LLM Finetuning Toolkit
v0.2.3

LLM Finetuning Toolkit เป็นเครื่องมือ CLI ที่ใช้การกำหนดค่าสำหรับการเปิดตัวชุดการทดลองปรับแต่ง LLM ในข้อมูลของคุณและรวบรวมผลลัพธ์ จากไฟล์กำหนดค่า yaml เดียวควบคุมองค์ประกอบทั้งหมดของไปป์ไลน์การทดลองทั่วไป - พรอมต์ , LLM โอเพนซอร์ซ , กลยุทธ์การเพิ่มประสิทธิภาพ และ การทดสอบ LLM
PIPX ติดตั้งแพ็คเกจและการพึ่งพาในสภาพแวดล้อมเสมือนจริงแยกต่างหาก
pipx install llm-toolkitpip install llm-toolkitคู่มือนี้มี 3 ขั้นตอนที่จะช่วยให้คุณได้รับประโยชน์สูงสุดจากชุดเครื่องมือนี้!
llmtune generate config
llmtune run ./config.yml คำสั่งแรกสร้างไฟล์ config.yml สตาร์ทเตอร์ที่เป็นประโยชน์และบันทึกในไดเรกทอรีการทำงานปัจจุบัน สิ่งนี้มีให้สำหรับผู้ใช้เพื่อเริ่มต้นอย่างรวดเร็วและเป็นฐานสำหรับการปรับเปลี่ยนเพิ่มเติม
จากนั้นคำสั่งที่สองจะเริ่มกระบวนการปรับแต่งอย่างละเอียดโดยใช้การตั้งค่าที่ระบุในไฟล์กำหนดค่า YAML config.yaml ค่าเริ่มต้น
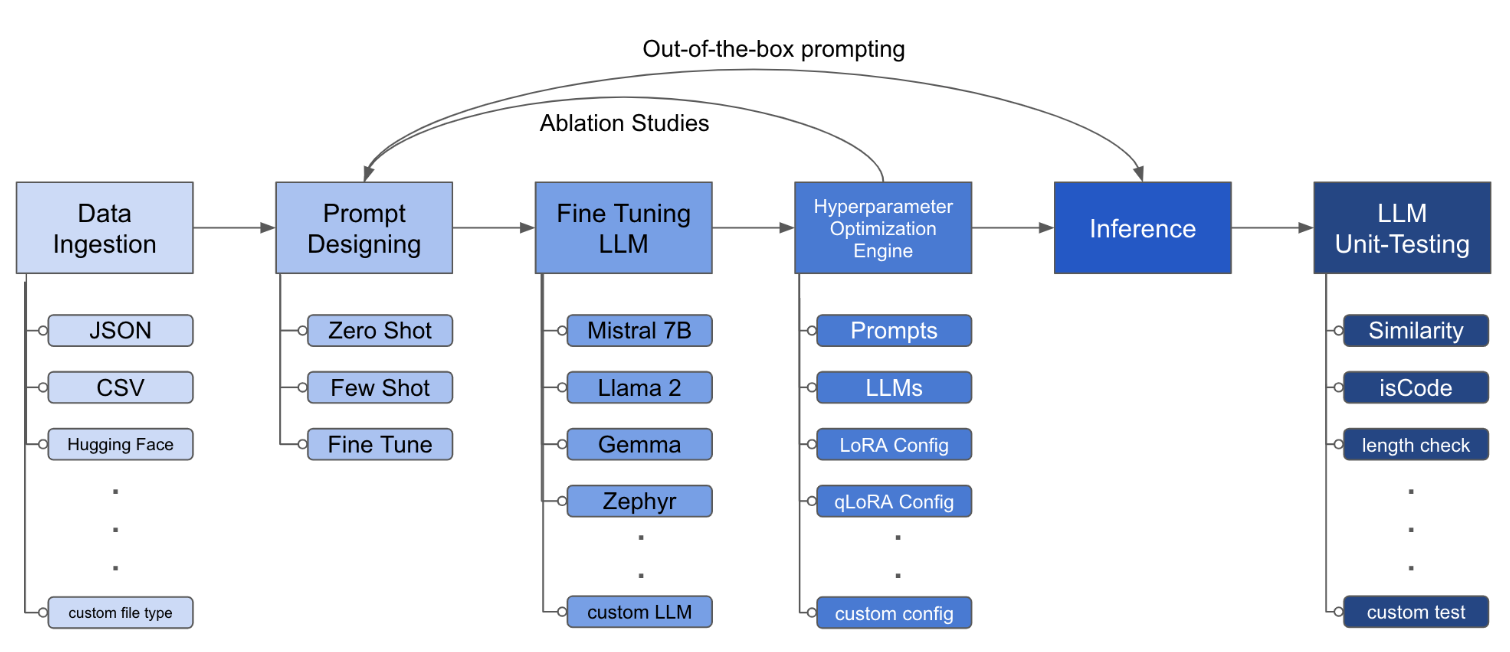
ไฟล์การกำหนดค่าเป็นชิ้นส่วนกลางที่กำหนดพฤติกรรมของชุดเครื่องมือ มันถูกเขียนขึ้นในรูปแบบ YAML และประกอบด้วยหลายส่วนที่ควบคุมแง่มุมต่าง ๆ ของกระบวนการเช่นการบริโภคข้อมูลคำจำกัดความของแบบจำลองการฝึกอบรมการอนุมานและการประกันคุณภาพ เราเน้นบางส่วนที่สำคัญ
เพื่อเปิดใช้งานความสนใจแบบแฟลชสำหรับรุ่นที่รองรับ ติดตั้ง flash-attn ก่อน:
pipx
pipx inject llm-toolkit flash-attn --pip-args=--no-build-isolationปิ๊ก
pip install flash-attn --no-build-isolation
จากนั้นเพิ่มลงในไฟล์ config
model :
torch_dtype : " bfloat16 " # or "float16" if using older GPU
attn_implementation : " flash_attention_2 " ตัวอย่างของการบริโภคข้อมูลอาจเป็นอย่างไร:
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
# ## Instruction: {instruction}
# ## Input: {input}
# ## Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 file_type : " json "
path : " <path to your data file> file_type : " csv "
path : " <path to your data file> ฟิลด์พรอมต์ช่วยสร้างคำแนะนำในการปรับแต่ง LLM มันอ่านข้อมูลจากคอลัมน์เฉพาะที่กล่าวถึงในวงเล็บ {} ที่มีอยู่ในชุดข้อมูลของคุณ ในตัวอย่างที่ให้ไว้คาดว่าไฟล์ข้อมูลจะมีชื่อคอลัมน์: instruction input และ output
ฟิลด์พรอมต์ใช้ทั้ง prompt และ prompt_stub ในระหว่างการปรับแต่ง อย่างไรก็ตามในระหว่างการทดสอบ เฉพาะ ส่วน prompt จะใช้เป็นอินพุตไปยัง LLM ที่ปรับแต่งอย่างละเอียด
model :
hf_model_ckpt : " NousResearch/Llama-2-7b-hf "
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 "
# LoRA Params -------------------
lora :
task_type : " CAUSAL_LM "
r : 32
lora_dropout : 0.1
target_modules :
- q_proj
- v_proj
- k_proj
- o_proj
- up_proj
