنابيب بأكمله على مرحلة ،
source install.sh ; python main.py --config configs/bert-simple.yaml والتي ستقوم بتشغيل تثبيت البيئة ، مجموعة البيانات المسبقة ، مجموعة ما قبل ، واختبار التحويل واختبار مجموعة واحدة تلو الأخرى وإنشاء ملف .zip لتقديم خادم اختبار الغراء ضمن output_test_translated/finetune/*/*.zip . يرجى الرجوع إلى pipeline_config.md لمزيد من المعلومات حول ملف تكوين YAML.
تم توضيح تفاصيل كل مرحلة في الأقسام التالية.
تشغيل source install.sh
يتضمن دليل dataset البرامج النصية للعملية المسبقة لمجموعات البيانات التي استخدمناها في تجاربنا (Wikipedia ، BookCorpus). انظر مخصص ReadMe للحصول على التفاصيل الكاملة.
البرنامج النصي المسبق: run_pretraining.py
للحصول على جميع الحجج الممكنة الممكنة ، انظر: python run_pretraining.py -h
deepspeed run_pretraining.py
--model_type bert-mlm --tokenizer_name bert-large-uncased
--hidden_act gelu
--hidden_size 1024
--num_hidden_layers 24
--num_attention_heads 16
--intermediate_size 4096
--hidden_dropout_prob 0.1
--attention_probs_dropout_prob 0.1
--encoder_ln_mode pre-ln
--lr 1e-3
--train_batch_size 4096
--train_micro_batch_size_per_gpu 32
--lr_schedule time
--curve linear
--warmup_proportion 0.06
--gradient_clipping 0.0
--optimizer_type adamw
--weight_decay 0.01
--adam_beta1 0.9
--adam_beta2 0.98
--adam_eps 1e-6
--total_training_time 24.0
--early_exit_time_marker 24.0
--dataset_path < dataset path >
--output_dir /tmp/training-out
--print_steps 100
--num_epochs_between_checkpoints 10000
--job_name pretraining_experiment
--project_name budget-bert-pretraining
--validation_epochs 3
--validation_epochs_begin 1
--validation_epochs_end 1
--validation_begin_proportion 0.05
--validation_end_proportion 0.01
--validation_micro_batch 16
--deepspeed
--data_loader_type dist
--do_validation
--use_early_stopping
--early_stop_time 180
--early_stop_eval_loss 6
--seed 42
--fp16 استخدم run_glue.py لتشغيل Finetuning للحصول على نقطة تفتيش محفوظة على مهام الغراء.
يتطابق البرنامج النصي في Finetuning مع البرنامج الذي يوفره Huggingface مع إضافة نموذجنا.
للحصول على جميع الحجج الممكنة الممكنة ، انظر: python run_glue.py -h
python run_glue.py
--model_name_or_path < path to model >
--task_name MRPC
--max_seq_length 128
--output_dir /tmp/finetuning
--overwrite_output_dir
--do_train --do_eval
--evaluation_strategy steps
--per_device_train_batch_size 32 --gradient_accumulation_steps 1
--per_device_eval_batch_size 32
--learning_rate 5e-5
--weight_decay 0.01
--eval_steps 50 --evaluation_strategy steps
--max_grad_norm 1.0
--num_train_epochs 5
--lr_scheduler_type polynomial
--warmup_steps 50إذا وجدت هذا المستودع مفيدًا ، فيمكنك أن تستشهد بورقنا على النحو التالي:
@inproceedings{extreme-bert,
title={ExtremeBERT: A Toolkit for Accelerating Pretraining of Customized BERT},
author={Rui Pan and Shizhe Diao and Jianlin Chen and Tong Zhang},
year={2022},
eprint={2211.17201},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2211.17201},
}
يعتمد جزء كبير من الرمز على كيفية تدريب Bert بميزانية أكاديمية مرخصة بموجب Apache 2.0.
للحصول على مساعدة أو مشكلات باستخدام هذه الحزمة ، يرجى تقديم مشكلة github.
للاتصال الشخصي المتعلق بهذه الحزمة ، يرجى الاتصال بـ Rui Pan ([email protected]) و Shizhe Dio ([email protected]).


