LLM Finetuning Toolkit
v0.2.3

LLM FinetUning Toolkit هي أداة CLI قائمة على التكوين لإطلاق سلسلة من تجارب صقل LLM على بياناتك وجمع نتائجها. من ملف تكوين yaml واحد ، تتحكم في جميع عناصر خط أنابيب التجريب النموذجي - المطالبات ، LLMS مفتوحة المصدر ، استراتيجية التحسين واختبار LLM .
يقوم PIPX بتثبيت الحزمة والتبعيات في بيئة افتراضية منفصلة
pipx install llm-toolkitpip install llm-toolkitيحتوي هذا الدليل على 3 مراحل ستمكنك من الحصول على أقصى استفادة من مجموعة الأدوات هذه!
llmtune generate config
llmtune run ./config.yml يقوم الأمر الأول بإنشاء ملف config.yml مفيد ويحفظ في دليل العمل الحالي. يتم توفير ذلك للمستخدمين للبدء بسرعة وكقاعدة لمزيد من التعديل.
ثم يبدأ الأمر الثاني في عملية الضبط باستخدام الإعدادات المحددة في ملف تكوين YAML الافتراضي config.yaml .
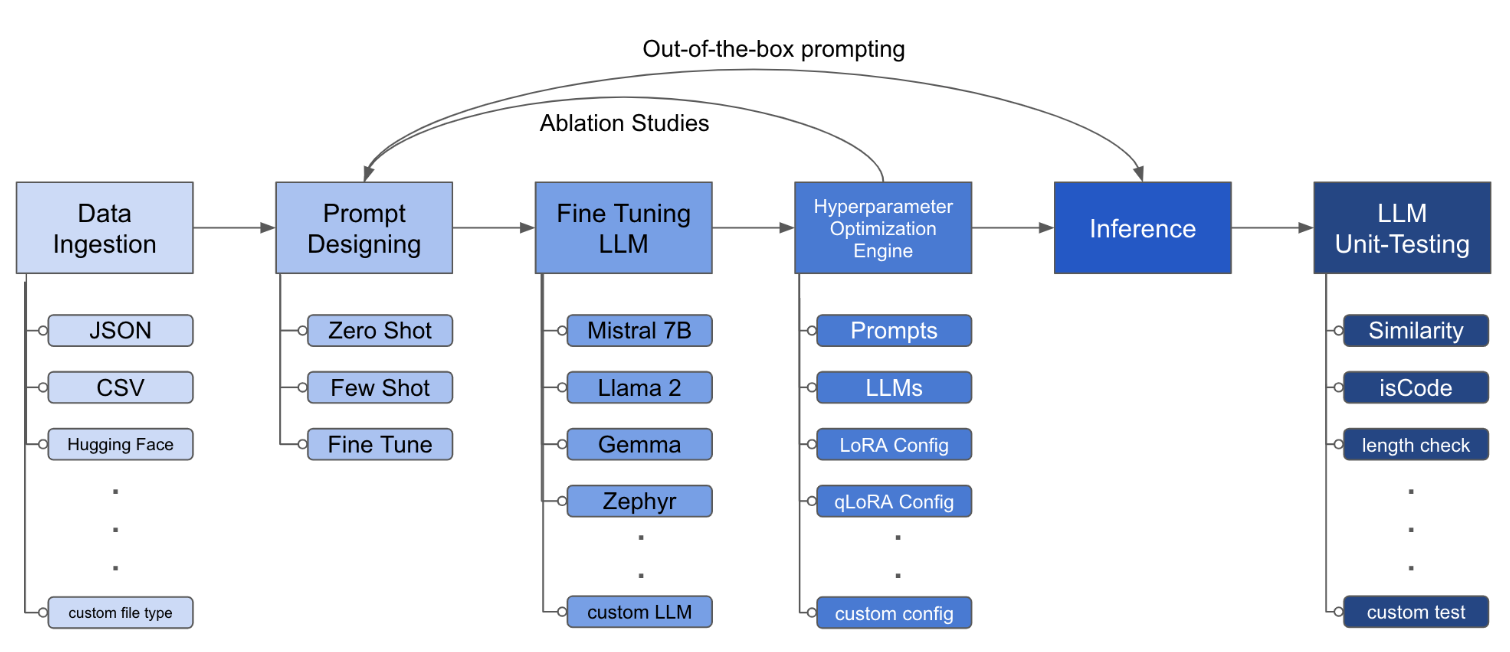
ملف التكوين هو القطعة المركزية التي تحدد سلوك مجموعة الأدوات. إنه مكتوب بتنسيق YAML ويتألف من عدة أقسام تتحكم في جوانب مختلفة من العملية ، مثل ابتلاع البيانات ، وتعريف النموذج ، والتدريب ، والاستدلال ، وضمان الجودة. نسلط الضوء على بعض الأقسام الحرجة.
لتمكين الاهتمام الفلاش للنماذج المدعومة. أول تثبيت flash-attn :
PIPX
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationpip
pip install flash-attn --no-build-isolation
ثم ، أضف إلى ملف التكوين.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " مثال على شكل ابتلاع البيانات:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> تساعد الحقول المطالبة في إنشاء إرشادات لضبط LLM. يقرأ البيانات من أعمدة محددة ، المذكورة في قوسين {} ، موجودة في مجموعة البيانات الخاصة بك. في المثال المقدم ، من المتوقع أن يحتوي ملف البيانات على أسماء الأعمدة: instruction input output .
تستخدم الحقول المطالبة كلاً من prompt و prompt_stub أثناء الضبط. ومع ذلك ، أثناء الاختبار ، يتم استخدام قسم prompt فقط كمدخلات إلى LLM المضبوطة.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r و Strped. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test سيتم تشغيل هذا التكوين بشكل دقيق ويحفظ النتائج ضمن الدليل ./experiment/[unique_hash] سيقوم كل تكوين فريد بإنشاء تجزئة فريدة من نوعها ، بحيث يمكن لأداةنا التلقائي تلقائيًا من حيث توقفت. على سبيل المثال ، إذا كنت بحاجة إلى الخروج في منتصف التدريب ، من خلال إعادة إطلاق البرنامج النصي ، فسيقوم البرنامج تلقائيًا بتحميل مجموعة البيانات الموجودة التي تم إنشاؤها تحت الدليل ، بدلاً من القيام بذلك مرة أخرى.
بعد انتهاء البرنامج النصي ، سترى هذه القطع الأثرية المميزة:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionبمجرد دمج جميع التغييرات في ملف YAML ، يمكنك ببساطة استخدامه لتشغيل تجربة صقل مخصصة!
python toolkit.py --config-path < path to custom YAML file >عادةً ما تتضمن مهام سير العمل الدقيقة تشغيل دراسات الاجتثاث عبر مختلف LLMs والتصميمات السريعة وتقنيات التحسين. يمكن تغيير ملف التكوين لدعم تشغيل دراسات الاجتثاث.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] توفر مجموعة الأدوات بنية معيارية وقابلة للتمديد تتيح للمطورين تخصيص وظائفها وتعزيزها لتناسب احتياجاتهم الخاصة. تم تصميم كل مكون من مكونات مجموعة الأدوات ، مثل ابتلاع البيانات ، والضبط ، والاستدلال ، واختبار ضمان الجودة ، ليكون قابلاً للتمديد بسهولة.
المساهمات المفتوحة في مجموعة الأدوات هذه موضع ترحيب وتشجيع. إذا كنت ترغب في المساهمة ، يرجى الاطلاع على المساهمة.