- down_proj
- gate_proj hf_model_ckpt : " mistralai/Mistral-7B-v0.1 " hf_model_ckpt : " tiiuae/falcon-7b "r และการออกกลางคันสามารถเปลี่ยนแปลงได้ lora :
r : 64
lora_dropout : 0.25 qa :
llm_metrics :
- length_test
- word_overlap_test การกำหนดค่านี้จะเรียกใช้การปรับแต่งอย่างละเอียดและบันทึกผลลัพธ์ภายใต้ไดเรกทอรี ./experiment/[unique_hash] การกำหนดค่าที่ไม่ซ้ำกันแต่ละครั้งจะสร้างแฮชที่ไม่ซ้ำกันเพื่อให้เครื่องมือของเราสามารถรับได้โดยอัตโนมัติ ตัวอย่างเช่นหากคุณต้องการออกในช่วงกลางของการฝึกอบรมโดยการเปิดตัวสคริปต์ใหม่โปรแกรมจะโหลดชุดข้อมูลที่มีอยู่โดยอัตโนมัติซึ่งถูกสร้างขึ้นภายใต้ไดเรกทอรีแทนที่จะทำซ้ำอีกครั้ง
หลังจากที่สคริปต์ทำงานเสร็จคุณจะเห็นสิ่งประดิษฐ์ที่แตกต่างเหล่านี้:
/dataset # generated pkl file in hf datasets format
/model # peft model weights in hf format
/results # csv of prompt, ground truth, and predicted values
/qa # csv of test results: e.g. vector similarity between ground truth and predictionเมื่อการเปลี่ยนแปลงทั้งหมดได้รับการรวมอยู่ในไฟล์ YAML คุณสามารถใช้มันเพื่อเรียกใช้การทดลองปรับแต่งแบบกำหนดเอง!
python toolkit.py --config-path < path to custom YAML file >โดยทั่วไปแล้วเวิร์กโฟลว์การปรับจูนจะเกี่ยวข้องกับการศึกษาการระเหยใน LLMs ต่างๆการออกแบบที่รวดเร็วและเทคนิคการปรับให้เหมาะสม ไฟล์การกำหนดค่าสามารถเปลี่ยนแปลงได้เพื่อสนับสนุนการศึกษาการระเหย
data :
file_type : " huggingface "
path : " yahma/alpaca-cleaned "
prompt :
- >-
This is the first prompt template to iterate over
### Input: {input}
### Output:
- >-
This is the second prompt template
### Instruction: {instruction}
### Input: {input}
### Output:
prompt_stub : { output }
test_size : 0.1 # Proportion of test as % of total; if integer then # of samples
train_size : 0.9 # Proportion of train as % of total; if integer then # of samples
train_test_split_seed : 42 model :
hf_model_ckpt :
[
" NousResearch/Llama-2-7b-hf " ,
mistralai/Mistral-7B-v0.1",
" tiiuae/falcon-7b " ,
]
quantize : true
bitsandbytes :
load_in_4bit : true
bnb_4bit_compute_dtype : " bf16 "
bnb_4bit_quant_type : " nf4 " lora :
r : [16, 32, 64]
lora_dropout : [0.25, 0.50] ชุดเครื่องมือให้สถาปัตยกรรมแบบแยกส่วนและขยายได้ซึ่งช่วยให้นักพัฒนาสามารถปรับแต่งและปรับปรุงการทำงานเพื่อให้เหมาะกับความต้องการเฉพาะของพวกเขา แต่ละองค์ประกอบของชุดเครื่องมือเช่นการบริโภคข้อมูลการปรับแต่งการอนุมานและการทดสอบการประกันคุณภาพได้รับการออกแบบให้สามารถขยายได้ง่าย
การบริจาคโอเพ่นซอร์สสำหรับชุดเครื่องมือนี้ยินดีต้อนรับและสนับสนุน หากคุณต้องการมีส่วนร่วมโปรดดูการสนับสนุน


