LLM Finetuning Toolkit
v0.2.3

LLM Finetuning Toolkit es una herramienta CLI basada en configuraciones para iniciar una serie de experimentos de ajuste fino de LLM en sus datos y recopilar sus resultados. Desde un solo archivo de configuración yaml , controle todos los elementos de una tubería de experimentación típica: indicaciones , LLM de código abierto , estrategia de optimización y pruebas de LLM .
PIPX instala el paquete y las dependencias en un entorno virtual separado
pipx install llm-toolkitpip install llm-toolkit¡Esta guía contiene 3 etapas que le permitirán aprovechar al máximo este kit de herramientas!
llmtune generate config
llmtune run ./config.yml El primer comando genera un archivo de inicio config.yml arranque útil y guarda en el directorio de trabajo actual. Esto se proporciona a los usuarios para comenzar rápidamente y como base para una modificación adicional.
Luego, el segundo comando inicia el proceso de ajuste fino utilizando la configuración especificada en el archivo de configuración YAML predeterminado config.yaml .
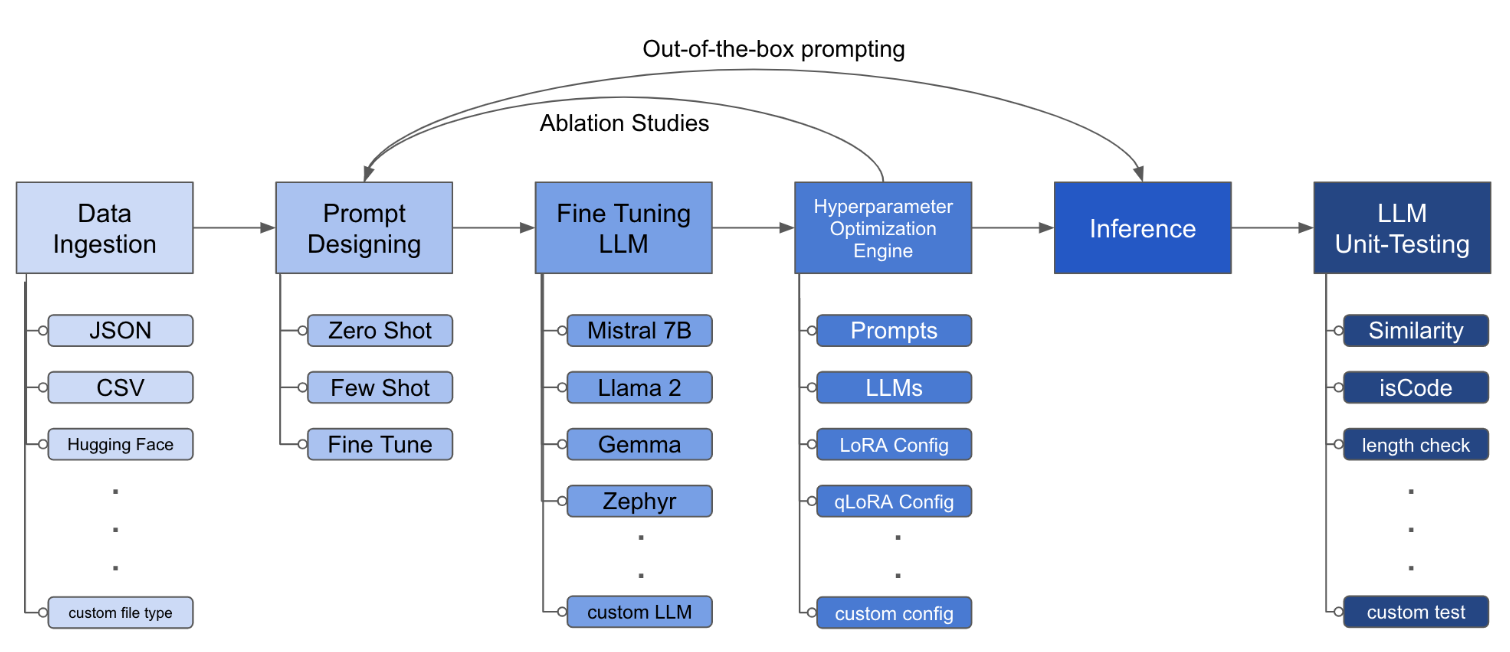
El archivo de configuración es la pieza central que define el comportamiento del kit de herramientas. Está escrito en formato YAML y consta de varias secciones que controlan diferentes aspectos del proceso, como la ingestión de datos, la definición del modelo, la capacitación, la inferencia y la garantía de calidad. Destacamos algunas de las secciones críticas.
Para habilitar la atención flash para modelos compatibles. Primer instalación flash-attn :
pipa
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationpepita
pip install flash-attn --no-build-isolation
Luego, agregue al archivo de configuración.
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " Un ejemplo de cómo puede ser la ingestión de datos:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> Los campos de inmediato ayudan a crear instrucciones para ajustar el LLM. Se lee datos de columnas específicas, mencionadas en {} soportes, que están presentes en su conjunto de datos. En el ejemplo proporcionado, se espera que el archivo de datos tenga nombres de columnas: instruction , input y output .
Los campos de inmediato usan prompt y prompt_stub durante el ajuste fino. Sin embargo, durante las pruebas, solo la sección prompt se usa como entrada al LLM sintonizado.
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r y el abandono, pueden alterarse. lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test Esta configuración ejecutará el ajuste y guardará los resultados en el directorio ./experiment/[unique_hash] . Cada configuración única generará un hash único, para que nuestra herramienta pueda retomar automáticamente dónde lo dejó. Por ejemplo, si necesita salir en el medio de la capacitación, relanzando el script, el programa cargará automáticamente el conjunto de datos existente que se ha generado en el directorio, en lugar de hacerlo todo nuevamente.
Después de que termine el guión en funcionamiento, verá estos artefactos distintos:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionUna vez que se han incorporado todos los cambios en el archivo YAML, ¡simplemente puede usarlo para ejecutar un experimento personalizado de ajuste fino!
python toolkit.py --config-path < path to custom YAML file >Los flujos de trabajo ajustados generalmente implican ejecutar estudios de ablación en varios LLM, diseños inmediatos y técnicas de optimización. El archivo de configuración se puede alterar para admitir la ejecución de estudios de ablación.
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] El kit de herramientas proporciona una arquitectura modular y extensible que permite a los desarrolladores personalizar y mejorar su funcionalidad para satisfacer sus necesidades específicas. Cada componente del conjunto de herramientas, como la ingestión de datos, el ajuste fino, la inferencia y las pruebas de garantía de calidad, está diseñado para ser fácilmente extensible.
Las contribuciones de código abierto a este conjunto de herramientas son bienvenidas y alentadas. Si desea contribuir, consulte Contriping.md.


