LLM Finetuning Toolkit
v0.2.3

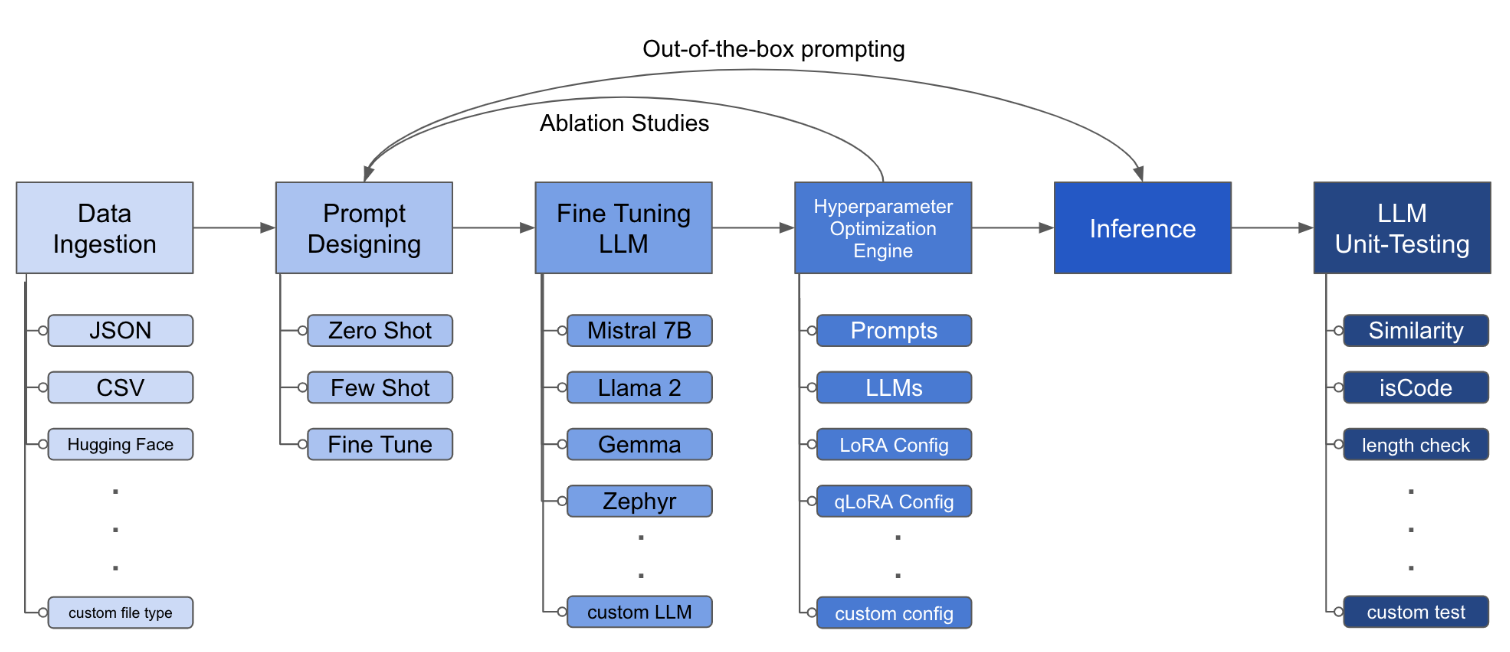
LLM Finetuning Toolkit est un outil CLI basé sur la configuration pour lancer une série d'expériences de réglage fin LLM sur vos données et recueillir leurs résultats. À partir d'un seul fichier de configuration yaml , contrôlez tous les éléments d'un pipeline d'expérimentation typique - invites , LLMS open-source , stratégie d'optimisation et tests LLM .
PIPX installe le package et les dépendances dans un environnement virtuel séparé
pipx install llm-toolkitpip install llm-toolkitCe guide contient 3 étapes qui vous permettront de tirer le meilleur parti de cette boîte à outils!
llmtune generate config
llmtune run ./config.yml La première commande génère un fichier starter config.yml utile et enregistre dans le répertoire de travail actuel. Ceci est fourni aux utilisateurs pour démarrer rapidement et comme base pour une modification supplémentaire.
Ensuite, la deuxième commande initie le processus de réglage fin à l'aide des paramètres spécifiés dans le fichier de configuration YAML par défaut config.yaml .
Le fichier de configuration est la pièce centrale qui définit le comportement de la boîte à outils. Il est écrit au format YAML et se compose de plusieurs sections qui contrôlent différents aspects du processus, tels que l'ingestion de données, la définition du modèle, la formation, l'inférence et l'assurance qualité. Nous mettons en évidence certaines des sections critiques.
Pour permettre la mise en garde Flash pour les modèles pris en charge. Installez d'abord flash-attn :
pipx
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationpépin
pip install flash-attn --no-build-isolation
Ensuite, ajoutez au fichier config.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " Un exemple de ce à quoi peut ressembler l'ingestion de données:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> Les champs rapides aident à créer des instructions pour affiner le LLM. Il lit les données de colonnes spécifiques, mentionnées dans des supports {}, qui sont présents dans votre ensemble de données. Dans l'exemple fourni, il est prévu que le fichier de données ait des noms de colonne: instruction , input et output .
Les champs d'invite utilisent à la fois prompt et prompt_stub pendant le réglage fin. Cependant, lors des tests, seule la section prompt est utilisée comme entrée dans le LLM affiné.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r et le décrochage, peuvent être modifiés. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test Cette configuration s'exécutera des réglages fins et enregistrera les résultats sous répertoire ./experiment/[unique_hash] . Chaque configuration unique générera un hachage unique, afin que notre outil puisse automatiquement reprendre là où il s'était arrêté. Par exemple, si vous devez sortir au milieu de la formation, en relancant le script, le programme chargera automatiquement l'ensemble de données existant qui a été généré dans le répertoire, au lieu de recommencer.
Une fois le script terminé en cours d'exécution, vous verrez ces artefacts distincts:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionUne fois que toutes les modifications ont été incorporées dans le fichier YAML, vous pouvez simplement l'utiliser pour exécuter une expérience de réglage fin personnalisée!
python toolkit.py --config-path < path to custom YAML file >Les workflows finissants impliquent généralement l'exécution d'études d'ablation dans divers LLM, des conceptions rapides et des techniques d'optimisation. Le fichier de configuration peut être modifié pour prendre en charge l'exécution d'études d'ablation.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] La boîte à outils fournit une architecture modulaire et extensible qui permet aux développeurs de personnaliser et d'améliorer sa fonctionnalité en fonction de leurs besoins spécifiques. Chaque composant de la boîte à outils, tel que l'ingestion de données, le réglage fin, l'inférence et les tests d'assurance qualité, est conçu pour être facilement extensible.
Les contributions open source à cette boîte à outils sont les bienvenues et encouragées. Si vous souhaitez contribuer, veuillez consulter contribution.md.


