LLM Finetuning Toolkit
v0.2.3

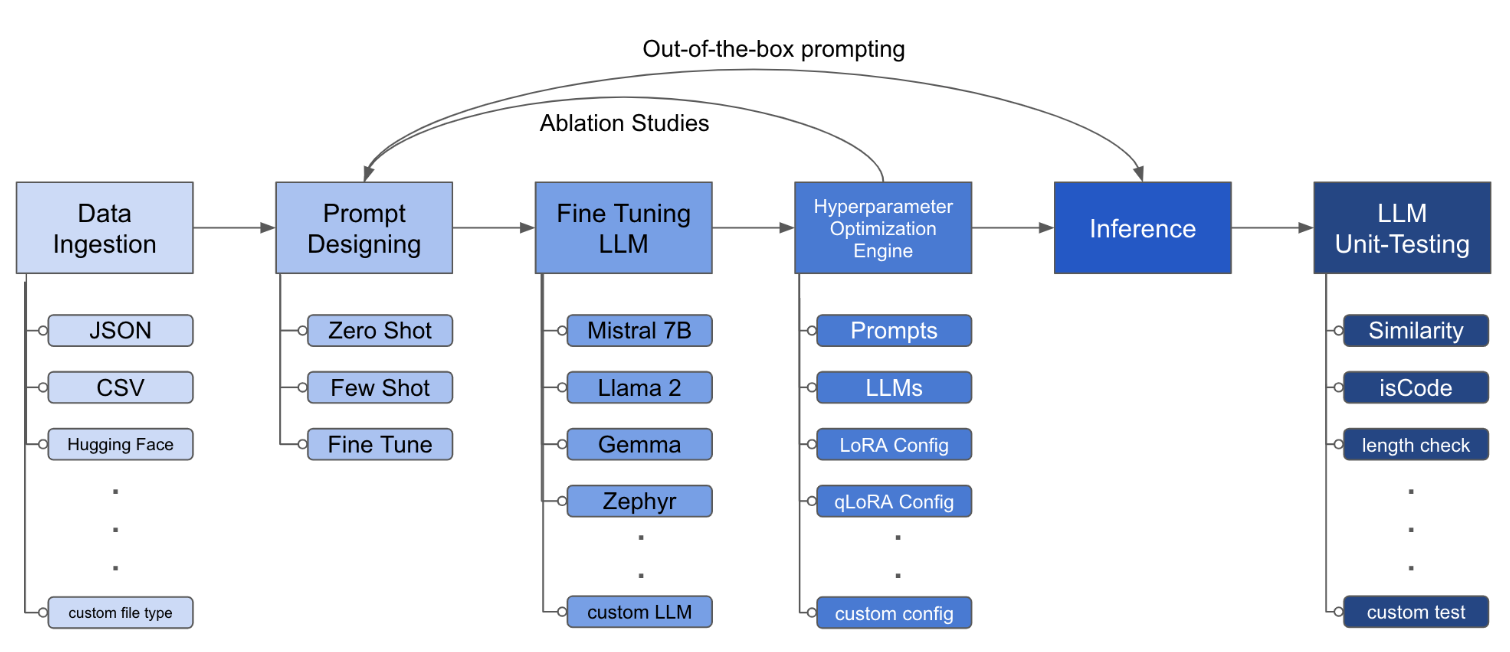
O LLM Finetuning Toolkit é uma ferramenta de CLI baseada em configuração para lançar uma série de experimentos de ajuste fino da LLM em seus dados e reunir seus resultados. A partir de um único arquivo de configuração yaml , controle todos os elementos de um pipeline de experimentação típico - prompts , LLMs de código aberto , estratégia de otimização e teste de LLM .
O PIPX instala o pacote e as dependências em um ambiente virtual separado
pipx install llm-toolkitpip install llm-toolkitEste guia contém 3 estágios que permitirão que você aproveite ao máximo este kit de ferramentas!
llmtune generate config
llmtune run ./config.yml O primeiro comando gera um arquivo útil inicial config.yml e salva no diretório de trabalho atual. Isso é fornecido aos usuários para começar rapidamente e como base para uma modificação adicional.
Em seguida, o segundo comando inicia o processo de ajuste fino usando as configurações especificadas no arquivo de configuração YAML padrão config.yaml .
O arquivo de configuração é a peça central que define o comportamento do kit de ferramentas. Está escrito no formato YAML e consiste em várias seções que controlam diferentes aspectos do processo, como ingestão de dados, definição de modelo, treinamento, inferência e garantia de qualidade. Destacamos algumas das seções críticas.
Para ativar a atendimento flash para modelos suportados. Primeiro instalar flash-attn :
pipx
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationpip
pip install flash-attn --no-build-isolation
Em seguida, adicione ao arquivo de configuração.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " Um exemplo de como pode ser a ingestão de dados:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> Os campos prompts ajudam a criar instruções para ajustar o LLM. Ele lê dados de colunas específicas, mencionadas nos colchetes {}, que estão presentes no seu conjunto de dados. No exemplo fornecido, espera -se que o arquivo de dados tenha nomes de colunas: instruction , input e output .
Os campos prompts usam o prompt e prompt_stub durante o ajuste fino. No entanto, durante o teste, apenas a seção prompt é usada como entrada para o LLM ajustado.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r e o abandono, podem ser alterados. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test Esta configuração será executada e salvará os resultados no diretório ./experiment/[unique_hash] . Cada configuração exclusiva gerará um hash exclusivo, para que nossa ferramenta possa pegar automaticamente de onde parou. Por exemplo, se você precisar sair no meio do treinamento, relançando o script, o programa carregará automaticamente o conjunto de dados existente que foi gerado no diretório, em vez de fazê -lo novamente.
Depois que o script termina em execução, você verá estes artefatos distintos:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionDepois que todas as alterações forem incorporadas no arquivo YAML, você pode simplesmente usá-lo para executar um experimento personalizado de ajuste fino!
python toolkit.py --config-path < path to custom YAML file >Os fluxos de trabalho de ajuste fino geralmente envolvem a execução de estudos de ablação em vários LLMs, projetos rápidos e técnicas de otimização. O arquivo de configuração pode ser alterado para apoiar os estudos de ablação.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] O kit de ferramentas fornece uma arquitetura modular e extensível que permite aos desenvolvedores personalizar e aprimorar sua funcionalidade para atender às suas necessidades específicas. Cada componente do kit de ferramentas, como ingestão de dados, ajuste fino, inferência e teste de garantia de qualidade, é projetado para ser facilmente extensível.
As contribuições de código aberto para este kit de ferramentas são bem-vindas e incentivadas. Se você deseja contribuir, consulte contribuindo.md.


