LLM Finetuning Toolkit
v0.2.3

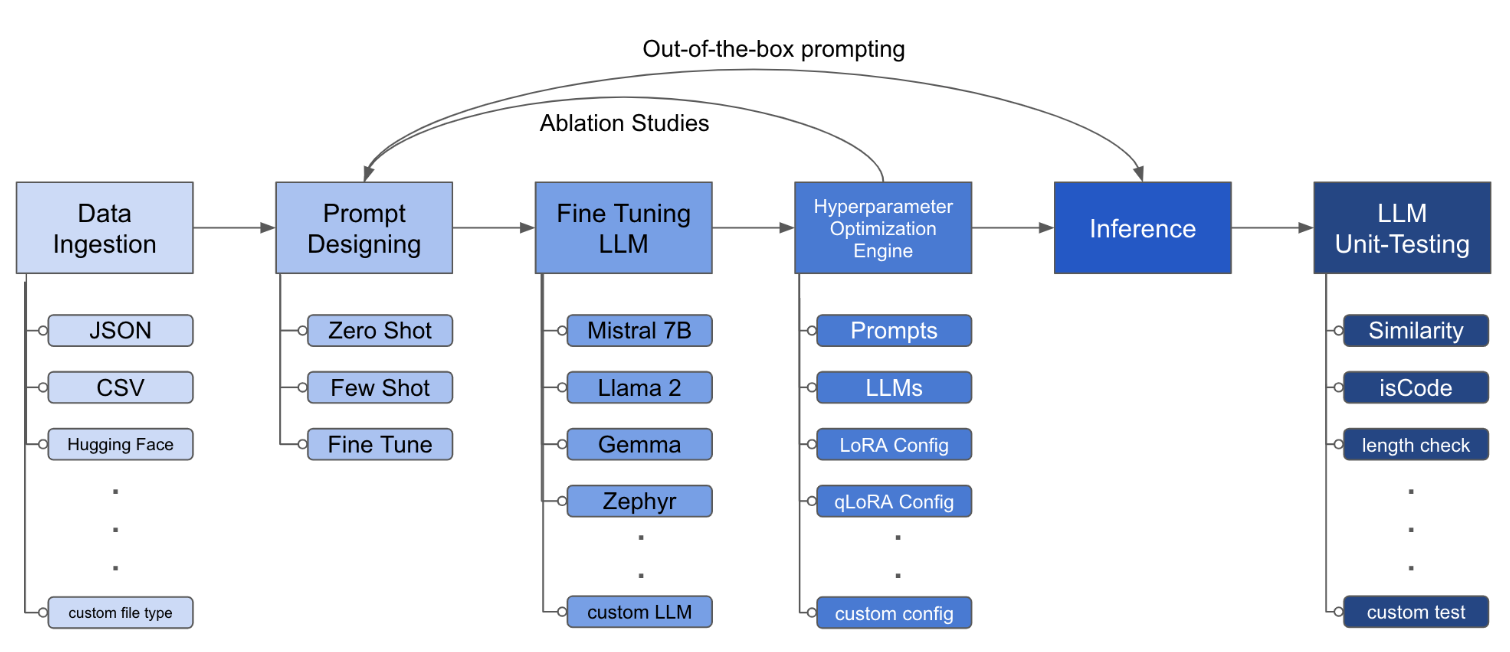
LLM Finetuning Toolkit是一种基于配置的CLI工具,用于在您的数据上启动一系列LLM微调实验并收集结果。从一个yaml配置文件中,控制典型实验管道的所有元素 -提示,开源LLM ,优化策略和LLM测试。
PIPX在单独的虚拟环境中安装软件包和依赖项
pipx install llm-toolkitpip install llm-toolkit本指南包含3个阶段,可以使您能够充分利用此工具包!
llmtune generate config
llmtune run ./config.yml第一个命令生成有用的启动器config.yml文件,并保存在当前工作目录中。提供给用户快速入门,并作为进一步修改的基础。
然后,第二个命令使用默认YAML Configuration config.yaml中指定的设置来启动微调过程。
配置文件是定义工具包行为的中心部分。它以YAML格式编写,由几个部分组成,这些部分控制过程的不同方面,例如数据摄入,模型定义,培训,推理和质量保证。我们重点介绍了一些关键部分。
启用闪存注意力的支持模型。首先安装flash-attn :
pipx
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationpip
pip install flash-attn --no-build-isolation
然后,添加到配置文件。
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " 数据摄入可能是什么样子:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file>提示字段有助于创建说明以微调LLM。它读取数据集中存在的{}括号中提到的特定列中的数据。在提供的示例中,可以预期数据文件具有列名: instruction , input和output 。
在微调过程中,提示字段同时使用prompt和prompt_stub 。但是,在测试过程中,仅prompt部分用作微调LLM的输入。
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r和辍学。 lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test此配置将在目录中进行微调并保存结果./experiment/[unique_hash] 。每种唯一的配置都会生成一个唯一的哈希,以便我们的工具可以自动拾取其关闭的位置。例如,如果您需要在培训的中间退出,则通过重新启动脚本,该程序将自动加载在目录下生成的现有数据集,而不是再次进行。
脚本完成后,您将看到这些独特的文物:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and prediction一旦将所有更改都合并到YAML文件中,您就可以使用它来运行自定义微调实验!
python toolkit.py --config-path < path to custom YAML file >微调工作流程通常涉及在各种LLM上进行消融研究,及时设计和优化技术。可以更改配置文件以支持运行消融研究。
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] 该工具包提供了模块化且可扩展的体系结构,使开发人员可以自定义和增强其功能以适应其特定需求。工具包的每个组件,例如数据摄入,微调,推理和质量保证测试,旨在易于扩展。
欢迎和鼓励对该工具包的开源供款。如果您想做出贡献,请参阅parduting.md。


