LLM Finetuning Toolkit
v0.2.3

LLM MineTuning Toolkit-это инструмент CLI на основе конфигурации для запуска серии экспериментов с тонкой настройкой LLM на ваших данных и сбора их результатов. Из одного файла конфигурации yaml управляйте всеми элементами типичного экспериментального конвейера - подсказки , LLMS с открытым исходным кодом , стратегии оптимизации и тестирования LLM .
PIPX устанавливает пакет и зависимости в отдельной виртуальной среде
pipx install llm-toolkitpip install llm-toolkitЭто руководство содержит 3 этапа, которые позволят вам получить максимальную отдачу от этого инструментария!
llmtune generate config
llmtune run ./config.yml Первая команда генерирует полезный файл config.yml стартера. Myml и сохраняет в текущем рабочем каталоге. Это предоставляется пользователям для быстрого начала и в качестве базы для дальнейшей модификации.
Затем вторая команда инициирует процесс тонкой настройки, используя настройки, указанные в файле конфигурации YAML config.yaml умолчанию.
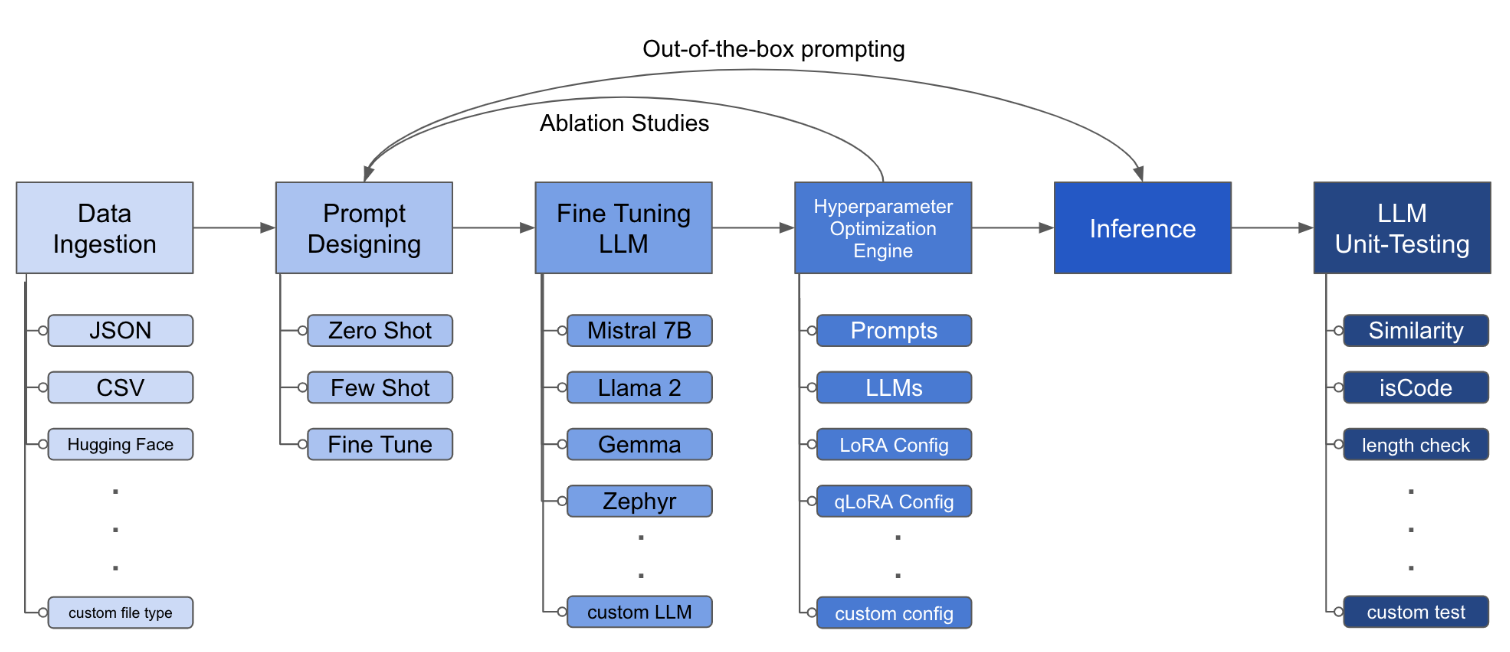
Файл конфигурации - это центральная часть, которая определяет поведение инструментария. Он написан в формате YAML и состоит из нескольких разделов, которые контролируют различные аспекты процесса, такие как приглашение данных, определение модели, обучение, вывод и обеспечение качества. Мы выделяем некоторые критические разделы.
Чтобы включить флэш-агитацию для поддерживаемых моделей. Сначала установить flash-attn :
пипкс
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationпип
pip install flash-attn --no-build-isolation
Затем добавьте в файл конфигурации.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " Пример того, как может выглядеть употребление данных:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> Полные поля помогают создавать инструкции, чтобы точно настроить LLM. Он считывает данные из конкретных столбцов, упомянутых в {} скобках, которые присутствуют в вашем наборе данных. В приведенном примере ожидается, что файл данных имеет имена столбцов: instruction , input и output .
Поля «Приглашения» используют как prompt , так и prompt_stub во время точной настройки. Однако во время тестирования только в качестве входного ввода используется только prompt часть LLM.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r и выброс, могут быть изменены. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test Эта конфигурация будет работать с тонкой настройкой и сохранить результаты в Directory ./experiment/[unique_hash] . Каждая уникальная конфигурация будет генерировать уникальный хэш, так что наш инструмент может автоматически поднять, где он остановился. Например, если вам нужно выйти в середине обучения, перезаписывая сценарий, программа автоматически загрузит существующий набор данных, который был сгенерирован в каталоге, вместо того, чтобы делать это все снова.
После запуска сценария вы увидите эти различные артефакты:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionПосле того, как все изменения были включены в файл YAML, вы можете просто использовать его для запуска пользовательского эксперимента с тонкой настройкой!
python toolkit.py --config-path < path to custom YAML file >Прекрасные рабочие процессы, как правило, включают в себя пропуск исследований абляции по различным LLMS, быстрые проекты и методы оптимизации. Файл конфигурации может быть изменен для поддержки запущенных исследований абляции.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] Toolkit предоставляет модульную и расширяемую архитектуру, которая позволяет разработчикам настраивать и улучшать свои функции в соответствии с их конкретными потребностями. Каждый компонент инструментария, такого как приема данных, тонкая настройка, вывод и тестирование качества, предназначено для того, чтобы его можно было легко расширить.
Вклад с открытым исходным кодом в этот инструментарий приветствуется и поощряется. Если вы хотите внести свой вклад, см. Appling.md.


